Demystifying Training-Time Augmentation for Data-Constrained Language Model Pretraining
Pith reviewed 2026-06-27 03:51 UTC · model grok-4.3
The pith
Training-time data augmentations let autoregressive language models train productively for hundreds of epochs on fixed data by reducing overfitting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
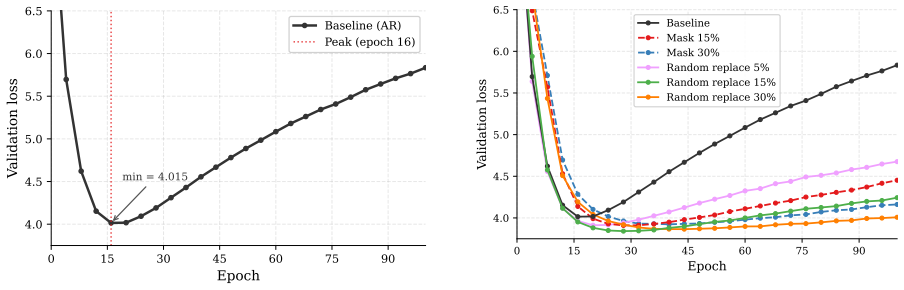
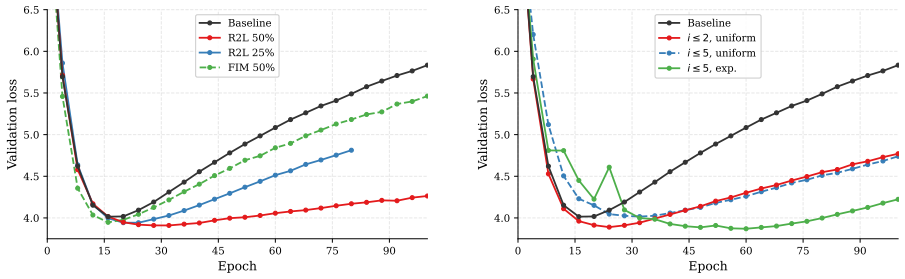
Data augmentations in the categories of token-level noise, sequence permutations, and target offset prediction delay overfitting during autoregressive pretraining, produce lower minimum validation loss than the unaugmented baseline, and thereby support productive multi-epoch training on a fixed corpus.
What carries the argument
Three orthogonal augmentation categories applied during autoregressive pretraining: token-level noise (masking or random replacement), sequence permutations (right-to-left or Fill-in-the-Middle), and target offset prediction (predicting x_{t+i} for i>1).
If this is right
- Random token replacement produces the lowest validation loss among the single augmentations tested.
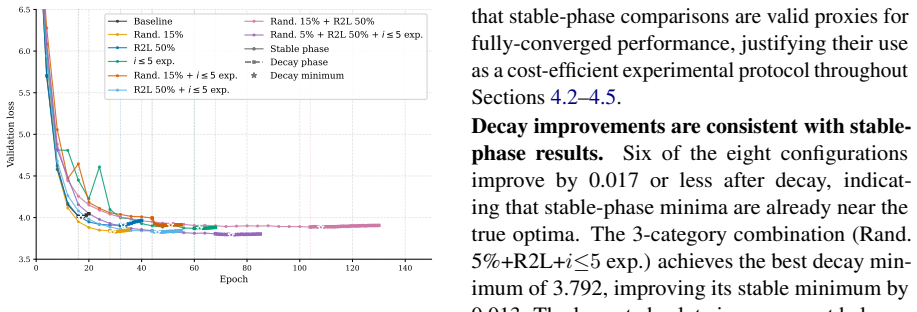
- Combining augmentations from different categories yields further reductions in minimum validation loss.
- Augmentations extend the number of useful training epochs on a fixed corpus from a handful to hundreds.
- The approach directly targets the data inefficiency of standard autoregressive pretraining.
Where Pith is reading between the lines
- If the validation-to-downstream translation holds, the same augmentation families could be applied to extend training horizons in other sequence modeling domains.
- The finding implies that data repetition can be made productive without collecting new text, shifting emphasis from data scale to training procedure.
- Future work could test whether the gains persist when the augmented models are evaluated on tasks that require exact reproduction of the original data distribution.
Load-bearing premise
Lower validation loss measured on the augmented training distribution will translate into better performance on downstream tasks or on held-out data drawn from the original unaugmented distribution.
What would settle it
A controlled run in which augmentation-trained models reach lower validation loss yet show equal or worse downstream task performance than the baseline would falsify the claim that these augmentations productively solve the data-constrained regime.
Figures



read the original abstract
As AI labs approach a data ceiling where compute capacity outpaces the rate of new high-quality text generation, language model pretraining is shifting toward a data-constrained, compute-abundant regime that demands productive multi-epoch training on fixed corpora. Standard autoregressive (AR) pretraining overfits severely in this setting, reaching its optimum early and then continuously deteriorating. We investigate training-time data augmentation as a regularizer to mitigate this overfitting and enable productive training for hundreds of epochs on the same data. We introduce three orthogonal categories of augmentation for AR pretraining: token-level noise (masking, random replacement), sequence permutations (right-to-left prediction, Fill-in-the-Middle), and target offset prediction ($x_{t+i}$ for $i > 1$). Through systematic ablations, we find that individual augmentations delay overfitting and lower validation loss relative to the baseline, with random token replacement achieving the best minimum loss among individual methods. Combining augmentation categories further lowers the minimum validation loss. Our experiments demonstrate that data augmentations mitigate AR pretraining's data inefficiency and offer a promising solution to the data-constrained regime~\footnote{All code and data are available at https://github.com/ michaelchen-lab/ data-augmentations-for-pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically investigates training-time data augmentations (token-level noise such as random replacement, sequence permutations including Fill-in-the-Middle, and target offset prediction) as a regularizer for autoregressive language model pretraining on fixed corpora. Systematic ablations show that individual augmentations delay overfitting and that combinations further reduce the minimum validation loss relative to the unaugmented baseline, supporting the claim that such methods enable productive multi-epoch training in data-constrained regimes.
Significance. If the minimum validation losses reflect improved modeling of the original data distribution, the work provides a practical, easily implemented regularization strategy for the emerging data-ceiling regime in LM pretraining. The open release of code and data is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Experimental results and validation procedure] The manuscript does not specify whether the validation set used to compute and report minimum loss receives the same augmentations applied during training. If the validation data is augmented, the observed loss reductions may arise from fitting the augmentation distribution rather than from better likelihoods on clean held-out sequences drawn from the original distribution; this distinction is load-bearing for the central claim that augmentations mitigate data inefficiency.
- [Methods and experimental setup] Key experimental details are missing, including model sizes, training dataset sizes, number of independent runs, statistical significance testing, and data exclusion criteria. Without these, it is impossible to evaluate whether the reported ablation trends are robust or subject to post-hoc selection.
minor comments (1)
- [Footnote 1] The GitHub URL in the footnote contains extraneous spaces ("https://github.com/ michaelchen-lab/ data-augmentations-for-pretraining"); this should be corrected for accessibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript to improve clarity on the validation procedure and experimental details.
read point-by-point responses
-
Referee: [Experimental results and validation procedure] The manuscript does not specify whether the validation set used to compute and report minimum loss receives the same augmentations applied during training. If the validation data is augmented, the observed loss reductions may arise from fitting the augmentation distribution rather than from better likelihoods on clean held-out sequences drawn from the original distribution; this distinction is load-bearing for the central claim that augmentations mitigate data inefficiency.
Authors: We confirm that validation loss is always computed on clean, unaugmented held-out sequences drawn from the original data distribution. This design choice ensures the reported minimum losses reflect improved modeling of the target distribution. We will add an explicit statement to this effect in the revised experimental results and validation procedure section. revision: yes
-
Referee: [Methods and experimental setup] Key experimental details are missing, including model sizes, training dataset sizes, number of independent runs, statistical significance testing, and data exclusion criteria. Without these, it is impossible to evaluate whether the reported ablation trends are robust or subject to post-hoc selection.
Authors: We acknowledge these details should be stated explicitly in the main text rather than relying solely on the code release. We will add a dedicated Experimental Setup subsection that reports model sizes, training dataset sizes, number of independent runs, data exclusion criteria, and a note on run-to-run consistency. Statistical significance testing was not performed, but we will report that trends held across all runs. revision: yes
Circularity Check
No circularity: empirical ablation study with independent experimental results
full rationale
The paper is a purely empirical ablation study reporting validation loss curves for various training-time augmentations (token replacement, permutations, target offsets) on autoregressive pretraining. No equations, derivations, or 'predictions' are presented that reduce by construction to author-defined inputs or fitted parameters. The central claim rests on observed minimum validation losses from systematic experiments, which are falsifiable against held-out data and do not invoke self-citation chains, uniqueness theorems, or ansatzes smuggled via prior work. The provided abstract and reader summary confirm absence of any load-bearing self-referential steps; self-citation (if present) is not used to justify core results. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Validation loss on the training distribution serves as a reliable indicator of productive multi-epoch training.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2001.08361 , year=
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[2]
arXiv preprint arXiv:2203.15556 , volume=
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , volume=
-
[3]
arXiv preprint arXiv:2211.04325 , volume=
Will we run out of data? an analysis of the limits of scaling datasets in machine learning , author=. arXiv preprint arXiv:2211.04325 , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Scaling data-constrained language models , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
arXiv preprint arXiv:2509.14786 , year=
Pre-training under infinite compute , author=. arXiv preprint arXiv:2509.14786 , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Diffusion beats autoregressive in data-constrained settings , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2511.03276 , year=
Diffusion language models are super data learners , author=. arXiv preprint arXiv:2511.03276 , year=
-
[8]
arXiv preprint arXiv:2205.05131 , year=
Ul2: Unifying language learning paradigms , author=. arXiv preprint arXiv:2205.05131 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Scaling laws and compute-optimal training beyond fixed training durations , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Advances in neural information processing systems , volume=
Xlnet: Generalized autoregressive pretraining for language understanding , author=. Advances in neural information processing systems , volume=
-
[11]
arXiv preprint arXiv:2207.14255 , year=
Efficient training of language models to fill in the middle , author=. arXiv preprint arXiv:2207.14255 , year=
-
[12]
arXiv preprint arXiv:2605.19407 , year=
A Bitter Lesson for Data Filtering , author=. arXiv preprint arXiv:2605.19407 , year=
-
[13]
Journal of big data , volume=
A survey on image data augmentation for deep learning , author=. Journal of big data , volume=. 2019 , publisher=
2019
-
[14]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[15]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[16]
Advances in Neural Information Processing Systems , volume=
Datacomp-lm: In search of the next generation of training sets for language models , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[18]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Theoretical benefit and limitation of diffusion language model , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2508.10875 , year=
A survey on diffusion language models , author=. arXiv preprint arXiv:2508.10875 , year=
-
[21]
arXiv preprint arXiv:2510.18480 , year=
How efficient are diffusion language models? a critical examination of efficiency evaluation practices , author=. arXiv preprint arXiv:2510.18480 , year=
-
[22]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[23]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[24]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[25]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[26]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[27]
, author=
Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning. , author=. AAAI spring symposium: logical formalizations of commonsense reasoning , pages=
-
[28]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Nemotron-cc: Transforming common crawl into a refined long-horizon pretraining dataset , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Dolma: An open corpus of three trillion tokens for language model pretraining research , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[31]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[32]
arXiv preprint arXiv:2002.05202 , year=
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
Pith/arXiv arXiv 2002
-
[33]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[34]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[35]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[36]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
To repeat or not to repeat: Insights from scaling llm under token-crisis , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Cutmix: Regularization strategy to train strong classifiers with localizable features , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[39]
arXiv preprint arXiv:1710.09412 , year=
mixup: Beyond empirical risk minimization , author=. arXiv preprint arXiv:1710.09412 , year=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
Randaugment: Practical automated data augmentation with a reduced search space , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
-
[41]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[42]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[43]
Advances in Neural Information Processing Systems , volume=
Meet in the middle: A new pre-training paradigm , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2205.10487 , year=
Scaling Laws and Interpretability of Learning from Repeated Data , author=. arXiv preprint arXiv:2205.10487 , year=
-
[45]
Advances in Neural Information Processing Systems , year=
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[46]
The Eleventh International Conference on Learning Representations (ICLR) , year=
Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning , author=. The Eleventh International Conference on Learning Representations (ICLR) , year=
-
[47]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[48]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Coherence Boosting: When Your Pretrained Language Model is Not Paying Enough Attention , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[49]
arXiv preprint arXiv:2511.07338 , year=
DeepPersona: A Generative Engine for Scaling Deep Synthetic Personas , author=. arXiv preprint arXiv:2511.07338 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.