NEXUS: Neural Energy Fields for Physically Consistent Contact-Rich 3D Object Dynamics
Pith reviewed 2026-06-27 04:22 UTC · model grok-4.3
The pith
NEXUS derives forces from additive neural energy and dissipation fields on contact graphs to produce consistent 3D object dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
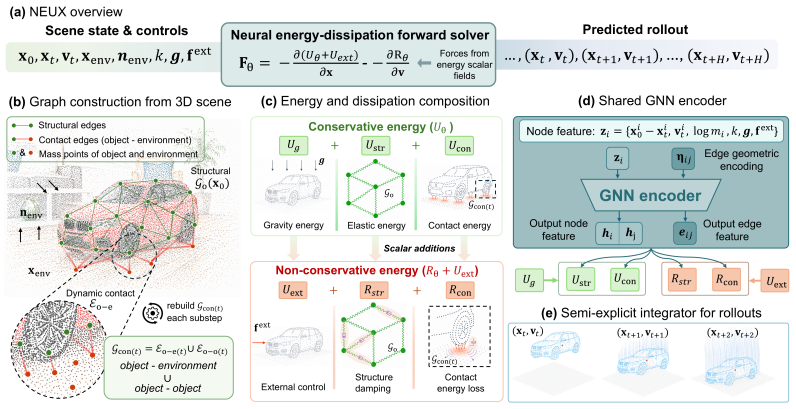
NEXUS formulates contact-rich 3D dynamics by representing objects as structural graphs, constructing object-object and object-environment contact graphs, and expressing motion through additive scalar energy terms for conservative effects and Rayleigh-style dissipation terms for non-conservative effects; forces are recovered by automatic differentiation and rolled out via a semi-implicit integrator, delivering improved long-horizon accuracy over baselines under varying mechanical properties and effect compositions.
What carries the argument
Scalar neural energy and dissipation fields defined on structural and contact graphs, differentiated to yield forces and integrated semi-implicitly.
If this is right
- Long-horizon trajectory accuracy rises relative to both purely learned and physics-structured baselines when mechanical properties and physical-effect compositions vary.
- Trajectories generated by NEXUS supply effective guidance that raises physical plausibility of contact-rich video generation while preserving visual quality.
- Conservative and non-conservative effects can be composed additively inside the same energy-dissipation representation rather than modeled in isolation.
- Differentiation of scalar fields followed by semi-implicit integration produces the forces that drive the dynamics rollout.
Where Pith is reading between the lines
- The graph-based contact representation may allow the same energy fields to be reused across scenes that share object identities but differ in arrangement.
- If the semi-implicit integrator tolerates larger step sizes without instability, the approach could reduce the number of substeps needed for real-time applications.
- Because forces derive from explicit scalar potentials, energy drift over long rollouts becomes directly measurable and potentially correctable by adjusting the learned dissipation term.
Load-bearing premise
Additive composition of the learned energy and dissipation terms, once differentiated and stepped with a semi-implicit integrator, will remain stable and physically consistent across arbitrary contact-rich scenes without extra constraints or tuning.
What would settle it
A benchmark scene with multiple simultaneous contacts, elastic deformation, and damping in which NEXUS trajectories diverge from ground-truth long-horizon paths or violate expected energy behavior while the compared baselines remain closer to truth.
Figures


read the original abstract
Physics-grounded video generation requires controllable 3D object dynamics that remain physically consistent under contact, deformation, and external forcing. Existing trajectory-based methods often model isolated physical effects, making it difficult to compose conservative and non-conservative dynamics in contact-rich 3D scenes. We present NEXUS, a neural energy-field framework for contact-rich 3D object dynamics. NEXUS represents each object as a structural graph and constructs dynamic object-object and object-environment contact graphs. Inspired by Hamiltonian Neural Networks, NEXUS formulates motion through scalar energy and dissipation terms rather than directly predicting states or accelerations. Conservative effects, including gravity and elastic deformation, are composed as additive energy terms, while non-conservative effects such as damping and impact-induced energy loss are modeled with learned Rayleigh-style dissipation. Forces are derived by differentiating the energy and dissipation functions and rolled out with a multi-substep semi-implicit integrator. Across controlled trajectory benchmarks, NEXUS improves long-horizon accuracy over representative learned and physics-structured dynamics baselines under varying mechanical properties and physical-effect compositions. We further show that NEXUS trajectories provide effective guidance for contact-rich video generation, improving physical plausibility while maintaining competitive visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NEXUS, a neural energy-field framework for contact-rich 3D object dynamics. Objects are represented as structural graphs with dynamic contact graphs constructed between objects and the environment. Motion is formulated via additive scalar energy terms (gravity, elasticity) for conservative effects and learned Rayleigh-style dissipation terms for non-conservative effects (damping, impact loss). Forces are obtained by differentiation of these terms and rolled out via a multi-substep semi-implicit integrator. The central empirical claim is improved long-horizon trajectory accuracy over learned and physics-structured baselines across varying mechanical properties, with secondary utility for guiding contact-rich video generation.
Significance. If the accuracy and consistency claims hold under the reported benchmarks, the energy-field formulation with graph-based contacts would provide a structured, composable alternative to direct state or acceleration prediction for physics-grounded dynamics. The separation of conservative and non-conservative effects via differentiable energy and dissipation terms is a clear methodological strength that could benefit simulation and generation tasks.
major comments (1)
- [Abstract (formulation paragraph)] Abstract (formulation paragraph): the headline claim of improved long-horizon accuracy rests on the assumption that additive scalar energies plus learned Rayleigh dissipation, differentiated to forces and integrated semi-implicitly, remain stable and physically consistent for arbitrary contact-rich scenes. No explicit constraints, energy bounds, or stability analysis are described to prevent negative effective damping, interpenetration, or drift when stiffness varies or when learned potentials deviate from conservative fields; this assumption is load-bearing for the central claim.
minor comments (1)
- [Abstract] Abstract: the claim of accuracy gains is stated without any quantitative metrics, error bars, dataset descriptions, or ablation details, which makes the strength of the empirical contribution difficult to assess from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the stability assumptions underlying our energy-field formulation. We respond to the single major comment below.
read point-by-point responses
-
Referee: the headline claim of improved long-horizon accuracy rests on the assumption that additive scalar energies plus learned Rayleigh dissipation, differentiated to forces and integrated semi-implicitly, remain stable and physically consistent for arbitrary contact-rich scenes. No explicit constraints, energy bounds, or stability analysis are described to prevent negative effective damping, interpenetration, or drift when stiffness varies or when learned potentials deviate from conservative fields; this assumption is load-bearing for the central claim.
Authors: We agree that the manuscript provides no formal stability analysis, energy bounds, or explicit constraints on the learned potentials and dissipation terms. The central empirical claim is supported by controlled trajectory benchmarks demonstrating improved long-horizon accuracy without observed instabilities across the tested range of mechanical properties and contact configurations. The multi-substep semi-implicit integrator is selected for its established numerical properties in contact-rich settings, and the Rayleigh-style dissipation is structured to model non-conservative losses. In the revised manuscript we will add a discussion subsection addressing the modeling assumptions, the conditions under which negative effective damping or drift could arise, and the empirical safeguards observed in our experiments. We will also qualify the abstract claim to emphasize that physical consistency is validated empirically rather than guaranteed by theoretical bounds. revision: partial
Circularity Check
No circularity: standard learned energy model evaluated on external benchmarks
full rationale
The paper presents NEXUS as a modeling framework that represents objects via graphs, composes additive scalar energy terms for conservative effects and learned Rayleigh dissipation for non-conservative effects, derives forces by differentiation, and integrates via semi-implicit scheme. Claims of improved long-horizon accuracy rest on controlled trajectory benchmarks against learned and physics-structured baselines. No derivation step reduces to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no self-citation chain or uniqueness theorem is invoked to justify the formulation. The approach is a self-contained empirical modeling choice whose performance is assessed against independent test data.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned dissipation coefficients
axioms (2)
- domain assumption Forces can be obtained by differentiating scalar energy and dissipation functions
- domain assumption A multi-substep semi-implicit integrator preserves stability for the derived forces
invented entities (1)
-
neural energy fields on contact graphs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc., 2020
2020
-
[2]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling.arXiv e-prints, page arXiv:2210.02747, October 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Autoregressive Models in Vision: A Survey.arXiv e-prints, page arXiv:2411.05902, November 2024
Jing Xiong, Gongye Liu, Lun Huang, Chengyue Wu, Taiqiang Wu, Yao Mu, Yuan Yao, Hui Shen, Zhongwei Wan, Jinfa Huang, Chaofan Tao, Shen Yan, Huaxiu Yao, Lingpeng Kong, Hongxia Yang, Mi Zhang, Guillermo Sapiro, Jiebo Luo, Ping Luo, and Ngai Wong. Autoregressive Models in Vision: A Survey.arXiv e-prints, page arXiv:2411.05902, November 2024
-
[4]
Sora 2 video generator, 2024
OpenAI. Sora 2 video generator, 2024. Accessed: 2026-05-02
2024
-
[5]
World and human action models towards gameplay ideation.Nature, 638(8051):656–663, 2025
Anssi Kanervisto, Dave Bignell, and Katja Hofmann. World and human action models towards gameplay ideation.Nature, 638(8051):656–663, 2025
2025
-
[6]
Video models are zero-shot learners and reasoners
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners.arXiv e-prints, page arXiv:2509.20328, September 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
arXiv preprint arXiv:2601.03782 (2026)
Wenlong Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei-Fei. PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation.arXiv e-prints, page arXiv:2601.03782, January 2026
-
[8]
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, and Pieter Abbeel. DayDreamer: World Models for Physical Robot Learning.arXiv e-prints, page arXiv:2206.14176, June 2022
-
[9]
Michael McCabe, Payel Mukhopadhyay, Tanya Marwah, Bruno Regaldo-Saint Blancard, Francois Rozet, Cristiana Diaconu, Lucas Meyer, Kaze W. K. Wong, Hadi Sotoudeh, Alberto Bietti, Irina Espejo, Rio Fear, Siavash Golkar, Tom Hehir, Keiya Hirashima, Geraud Krawezik, Francois Lanusse, Rudy Morel, Ruben Ohana, Liam Parker, Mariel Pettee, Jeff Shen, Kyunghyun Cho,...
-
[10]
ProPhy: Progressive Physical Alignment for Dynamic World Simulation
Zijun Wang, Panwen Hu, Jing Wang, Terry Jingchen Zhang, Yuhao Cheng, Long Chen, Yiqiang Yan, Zutao Jiang, Hanhui Li, and Xiaodan Liang. ProPhy: Progressive Physical Alignment for Dynamic World Simulation.arXiv e-prints, page arXiv:2512.05564, December 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Qiyuan Zhang, Biao Gong, Shuai Tan, Zheng Zhang, Yujun Shen, Xing Zhu, Yuyuan Li, Kelu Yao, Chunhua Shen, and Changqing Zou. PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models.arXiv e-prints, page arXiv:2601.11087, January 2026
-
[12]
Physgen3d: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. Physgen3d: Crafting a miniature interactive world from a single image. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6178–6189, 2025
2025
-
[13]
Xiangyu Bai, He Liang, Bishoy Galoaa, Utsav Nandi, Shayda Moezzi, Yuhang He, and Sarah Ostadabbas. MoReGen: Multi-Agent Motion-Reasoning Engine for Code-based Text-to-Video Synthesis.arXiv e-prints, page arXiv:2512.04221, December 2025. 11
- [14]
-
[15]
Physgaussian: Physics-integrated 3d gaussians for generative dynamics
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics-integrated 3d gaussians for generative dynamics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4389–4398, 2024
2024
-
[16]
Physdreamer: Physics-based interaction with 3d objects via video generation
Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T Freeman. Physdreamer: Physics-based interaction with 3d objects via video generation. In European Conference on Computer Vision, pages 388–406. Springer, 2024
2024
-
[17]
Phystwin: Physics-informed reconstruction and simulation of deformable objects from videos.ICCV, 2025
Hanxiao Jiang, Hao-Yu Hsu, Kaifeng Zhang, Hsin-Ni Yu, Shenlong Wang, and Yunzhu Li. Phystwin: Physics-informed reconstruction and simulation of deformable objects from videos.ICCV, 2025
2025
-
[18]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. PhysCtrl: Generative Physics for Controllable and Physics-Grounded Video Generation.arXiv e-prints, page arXiv:2509.20358, September 2025
-
[19]
Minh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras. What about gravity in video generation? post-training newton’s laws with verifiable rewards.arXiv preprint arXiv:2512.00425, 2025
-
[20]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Sam Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian Neural Networks.arXiv e-prints, page arXiv:1906.01563, June 2019
-
[21]
Extending lagrangian and hamiltonian neural networks with differentiable contact models.Advances in Neural Information Processing Systems, 34:21910–21922, 2021
Yaofeng Desmond Zhong, Biswadip Dey, and Amit Chakraborty. Extending lagrangian and hamiltonian neural networks with differentiable contact models.Advances in Neural Information Processing Systems, 34:21910–21922, 2021
2021
-
[22]
Denoising hamiltonian network for physical reasoning.arXiv preprint arXiv:2503.07596, 2025
Congyue Deng, Brandon Y Feng, Cecilia Garraffo, Alan Garbarz, Robin Walters, William T Freeman, Leonidas Guibas, and Kaiming He. Denoising hamiltonian network for physical reasoning.arXiv preprint arXiv:2503.07596, 2025
-
[23]
Generative image dynamics
Zhengqi Li, Richard Tucker, Noah Snavely, and Aleksander Holynski. Generative image dynamics. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24142–24153, 2024
2024
-
[24]
Vlipp: Towards physically plausible video generation with vision and language informed physical prior
Xindi Yang, Baolu Li, Yiming Zhang, Zhenfei Yin, Lei Bai, Liqian Ma, Zhiyong Wang, Jianfei Cai, Tien-Tsin Wong, Huchuan Lu, et al. Vlipp: Towards physically plausible video generation with vision and language informed physical prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12360–12370, 2025
2025
-
[25]
Wisa: World simulator assistant for physics-aware text-to-video generation
Jing Wang, Ao Ma, Ke Cao, Jun Zheng, Zhanjie Zhang, Jiasong Feng, Shanyuan Liu, Yuhang Ma, Bo Cheng, Dawei Leng, et al. Wisa: World simulator assistant for physics-aware text-to-video generation. arXiv preprint arXiv:2503.08153, 2025
-
[26]
Think before you diffuse: Llms-guided physics-aware video generation.arXiv e-prints, pages arXiv–2505, 2025
Ke Zhang, Cihan Xiao, Yiqun Mei, Jiacong Xu, and Vishal M Patel. Think before you diffuse: Llms-guided physics-aware video generation.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[27]
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. Videojam: Joint appearance-motion representations for enhanced motion generation in video models.arXiv preprint arXiv:2502.02492, 2025
-
[28]
Motion modes: What could happen next? InProceedings of the computer vision and pattern recognition conference, pages 2030–2039, 2025
Karran Pandey, Yannick Hold-Geoffroy, Matheus Gadelha, Niloy J Mitra, Karan Singh, and Paul Guerrero. Motion modes: What could happen next? InProceedings of the computer vision and pattern recognition conference, pages 2030–2039, 2025
2030
-
[29]
Tao Feng, Xianbing Zhao, Zhenhua Chen, Tien Tsin Wong, Hamid Rezatofighi, Gholamreza Haffari, and Lizhen Qu. Physics-grounded motion forecasting via equation discovery for trajectory-guided image-to- video generation.arXiv preprint arXiv:2507.06830, 2025
-
[30]
Physdiff: Physics-guided human motion diffusion model
Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, and Jan Kautz. Physdiff: Physics-guided human motion diffusion model. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16010–16021, October 2023
2023
-
[31]
Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning
Jiaxi Lv, Yi Huang, Mingfu Yan, Jiancheng Huang, Jianzhuang Liu, Yifan Liu, Yafei Wen, Xiaoxin Chen, and Shifeng Chen. Gpt4motion: Scripting physical motions in text-to-video generation via blender-oriented gpt planning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1430–1440, 2024. 12
2024
-
[32]
Physgen: Rigid-body physics- grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics- grounded image-to-video generation. InEuropean Conference on Computer Vision, pages 360–378. Springer, 2024
2024
-
[33]
Motioncraft: Physics-based zero-shot video generation.Advances in Neural Information Processing Systems, 37:123155– 123181, 2024
Antonio Montanaro, Luca Savant Aira, Emanuele Aiello, Diego Valsesia, and Enrico Magli. Motioncraft: Physics-based zero-shot video generation.Advances in Neural Information Processing Systems, 37:123155– 123181, 2024
2024
-
[34]
Physanimator: Physics-guided generative cartoon animation
Tianyi Xie, Yiwei Zhao, Ying Jiang, and Chenfanfu Jiang. Physanimator: Physics-guided generative cartoon animation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10793–10804, 2025
2025
-
[35]
Wonderplay: Dynamic 3d scene generation from a single image and actions
Zizhang Li, Hong-Xing Yu, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, and Jiajun Wu. Wonderplay: Dynamic 3d scene generation from a single image and actions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9080–9090, 2025
2025
-
[36]
PAC-neRF: Physics augmented continuum neural radiance fields for geometry-agnostic system identification
Xuan Li, Yi-Ling Qiao, Peter Yichen Chen, Krishna Murthy Jatavallabhula, Ming Lin, Chenfanfu Jiang, and Chuang Gan. PAC-neRF: Physics augmented continuum neural radiance fields for geometry-agnostic system identification. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[37]
Pie-nerf: Physics- based interactive elastodynamics with nerf
Yutao Feng, Yintong Shang, Xuan Li, Tianjia Shao, Chenfanfu Jiang, and Yin Yang. Pie-nerf: Physics- based interactive elastodynamics with nerf. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4450–4461, 2024
2024
-
[38]
Reconstruction and simulation of elastic objects with spring-mass 3d gaussians
Licheng Zhong, Hong-Xing Yu, Jiajun Wu, and Yunzhu Li. Reconstruction and simulation of elastic objects with spring-mass 3d gaussians. InEuropean Conference on Computer Vision, pages 407–423. Springer, 2024
2024
-
[39]
Dynamic 3d gaussian tracking for graph-based neural dynamics modeling
Mingtong Zhang, Kaifeng Zhang, and Yunzhu Li. Dynamic 3d gaussian tracking for graph-based neural dynamics modeling. In8th Annual Conference on Robot Learning, 2024
2024
-
[40]
Seeing the wind from a falling leaf
Zhiyuan Gao, Jiageng Mao, Hong-Xing Yu, Haozhe Lou, Emily Yue-ting Jia, Jernej Barbic, Jiajun Wu, and Yue Wang. Seeing the wind from a falling leaf. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[41]
Interaction networks for learning about objects, relations and physics.Advances in neural information processing systems, 29, 2016
Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, et al. Interaction networks for learning about objects, relations and physics.Advances in neural information processing systems, 29, 2016
2016
-
[42]
Learning Particle Dynamics for Manipulating Rigid Bodies, Deformable Objects, and Fluids
Yunzhu Li, Jiajun Wu, Russ Tedrake, Joshua B Tenenbaum, and Antonio Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids.arXiv preprint arXiv:1810.01566, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Learning to simulate complex physics with graph networks
Alvaro Sanchez-Gonzalez, Jonathan Godwin, Tobias Pfaff, Rex Ying, Jure Leskovec, and Peter Battaglia. Learning to simulate complex physics with graph networks. InInternational conference on machine learning, pages 8459–8468. PMLR, 2020
2020
-
[44]
In: International Conference on Learning Representations (ICLR) (2021)
Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, and Peter W Battaglia. Learning mesh-based simulation with graph networks.arXiv preprint arXiv:2010.03409, 2020
-
[45]
Object dynamics modeling with hierarchical point cloud-based representations
Chanho Kim and Li Fuxin. Object dynamics modeling with hierarchical point cloud-based representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20977– 20986, 2024
2024
-
[46]
La- grangian neural networks.arXiv preprint arXiv:2003.04630, 2020
Miles Cranmer, Sam Greydanus, Stephan Hoyer, Peter Battaglia, David Spergel, and Shirley Ho. La- grangian neural networks.arXiv preprint arXiv:2003.04630, 2020
-
[47]
Symplectic ode-net: Learning hamiltonian dynamics with control.arXiv preprint arXiv:1909.12077, 2019
Yaofeng Desmond Zhong, Biswadip Dey, and Amit Chakraborty. Symplectic ode-net: Learning hamiltonian dynamics with control.arXiv preprint arXiv:1909.12077, 2019
-
[48]
Simplifying hamiltonian and lagrangian neural networks via explicit constraints.Advances in neural information processing systems, 33:13880–13889, 2020
Marc Finzi, Ke Alexander Wang, and Andrew G Wilson. Simplifying hamiltonian and lagrangian neural networks via explicit constraints.Advances in neural information processing systems, 33:13880–13889, 2020
2020
-
[49]
Yaofeng Desmond Zhong, Biswadip Dey, and Amit Chakraborty. Dissipative symoden: Encoding hamiltonian dynamics with dissipation and control into deep learning.arXiv preprint arXiv:2002.08860, 2020. 13
-
[50]
Port- hamiltonian neural networks for learning explicit time-dependent dynamical systems.Physical Review E, 104(3):034312, 2021
Shaan A Desai, Marios Mattheakis, David Sondak, Pavlos Protopapas, and Stephen J Roberts. Port- hamiltonian neural networks for learning explicit time-dependent dynamical systems.Physical Review E, 104(3):034312, 2021
2021
-
[51]
Andrew Sosanya and Sam Greydanus. Dissipative hamiltonian neural networks: Learning dissipative and conservative dynamics separately.arXiv preprint arXiv:2201.10085, 2022
-
[52]
E (n) equivariant graph neural networks
Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. In International conference on machine learning, pages 9323–9332. PMLR, 2021
2021
-
[53]
Point transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. In Proceedings of the IEEE/CVF international conference on computer vision, pages 16259–16268, 2021
2021
-
[54]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations, volume 2025, pages 83048–83077, 2025
2025
-
[56]
Draganything: Motion control for anything using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for anything using entity representation. In European Conference on Computer Vision, pages 331–348. Springer, 2024
2024
-
[57]
Objctrl-2.5 d: Training-free object control with camera poses.International Journal of Computer Vision, 134(5):249, 2026
Zhouxia Wang, Yushi Lan, Shangchen Zhou, and Chen Change Loy. Objctrl-2.5 d: Training-free object control with camera poses.International Journal of Computer Vision, 134(5):249, 2026
2026
-
[58]
Veo, 2026
Google DeepMind. Veo, 2026. Accessed: 2026-05-06
2026
-
[59]
Objaverse-xl: A universe of 10m+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems, 36:35799–35813, 2023. 14 A Additional Implementation Details A.1 Dataset and Simulation Benchmark We...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.