Last But Not Least: Boundary Attention CalibratiON for Multimodal KV Cache Compression
Pith reviewed 2026-06-27 10:20 UTC · model grok-4.3
The pith
BACON calibrates observation-window attention with last-query signals to recover answer-critical tokens lost in aggressive multimodal KV cache compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
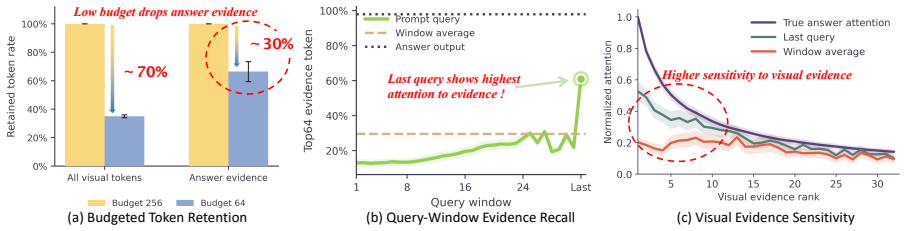
BACON is a plug-and-play calibration that combines observation-window attention with last-query evidence and suppresses isolated noise via intra-layer coherence and inter-layer persistence. Across diverse benchmarks, models, budgets, and compression methods, it improves multimodal KV compression by 7.5 percent on average under the most aggressive budget, with gains up to 30.9 percent.
What carries the argument
The boundary attention calibration that fuses observation-window attention scores with last-query attention, then filters the result using intra-layer coherence and inter-layer persistence to produce a more accurate token-importance ranking.
If this is right
- Average performance rises 7.5 percent under the tightest compression budgets across multiple models and tasks.
- Peak gains reach 30.9 percent on individual benchmarks while remaining compatible with existing compression pipelines.
- The calibration preserves vision-language reasoning quality at higher compression ratios than prior window-only methods.
- Decoding latency drops because fewer tokens are retained in the KV cache without proportional loss in answer quality.
Where Pith is reading between the lines
- The same dual-source calibration pattern may transfer to text-only long-context models that face similar sparse-evidence problems.
- Dynamic per-layer weighting between the two attention sources could further reduce the cases where noise still leaks through.
- The approach suggests that boundary queries carry systematic information about token relevance that single-window aggregation overlooks.
Load-bearing premise
Last-query attention supplies reliable complementary evidence for answer-critical tokens, and intra-layer coherence together with inter-layer persistence can suppress answer-irrelevant signals without discarding useful information.
What would settle it
A controlled test on a benchmark with dense rather than sparse visual evidence where applying the last-query calibration produces lower accuracy than the observation-window baseline alone.
Figures





read the original abstract
Multimodal Large Language Models (MLLMs) achieve strong vision-language reasoning, but long visual contexts enlarge the KV cache and increase decoding latency. Existing compression methods rely on observation window attention for stable token-importance estimation, yet this aggregation can dilute sparse visual evidence and discard answer-critical tokens under aggressive compression. Therefore, we identify last-query attention as a complementary source for recovering such evidence, but its answer-irrelevant signals can mislead retention. We propose BACON, a plug-and-play method that calibrates observation window attention with last-query evidence and suppresses isolated noise via intra-layer coherence and inter-layer persistence. Across diverse benchmarks, models, budgets, and compression methods, BACON improves multimodal KV compression by 7.5% on average under the most aggressive budget, with gains up to 30.9%. Our project page is available at https://ryu1ion.github.io/official_BACON/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BACON, a plug-and-play calibration method for KV-cache compression in multimodal LLMs. It augments observation-window attention scores with last-query attention evidence and suppresses answer-irrelevant tokens via intra-layer coherence and inter-layer persistence filters. The central empirical claim is an average 7.5% performance improvement (up to 30.9%) under aggressive compression budgets across multiple benchmarks, models, and base compression methods.
Significance. If the reported gains prove robust under the supplied experimental protocol, the work would offer a practical, low-overhead improvement to existing KV-compression pipelines for long-context vision-language models. The explicit cross-method, cross-model, and cross-budget evaluation together with ablations directly tests the core assumption that last-query signals can be safely combined with coherence/persistence filtering.
minor comments (3)
- §4.3 and Table 2: the reported standard deviations are given only for the final BACON rows; adding them to the baseline columns would strengthen the statistical comparison.
- Figure 3: the y-axis label 'Relative Performance' should explicitly state the reference (e.g., 'w.r.t. full cache') for clarity.
- §3.1: the notation for the coherence threshold τ_coh is introduced without a preceding sentence defining its range or selection procedure.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the recognition of its practical value for multimodal KV-cache compression, and the recommendation for minor revision. The report accurately captures the motivation, method, and empirical scope of BACON. No specific major comments were provided in the report, so we have no point-by-point revisions to address at this stage.
Circularity Check
No circularity; empirical method with external benchmarks
full rationale
The paper introduces BACON as a plug-and-play calibration method for multimodal KV cache compression, relying on last-query attention, intra-layer coherence, and inter-layer persistence. All performance claims (7.5% average gain, up to 30.9%) are presented strictly as outcomes of experiments across external benchmarks, models, and budgets. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing argument. The construction is self-contained against independent test sets and does not reduce to its own inputs by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Observation-window attention and last-query attention can be combined to produce a more accurate token-importance estimate than either alone.
- domain assumption Intra-layer coherence and inter-layer persistence reliably distinguish signal from noise in attention maps.
Reference graph
Works this paper leans on
-
[1]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[2]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-prumerge: Adaptive token reduction for efficient large multimodal models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[6]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
International Conference on Learning Representations , volume=
Efficient streaming language models with attention sinks , author=. International Conference on Learning Representations , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems , volume=
Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Sparsemm: Head sparsity emerges from visual concept responses in mllms , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[13]
Advances in Neural Information Processing Systems , volume=
Infinipot-v: Memory-constrained kv cache compression for streaming video understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2510.20707 , year=
Mixing Importance with Diversity: Joint Optimization for KV Cache Compression in Large Vision-Language Models , author=. arXiv preprint arXiv:2510.20707 , year=
-
[15]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[16]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[17]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Docvqa: A dataset for vqa on document images , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
Findings of the association for computational linguistics: ACL 2022 , pages=
Chartqa: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics: ACL 2022 , pages=
2022
-
[22]
European conference on computer vision , pages=
Textcaps: a dataset for image captioning with reading comprehension , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[23]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vatex: A large-scale, high-quality multilingual dataset for video-and-language research , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Next-qa: Next phase of question-answering to explaining temporal actions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Screenspot-pro: Gui grounding for professional high-resolution computer use , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[26]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[27]
European Conference on Computer Vision , pages=
Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[28]
LLaVA-OneVision: Easy Visual Task Transfer
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Video-chatgpt: Towards detailed video understanding via large vision and language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Efficient Multimodal Large Language Model via Dynamic KV Cache Quantization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Q-vlm: Post-training quantization for large vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-kd: A framework of distilling multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
EM-KD: Distilling Efficient Multimodal Large Language Model with Unbalanced Vision Tokens , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
Advances in neural information processing systems , volume=
Long-short transformer: Efficient transformers for language and vision , author=. Advances in neural information processing systems , volume=
-
[35]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[36]
Advances in Neural Information Processing Systems , volume=
Kvzip: Query-agnostic kv cache compression with context reconstruction , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
International Conference on Learning Representations , volume=
Not all heads matter: A head-level kv cache compression method with integrated retrieval and reasoning , author=. International Conference on Learning Representations , volume=
-
[38]
See what you are told: Visual attention sink in large multimodal models , author=. arXiv preprint arXiv:2503.03321 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.