Cordon: Semantic Transactions for Tool-Using LLM Agents
Pith reviewed 2026-06-26 22:00 UTC · model grok-4.3
The pith
Cordon introduces semantic transactions as a task-level boundary for LLM agents to stage, validate, and commit tool effects with rollback and recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
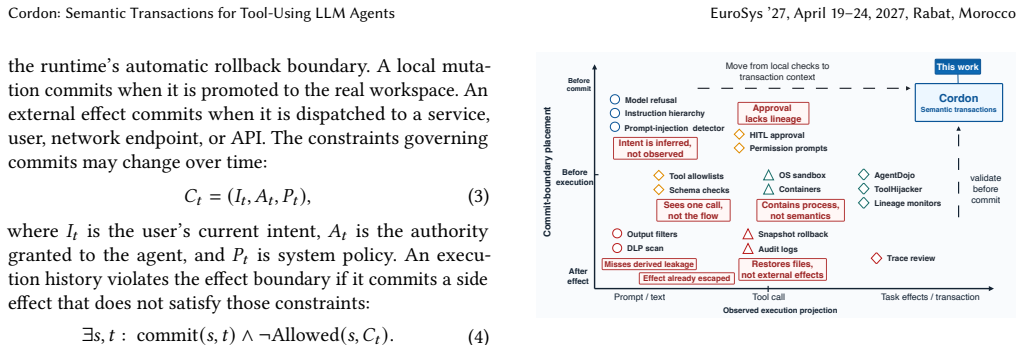
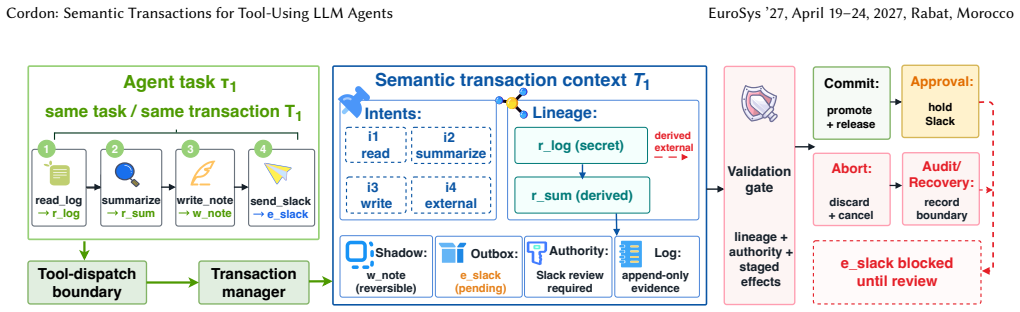
A semantic transaction is a task-level execution boundary that binds tool intents and runtime-tracked result lineage to reversible local state, staged external effects, delegated authority, and audit metadata. Cordon implements this abstraction with a transaction manager that tracks derived result objects, executes reversible mutations in shadow state, stages outward-facing actions in an effect outbox, and records recovery metadata. The runtime then validates the composed execution flow before it commits state or releases external effects.
What carries the argument
The semantic transaction, a task-level execution boundary that links tool intents with tracked lineage, reversible state, staged effects, and validation before commit.
If this is right
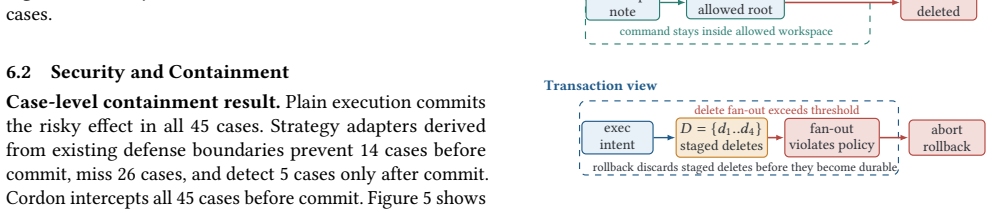
- Existing per-call defenses miss cross-step violations that the task-level validation can expose.
- Irreversible-effect failures decrease because effects remain staged until the composed flow is approved.
- Benign task completion rates stay high while approval and latency overhead remain modest.
- Agents gain explicit commit, rollback, recovery, and audit capabilities across multi-step tool workflows.
Where Pith is reading between the lines
- The shadow-state and outbox design could be adapted to other autonomous decision systems that issue external actions over multiple steps.
- Integration with human-in-the-loop approval might allow selective release of high-risk effects while keeping the rest automated.
- Real-world agent deployments could test whether the tracking overhead stays acceptable when tool calls involve large result objects or long chains.
Load-bearing premise
The runtime can accurately track derived result objects and composed execution flows across tool calls to detect violations without missing critical cross-step issues or adding prohibitive overhead.
What would settle it
An adversarial workflow in which a cross-step violation occurs but the validation step approves the transaction and releases effects would falsify the claim that the boundary reliably catches such issues.
Figures




read the original abstract
Tool-using LLM agents are shifting the unit of computation from explicit human-issued commands to model-driven tasks with stateful consequences. Yet today's agent runtimes still expose tools as isolated RPCs. This interface gives runtimes a convenient integration point, but it lacks a task-scoped execution boundary for commit, rollback, recovery, and audit across multi-step agent workflows. We argue that this mismatch calls for a runtime containment boundary rather than another per-call guardrail. This paper introduces Cordon, a transactional runtime system for staging and validating irreversible agent effects before commit. A semantic transaction is a task-level execution boundary that binds tool intents and runtime-tracked result lineage to reversible local state, staged external effects, delegated authority, and audit metadata. Cordon implements this abstraction with a transaction manager that tracks derived result objects, executes reversible mutations in shadow state, stages outward-facing actions in an effect outbox, and records recovery metadata. The runtime then validates the composed execution flow before it commits state or releases external effects. Our evaluation across adversarial and benign workflows shows that Cordon exposes cross-step violations missed by existing defenses. It also reduces irreversible-effect failures while preserving benign task completion with modest approval and latency overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tool-using LLM agents require task-scoped execution boundaries rather than per-call guards, and introduces Cordon as a transactional runtime implementing semantic transactions. These bind tool intents and result lineage to reversible shadow-state mutations, an effect outbox for staged external actions, delegated authority, and recovery metadata. The transaction manager tracks derived result objects and validates the composed execution flow before commit or effect release. Evaluation on adversarial and benign workflows is said to show detection of cross-step violations missed by existing defenses, reduced irreversible failures, and modest overhead while preserving task completion.
Significance. If the tracking and validation mechanisms prove sound, Cordon would represent a meaningful systems contribution by shifting containment from isolated RPCs to task-level transactional semantics for agent workflows. The shadow-state plus outbox design directly addresses rollback and audit needs in stateful, model-driven execution. The paper earns credit for framing the problem as a runtime boundary mismatch rather than incremental guardrails. Significance is limited by the high-level presentation; without concrete lineage algorithms or validation completeness arguments, it is unclear whether the approach delivers on its safety claims or merely adds overhead.
major comments (3)
- [Abstract / Transaction Manager Description] The manuscript provides no description of the lineage tracking algorithm, how it resolves LLM-generated or ambiguous result objects, or how indirect dependencies are captured. This directly undermines the central claim that the runtime 'validates the composed execution flow' and 'exposes cross-step violations missed by existing defenses' (Abstract).
- [Abstract / Validation Step] No validation rules for composed flows, completeness analysis (e.g., missed indirect dependencies), or false-negative bounds are given. The weakest assumption—that accurate tracking occurs without prohibitive overhead or missed issues—remains unaddressed and is load-bearing for the evaluation claims.
- [Evaluation] The evaluation section asserts exposure of violations and reduced failures 'across adversarial and benign workflows' but supplies no methodology, workload details, quantitative metrics (failure rates, overhead numbers), or comparison baselines, preventing assessment of whether the results support the claims.
minor comments (1)
- [Abstract] The term 'semantic transaction' is used without a precise definition or explicit contrast to classical ACID transactions or other agent containment proposals, which would aid readers in understanding the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional detail would strengthen the presentation. We address each major comment below and commit to incorporating the requested clarifications and expansions in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Transaction Manager Description] The manuscript provides no description of the lineage tracking algorithm, how it resolves LLM-generated or ambiguous result objects, or how indirect dependencies are captured. This directly undermines the central claim that the runtime 'validates the composed execution flow' and 'exposes cross-step violations missed by existing defenses' (Abstract).
Authors: We agree that the current high-level presentation omits the concrete lineage tracking algorithm and mechanisms for handling LLM-generated or ambiguous results and indirect dependencies. The manuscript focuses on the overall transactional abstraction rather than implementation internals. In revision we will add a new subsection under the Transaction Manager that specifies the lineage tracking algorithm, including how result objects are resolved, how indirect dependencies are recorded via shadow-state mutations, and the data structures used to maintain the lineage graph. revision: yes
-
Referee: [Abstract / Validation Step] No validation rules for composed flows, completeness analysis (e.g., missed indirect dependencies), or false-negative bounds are given. The weakest assumption—that accurate tracking occurs without prohibitive overhead or missed issues—remains unaddressed and is load-bearing for the evaluation claims.
Authors: The manuscript describes validation conceptually but does not enumerate the concrete rules or provide a completeness argument. We will revise the Validation subsection to list the explicit validation rules applied to composed flows, include a discussion of potential missed indirect dependencies with mitigation strategies, and supply an informal argument bounding false negatives under the stated assumptions about result tracking. revision: yes
-
Referee: [Evaluation] The evaluation section asserts exposure of violations and reduced failures 'across adversarial and benign workflows' but supplies no methodology, workload details, quantitative metrics (failure rates, overhead numbers), or comparison baselines, preventing assessment of whether the results support the claims.
Authors: We acknowledge that the evaluation section is currently summarized at a high level without the requested methodological details. In the revised manuscript we will expand the Evaluation section to describe the experimental methodology, the specific adversarial and benign workloads used, quantitative metrics including failure rates, overhead measurements, and direct comparisons against the baselines referenced in the text. revision: yes
Circularity Check
No circularity: purely architectural description with no derivations or equations
full rationale
The paper describes a runtime system and abstraction (semantic transactions) at the level of system architecture and implementation details, with no equations, fitted parameters, mathematical derivations, or load-bearing self-citations that reduce claims to inputs by construction. Evaluation claims rest on empirical observation of the implemented system rather than any self-referential prediction or renaming of results. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI Security Institute. 2025. The Inspect Sandboxing Toolkit: Scalable and Secure AI Agent Evaluations.https://www.aisi.gov.uk/work/the- inspect-sandboxing-toolkit-scalable-and-secure-ai-agent- evaluations. Accessed 2026-05-12
2025
-
[2]
Always Further. 2026. nono.https://github.com/always-further/nono. AI-agent sandbox and runtime; Accessed 2026-05-14
2026
-
[3]
Anderson
James P. Anderson. 1972.Computer Security Technology Planning Study. Technical Report ESD-TR-73-51. USAF Electronic Systems Division, Hanscom Air Force Base, Bedford, MA
1972
-
[4]
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. 2024. AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents.arXiv preprint arXiv:2410.09024(2024). https://arxiv.org/abs/2410.09024
Pith/arXiv arXiv 2024
-
[5]
Anthropic. 2026. Claude Code Settings: Permissions.https://docs. anthropic.com/en/docs/claude-code/settings#permissions. Accessed 2026-05-12
2026
-
[6]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jack- son Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran- Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse...
Pith/arXiv arXiv 2022
-
[7]
Franklin, Ali Ghodsi, Joseph M
Peter Bailis, Alan Fekete, Michael J. Franklin, Ali Ghodsi, Joseph M. Hellerstein, and Ion Stoica. 2014. Coordination Avoidance in Database Systems.Proceedings of the VLDB Endowment8, 3 (2014), 185–196. doi:10.14778/2735508.2735509
-
[8]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. 2023. Autonomous chemical research with large language models.Nature 624 (2023), 570–578. doi:10.1038/s41586-023-06792-0
-
[9]
Bran, Sam Cox, Oliver Schilter, et al
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. 2024. Augmenting large language models with chemistry tools.Nature Machine Intelligence6 (2024), 525–535. doi:10.1038/s42256-024-00832-8
-
[10]
Peter Buneman, Sanjeev Khanna, and Wang-Chiew Tan. 2001. Why and Where: A Characterization of Data Provenance. InProceedings of the 8th International Conference on Database Theory. 316–330. doi:10. 1007/3-540-44503-X_20
2001
-
[11]
Haogang Chen, Daniel Ziegler, Tej Chajed, Adam Chlipala, M. Frans Kaashoek, and Nickolai Zeldovich. 2015. Using Crash Hoare Logic for Certifying the FSCQ File System. InProceedings of the 25th Symposium on Operating Systems Principles. 18–37. doi:10.1145/2815400.2815402
-
[12]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2024. StruQ: Defending Against Prompt Injection with Structured Queries. arXiv preprint arXiv:2402.06363(2024).https://arxiv.org/abs/2402. 06363
arXiv 2024
-
[13]
James Cheney, Laura Chiticariu, and Wang-Chiew Tan. 2009. Prove- nance in Databases: Why, How, and Where.Foundations and Trends in Databases1, 4 (2009), 379–474. doi:10.1561/1900000006
-
[14]
David D. Clark and David R. Wilson. 1987. A Comparison of Com- mercial and Military Computer Security Policies. InProceedings of the IEEE Symposium on Security and Privacy. 184–194. doi:10.1109/SP.1987. 10001
-
[15]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer- Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dy- namic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems. doi:10.52202/079017-2636
-
[16]
DeepSeek-AI. 2026. DeepSeek-V4: Towards Highly Efficient Million- Token Context Intelligence.https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro. Accessed 2026-05-15
2026
-
[17]
Docker. 2026. Docker Documentation: Seccomp Security Profiles. https://docs.docker.com/engine/security/seccomp/. Accessed 2026-05- 03
2026
-
[18]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. 2024. WorkArena: How Capable are Web Agents at Solving Common Knowledge Work Tasks?. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 23...
2024
-
[19]
Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N
William Enck, Peter Gilbert, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N. Sheth. 2010. TaintDroid: An Information-Flow Tracking System for Realtime Privacy Monitoring on Smartphones. InUSENIX Symposium on Operating Systems Design and Implementation
2010
-
[20]
Hector Garcia-Molina and Kenneth Salem. 1987. Sagas. InProceedings of the ACM SIGMOD International Conference on Management of Data. 249–259
1987
-
[21]
In: 1982 IEEE Symposium on Security and Privacy, 1982, pp
Joseph A. Goguen and José Meseguer. 1982. Security Policies and Security Models. InProceedings of the IEEE Symposium on Security and Privacy. 11–20. doi:10.1109/SP.1982.10014 13 EuroSys ’27, April 19–24, 2027, Rabat, Morocco Zheng Chen, Hanqing Liu, Duling Xu, Dong Dong, Jialin Li, Bangzheng Pu, and Jidong Zhai
-
[22]
gRPC Authors. 2026. gRPC Documentation.https://grpc.io/docs/. Accessed 2026-05-14
2026
-
[23]
Theo Härder and Andreas Reuter. 1983. Principles of Transaction- Oriented Database Recovery.Comput. Surveys15, 4 (1983), 287–317. doi:10.1145/289.291
-
[24]
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. 2024. Defending Against Indirect Prompt Injection Attacks with Spotlighting.arXiv preprint arXiv:2403.14720 (2024).https://arxiv.org/abs/2403.14720
Pith/arXiv arXiv 2024
-
[25]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. 2023. Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations.arXiv preprint arXiv:2312.06674(2023).https://arxiv.org/abs/2312.06674
Pith/arXiv arXiv 2023
-
[26]
Invariant Labs. 2026. MCP-Scan: A Security Scanner for MCP.https: //github.com/invariantlabs-ai/mcp-scan. Accessed 2026-05-12
2026
-
[27]
Butler W. Lampson. 1974. Protection.ACM SIGOPS Operating Systems Review8, 1 (1974), 18–24. doi:10.1145/775265.775268
-
[28]
LangChain. 2026. LangChain Documentation: Human-in-the- loop.https://docs.langchain.com/oss/python/langchain/human-in- the-loop. Accessed 2026-05-03
2026
-
[29]
Songkai Liu, Yanqing Shen, Yilun Zhang, Zhangli Hou, Xin Wang, Jianxi Luo, and Zhinan Zhang. 2026. iDesignGPT enhances conceptual design via large language model agentic workflows.Nature Commu- nications17 (2026), 1997. doi:10.1038/s41467-026-68672-1
-
[30]
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. 2026. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868(2026)
Pith/arXiv arXiv 2026
-
[31]
Chandrasekaran Mohan, Don Haderle, Bruce Lindsay, Hamid Pirahesh, and Peter Schwarz. 1992. ARIES: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write- ahead logging.ACM Transactions on Database Systems (TODS)17, 1 (1992), 94–162
1992
-
[32]
Nous Research. 2026. Hermes Agent: Tirith Security.https://hermes- agent.ai/features/tirith-security. Accessed 2026-05-12
2026
-
[33]
OpenAI. 2026. Codex CLI.https://developers.openai.com/codex/cli. Accessed 2026-05-11
2026
-
[34]
OpenAI. 2026. OpenAI Agents SDK: Human-in-the-loop.https: //openai.github.io/openai-agents-js/guides/human-in-the-loop/. Ac- cessed 2026-05-03
2026
-
[35]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Chris- tiano, Jan Leike, and Ryan Lowe. 2022. Training Language Models to Follow Instructions with Hu...
2022
-
[36]
Protect AI. 2026. LLM Guard: The Security Toolkit for LLM Interactions. https://github.com/protectai/llm-guard. Accessed 2026-05-12
2026
-
[37]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christo- pher Parisien, and Jonathan Cohen. 2023. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Association for Compu- tational Linguistics...
-
[38]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems
2023
-
[39]
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. 2025. Prompt Injection Attack to Tool Selection in LLM Agents.arXiv preprint arXiv:2504.19793(2025).https://arxiv. org/abs/2504.19793
Pith/arXiv arXiv 2025
-
[40]
Snyk. 2026. Agent Scan: Security Scanner for AI Agents, MCP Servers, and Agent Skills.https://github.com/snyk/agent-scan. Accessed 2026-05-12
2026
-
[41]
Snyk. 2026. ToxicSkills: Malicious AI Agent Skills and Agent Skills Supply Chain Compromise.https://snyk.io/blog/toxicskills-malicious- ai-agent-skills-clawhub/. Accessed 2026-05-12
2026
-
[42]
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. 2024. AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics. doi:10.48550/arXi...
-
[43]
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. 2024. The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions.arXiv preprint arXiv:2404.13208 (2024).https://arxiv.org/abs/2404.13208
Pith/arXiv arXiv 2024
-
[44]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent- Computer Interfaces Enable Automated Software Engineering. InAd- vances in Neural Information Processing Systems, Vol. 37. Neural Infor- mation Processing Systems Foundation, Vancouver, Canada, 125 pages. doi:10.52202/079017-1601
-
[45]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan
-
[46]
doi:10.48550/ arXiv.2406.12045
𝜏-bench: A Benchmark for Tool-Agent-User Interaction in Real- World Domains.arXiv preprint arXiv:2406.12045(2024). doi:10.48550/ arXiv.2406.12045
Pith/arXiv arXiv 2024
-
[47]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations
2023
-
[48]
Nickolai Zeldovich, Silas Boyd-Wickizer, Eddie Kohler, and David Mazières. 2006. Making Information Flow Explicit in HiStar. InUSENIX Symposium on Operating Systems Design and Implementation
2006
-
[49]
ZODB Developers. 2026. ZODB: A Native Object Database for Python. https://zodb.org/. Accessed 2026-05-14. 14
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.