A Bregman Perspective on Classification and Regression Trees
Pith reviewed 2026-06-27 05:07 UTC · model grok-4.3
The pith
Bregman divergences unify impurity measures, node representatives, and split rules across exponential-family CART models via convex functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Key ingredients of the CART methodology—including node representatives, impurity measures, and split selection rules—can be expressed and analyzed through general properties of convex functions rather than through separate model-specific constructions. Classical least-squares, Poisson deviance, Kullback-Leibler-type losses, and other impurity measures associated with exponential-family models are placed inside a common Bregman framework, allowing geometric properties of the generating convex function to govern impurity reductions and stability of recursive partitions, and delivering consistency results for the broad family of Bregman-based CART procedures.
What carries the argument
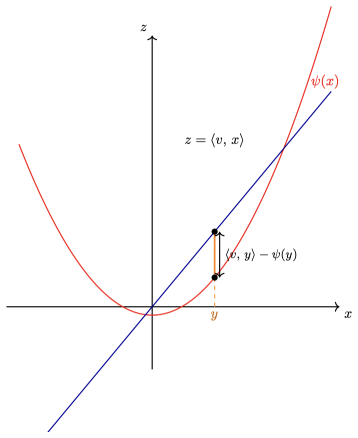
Bregman divergence generated by a convex function, used to represent impurity and to derive node representatives and split selection.
If this is right
- Impurity reductions and split selection rules become consequences of convexity and Bregman properties rather than model-specific derivations.
- Geometric features of the generating convex function directly control the size of impurity drops and the stability of the resulting partitions.
- Consistency theorems apply uniformly to the entire class of Bregman-based CART procedures instead of being proved case by case.
- A geometric interpretation of impurity-based tree construction replaces the collection of separate statistical arguments.
Where Pith is reading between the lines
- The same convex-function lens could be applied to other recursive partitioning methods that rely on impurity or deviance criteria.
- Specific choices of the generating convex function might yield new, previously unexamined impurity measures with controllable stability properties.
- Empirical tests could compare partition stability across different convex generators on the same data sets to isolate the geometric effect.
Load-bearing premise
Impurity measures for exponential-family models admit a Bregman divergence representation generated by a convex function.
What would settle it
An explicit impurity criterion used in standard CART that cannot be written as a Bregman divergence for any convex function.
Figures



read the original abstract
Classification and Regression Trees (CART) constitute one of the most influential paradigms in statistical learning. Although a variety of impurity measures have been proposed for different statistical models, these criteria are typically introduced on a case-by-case basis and analyzed separately. In this paper, we study CART through the lens of Bregman divergences. This perspective places the classical least-squares criterion, Poisson deviance, Kullback-Leibler-type losses, and other impurity measures associated with exponential-family models within a common framework. As a result, key ingredients of the CART methodology -- including node representatives, impurity measures, and split selection rules -- can be expressed and analyzed through general properties of convex functions rather than through separate model-specific constructions. Beyond the algorithmic formulation, we investigate theoretical properties of Bregman-based CART procedures. In particular, we analyze how geometric properties of the generating convex function influence impurity reductions and stability of recursive partitions. We also establish consistency results within the proposed framework, providing a unified theoretical treatment for a broad family of CART type procedures. Our results provide a geometric interpretation of impurity-based tree construction and show that many classical CART impurity criteria admit a common interpretation within a Bregman framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified Bregman-divergence framework for CART procedures on exponential-family models. Node representatives are defined as Bregman projections (unique minimizers of expected divergence), impurity measures as expected divergences to these points, and split rules as maximizers of impurity reduction; all are generated by the cumulant function of the exponential family. The paper recovers classical criteria (squared error, Poisson deviance, KL) as special cases, analyzes how strong convexity and other geometric properties of the generator control reduction rates and partition stability, and derives consistency results for the resulting tree estimators via convex-analysis and empirical-process arguments.
Significance. If the derivations hold, the work supplies a single geometric lens that replaces separate model-specific constructions for a broad class of impurity measures. This yields immediate corollaries for stability and consistency that previously required case-by-case arguments, and it makes transparent how the curvature of the cumulant function governs the behavior of recursive partitioning. The explicit recovery of standard criteria and the use of off-the-shelf convex-analysis tools constitute a genuine organizational contribution.
minor comments (3)
- [§3] §3 (or the section defining the split criterion): the statement that the split rule 'maximizes the reduction in expected Bregman divergence' should explicitly note that this is equivalent to the classical weighted-impurity reduction only after the node-size weighting is inserted; a short derivation would prevent readers from overlooking the weighting step.
- [Theorem on consistency] The consistency theorem (presumably Theorem 4 or 5) invokes 'standard empirical-process arguments' but does not list the precise moment or Lipschitz conditions on the generator f that are needed for the uniform law of large numbers; adding a short remark or reference to the relevant corollary in van der Vaart & Wellner would make the result self-contained.
- Notation: the generating convex function is sometimes denoted f, sometimes ψ, and occasionally left implicit. A single global symbol together with a reminder that it is the cumulant function would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The provided summary accurately captures the manuscript's contributions to unifying CART procedures via Bregman divergences for exponential-family models.
Circularity Check
No significant circularity; standard Bregman framework applied to CART
full rationale
The derivation applies well-known properties of Bregman divergences (node representative as unique minimizer of expected divergence to a convex function's gradient, impurity as expected divergence, splits maximizing reduction) to exponential-family CART. These recover classical criteria (least-squares from quadratic, Poisson from exp) by direct substitution without parameter fitting or redefinition. Consistency and geometric properties follow from external convex analysis and empirical process theory. No self-citation is load-bearing, no ansatz is smuggled, and no step equates a prediction to its own fitted input by construction. The paper is self-contained against standard mathematical benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wadsworth and Brooks/Cole , year=
Classification and Regression Trees , author=. Wadsworth and Brooks/Cole , year=
-
[2]
Journal of Machine Learning Research , volume=
Clustering with Bregman Divergences , author=. Journal of Machine Learning Research , volume=
-
[3]
A Probabilistic Theory of Pattern Recognition , pages=
Feature Extraction , author=. A Probabilistic Theory of Pattern Recognition , pages=. 1996 , publisher=
1996
-
[4]
The annals of statistics , pages=
Consistent nonparametric regression , author=. The annals of statistics , pages=. 1977 , publisher=
1977
-
[5]
IEEE Transactions on Information Theory , volume=
The information geometry of mirror descent , author=. IEEE Transactions on Information Theory , volume=. 2015 , publisher=
2015
-
[6]
Journal of machine learning research , volume=
A unified theory of diversity in ensemble learning , author=. Journal of machine learning research , volume=
-
[7]
arXiv preprint arXiv:2302.05833 , year=
Bregman-Wasserstein divergence: geometry and applications , author=. arXiv preprint arXiv:2302.05833 , year=
-
[8]
Problem complexity and method efficiency in optimization , year=
Wiley-Interscience series in discrete mathematics , author=. Problem complexity and method efficiency in optimization , year=
-
[9]
arXiv preprint arXiv:2511.08789 , year=
A generalized bias-variance decomposition for bregman divergences , author=. arXiv preprint arXiv:2511.08789 , year=
-
[10]
Re-examination of Bregman functions and new properties of their divergences
Re‑examination of Bregman functions and new properties of their divergences , author=. arXiv preprint arXiv:1803.00641 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Nelder , title =
Peter McCullagh and John A. Nelder , title =
-
[12]
2022 , publisher=
Exponential families in theory and practice , author=. 2022 , publisher=
2022
-
[13]
, title =
Bregman, Lev M. , title =. USSR Computational Mathematics and Mathematical Physics , volume =. 1967 , doi =
1967
-
[14]
Journal of Computational and Graphical Statistics , volume =
Zeileis, Achim and Hothorn, Torsten and Hornik, Kurt , title =. Journal of Computational and Graphical Statistics , volume =
-
[15]
Journal of Machine Learning Research , volume =
Hothorn, Torsten and Zeileis, Achim , title =. Journal of Machine Learning Research , volume =
-
[16]
International Journal of Biostatistics , volume =
Seibold, Hannes and Zeileis, Achim and Hothorn, Torsten , title =. International Journal of Biostatistics , volume =
-
[17]
Journal of Computational and Graphical Statistics , volume =
Schlosser, Lisa and Hothorn, Torsten and Stauffer, Reto and Zeileis, Achim , title =. Journal of Computational and Graphical Statistics , volume =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.