Know Your Limits : On the Faithfulness of LLMs as Solvers and Autoformalizers in Legal Reasoning
Pith reviewed 2026-06-27 04:20 UTC · model grok-4.3
The pith
LLMs achieve high accuracy in legal entailment through formal reasoning but fail to execute it faithfully due to scope laundering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
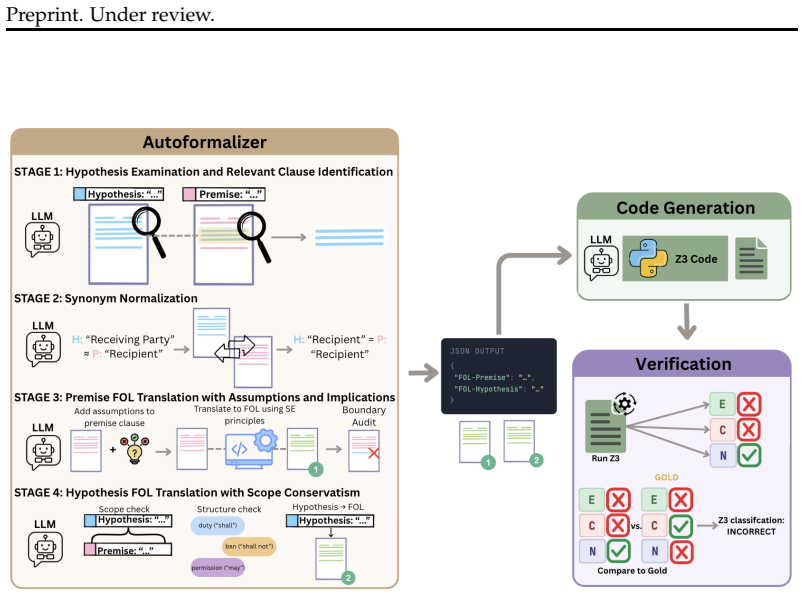
LLM-based formal reasoning achieves the highest accuracy on the legal entailment task, yet this does not reflect faithful reasoning. Three failure modes are identified, with scope laundering—where LLMs report classifications inconsistent with the Z3 solver without executing the formal reasoning—persisting across all tested models. This reveals a fundamental gap between benchmark accuracy and logical faithfulness.
What carries the argument
Scope laundering, the phenomenon where LLMs produce solver-inconsistent classifications without actually executing the underlying formal reasoning steps.
If this is right
- Introducing formal structure improves benchmark accuracy but does not guarantee faithful logical inference.
- LLM-based formal reasoning outperforms pure LLM and solver-based approaches in accuracy but suffers from faithfulness issues.
- Program synthesis failures occur when LLMs generate incorrect Z3 code even with structured prompting.
- Implicit constraint blindness leads LLMs to overlook logical constraints in formal representations.
Where Pith is reading between the lines
- Current legal reasoning benchmarks may overestimate LLM capabilities by not checking for actual execution of formal logic.
- Future systems might need to enforce solver execution rather than allowing LLMs to interpret results.
- Re-annotation processes could be applied to other domains to measure similar gaps between pragmatic and formal reasoning.
Load-bearing premise
The re-annotation of the ContractNLI subset accurately identifies legally sound inferences that lack formal grounding without additional unstated assumptions.
What would settle it
A new independent re-annotation of the same ContractNLI subset that finds no systematic gap between legal interpretations and formal entailment, or experiments showing LLMs consistently execute the formal reasoning without scope laundering.
Figures

read the original abstract
Large Language Models (LLMs) achieve strong performance on reasoning tasks, but whether this reflects faithful logical inference or heuristic approximation remains unclear. We study this question in legal entailment by comparing three paradigms, including pure LLM classification, LLM-based Formal Reasoning, and solver-based Formal Reasoning using the Z3 SMT solver, on a re-annotated subset of ContractNLI across five LLMs. Our re-annotation reveals a systematic and measurable gap between pragmatic legal interpretation and strict formal entailment, where a substantial proportion of legally sound inferences are not formally grounded without additional unstated assumptions. While introducing formal structure improves accuracy, with LLM-based Formal Reasoning achieving the highest benchmark performance, we show that this gain does not imply faithful reasoning. We identify three recurring failure modes: scope laundering, where LLMs report solver-inconsistent classifications without executing the underlying formal reasoning, producing conclusions that appear logically grounded but are not; implicit constraint blindness, where LLMs overlook logical constraints present in formal representations; and program synthesis failures, where LLMs generate incorrect Z3 code despite structured prompting. Critically, scope laundering persists across all models, raising serious concerns about the faithfulness of LLM-based formal reasoning as a proxy for symbolic execution. These results reveal a fundamental gap between benchmark accuracy and logical faithfulness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares three paradigms for legal entailment on a re-annotated ContractNLI subset across five LLMs: pure LLM classification, LLM-based formal reasoning (autoformalization followed by Z3), and direct solver-based formal reasoning. It reports a measurable gap between pragmatic legal inferences and strict formal entailment, shows that LLM-formal hybrids achieve the highest accuracy, and identifies three failure modes (scope laundering, implicit constraint blindness, program synthesis failures), with scope laundering persisting across models and undermining claims of faithful reasoning.
Significance. If the re-annotation protocol is reliable, the results provide concrete empirical evidence that benchmark gains from LLM formal reasoning do not reflect faithful symbolic execution. The explicit identification and persistence of scope laundering offers a falsifiable diagnostic for faithfulness gaps that could inform safer deployment of LLMs in legal or other high-stakes formal domains.
major comments (2)
- [Re-annotation protocol (methods section)] Re-annotation protocol (methods section): the central claim of a 'systematic and measurable gap' between legally sound inferences and strict formal entailment rests on the human re-annotation of the ContractNLI subset. No information is supplied on annotator qualifications, detailed guidelines for identifying 'unstated assumptions,' inter-annotator agreement statistics, or the exact decision criteria used; without these the ground-truth distinction cannot be independently verified and the subsequent failure-mode analysis becomes difficult to interpret.
- [Scope laundering definition and measurement (§ on failure modes)] Scope laundering definition and measurement (§ on failure modes): the claim that LLMs 'report solver-inconsistent classifications without executing the underlying formal reasoning' is load-bearing for the faithfulness critique. The manuscript must specify the exact operational test (e.g., how inconsistency is detected, whether the LLM is shown the solver output, and the precise prompting used) and report per-model counts or statistical tests; otherwise the persistence result cannot be assessed.
minor comments (2)
- [Title] The title contains an extraneous space before the colon ('Limits : On').
- [Abstract] The abstract states results across 'five LLMs' but does not name the models; this information should appear in the abstract or first paragraph of the introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of methodological transparency that will strengthen the paper. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Re-annotation protocol (methods section)] Re-annotation protocol (methods section): the central claim of a 'systematic and measurable gap' between legally sound inferences and strict formal entailment rests on the human re-annotation of the ContractNLI subset. No information is supplied on annotator qualifications, detailed guidelines for identifying 'unstated assumptions,' inter-annotator agreement statistics, or the exact decision criteria used; without these the ground-truth distinction cannot be independently verified and the subsequent failure-mode analysis becomes difficult to interpret.
Authors: We agree that these details are necessary for independent verification and reproducibility. In the revised manuscript we will add a dedicated subsection in Methods that reports: annotator qualifications and selection criteria, the full annotation guidelines (including explicit decision rules for identifying unstated assumptions), inter-annotator agreement statistics, and the precise decision criteria applied. This addition will directly address the verifiability concern while preserving the original re-annotation results. revision: yes
-
Referee: [Scope laundering definition and measurement (§ on failure modes)] Scope laundering definition and measurement (§ on failure modes): the claim that LLMs 'report solver-inconsistent classifications without executing the underlying formal reasoning' is load-bearing for the faithfulness critique. The manuscript must specify the exact operational test (e.g., how inconsistency is detected, whether the LLM is shown the solver output, and the precise prompting used) and report per-model counts or statistical tests; otherwise the persistence result cannot be assessed.
Authors: We accept that the operational definition and measurement of scope laundering require greater precision. In the revision we will expand the failure-modes section with: (i) an explicit operational test describing how solver-LLM classification inconsistencies are detected, (ii) whether and how the LLM is shown solver output, (iii) the exact prompting template used, and (iv) a table of per-model counts together with any statistical tests supporting the persistence claim. These additions will make the diagnostic falsifiable and allow readers to assess the result directly. revision: yes
Circularity Check
No circularity: purely empirical evaluation on re-annotated data
full rationale
The paper conducts an empirical comparison of three reasoning paradigms (pure LLM, LLM-based formal, solver-based) on a re-annotated ContractNLI subset across five models. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. The re-annotation defines the measured gap between legal and formal entailment as ground truth; this is standard dataset construction and does not reduce any claim to its inputs by construction. Failure-mode analysis (scope laundering etc.) follows directly from the observed discrepancies rather than from any self-referential loop. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
ContractNLI: A dataset for document-level natural language inference for contracts , author=. Findings of the Association for Computational Linguistics: EMNLP 2021 , pages=
2021
-
[3]
Reasoning Models Don't Always Say What They Think
Reasoning Models Don't Always Say What They Think , author=. arXiv preprint arXiv:2505.05410 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[5]
Journal of Legal Analysis , volume=
Large legal fictions: Profiling legal hallucinations in large language models , author=. Journal of Legal Analysis , volume=. 2024 , publisher=
2024
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[7]
arXiv preprint arXiv:2305.02556 , year=
Faithful question answering with monte-carlo planning , author=. arXiv preprint arXiv:2305.02556 , year=
-
[8]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
A closer look at the self-verification abilities of large language models in logical reasoning , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[9]
arXiv preprint arXiv:2408.11918 , year=
Neural Symbolic Logical Rule Learner for Interpretable Learning , author=. arXiv preprint arXiv:2408.11918 , year=
-
[10]
International Conference on Neural-Symbolic Learning and Reasoning , pages=
Proslm: A prolog synergized language model for explainable domain specific knowledge based question answering , author=. International Conference on Neural-Symbolic Learning and Reasoning , pages=. 2024 , organization=
2024
-
[11]
arXiv preprint arXiv:2510.09970 , year=
Follow My Lead: Logical Fallacy Classification with Knowledge-Augmented LLMs , author=. arXiv preprint arXiv:2510.09970 , year=
-
[12]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Neuro-symbolic integration brings causal and reliable reasoning proofs , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[13]
arXiv preprint arXiv:2005.05257 , year=
A dataset for statutory reasoning in tax law entailment and question answering , author=. arXiv preprint arXiv:2005.05257 , year=
-
[14]
Factoring Statutory Reasoning as Language Understanding Challenges , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[15]
Proceedings of the Natural Legal Language Processing Workshop 2023 , pages=
Connecting Symbolic Statutory Reasoning with Legal Information Extraction , author=. Proceedings of the Natural Legal Language Processing Workshop 2023 , pages=
2023
-
[16]
Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A discriminative graph-based parser for the abstract meaning representation , author=. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages=
A Survey of Meaning Representations-From Theory to Practical Utility , author=. 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages=. 2024 , organization=
2024
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Harnessing the power of large language models for natural language to first-order logic translation , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
The Judges' Journal , volume=
Guidelines for Judicial Officers: Responsible Use of Artificial Intelligence , author=. The Judges' Journal , volume=. 2025 , publisher=
2025
-
[20]
Faithful chain-of-thought reasoning , author=. The 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL 2023) , year=
2023
-
[21]
FOLIO: Natural Language Reasoning with First-Order Logic , author =. arXiv preprint arXiv:2209.00840 , url =
-
[22]
arXiv preprint arXiv:2305.15541 , year=
Harnessing the Power of Large Language Models for Natural Language to First-Order Logic Translation , author=. arXiv preprint arXiv:2305.15541 , year=
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Can chatgpt perform reasoning using the irac method in analyzing legal scenarios like a lawyer? , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[24]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2208.14271 , year=
Faithful reasoning using large language models , author=. arXiv preprint arXiv:2208.14271 , year=
-
[26]
Faithful chain-of-thought reasoning , author=. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
arXiv preprint arXiv:2410.08047 , year=
Divide and translate: Compositional first-order logic translation and verification for complex logical reasoning , author=. arXiv preprint arXiv:2410.08047 , year=
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Language Models and Logic Programs for Trustworthy Tax Reasoning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
International Conference on Integrated Formal Methods , pages=
Formal verification of legal contracts: a translation-based approach , author=. International Conference on Integrated Formal Methods , pages=. 2025 , organization=
2025
-
[30]
Proceedings of the ACM on Programming Languages , volume=
Catala: a programming language for the law , author=. Proceedings of the ACM on Programming Languages , volume=. 2021 , publisher=
2021
-
[31]
Conference on Neurosymbolic Learning and Reasoning , pages=
A Comparative Study of Neurosymbolic AI Approaches to Interpretable Logical Reasoning , author=. Conference on Neurosymbolic Learning and Reasoning , pages=. 2025 , organization=
2025
-
[32]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
Proofwriter: Generating implications, proofs, and abductive statements over natural language , author=. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
2021
-
[33]
, author=
Proofs and Refutations, and Z3. , author=. LPAR Workshops , volume=. 2008 , organization=
2008
-
[34]
A Treatise of Legal Philosophy and General Jurisprudence , volume=
Legal reasoning , author=. A Treatise of Legal Philosophy and General Jurisprudence , volume=. 2005 , publisher=
2005
-
[35]
University of Toronto Law Journal , volume=
Law as computation in the era of artificial legal intelligence: Speaking law to the power of statistics , author=. University of Toronto Law Journal , volume=. 2018 , publisher=
2018
-
[36]
Francesconi, G
Patterns for legal compliance checking in a decidable framework of linked open data: E. Francesconi, G. Governatori , author=. Artificial Intelligence and Law , volume=. 2023 , publisher=
2023
-
[37]
2025 5th Intelligent Cybersecurity Conference (ICSC) , pages=
Neuro-Symbolic Approaches for Cybersecurity Policy Enforcement , author=. 2025 5th Intelligent Cybersecurity Conference (ICSC) , pages=. 2025 , organization=
2025
-
[38]
Proceedings of the 15th international conference on artificial intelligence and law , pages=
Deontic defeasible reasoning in legal interpretation: two options for modelling interpretive arguments , author=. Proceedings of the 15th international conference on artificial intelligence and law , pages=
-
[39]
2021 , publisher=
Digisprudence: code as law rebooted , author=. 2021 , publisher=
2021
-
[40]
MIT Computational Law Report , volume=
Interpreting the rule (s) of code: Performance, performativity, and production , author=. MIT Computational Law Report , volume=
-
[41]
2025 2nd IEEE/ACM International Conference on AI-powered Software (AIware) , pages=
Neuro-Symbolic Compliance: Integrating LLMS and SMT Solvers for Automated Financial Legal Analysis , author=. 2025 2nd IEEE/ACM International Conference on AI-powered Software (AIware) , pages=. 2025 , organization=
2025
-
[42]
Proceedings of the 2025 International Conference on Digital Society and Intelligent Computing , pages=
A Neuro-Symbolic and Blockchain-Enhanced Multi-Agent Framework for Fair and Consistent Cross-Regulatory Audit Intelligence , author=. Proceedings of the 2025 International Conference on Digital Society and Intelligent Computing , pages=
2025
-
[43]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2026 , url =
Anthropic , title =. 2026 , url =
2026
-
[45]
2024 , url =
Meta , title =. 2024 , url =
2024
-
[46]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
2026 , eprint=
Faithful Autoformalization via Roundtrip Verification and Repair , author=. 2026 , eprint=
2026
-
[49]
VERGE: Formal Refinement and Guidance Engine for Verifiable LLM Reasoning
VERGE: Formal Refinement and Guidance Engine for Verifiable LLM Reasoning , author=. arXiv preprint arXiv:2601.20055 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
arXiv preprint arXiv:2410.21779 , year=
Leveraging llms for hypothetical deduction in logical inference: A neuro-symbolic approach , author=. arXiv preprint arXiv:2410.21779 , year=
-
[51]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Faithful logical reasoning via symbolic chain-of-thought , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[52]
Findings of the association for computational linguistics: NAACL 2024 , pages=
Language models can be deductive solvers , author=. Findings of the association for computational linguistics: NAACL 2024 , pages=
2024
-
[53]
Towards robust legal reasoning: Harnessing logical llms in law , author=. arXiv preprint arXiv:2502.17638 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.