Translating the Untranslatable: An Operationalizable Ontology for Untranslatability
Pith reviewed 2026-06-27 02:49 UTC · model grok-4.3
The pith
A structured ontology of untranslatability plus a taxonomy of compensation strategies lets researchers build and test a dataset of cases where direct translation fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
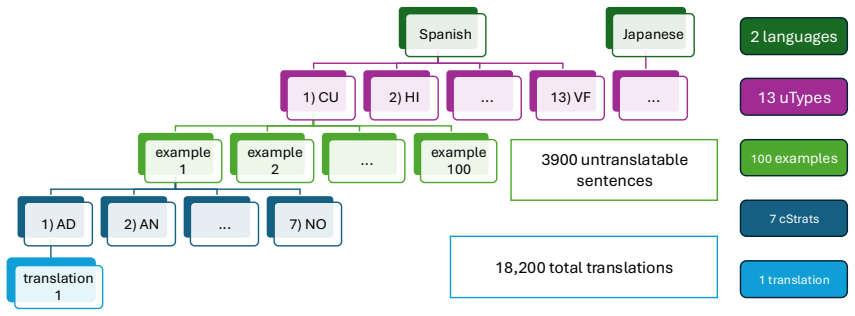
We introduce a structured ontology of untranslatability along with a taxonomy of compensation strategies, which are specific techniques to convey meaning under these untranslatable circumstances. We operationalize this framework into a multilingual dataset of untranslatable sentences paired with strategy-based translations, enabling controlled analysis of translation behavior. Initial human preference studies suggest that translation quality depends on the strategy used, with consistent preferences for outputs that include explanatory context, known as the Annotation compensation strategy.
What carries the argument
Ontology of untranslatability paired with taxonomy of compensation strategies, turned into a dataset of paired sentences for controlled comparison.
If this is right
- Machine translation evaluation can move from aggregate BLEU or COMET scores to per-strategy performance on untranslatable inputs.
- Systems could be fine-tuned to detect untranslatability type and then select an appropriate compensation method.
- The dataset supplies training signals for models that output not only a translation but also the strategy it employed.
- Cross-lingual consistency of human preferences can be measured by applying the same taxonomy to new language pairs.
Where Pith is reading between the lines
- The same categories could be used to audit existing MT outputs for over-reliance on literal renderings that lose key meaning.
- Literary or legal translation workflows might adopt the taxonomy to decide when to add annotation versus other adjustments.
- If Annotation remains preferred, MT interfaces could surface explanatory notes automatically rather than forcing a single target sentence.
Load-bearing premise
The chosen ontology and taxonomy categories are assumed to be sufficiently complete and non-overlapping to support controlled analysis and generalizable human preference findings across languages.
What would settle it
A follow-up study in which raters show no reliable preference differences across the listed strategies or in which many real sentences fit multiple taxonomy categories equally well.
Figures









read the original abstract
Untranslatability, cases where meaning cannot be directly preserved across languages, is well-studied in linguistics but underexplored in NLP. As machine translation (MT) systems improve on standard benchmarks, their limitations increasingly concentrate in such cases, where translation cannot be reduced to one-to-one equivalence. We introduce a structured ontology of untranslatability along with a taxonomy of compensation strategies, which are specific techniques to convey meaning under these untranslatable circumstances. We operationalize this framework into a multilingual dataset of untranslatable sentences paired with strategy-based translations, enabling controlled analysis of translation behavior. Initial human preference studies suggest that translation quality depends on the strategy used, with consistent preferences for outputs that include explanatory context, known as the Annotation compensation strategy. Our framework and dataset provide a foundation for studying and modeling strategy-informed machine translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a structured ontology of untranslatability along with a taxonomy of compensation strategies. It operationalizes the framework into a multilingual dataset of untranslatable sentences paired with strategy-based translations, enabling controlled analysis of translation behavior. Initial human preference studies are reported to indicate that translation quality depends on the strategy used, with consistent preferences for the Annotation compensation strategy that includes explanatory context. The work positions the ontology, taxonomy, and dataset as a foundation for studying and modeling strategy-informed machine translation.
Significance. If the ontology proves comprehensive and the preference findings generalize, the work could meaningfully advance MT research by shifting focus from standard equivalence benchmarks to structured handling of untranslatable cases. The operationalization into a dataset is a positive step toward falsifiable, controlled experiments in the area.
major comments (2)
- The abstract states that the ontology and taxonomy 'enable controlled analysis' and support 'generalizable human preference findings,' yet provides no validation of category completeness or disjointness (e.g., coverage against established linguistic inventories of untranslatability or quantitative overlap metrics). This assumption is load-bearing for the central claim that the framework supports controlled analysis rather than artifactual results from dataset partitioning.
- [Abstract] The abstract reports that 'initial human preference studies suggest' a consistent preference for the Annotation strategy but supplies no dataset size, number of annotators, inter-annotator agreement, error bars, statistical tests, or baseline comparisons. These omissions prevent evaluation of whether the preference result is robust enough to support the operationalization claim.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the number of languages or language families covered by the multilingual dataset.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the abstract's claims and the need for more rigorous reporting. We address each major comment below and commit to revisions that strengthen the manuscript without overstating current results.
read point-by-point responses
-
Referee: The abstract states that the ontology and taxonomy 'enable controlled analysis' and support 'generalizable human preference findings,' yet provides no validation of category completeness or disjointness (e.g., coverage against established linguistic inventories of untranslatability or quantitative overlap metrics). This assumption is load-bearing for the central claim that the framework supports controlled analysis rather than artifactual results from dataset partitioning.
Authors: We agree this is a substantive point. The ontology was constructed through a systematic review of linguistic literature on untranslatability phenomena, with categories intended to be mutually exclusive and exhaustive based on that synthesis. However, the manuscript does not include quantitative validation such as overlap metrics or coverage against all established inventories. We will revise the abstract to moderate the language around 'controlled analysis' and 'generalizable findings,' add an explicit limitations subsection discussing potential gaps or overlaps, and include a brief qualitative mapping to key linguistic references to better ground the framework. revision: yes
-
Referee: [Abstract] The abstract reports that 'initial human preference studies suggest' a consistent preference for the Annotation strategy but supplies no dataset size, number of annotators, inter-annotator agreement, error bars, statistical tests, or baseline comparisons. These omissions prevent evaluation of whether the preference result is robust enough to support the operationalization claim.
Authors: The full manuscript reports the human preference study details (including sentence counts, annotator numbers, agreement metrics, and statistical comparisons) in the experiments section. We acknowledge that the abstract is overly concise and omits these elements, which weakens the summary of the operationalization claim. We will revise the abstract to incorporate key quantitative details such as study scale and agreement levels while remaining within length constraints. revision: yes
Circularity Check
New ontology and taxonomy presented as explicit construction with no derivation chain or self-citation reduction
full rationale
The paper introduces its ontology of untranslatability and taxonomy of compensation strategies as a new framework ('We introduce a structured ontology... along with a taxonomy... We operationalize this framework into a multilingual dataset'). No equations, fitted parameters, or predictions are described. No load-bearing self-citations or uniqueness theorems from prior author work are invoked to justify the categories. The construction is self-contained against external benchmarks in the sense that it does not claim to derive its categories from data fits or prior results that would reduce by construction. This matches the expected non-circular case for a definitional framework paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Untranslatability admits a finite, non-overlapping taxonomy of types and compensation strategies that can be operationalized into sentence-level annotations.
Reference graph
Works this paper leans on
-
[1]
Machine Translation Robustness to Natural Asemantic Variation
Bremerman, Jacob and Ren, Xiang and May, Jonathan. Machine Translation Robustness to Natural Asemantic Variation. 2022. doi:10.18653/v1/2022.emnlp-main.230
-
[2]
Untranslatability and the Method of Compensation
Jingjing Cui. Untranslatability and the Method of Compensation. Theory and Practice in Language Studies, Vol. 2, No. 4. 2012
2012
-
[3]
(Un)translatability of a text: a blessing in disguise? The case of Spanish, English and Polish
Puchała-Ladzińska, Karolina. (Un)translatability of a text: a blessing in disguise? The case of Spanish, English and Polish. Studia Anglica Resoviensia T. 20. 2023
2023
-
[4]
Translation Journal , volume=
Cultural untranslatability , author=. Translation Journal , volume=
-
[5]
Humanities science current issues , volume=
The problem of untranslatability: challenges and strategies for solving translation difficulties , author=. Humanities science current issues , volume=
-
[6]
Detecting the Untranslatable Colloquial Expressions of J apanese Verbs in Cross-Language Instant Messaging
Cheng, Yuchang and Fuji, Masaru and Nagase, Tomoki and Uegaki, Minoru and Okada, Isaac. Detecting the Untranslatable Colloquial Expressions of J apanese Verbs in Cross-Language Instant Messaging. Proceedings of the 28th Pacific Asia Conference on Language, Information and Computing. 2014
2014
-
[7]
Ghazvininejad, Marjan and Choi, Yejin and Knight, Kevin. Neural Poetry Translation. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2011
-
[8]
Examining the Tip of the Iceberg: A Data Set for Idiom Translation
Fadaee, Marzieh and Bisazza, Arianna and Monz, Christof. Examining the Tip of the Iceberg: A Data Set for Idiom Translation. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[9]
Controlling Politeness in Neural Machine Translation via Side Constraints
Sennrich, Rico and Haddow, Barry and Birch, Alexandra. Controlling Politeness in Neural Machine Translation via Side Constraints. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016. doi:10.18653/v1/N16-1005
-
[10]
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Zhu, Wenhao and Liu, Hongyi and Dong, Qingxiu and Xu, Jingjing and Huang, Shujian and Kong, Lingpeng and Chen, Jiajun and Li, Lei. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.176
-
[11]
Synthetic Dialogue Dataset Generation using LLM Agents
Abdullin, Yelaman and Molla, Diego and Ofoghi, Bahadorreza and Yearwood, John and Li, Qingyang. Synthetic Dialogue Dataset Generation using LLM Agents. Proceedings of the Third Workshop on Natural Language Generation, Evaluation, and Metrics (GEM). 2023
2023
-
[12]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[13]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[14]
Annual Meeting of the Association for Computational Linguistics , year=
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[15]
Khanuja, Simran and Ramamoorthy, Sathyanarayanan and Song, Yueqi and Neubig, Graham. An image speaks a thousand words, but can everyone listen? On image transcreation for cultural relevance. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.573
-
[16]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[17]
Field, Andy P. , publisher =. Kendall's Coefficient of Concordance , booktitle =. doi:https://doi.org/10.1002/0470013192.bsa327 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/0470013192.bsa327 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.