From Compression to Deployment: Real-Time and Energy-Efficient FastGRNN on Ultra-Constrained Microcontrollers
Pith reviewed 2026-06-27 02:12 UTC · model grok-4.3
The pith
A 566-byte FastGRNN model delivers bit-equivalent real-time inference on Arduino and MSP430 microcontrollers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
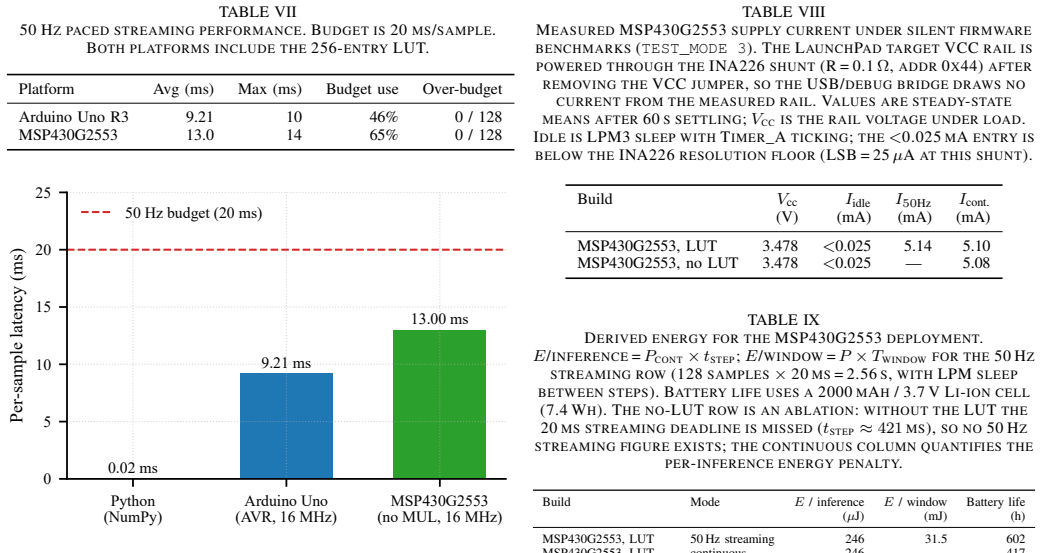
The compressed FastGRNN occupies 566 bytes of weights, achieves macro F1 of 0.918 on the HAPT test set, matches PyTorch predictions at 100 percent agreement across 3,399 windows, and supports real-time 50 Hz inference on both the 8-bit Arduino and 16-bit MSP430, where a 256-entry sigmoid/tanh look-up table delivers a 30.5x speedup on the multiplier-less platform.
What carries the argument
The compression pipeline of low-rank weight factorization, iterative hard-thresholding sparsity, and per-tensor Q15 post-training quantization with explicit activation calibration that produces deterministic cross-platform inference.
If this is right
- Bit-equivalent deterministic inference holds between the PyTorch reference and the bare-metal C code on both target platforms.
- Real-time 50 Hz streaming inference is sustained at 9.21 ms per sample on Arduino and 13 ms on MSP430.
- A 96.7 percent energy reduction is obtained with the 256-entry sigmoid/tanh look-up table on multiplier-less targets.
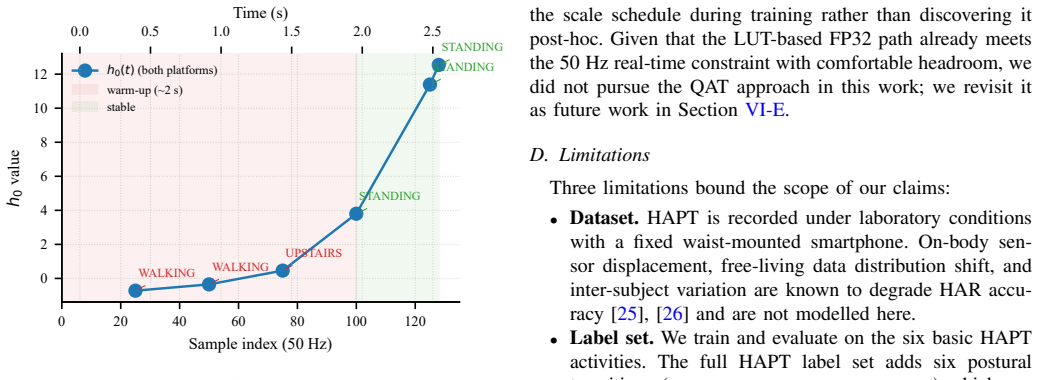
- Recurrent warm-up latency has a median of 74 samples and worst-case of 125 samples over 100 test windows.
Where Pith is reading between the lines
- The same compression steps could be applied to other small recurrent cells to enable deployment on similar constrained hardware.
- Always-on sensing applications in battery-powered devices become practical without offloading computation to the cloud.
- The lookup-table recipe for activation functions may reduce energy in other multiplier-less embedded computations.
Load-bearing premise
Per-tensor Q15 post-training quantization with explicit activation calibration preserves bit-equivalent behavior across the full test set without requiring dataset-specific retuning when moving from PyTorch to bare-metal C.
What would settle it
Any prediction disagreement between the MCU implementation and the PyTorch reference on the 3,399 HAPT test windows, or failure to achieve the reported 50 Hz inference rate or energy reduction with the lookup table.
Figures

read the original abstract
The dominant trajectory of modern machine learning has been to scale up: larger models, larger accelerators, larger memory budgets. Yet a multi-year global semiconductor supply constraint and the growing energy and carbon cost of always-online inference expose the fragility of this trajectory and motivate the opposite direction: refactoring AI and ML algorithms to fit the small, ubiquitous microcontrollers already in mass production in wearables, sensors, and edge appliances. We present an end-to-end open-source reproduction of FastGRNN, a compact gated recurrent cell, deployed on two bare-metal targets: the 8-bit Arduino (ATmega328P) and the 16-bit MSP430 (no hardware multiplier; 16 KB Flash; 512 B SRAM). Our compression pipeline combines low-rank weight factorization, iterative hard-thresholding sparsity, and per-tensor Q15 post-training quantization with explicit activation calibration. The deployed model occupies 566 bytes of weights and achieves macro F1 = 0.918 (seed 0; five-seed Q15 mean 0.853+-0.107) on the HAPT test set. It matches a PyTorch reference at 100% prediction agreement across 3,399 test windows (MCU seed 0; 99.91-100% C-equivalent across five seeds). Both platforms sustain real-time 50 Hz streaming inference (9.21 ms per sample on Arduino; 13 ms on MSP430), where a 256-entry sigmoid/tanh look-up table delivers a 30.5x speedup on the multiplier-less MSP430. Four contributions extend the original FastGRNN paper: (i) cross-platform bit-equivalent deterministic inference; (ii) characterization of recurrent warm-up latency (median 74 samples, 1.48 s; worst-case 125 samples, 2.50 s over 100 test windows); (iii) a deployable look-up-table recipe for multiplier-less embedded targets; and (iv) hardware energy characterization showing 17.7 mW active inference power, <0.09 mW idle power, and 96.7% energy reduction with the LUT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an end-to-end open-source reproduction of FastGRNN on two bare-metal MCUs (ATmega328P Arduino and multiplier-less MSP430), combining low-rank factorization, iterative hard-thresholding sparsity, and per-tensor Q15 post-training quantization with explicit activation calibration. The resulting 566-byte model achieves macro F1=0.918 (seed 0) on HAPT, 100% prediction agreement with a PyTorch reference across 3399 test windows, real-time 50 Hz streaming inference (9.21 ms/sample on Arduino, 13 ms on MSP430), and 96.7% energy reduction via a 256-entry sigmoid/tanh LUT, plus characterizations of warm-up latency and power.
Significance. If the results hold, the work supplies direct hardware evidence that compact gated RNNs can be deployed with bit-equivalent deterministic inference on ultra-constrained devices already in mass production, including concrete timing, energy (17.7 mW active, <0.09 mW idle), and latency figures. The empirical 100% cross-platform agreement and open-source pipeline are concrete strengths that extend the original FastGRNN paper.
major comments (1)
- [Abstract / compression pipeline] Abstract / compression pipeline: the headline claim of cross-platform bit-equivalent deterministic inference (contribution i) and the 100% prediction agreement across 3399 windows rest on per-tensor Q15 post-training quantization with explicit activation calibration producing identical fixed-point results in bare-metal C. No calibration offsets or ranges are released, and recurrent state accumulation over variable-length windows plus the reported seed-dependent F1 variance of ±0.107 leave open whether the match is robust or seed/dataset-specific; this directly affects reproducibility of the central deployment claim.
minor comments (1)
- [Abstract] The four enumerated contributions in the abstract would be clearer if each were explicitly mapped to the section or figure that demonstrates it.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, recognition of the empirical strengths, and recommendation for minor revision. The feedback on reproducibility is constructive and we address it directly below.
read point-by-point responses
-
Referee: [Abstract / compression pipeline] Abstract / compression pipeline: the headline claim of cross-platform bit-equivalent deterministic inference (contribution i) and the 100% prediction agreement across 3399 windows rest on per-tensor Q15 post-training quantization with explicit activation calibration producing identical fixed-point results in bare-metal C. No calibration offsets or ranges are released, and recurrent state accumulation over variable-length windows plus the reported seed-dependent F1 variance of ±0.107 leave open whether the match is robust or seed/dataset-specific; this directly affects reproducibility of the central deployment claim.
Authors: We agree that tabulating the calibration parameters improves reproducibility and will add them. The open-source repository already contains the complete calibration and quantization scripts; the per-tensor ranges and offsets were simply not extracted into a table in the manuscript. In revision we will insert a supplementary table listing the explicit min/max ranges and zero-points used for every weight and activation tensor. On robustness: the 100 % agreement is reported for the exact seed-0 model that was compiled and run on both MCUs; across the five seeds the C-equivalent agreement stays between 99.91 % and 100 %. Because the bare-metal implementation uses deterministic fixed-point arithmetic with no floating-point rounding, once the recurrent state is initialized the output sequence is identical regardless of window length. The warm-up latency measurements already quantify the effect of variable-length state accumulation. These additions and clarifications directly address the reproducibility concern. revision: yes
Circularity Check
No circularity; results are direct empirical measurements against external reference
full rationale
The manuscript presents an engineering reproduction and bare-metal deployment of FastGRNN. All headline claims (566-byte model, macro F1 scores, 100% prediction agreement across 3399 windows, latency, energy numbers) are obtained by direct hardware execution and comparison to an independent PyTorch reference implementation. No equations, fitted parameters, or predictions are defined such that any reported quantity reduces to its own inputs by construction. The compression steps (low-rank factorization, hard-thresholding, per-tensor Q15 quantization) are standard techniques whose outputs are validated externally rather than asserted by definition. No self-citation chain or uniqueness theorem is invoked as load-bearing justification. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- low-rank factor dimensions
- hard-thresholding sparsity level
- Q15 activation calibration offsets
axioms (2)
- standard math Matrix multiplication and element-wise operations are associative and distributive over the chosen number format.
- domain assumption The HAPT activity recognition task distribution is representative of real-world sensor streams on the target hardware.
Reference graph
Works this paper leans on
-
[1]
Coping with the auto- semiconductor shortage: Strategies for success,
O. Burkacky, S. Lingemann, and K. Pototzky, “Coping with the auto- semiconductor shortage: Strategies for success,” McKinsey & Company, 2022, https://www.mckinsey.com/industries/automotive-and-assembly/ our-insights
2022
-
[2]
The semiconductor supply chain: Assessing national competitiveness,
S. M. Khan, A. Mann, and D. Peterson, “The semiconductor supply chain: Assessing national competitiveness,” Center for Security and Emerging Technology (CSET), Georgetown University, Tech. Rep., 2021
2021
-
[3]
Energy and policy consider- ations for deep learning in NLP,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consider- ations for deep learning in NLP,” inAnnual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[4]
Carbon Emissions and Large Neural Network Training
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, “Carbon emissions and large neural network training,”arXiv preprint arXiv:2104.10350, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
FastGRNN: A fast, accurate, stable and tiny kilobyte sized gated recurrent neural network,
A. Kusupati, M. Singh, K. Bhatia, A. Kumar, P. Jain, and M. Varma, “FastGRNN: A fast, accurate, stable and tiny kilobyte sized gated recurrent neural network,” inAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[6]
MLPerf tiny bench- mark,
C. Banbury, V . J. Reddi, P. Torelli, J. Holleman, N. Jeffries, C. Kiraly, P. Montino, D. Kanter, S. Ahmed, D. Pauet al., “MLPerf tiny bench- mark,” inConference on Machine Learning and Systems (MLSys), 2021
2021
-
[7]
CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs
L. Lai, N. Suda, and V . Chandra, “CMSIS-NN: Efficient neural network kernels for ARM Cortex-M CPUs,” inarXiv preprint arXiv:1801.06601, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
TensorFlow Lite Micro: Embedded machine learning for TinyML systems,
R. David, J. Duke, A. Jain, V . Janapa Reddi, N. Jeffries, J. Li, N. Kreeger, I. Nappier, M. Natraj, S. Regevet al., “TensorFlow Lite Micro: Embedded machine learning for TinyML systems,”Conference on Machine Learning and Systems (MLSys), 2021
2021
-
[9]
MCUNet: Tiny deep learning on IoT devices,
J. Lin, W.-M. Chen, Y . Lin, J. Cohn, C. Gan, and S. Han, “MCUNet: Tiny deep learning on IoT devices,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[10]
A public domain dataset for human activity recognition using smartphones,
D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. L. Reyes-Ortiz, “A public domain dataset for human activity recognition using smartphones,” in European Symposium on Artificial Neural Networks (ESANN), 2013
2013
-
[11]
Transition-aware human activity recognition using smartphones,
J.-L. Reyes-Ortiz, L. Oneto, A. Samà, X. Parra, and D. Anguita, “Transition-aware human activity recognition using smartphones,”Neu- rocomputing, vol. 171, pp. 754–767, 2016
2016
-
[12]
Iterative hard thresholding for compressed sensing,
T. Blumensath and M. E. Davies, “Iterative hard thresholding for compressed sensing,”Applied and Computational Harmonic Analysis, vol. 27, no. 3, pp. 265–274, 2009
2009
-
[13]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[14]
Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman cod- ing,
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman cod- ing,” inInternational Conference on Learning Representations (ICLR), 2016
2016
-
[15]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[16]
Learning phrase representations using RNN encoder-decoder for statistical machine translation,
K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” inConference on Empirical Methods in Natural Language Processing (EMNLP), 2014
2014
-
[17]
Resource-efficient machine learn- ing in 2 KB RAM for the internet of things,
A. Kumar, S. Goyal, and M. Varma, “Resource-efficient machine learn- ing in 2 KB RAM for the internet of things,” inInternational Conference on Machine Learning (ICML), 2017
2017
-
[18]
ProtoNN: Com- pressed and accurate kNN for resource-scarce devices,
C. Gupta, A. S. Suggala, A. Goyal, H. V . Simhadri, B. Paranjape, A. Kumar, S. Goyal, R. Udupa, M. Varma, and P. Jain, “ProtoNN: Com- pressed and accurate kNN for resource-scarce devices,” inInternational Conference on Machine Learning (ICML), 2017
2017
-
[19]
EdgeML: Machine learning for resource- constrained edge devices,
Microsoft Research India, “EdgeML: Machine learning for resource- constrained edge devices,” 2017–2024, https://github.com/microsoft/ EdgeML
2017
-
[20]
Quantized neural networks: Training neural networks with low preci- sion weights and activations,
I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y . Bengio, “Quantized neural networks: Training neural networks with low preci- sion weights and activations,”Journal of Machine Learning Research, vol. 18, pp. 1–30, 2017
2017
-
[21]
Learning both weights and connections for efficient neural networks,
S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
-
[22]
The lottery ticket hypothesis: Finding sparse, trainable neural networks,
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” inInternational Conference on Learning Representations (ICLR), 2019
2019
-
[23]
CMix-NN: Mixed low-precision CNN library for memory-constrained edge devices,
A. Capotondi, M. Rusci, M. Fariselli, and L. Benini, “CMix-NN: Mixed low-precision CNN library for memory-constrained edge devices,”IEEE Transactions on Circuits and Systems II, 2020
2020
-
[24]
Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,
F. J. Ordóñez and D. Roggen, “Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition,”Sensors, vol. 16, no. 1, 2016
2016
-
[25]
Deep learning for sensor- based activity recognition: A survey,
J. Wang, Y . Chen, S. Hao, X. Peng, and L. Hu, “Deep learning for sensor- based activity recognition: A survey,”Pattern Recognition Letters, vol. 119, pp. 3–11, 2019
2019
-
[26]
Human activity recognition using inertial, physiological and environmental sensors: A comprehensive survey,
F. Demrozi, G. Pravadelli, A. Bihorac, and P. Rashidi, “Human activity recognition using inertial, physiological and environmental sensors: A comprehensive survey,”IEEE Access, vol. 8, pp. 210 816–210 836, 2020
2020
-
[27]
MSP430x2xx family user’s guide (slau144j),
Texas Instruments, “MSP430x2xx family user’s guide (slau144j),” 2013, https://www.ti.com/lit/ug/slau144j/slau144j.pdf. APPENDIXA HYPERPARAMETERS Table X lists the full hyperparameter set used to produce the deployed model. All values are unchanged across the five training seeds. APPENDIXB Q15 QUANTIZATIONIMPLEMENTATION The per-tensor Q15 quantization step...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.