The 2026 Algorithmic Information Theory Data Compression Challenge
Pith reviewed 2026-06-26 22:59 UTC · model grok-4.3
The pith
The 2026 challenge benchmark shows compressor performance depends strongly on the optimization criterion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
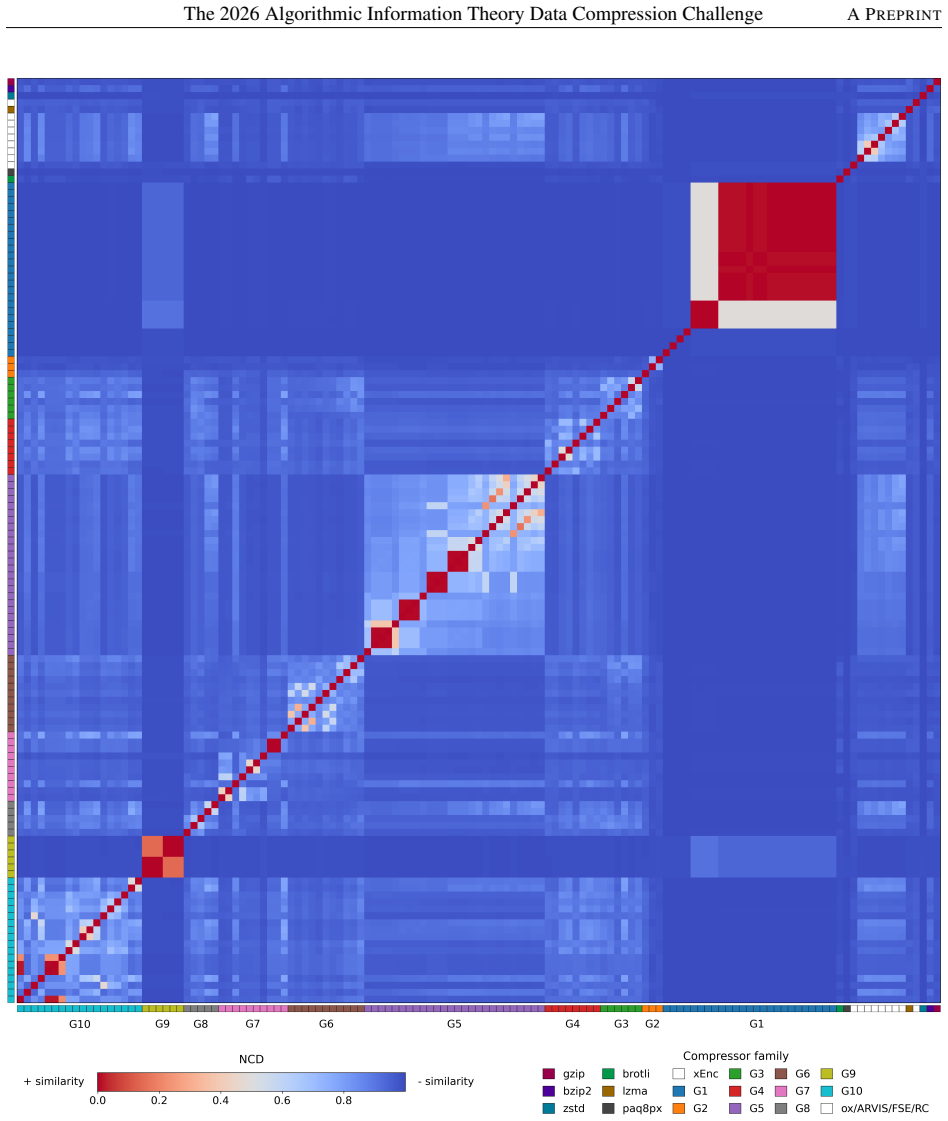
Performance depends strongly on the optimization criterion: fast compressors achieved the best speed-oriented scores, whereas modelling-intensive compressors produced smaller outputs at higher computational cost. A Normalized Compression Distance analysis further revealed clusters of related submissions and distinguished incremental variants from more independent implementations. Selected submissions tested competitively or superiorly on four large external datasets.
What carries the argument
The 2026 Algorithmic Information Theory Data Compression Challenge benchmark consisting of sixteen heterogeneous files, 8 GB memory limit, 1 MB decompressor constraint, and evaluation via ratio, time, Weissman score, Pareto frontier, and Normalized Compression Distance.
Load-bearing premise
The sixteen heterogeneous files and the chosen constraints are assumed to provide a representative and fair test of general-purpose compression performance and generalization.
What would settle it
A compressor that ranks first across all speed, ratio, and external-dataset metrics simultaneously, or a new file collection where performance no longer varies with the chosen optimization criterion.
Figures

read the original abstract
Lossless data compression remains central to computer science, with direct impact on storage, communication bandwidth, computational cost, and energy consumption. It is also closely related to Algorithmic Information Theory, where compressibility provides an operational measure of structure and non-randomness. This paper presents the 2026 Algorithmic Information Theory Data Compression Challenge, a benchmark for evaluating general-purpose lossless compressors under realistic constraints. Submissions were encouraged to use arithmetic or range coding, limited to at most 8 GB of memory, and required to include a decompressor no larger than 1 MB. The benchmark comprised sixteen heterogeneous files, split into public training and hidden testing datasets. In total, 117 valid submitted compressors were evaluated alongside established reference compressors using compression ratio, compression and decompression time, Weissman score, and Pareto-frontier analysis. The results show that performance depends strongly on the optimization criterion: fast compressors achieved the best speed-oriented scores, whereas modelling-intensive compressors produced smaller outputs at higher computational cost. A Normalized Compression Distance analysis further revealed clusters of related submissions and distinguished incremental variants from more independent implementations. Selected submissions were described for their methodological novelty or competitive performance and further tested on four large external datasets, where several achieved competitive or superior results relative to established compressors. Overall, the challenge confirms the importance of probabilistic modelling, hidden testing, and external datasets for assessing compression performance and generalization. Benchmark resources, leaderboard data, binaries, and selected source code are publicly available at https://aitdcc.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the 2026 Algorithmic Information Theory Data Compression Challenge, a benchmark for general-purpose lossless compressors. Submissions were restricted to arithmetic or range coding, at most 8 GB memory, and a decompressor no larger than 1 MB. The benchmark used sixteen heterogeneous files (public training set, hidden test set). 117 valid submissions were evaluated alongside reference compressors on compression ratio, compression/decompression time, Weissman score, and Pareto-frontier analysis. The central empirical finding is that performance depends strongly on the optimization criterion: fast compressors scored highest on speed-oriented metrics while modeling-intensive compressors achieved better ratios at higher cost. Normalized Compression Distance analysis clustered submissions; selected entries were further evaluated on four large external datasets and showed competitive results. All resources (leaderboard, binaries, selected code) are released publicly.
Significance. If the reported empirical patterns hold, the work supplies a reproducible public benchmark that operationalizes compressibility as a measure of structure, directly relevant to Algorithmic Information Theory. The explicit use of hidden testing and external validation datasets, together with the public release of data, binaries, and code, constitutes a concrete strength that enables independent verification and follow-on research. The observed trade-off between speed and ratio, quantified via multiple metrics including Pareto analysis, provides a clear, falsifiable illustration of design choices in compressor construction.
major comments (1)
- [Benchmark description] Benchmark setup (sixteen files): the claim that these files and the 8 GB / 1 MB constraints yield a representative test of general-purpose compression performance is load-bearing for the generalization statements in the conclusion, yet the manuscript provides no quantitative diversity metrics, coverage of file types, or explicit selection criteria; without this, the dependence-on-criterion result remains benchmark-specific rather than broadly interpretable.
minor comments (2)
- [Abstract] The abstract states that 117 submissions were evaluated but does not indicate how many reference compressors were included in the same tables or Pareto plots; adding this count would improve clarity of the comparative claims.
- [Results] The Normalized Compression Distance clustering is described at a high level; a brief statement of the distance matrix construction or linkage method used would aid reproducibility of the cluster analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark description. We address the comment below and will revise the manuscript to incorporate additional details.
read point-by-point responses
-
Referee: [Benchmark description] Benchmark setup (sixteen files): the claim that these files and the 8 GB / 1 MB constraints yield a representative test of general-purpose compression performance is load-bearing for the generalization statements in the conclusion, yet the manuscript provides no quantitative diversity metrics, coverage of file types, or explicit selection criteria; without this, the dependence-on-criterion result remains benchmark-specific rather than broadly interpretable.
Authors: We agree that explicit documentation of file coverage and selection criteria would strengthen support for the generalization statements. In the revised manuscript we will add a dedicated subsection (or appendix) that: (1) enumerates the sixteen files by type and domain (natural-language text, source code, raw binary executables, image/sensor data, and structured scientific files); (2) reports basic quantitative descriptors such as file sizes and zeroth-order entropy estimates; and (3) states the selection rationale—public availability, heterogeneity across data structures relevant to algorithmic information theory, and suitability for the memory and decompressor-size constraints. We will also include a small table summarizing these characteristics. This addition will make the observed dependence on optimization criterion more clearly benchmark-supported while remaining faithful to the data we collected. revision: yes
Circularity Check
Empirical benchmark report with no derivation chain
full rationale
The paper presents results from an open compression challenge: 117 submitted compressors evaluated on 16 public/hidden files under fixed constraints (8 GB RAM, 1 MB decompressor), scored by ratio, time, Weissman score, and Pareto analysis. No equations, fitted parameters, predictions, or uniqueness theorems appear. All reported outcomes are direct measurements on the test set; reference compressors and external datasets are independent. No self-citation is load-bearing for any claim. The work is self-contained as an empirical benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The 2026 algorithmic information theory data compression challenge
AIT Data Compression Challenge. The 2026 algorithmic information theory data compression challenge. https://aitdcc.github.io/, 2026. Accessed: 2026-04-22
2026
-
[2]
Alakuijala, A
J. Alakuijala, A. Farruggia, P. Ferragina, E. Kliuchnikov, R. Obryk, Z. Szabadka, and L. Vandevenne. Brotli: A general-purpose data compressor.ACM Transactions on Information Systems, 37(1):1–30, 2019
2019
-
[3]
Alakuijala and Z
J. Alakuijala and Z. Szabadka. Brotli compressed data format. RFC 7932, July 2016. 16 The 2026 Algorithmic Information Theory Data Compression ChallengeA PREPRINT
2016
-
[4]
Alshahwan, E
N. Alshahwan, E. T. Barr, D. Clark, and G. Danezis. Detecting malware with information complexity. Working paper, UCL Discovery, 2015. Accessed: 2026-05-11
2015
-
[5]
Axelsson
S. Axelsson. The normalised compression distance as a file fragment classifier.Digital Investigation, 7(Supplement):S24–S31, 2010
2010
-
[6]
C. H. Bennett, P. Gács, M. Li, P. M. B. Vitányi, and W. H. Zurek. Information distance.IEEE Transactions on Information Theory, 44(4):1407–1423, 1998
1998
-
[7]
Burrows and D
M. Burrows and D. J. Wheeler. A Block-Sorting Lossless Data Compression Algorithm. Technical Report 124, Digital Equipment Corporation, Systems Research Center, Palo Alto, California, USA, May 1994
1994
-
[8]
G. J. Chaitin. Randomness and mathematical proof.Scientific American, 232(5):47–52, 1975
1975
-
[9]
G. J. Chaitin. Algorithmic information theory.IBM journal of research and development, 21(4):350–359, 1977
1977
-
[10]
Chen and C
T. Chen and C. Guestrin. XGBoost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794. Association for Computing Machinery, 2016
2016
-
[11]
Cilibrasi and P
R. Cilibrasi and P. M. B. Vitányi. Clustering by compression.IEEE Transactions on Information Theory, 51(4):1523–1545, 2005
2005
-
[12]
Y . Collet. Finite State Entropy: A New Breed of Entropy Coder. Fast Compression blog, 2013
2013
-
[13]
Y . Collet. LZ4: Extremely fast compression algorithm.https://lz4.org/, 2024. Accessed: 2026-05-11
2024
-
[14]
Collet and M
Y . Collet and M. Kucherawy. Zstandard compression and the application/zstd media type. RFC 8878, Feb. 2021
2021
-
[15]
Collin and I
L. Collin and I. Pavlov. XZ Utils: A complete implementation of the .xz file format.https://tukaani.org/xz/,
-
[16]
Accessed: 2026-05-11
2026
-
[17]
dblp computer science bibliography – Monthly Snapshot XML Release of May 2026, May 2026
dblp Team. dblp computer science bibliography – Monthly Snapshot XML Release of May 2026, May 2026. Compressed XML bibliographic dump used as dataset R; accessed: 2026-05-11
2026
-
[18]
P. Deutsch. DEFLATE compressed data format specification version 1.3. RFC 1951, May 1996
1951
-
[19]
P. Deutsch. GZIP file format specification version 4.3. RFC 1952, May 1996
1952
-
[20]
J. Duda. Asymmetric Numeral Systems: Entropy Coding Combining Speed of Huffman Coding with Compression Rate of Arithmetic Coding.arXiv preprint arXiv:1311.2540, 2013
Pith/arXiv arXiv 2013
-
[21]
M. K. Farhat, J. Zhang, X. Tao, and T. Li. DICOMP: Deep Reinforcement Learning for Integer Compression. Machine Learning with Applications, page 100756, 2025
2025
-
[22]
M. Goyal, K. Tatwawadi, S. Chandak, and I. Ochoa. Deepzip: Lossless data compression using recurrent neural networks.arXiv preprint arXiv:1811.08162, 2018
Pith/arXiv arXiv 2018
-
[23]
Griffin, A
G. Griffin, A. Holub, and P. Perona. Caltech-256 Object Category Dataset. Technical Report CNS-TR-2007-001, California Institute of Technology, 2007. Image dataset packaged as a TAR archive and used as dataset S
2007
-
[24]
Hosseini, D
M. Hosseini, D. Pratas, B. Morgenstern, and A. J. Pinho. Smash++: An alignment-free and memory-efficient tool to find genomic rearrangements.GigaScience, 9(5):giaa048, 2020
2020
-
[25]
B. Knoll and N. de Freitas. A machine learning perspective on predictive coding with PAQ.arXiv preprint arXiv:1108.3298, 2011
Pith/arXiv arXiv 2011
-
[26]
A. N. Kolmogorov. Three approaches to the quantitative definition of information.International journal of computer mathematics, 2(1-4):157–168, 1968
1968
-
[27]
M. Li, X. Chen, X. Li, B. Ma, and P. M. B. Vitányi. The similarity metric.IEEE Transactions on Information Theory, 50(12):3250–3264, 2004
2004
-
[28]
Li and P
M. Li and P. M. B. Vitányi.An Introduction to Kolmogorov Complexity and Its Applications. Springer, Cham, Switzerland, 4 edition, 2019
2019
-
[29]
H. Ma, H. Sun, L. Yi, Y . Ding, X. Liu, and G. Wang. Msdzip: Universal lossless compression for multi-source data via stepwise-parallel and learning-based prediction. InProceedings of the ACM on Web Conference 2025, pages 3543–3551, 2025
2025
-
[30]
M. Mahoney. Adaptive weighing of context models for lossless data compression. Technical Report CS-2005-16, Florida Institute of Technology, 2005
2005
-
[31]
M. Mahoney. The PAQ data compression programs. https://www.mattmahoney.net/dc/paq.html, 2024. Accessed: 2026-05-11. 17 The 2026 Algorithmic Information Theory Data Compression ChallengeA PREPRINT
2024
-
[32]
Nikvand, Z
N. Nikvand, Z. Wang, W. Farjow, X. Fernando, and S. Y . Sadat-Nejad. Perceptually Inspired Normalized Conditional Compression Distance. In2019 53rd Asilomar Conference on Signals, Systems, and Computers, pages 1788–1795. IEEE, 2019
2019
-
[33]
S. Nurk, S. Koren, A. Rhie, M. Rautiainen, A. V . Bzikadze, A. Mikheenko, M. R. V ollger, N. Altemose, L. Uralsky, A. Gershman, et al. The complete sequence of a human genome.Science, 376(6588):44–53, 2022. Reference assembly T2T-CHM13v2.0; FASTA genome sequence used as dataset Q
2022
-
[34]
Openstreetmap data extracts: Portugal, 2026
OpenStreetMap contributors and Geofabrik GmbH. Openstreetmap data extracts: Portugal, 2026. Portugal extract in .osm.pbf format used as dataset T; accessed: 2026-05-11
2026
-
[35]
PBF Format
OpenStreetMap Wiki contributors. PBF Format. OpenStreetMap Wiki, 2026. Documentation of the Protocolbuffer Binary Format used for OpenStreetMap .osm.pbf files; accessed: 2026-05-11
2026
-
[36]
I. Pavlov. LZMA SDK (software development kit). https://www.7-zip.org/sdk.html, 2026. Accessed: 2026-05-11
2026
-
[37]
T. S. Perry. A Fictional Compression Metric Moves Into the Real World: The Weissman Score.IEEE Spectrum,
-
[38]
Accessed: 2024-11-20
2024
-
[39]
Pratas, C
D. Pratas, C. A. Bastos, A. J. Pinho, A. J. Neves, and L. M. Matos. DNA synthetic sequences generation using multiple competing Markov models. In2011 IEEE Statistical Signal Processing Workshop (SSP), pages 133–136. IEEE, 2011
2011
-
[40]
A. H. Robinson and C. Cherry. Results of a prototype television bandwidth compression scheme.Proceedings of the IEEE, 55(3):356–364, 1967
1967
-
[41]
book stack
B. Y . Ryabko. Data compression by means of a “book stack”.Problems of Information Transmission, 16(4):265– 269, 1980
1980
-
[42]
Sagan and T
N. Sagan and T. Weissman. A family of LZ78-based universal sequential probability assignments.IEEE Transactions on Information Theory, 2025
2025
-
[43]
Salomon.Data Compression: The Complete Reference
D. Salomon.Data Compression: The Complete Reference. Springer, London, United Kingdom, 4 edition, 2007
2007
-
[44]
Sayood.Introduction to Data Compression
K. Sayood.Introduction to Data Compression. Morgan Kaufmann, Cambridge, MA, USA, 5 edition, 2017
2017
-
[45]
J. Seward. bzip2 and libbzip2, version 1.0.8: A program and library for data compression.https://sourceware. org/bzip2/manual/manual.html, 2019. Accessed: 2026-05-11
2019
-
[46]
C. E. Shannon. Prediction and entropy of printed English.Bell system technical journal, 30(1):50–64, 1951
1951
-
[47]
J. M. Silva, A. J. Pinho, and D. Pratas. AltaiR: A C toolkit for alignment-free and temporal analysis of multi-FASTA data.GigaScience, 13:giae086, 2024
2024
-
[48]
J. M. Silva, D. Pratas, T. Caetano, and S. Matos. The complexity landscape of viral genomes.GigaScience, 11:giac079, 2022
2022
-
[49]
J. M. Silva, W. Qi, A. J. Pinho, and D. Pratas. AlcoR: Alignment-free simulation, mapping, and visualization of low-complexity regions in biological data.GigaScience, 12:giad101, 2023
2023
-
[50]
R. J. Solomonoff. A formal theory of inductive inference. Part I.Information and control, 7(1):1–22, 1964
1964
-
[51]
T. Suel. Delta compression techniques. In S. Sakr and A. Y . Zomaya, editors,Encyclopedia of Big Data Technologies. Springer, Cham, Switzerland, 2018
2018
-
[52]
H. Sun, H. Ma, F. Ling, H. Xie, Y . Sun, L. Yi, M. Yan, C. Zhong, X. Liu, and G. Wang. A survey and benchmark evaluation for neural-network-based lossless universal compressors toward multi-source data.Frontiers of Computer Science, 19(7):197360, 2025
2025
-
[53]
T2T-CHM13v2.0 genome assembly
Telomere-to-Telomere Consortium. T2T-CHM13v2.0 genome assembly. NCBI Assembly, 2022. Complete human genome assembly; accession GCA_009914755.4 / GCF_009914755.1; accessed: 2026-05-11
2022
-
[54]
XZ Utils Manual Page: xz(1), Branch/Call/Jump Filters
The Tukaani Project. XZ Utils Manual Page: xz(1), Branch/Call/Jump Filters. https://tukaani.org/xz/ man/xz.1.html, 2026. Documentation for BCJ filters used in xz/liblzma; accessed: 2026-05-11
2026
-
[55]
Transforming our world: The 2030 agenda for sustainable development
United Nations General Assembly. Transforming our world: The 2030 agenda for sustainable development. Resolution adopted by the General Assembly on 25 September 2015, A/RES/70/1, 2015
2030
-
[56]
Algorithmic Information Theory (2025/26): Project #1, 2026
University of Aveiro, Department of Electronics, Telecommunications and Informatics. Algorithmic Information Theory (2025/26): Project #1, 2026. Course project handout
2025
-
[57]
Vázquez and J
P.-P. Vázquez and J. Marco. Using normalized compression distance for image similarity measurement: an experimental study.The Visual Computer, 28(11):1063–1084, 2012. 18 The 2026 Algorithmic Information Theory Data Compression ChallengeA PREPRINT
2012
-
[58]
Veness, T
J. Veness, T. Lattimore, D. Budden, A. Desai, S. Woods, G. Ostrovski, A. Greco, M. Ng, P. Mnih, and M. Hutter. Gated linear networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10015–10023, 2021
2021
-
[59]
I. H. Witten, R. M. Neal, and J. G. Cleary. Arithmetic coding for data compression.Communications of the ACM, 30(6):520–540, 1987
1987
-
[60]
Wolfram.A New Kind of Science
S. Wolfram.A New Kind of Science. Wolfram Media, 2002
2002
-
[61]
S. Wolfram. What Is ChatGPT Doing ... and Why Does It Work? Stephen Wolfram Writings, Feb. 2023
2023
-
[62]
Ziv and A
J. Ziv and A. Lempel. A universal algorithm for sequential data compression.IEEE Transactions on Information Theory, 23(3):337–343, 1977. 19
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.