A Closer Look at Failure Modes in Temporal Understanding of Large Audio-Language Models
Pith reviewed 2026-06-26 23:23 UTC · model grok-4.3
The pith
Scaling attention at bottleneck layers improves large audio-language models' temporal reasoning accuracy from 55.9% to 59.1% without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
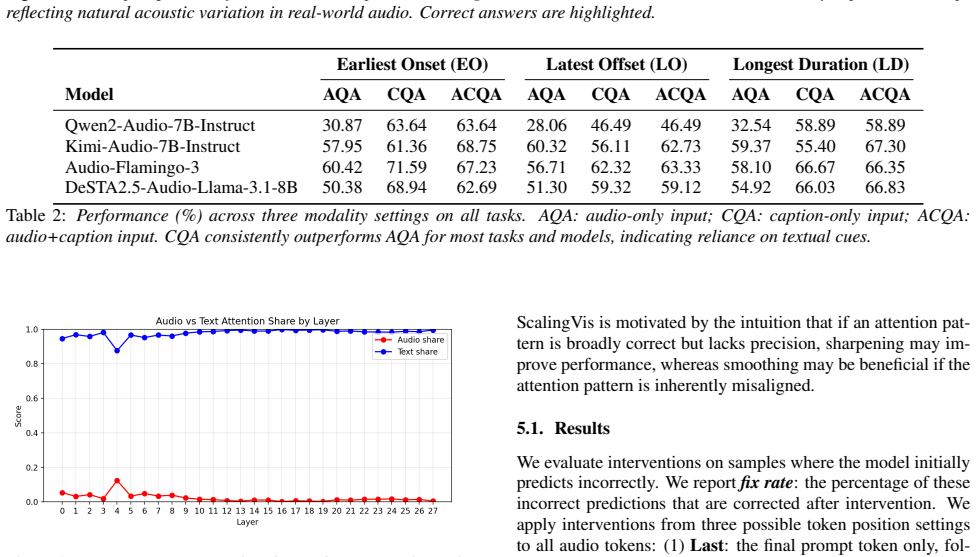
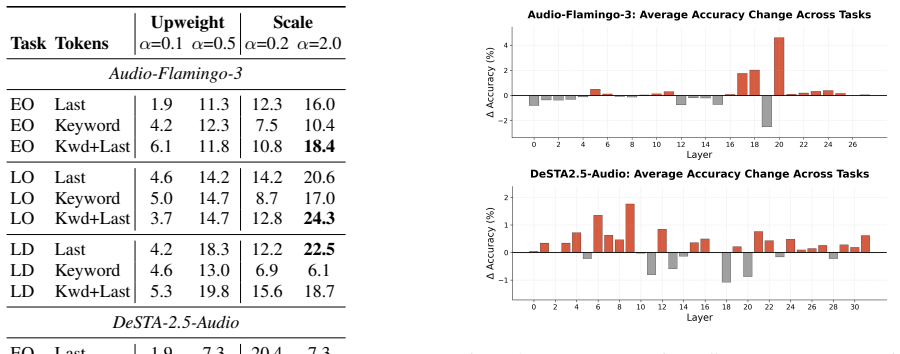
The authors establish that temporal reasoning failures in large audio-language models arise because models under-utilize audio when textual cues are available, and that redistributing attention across audio tokens is more effective than increasing audio attention. Targeting task-relevant tokens adds further gains. Attention scaling at bottleneck layers raises accuracy from 55.9% to 59.1% on the new benchmark without fine-tuning, showing that modality imbalance alone does not explain the failures.
What carries the argument
Attention scaling at bottleneck layers, which redistributes attention weights across audio tokens to emphasize task-relevant information.
If this is right
- Models often under-utilize audio when textual cues are available.
- Redistributing attention across audio tokens is more effective than increasing audio attention.
- Targeting task-relevant tokens yields further gains.
- Modality imbalance alone cannot explain failures.
Where Pith is reading between the lines
- Attention adjustments at specific layers might improve reasoning in other multimodal settings such as video or speech.
- The benchmark could be adapted to diagnose temporal issues in models outside the audio domain.
- Scaling interventions may generalize to larger models or different tasks without retraining.
- keywords:[
Load-bearing premise
The 1,657-question benchmark isolates temporal reasoning failures and cannot be solved via textual shortcuts or non-temporal cues.
What would settle it
If attention scaling at bottleneck layers produces no accuracy gain on a modified benchmark that removes temporal elements while keeping the same format and text cues, the claim that the intervention targets temporal reasoning would not hold.
Figures

read the original abstract
Large Audio Language Models (LALMs) achieve strong performance on a variety of audio understanding tasks but continue to struggle with temporal reasoning, a fundamental capability central to human auditory perception. Understanding the causes of these failures remains challenging as existing benchmarks report performance gaps without probing underlying mechanisms. To address this, we introduce a benchmark with 1,657 questions across three foundational tasks designed specifically for mechanistic analysis. Examining model outputs across varying input settings (behavioral analysis) reveals that models often under-utilize audio when textual cues are available. We also provide the first causal mechanistic analysis of temporal reasoning failures in LALMs. Comparing attention upweighting against scaling, we find that redistributing attention across audio tokens is more effective than increasing audio attention. Targeting task-relevant tokens yields further gains. These findings suggest that modality imbalance alone cannot explain failures. Attention scaling at bottleneck layers improves accuracy from 55.9% to 59.1% without fine-tuning, demonstrating a promising direction for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a 1,657-question benchmark across three tasks, designed for mechanistic analysis of temporal reasoning failures in Large Audio-Language Models (LALMs). Behavioral analysis shows models under-utilize audio when text cues are present. A causal analysis compares attention upweighting vs. scaling, finding redistribution across audio tokens more effective than increasing audio attention; targeting task-relevant tokens yields gains. Attention scaling at bottleneck layers raises accuracy from 55.9% to 59.1% without fine-tuning, implying modality imbalance alone does not explain the failures.
Significance. If the benchmark isolates temporal reasoning, the work supplies the first causal mechanistic dissection of LALM temporal failures and identifies a simple, training-free intervention. The distinction between redistribution and upweighting, plus the evidence against modality imbalance as sole cause, would be useful for guiding audio model design. The paper supplies behavioral evidence and reports concrete numeric gains from the intervention.
major comments (2)
- [Benchmark construction] Benchmark construction section: the manuscript states the benchmark is 'designed specifically for mechanistic analysis' yet reports no audio-removed, audio-scrambled, or text-only controls demonstrating that accuracy collapses without audio or temporal cues. This is load-bearing for the central claim, because the attribution of the 55.9% → 59.1% gain (and the conclusion that modality imbalance is insufficient) rests on the benchmark truly measuring temporal reasoning rather than residual text-only solvability.
- [Attention scaling results] Attention scaling results (abstract and § on interventions): the 3.2 pp improvement is reported without statistical tests, variance across runs, or explicit description of how 'bottleneck layers' and scaling factors were chosen or implemented, leaving the causal link between the intervention and temporal mechanisms unverified.
minor comments (2)
- The abstract lists 'three foundational tasks' but does not name them or indicate how they map to the 1,657 questions.
- No mention of confidence intervals or multiple-comparison corrections for the reported accuracy figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below with clarifications and commitments to revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the manuscript states the benchmark is 'designed specifically for mechanistic analysis' yet reports no audio-removed, audio-scrambled, or text-only controls demonstrating that accuracy collapses without audio or temporal cues. This is load-bearing for the central claim, because the attribution of the 55.9% → 59.1% gain (and the conclusion that modality imbalance is insufficient) rests on the benchmark truly measuring temporal reasoning rather than residual text-only solvability.
Authors: The referee correctly notes that the current manuscript does not report explicit audio-removed, scrambled, or text-only control experiments. Our behavioral analysis section does compare model outputs under varying input settings (including reduced audio context), which shows under-utilization of audio when text cues are available, but this falls short of the requested controls. We will add a new subsection with text-only and audio-scrambled baselines for all three tasks in the revised manuscript to quantify the drop in accuracy and better isolate temporal reasoning. This addresses the load-bearing concern directly. revision: yes
-
Referee: [Attention scaling results] Attention scaling results (abstract and § on interventions): the 3.2 pp improvement is reported without statistical tests, variance across runs, or explicit description of how 'bottleneck layers' and scaling factors were chosen or implemented, leaving the causal link between the intervention and temporal mechanisms unverified.
Authors: We agree that the reported 3.2 pp gain lacks statistical tests, run-to-run variance, and implementation details. In revision we will add: (1) standard deviations or standard errors across at least three random seeds, (2) paired statistical tests (e.g., McNemar or t-test) on the accuracy difference, and (3) an expanded methods paragraph specifying how bottleneck layers were identified via attention maps and the exact scaling procedure and factor values used. These additions will make the causal claim verifiable. revision: yes
Circularity Check
No significant circularity in empirical analysis
full rationale
The paper reports direct empirical measurements of LALM behavior on a new 1,657-question benchmark and the accuracy effects of attention interventions (e.g., scaling at bottleneck layers lifting 55.9% to 59.1%). No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described content; the central claims rest on experimental outcomes rather than any derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Despite strong performance in identi- fying and describing acoustic events, models often struggle to localize events in time or reason about their temporal relation- ships [1, 2]
Introduction Large Audio Language Models (LALMs) have recently emerged as a key focus in multimodal AI, enabling a wide range of audio-centric tasks. Despite strong performance in identi- fying and describing acoustic events, models often struggle to localize events in time or reason about their temporal relation- ships [1, 2]. These limitations reduce ef...
-
[2]
A Closer Look at Failure Modes in Temporal Understanding of Large Audio-Language Models
Related Work LALM Benchmarks and Temporal Reasoning.Temporal reasoning has emerged as a key challenge for LALMs. Bench- marks such as MMAU [3], MMAU-Pro [5], and MMAR [4] as- sess overall audio understanding across diverse tasks, with tem- poral reasoning as one component. Yao et al. [1] systematically analyze how temporal reasoning varies with audio char...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Each audio clip also includes a weak caption that provides general audio description
Dataset and Task Construction We evaluate temporal reasoning using three controlled multiple- choice QA tasks derived from TACOS [12], which provides temporally aligned audio segments with precise onset and off- set annotations paired with textual descriptions. Each audio clip also includes a weak caption that provides general audio description. TACOS is ...
-
[4]
We adopt this approach to examine how LALMs utilize audio versus textual information for temporal reasoning
Behavioral Analysis Behavioral analysis is an interpretability approach that seeks to understand a model by systematically prompting it and ob- serving its outputs under controlled conditions. We adopt this approach to examine how LALMs utilize audio versus textual information for temporal reasoning. We evaluate four state-of-the-art open-source LALMs: Qw...
-
[5]
earliest
Mechanistic Analysis For mechanistic analysis, we only utilize Audio-Flamingo-3 and DeSTA-2.5-Audio. These are the only state-of-the-art LALMs with fully open-source weights, training code, and training data. This enables reproducible mechanistic analysis and rules out data-driven confounds. We compare two training- free attention interventions, applied u...
-
[6]
The fix rates achieved indicate that attention distribution is one contributing factor among others
Limitations and Future Work Our attention-level interventions cannot rule out the impact of alternative mechanisms such as weak audio encoder representa- tions. The fix rates achieved indicate that attention distribution is one contributing factor among others. However, our findings do rule out one prominent hypothesis: prior work has empha- sized audio-t...
-
[7]
Behavioral analysis confirms models under-utilize audio when textual cues are available
Conclusion This work investigates temporal reasoning failures in LALMs through a controlled benchmark with 1,657 questions across three foundational tasks. Behavioral analysis confirms models under-utilize audio when textual cues are available. We pro- vide the first causal attention interventions for temporal reason- ing in LALMs, adapting ScalingVis fro...
-
[8]
These tools were used exclusively for linguistic support and were not used to generate scientific results or formulate claims
Generative AI Use Disclosure We utilized AI assistants to help clarify explanations, suggest concise phrasing, and organize text for readability. These tools were used exclusively for linguistic support and were not used to generate scientific results or formulate claims
-
[9]
Not in sync: Unveiling temporal bias in audio chat models,
J. Yao, S. Liu, Y . Wang, R. Cheng, L. Mei, B. Bi, Z. Xiong, and X. Cheng, “Not in sync: Unveiling temporal bias in audio chat models,” 2025. [Online]. Available: https: //arxiv.org/abs/2510.12185
-
[10]
Benchmarking and Confidence Evaluation of LALMs For Temporal Reasoning,
D. Bhattacharya, A. Kulkarni, and S. Ganapathy, “Benchmarking and Confidence Evaluation of LALMs For Temporal Reasoning,” inInterspeech 2025, 2025, pp. 2068–2072
2025
-
[11]
MMAU: A massive multi-task audio understanding and reasoning benchmark,
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “MMAU: A massive multi-task audio understanding and reasoning benchmark,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https: //openreview.net/forum?id=TeV AZXr3yv
2025
-
[12]
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,
Z. Ma, Y . Ma, Y . Zhu, C. Yang, Y .-W. Chao, R. Xu, W. Chen, Y . Chen, Z. Chen, J. Cong, K. Li, K. Li, S. Li, X. Li, X. Li, Z. Lian, Y . Liang, M. Liu, Z. Niu, T. Wang, Y . Wang, Y . Wang, Y . Wu, G. Yang, J. Yu, R. Yuan, Z. Zheng, Z. Zhou, H. Zhu, W. Xue, E. Benetos, K. Yu, E.-S. Chng, and X. Chen, “Mmar: A challenging benchmark for deep reasoning in sp...
-
[13]
S. Kumar, ˇSimon Sedl ´aˇcek, V . Lokegaonkar, F. L ´opez, W. Yu, N. Anand, H. Ryu, L. Chen, M. Pli ˇcka, M. Hlav ´aˇcek, W. F. Ellingwood, S. Udupa, S. Hou, A. Ferner, S. Barahona, C. Bola ˜nos, S. Rahi, L. Herrera-Alarc ´on, S. Dixit, S. Patil, S. Deshmukh, L. Koroshinadze, Y . Liu, L. P. G. Perera, E. Zanou, T. Stafylakis, J. S. Chung, D. Harwath, C. Z...
-
[14]
When audio and text disagree: Revealing text bias in large audio-language models,
C. Wang, G. Deng, X. Yang, H. Qiu, and T. Zhang, “When audio and text disagree: Revealing text bias in large audio-language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, Nov. 2025...
2025
-
[15]
Omni-r1: Do you really need audio to fine-tune your audio llm?
A. Rouditchenko, S. Bhati, E. Araujo, S. Thomas, H. Kuehne, R. Feris, and J. Glass, “Omni-r1: Do you really need audio to fine-tune your audio llm?” 2025. [Online]. Available: https://arxiv.org/abs/2505.09439
-
[16]
H. He, X. Du, R. Sun, Z. Dai, Y . Xiao, M. Yang, J. Zhou, X. Li, Z. Liu, Z. Liang, C. Wu, Q. He, T. Lee, X. Chen, W.-L. Zheng, W. Wang, M. Plumbley, J. Liu, and Q. Kong, “Measuring audio’s impact on correctness: Audio-contribution-aware post-training of large audio language models,” 2025. [Online]. Available: https://arxiv.org/abs/2509.21060
-
[17]
Paying more attention to image: A training-free method for alleviating hallucination in lvlms,
S. Liu, K. Zheng, and W. Chen, “Paying more attention to image: A training-free method for alleviating hallucination in lvlms,”
-
[18]
Available: https://arxiv.org/abs/2407.21771
[Online]. Available: https://arxiv.org/abs/2407.21771
-
[19]
Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas,
S. Chen, T. Zhu, R. Zhou, J. Zhang, S. Gao, J. C. Niebles, M. Geva, J. He, J. Wu, and M. Li, “Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas,”
-
[20]
Available: https://arxiv.org/abs/2503.01773
[Online]. Available: https://arxiv.org/abs/2503.01773
-
[21]
J. Wang, Z. Ma, Z. Luo, T. Wang, M. Ge, X. Wang, and L. Wang, “Pay more attention to audio: Mitigating imbalance of cross-modal attention in large audio language models,” 2025. [Online]. Available: https://arxiv.org/abs/2509.18816
-
[22]
Tacos: Temporally- aligned audio captions for language-audio pretraining,
P. Primus, F. Schmid, and G. Widmer, “Tacos: Temporally- aligned audio captions for language-audio pretraining,” 2025. [Online]. Available: https://arxiv.org/abs/2505.07609
-
[23]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-audio technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
KimiTeam, D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, Z. Wang, C. Wei, Y . Xin, X. Xu, J. Yu, Y . Zhang, X. Zhou, Y . Charles, J. Chen, Y . Chen, Y . Du, W. He, Z. Hu, G. Lai, Q. Li, Y . Liu, W. Sun, J. Wang, Y . Wang, Y . Wu, Y . Wu, D. Yang, H. Yang, Y . Yang, Z. Yang, A. Yin, R. Yuan, Y . Zhang, and Z. Zhou, “...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S. gil Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,” 2025. [Online]. Available: https://arxiv.org/abs/2507.08128
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
K.-H. Lu, Z. Chen, S.-W. Fu, C.-H. H. Yang, S.-F. Huang, C.-K. Yang, C.-E. Yu, C.-W. Chen, W.-C. Chen, C. yu Huang, Y .-C. Lin, Y .-X. Lin, C.-A. Fu, C.-Y . Kuan, W. Ren, X. Chen, W.-P. Huang, E.-P. Hu, T.-Q. Lin, Y .-K. Wu, K.-P. Huang, H.-Y . Huang, H.-C. Chou, K.-W. Chang, C.-H. Chiang, B. Ginsburg, Y .-C. F. Wang, and H. yi Lee, “Desta2.5-audio: Towar...
-
[27]
Is a picture worth a thousand words? delving into spatial reason- ing for vision language models,
J. Wang, Y . Ming, Z. Shi, V . Vineet, X. Wang, Y . Li, and N. Joshi, “Is a picture worth a thousand words? delving into spatial reason- ing for vision language models,” inAdvances in Neural Informa- tion Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Cur- ran Associates, Inc., 2024, p...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.