Influcoder: Distilling Decoders' Gradient Influence Rankings into an Encoder for Data Attribution
Pith reviewed 2026-06-27 06:31 UTC · model grok-4.3
The pith
Influcoder trains an encoder to approximate a decoder's gradient influence rankings for fast data attribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Influcoder distills gradient influence rankings computed on decoder models into an encoder model, yielding a quick and cost-effective approximation of influence-based data attribution that avoids repeated expensive gradient computations during inference.
What carries the argument
Influcoder, the distillation process that maps decoder-derived influence rankings onto an encoder model for reuse at scale.
If this is right
- Data attribution becomes practical for filtering training sets at the size used for current large language models.
- Training data can be curated to reduce specific unwanted behaviors such as toxicity without retraining from scratch.
- Storage and compute costs for influence calculations drop because the encoder produces rankings without full decoder gradients.
- Iterative dataset improvement cycles shorten because attribution scores are available quickly after each training run.
Where Pith is reading between the lines
- The same distillation idea could be tested on pairs of models that differ in architecture beyond encoder versus decoder.
- If the encoder approximation holds, it might combine with other attribution techniques to cross-check results on suspicious samples.
- The method could be applied to track how specific training examples affect downstream fine-tuning tasks rather than pretraining alone.
Load-bearing premise
An encoder model can accurately reproduce the influence rankings that a decoder model would produce on the same data.
What would settle it
Running both Influcoder and standard influence functions on the same held-out set of model outputs and finding low correlation between the two sets of attributed training samples.
Figures

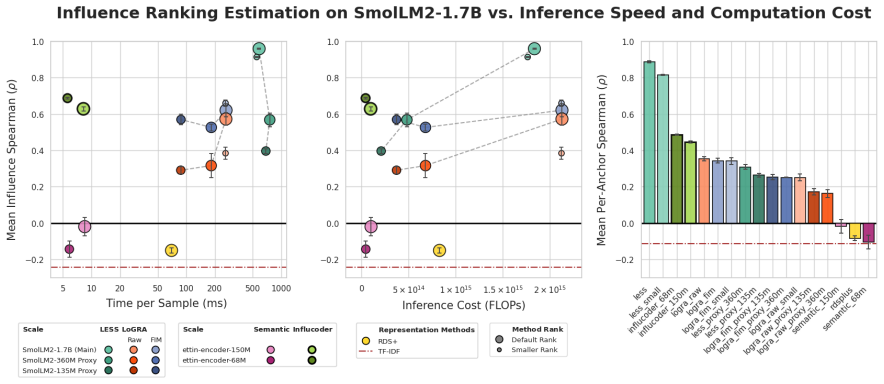
read the original abstract
With the growth of LLMs' (Large Language Models) capabilities, there has been an increasing push to curate high quality datasets by filtering samples in the training data. In general, Data Attribution (DA) methods aim to estimate how individual samples in a training dataset can precondition a model to generate certain outputs. As an example, one might be interested in which samples in the data could be the source of toxic behavior after training the LLM. Many methods quantify this conditioning through the paradigm of influence functions. While methods of this family are effective in its function, they lack the necessary processing speed and storage compactness to be practically implemented on large datasets. We propose a method, Influcoder, as a quick and cost-effective approach to influence-based Data Attribution at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Influcoder, a method to distill gradient influence rankings computed on decoder-based LLMs into a separate encoder model, enabling fast and storage-efficient influence-based data attribution at scale without repeated expensive gradient computations during inference.
Significance. If the distillation were shown to preserve ranking fidelity, the approach could make influence functions practical for curating training data in large models, addressing a recognized scalability barrier. The idea of transferring ranking structure via an encoder is conceptually interesting, but the manuscript supplies no empirical or theoretical support for evaluating whether this holds.
major comments (2)
- The manuscript consists only of an abstract that states the proposal without any methods section, equations, experimental protocol, or results. This absence directly prevents assessment of the central claim that an encoder trained on decoder-derived rankings can produce accurate influence attributions at inference time.
- [Abstract] Abstract: the claim that the method is 'quick and cost-effective' and 'accurately' approximates decoder influence rankings lacks any supporting quantitative check (e.g., Kendall-tau, NDCG, or top-k overlap) on held-out data comparing encoder outputs to recomputed decoder influences, which is required to establish that the distillation transfers ranking structure rather than average behavior.
Simulated Author's Rebuttal
We thank the referee for their review. We acknowledge that the current manuscript is limited to an abstract and lacks the detailed methods, equations, experimental protocols, and results needed for full evaluation. We will expand the paper accordingly in revision.
read point-by-point responses
-
Referee: The manuscript consists only of an abstract that states the proposal without any methods section, equations, experimental protocol, or results. This absence directly prevents assessment of the central claim that an encoder trained on decoder-derived rankings can produce accurate influence attributions at inference time.
Authors: We agree that the submitted version contains only the abstract and therefore cannot support assessment of the claims. A revised manuscript will include the full methods section with equations describing the distillation process, the experimental protocol, and results. revision: yes
-
Referee: Abstract: the claim that the method is 'quick and cost-effective' and 'accurately' approximates decoder influence rankings lacks any supporting quantitative check (e.g., Kendall-tau, NDCG, or top-k overlap) on held-out data comparing encoder outputs to recomputed decoder influences, which is required to establish that the distillation transfers ranking structure rather than average behavior.
Authors: The abstract states the intended properties of the method at a high level. The expanded manuscript will report the requested quantitative checks, including Kendall-tau, NDCG, and top-k overlap metrics on held-out data to evaluate ranking fidelity. revision: yes
Circularity Check
No circularity: distillation method is a standard trained approximation without self-referential definitions or fitted predictions by construction
full rationale
The abstract and available text describe Influcoder as a distillation procedure that trains an encoder to approximate precomputed decoder influence rankings. No equations, fitted parameters renamed as predictions, or self-citations are present that would make any claimed output equivalent to its inputs by definition. The approach is a conventional supervised approximation task whose validity depends on external held-out fidelity metrics rather than reducing tautologically to the training data itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , booktitle=
-
[9]
Advances in Neural Information Processing Systems , volume=
What is your data worth to gpt? llm-scale data valuation with influence functions , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
NeurIPS , year=
Enhancing Training Data Attribution with Representational Optimization , author=. NeurIPS , year=
-
[11]
arXiv preprint arXiv:2602.14696 , year=
A Critical Look at Targeted Instruction Selection: Disentangling What Matters (and What Doesn't) , author=. arXiv preprint arXiv:2602.14696 , year=
-
[12]
NeurIPS , year=
MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models , author=. NeurIPS , year=
-
[13]
2026 , eprint=
GIST: Targeted Data Selection for Instruction Tuning via Coupled Optimization Geometry , author=. 2026 , eprint=
2026
-
[14]
Influence-Preserving Proxies for Gradient-Based Data Selection in
Sirui Chen and Yunzhe Qi and Mengting Ai and Yifan Sun and Ruizhong Qiu and Jiaru Zou and Jingrui He , booktitle=. Influence-Preserving Proxies for Gradient-Based Data Selection in. 2026 , url=
2026
-
[15]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Garima and Liu, Frederick and Kale, Satyen and Sundararajan, Mukund , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[16]
Finding frequent items in data streams.Theoretical Computer Science, 312(1):3–15, 2004
Charikar, Moses and Chen, Kevin and Farach-Colton, Martin , title =. 2004 , issue_date =. doi:10.1016/S0304-3975(03)00400-6 , month = jan, pages =
-
[17]
2023 , url =
Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin , title =. 2023 , url =
2023
-
[18]
Challenging BIG - Bench Tasks and Whether Chain -of- Thought Can Solve Them
Suzgun, Mirac and Scales, Nathan and Sch. Challenging BIG -Bench Tasks and Whether Chain-of-Thought Can Solve Them. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.824
-
[19]
2025 , eprint=
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model , author=. 2025 , eprint=
2025
-
[20]
WildGuard: Open One-stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , url =
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , booktitle =. WildGuard: Open One-stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , url =. doi:10.52202/079017-0261 , editor =
-
[21]
2025 , booktitle=
DATE-LM: Benchmarking Data Attribution Evaluation for Large Language Models , author=. 2025 , booktitle=
2025
-
[22]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[23]
2024 , eprint=
The Faiss library , author=. 2024 , eprint=
2024
-
[24]
Deng, Junwei and Hu, Yuzheng and Hu, Pingbang and Li, Ting-wei and Liu, Shixuan and Wang, Jiachen T. and Ley, Dan and Dai, Qirun and Huang, Benhao and Huang, Jin and Jiao, Cathy and Just, Hoang Anh and Pan, Yijun and Shen, Jingyan and Tu, Yiwen and Wang, Weiyi and Wang, Xinhe and Zhang, Shichang and Zhang, Shiyuan and Jia, Ruoxi and Lakkaraju, Himabindu a...
-
[25]
Hamish Ivison and Muru Zhang and Faeze Brahman and Pang Wei Koh and Pradeep Dasigi , year=. 2503.01807 , archivePrefix=
-
[26]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[27]
International Conference on Machine Learning (ICML) , year =
TRAK: Attributing Model Behavior at Scale , author =. International Conference on Machine Learning (ICML) , year =
-
[28]
Contemporary mathematics , year=
Extensions of Lipschitz mappings into Hilbert space , author=. Contemporary mathematics , year=
-
[29]
Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =
Koh, Pang Wei and Liang, Percy , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
2017
-
[30]
Do Influence Functions Work on Large Language Models?
Li, Zhe and Zhao, Wei and Li, Yige and Sun, Jun. Do Influence Functions Work on Large Language Models?. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.775
-
[31]
ArXiv , year=
Studying Large Language Model Generalization with Influence Functions , author=. ArXiv , year=
-
[32]
Large Dual Encoders Are Generalizable Retrievers
Ni, Jianmo and Qu, Chen and Lu, Jing and Dai, Zhuyun and Hernandez Abrego, Gustavo and Ma, Ji and Zhao, Vincent and Luan, Yi and Hall, Keith and Chang, Ming-Wei and Yang, Yinfei. Large Dual Encoders Are Generalizable Retrievers. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.669
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Scalable Influence and Fact Tracing for Large Language Model Pretraining , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
Xing , booktitle=
Sang Keun Choe and Hwijeen Ahn and Juhan Bae and Kewen Zhao and Youngseog Chung and Adithya Pratapa and Willie Neiswanger and Emma Strubell and Teruko Mitamura and Jeff Schneider and Eduard Hovy and Roger Baker Grosse and Eric P. Xing , booktitle=. What is Your Data Worth to. 2026 , url=
2026
-
[35]
DataInf: Efficiently Estimating Data Influence in Lo
Yongchan Kwon and Eric Wu and Kevin Wu and James Zou , booktitle=. DataInf: Efficiently Estimating Data Influence in Lo. 2024 , url=
2024
-
[36]
Tu, Zhuozhuo and Chen, Cheng and Du, Yuxuan. RRI nf: Efficient Influence Function Estimation via Ridge Regression for Large Language Models and Text-to-Image Diffusion Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.933
-
[37]
2026 , eprint=
LoRIF: Low-Rank Influence Functions for Scalable Training Data Attribution , author=. 2026 , eprint=
2026
-
[38]
Transactions on Machine Learning Research , issn=
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[39]
ArXiv , year=
Distilling the Knowledge in a Neural Network , author=. ArXiv , year=
-
[40]
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen. Enhancing Chat Language Models by Scaling High-quality Instructional Conversations. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.183
-
[41]
2025 , eprint=
Seq vs Seq: An Open Suite of Paired Encoders and Decoders , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.