SegDINO: Introducing Multi-Scale Structure into DINO for Efficient Medical Image Segmentation
Pith reviewed 2026-06-27 01:09 UTC · model grok-4.3
The pith
SegDINO adds multi-scale structure to DINO features through lightweight adaptations to reach state-of-the-art medical segmentation efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
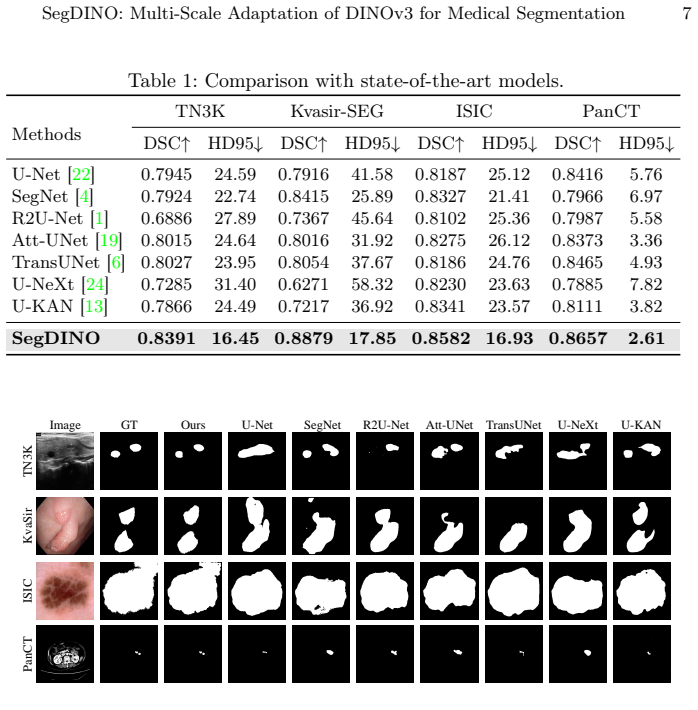
SegDINO integrates a DINOv3 backbone with Token Pyramid Adaptation (TPA) to reorganize intermediate DINO features into a pseudo multi-scale hierarchy and Scale-Aware Decoding (SAD) for efficient intra-scale refinement and top-down multi-scale propagation, achieving state-of-the-art segmentation results with high efficiency on PanCT and three public benchmarks.
What carries the argument
Token Pyramid Adaptation (TPA) and Scale-Aware Decoding (SAD), which together reorganize DINO features into a multi-scale hierarchy and enable lightweight refinement and propagation.
If this is right
- Medical segmentation pipelines can prioritize backbone-level scale adaptation over decoder redesign.
- Small-lesion cases such as pancreatic tumors become more tractable when DINO features receive explicit multi-scale reorganization.
- Parameter and compute budgets in clinical segmentation drop because lightweight scale modules replace complex upsampling stages.
- The same adaptation pattern can be tested on other self-supervised vision backbones that currently lack built-in scale handling.
Where Pith is reading between the lines
- The efficiency gains could make real-time or edge deployment of medical segmentation models more practical in resource-limited hospitals.
- The curated PanCT dataset may become a useful public benchmark for evaluating scale-sensitive lesion detection methods beyond the current work.
- Similar scale-reorganization steps might improve DINO-based dense prediction in non-medical domains where multi-resolution cues matter.
Load-bearing premise
Introducing scale into DINO features is far more critical than increasing decoder capacity.
What would settle it
A controlled comparison in which a DINO backbone paired with a heavier decoder but without TPA or SAD achieves higher accuracy or better efficiency on PanCT and the public benchmarks.
Figures


read the original abstract
Self-supervised DINO models provide strong transferable visual representations, yet applying them directly to image segmentation remains challenging. Existing approaches commonly rely on heavy decoders with complex upsampling, introducing substantial parameter and computational overhead. We observe that introducing scale into DINO features is far more critical than increasing decoder capacity. In this work, we present SegDINO, an efficient segmentation framework that integrates a DINOv3 backbone with lightweight scale modeling. SegDINO introduces Token Pyramid Adaptation (TPA) to reorganize intermediate DINO features into a pseudo multi-scale hierarchy, and Scale-Aware Decoding (SAD) for efficient intra-scale refinement and top-down multi-scale propagation. We further curate PanCT, a new CT dataset containing 284 patients with expert-annotated pancreatic tumors, to assess SegDINO's ability to handle difficult small-lesion cases. Extensive experiments on PanCT and three public benchmarks demonstrate that SegDINO achieves state-of-the-art results with high efficiency. The code is available at https://github.com/script-Yang/segdino_v2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SegDINO, which adapts a DINOv3 backbone for medical image segmentation by adding Token Pyramid Adaptation (TPA) to reorganize intermediate features into a pseudo multi-scale hierarchy and Scale-Aware Decoding (SAD) for intra-scale refinement plus top-down propagation. The central claim is that introducing scale structure is more critical than decoder capacity, enabling state-of-the-art accuracy and efficiency on the new PanCT dataset (284 patients with expert-annotated pancreatic tumors) and three public benchmarks; code is released.
Significance. If the results hold, the work shows that lightweight scale modeling on strong self-supervised backbones can match or exceed heavier decoder designs in medical segmentation, with direct evidence from Section 4.3 ablations comparing SAD against heavier alternatives both with and without TPA. The release of the PanCT dataset and the public code repository are concrete strengths that support reproducibility and further research.
minor comments (2)
- [Abstract] Abstract: the phrase 'DINOv3' is used without a citation or brief description of its relation to prior DINO variants; adding one sentence would aid readers unfamiliar with the exact backbone version.
- [Section 3] The manuscript would benefit from a short note in the introduction or Section 3 clarifying whether TPA and SAD introduce any additional hyperparameters beyond the standard DINOv3 setup.
Simulated Author's Rebuttal
We thank the referee for their positive review and recommendation to accept the manuscript. We appreciate the recognition of the PanCT dataset release, code availability, and the ablation evidence in Section 4.3 supporting the core claim that scale modeling is more critical than decoder capacity.
Circularity Check
No significant circularity
full rationale
The paper is an empirical architecture proposal for medical image segmentation. It introduces TPA and SAD modules on a DINOv3 backbone and reports experimental results on PanCT and public benchmarks. No equations, first-principles derivations, or predictions are present in the abstract or described claims. The central premise (scale modeling matters more than decoder capacity) is supported by ablations rather than any self-referential fitting or self-citation chain. All load-bearing evidence consists of direct experimental comparisons, making the work self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Introducing scale into DINO features is far more critical than increasing decoder capacity.
invented entities (2)
-
Token Pyramid Adaptation (TPA)
no independent evidence
-
Scale-Aware Decoding (SAD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1802.06955 (2018)
Alom, M.Z., Hasan, M., Yakopcic, C., Taha, T.M., Asari, V.K.: Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmen- tation. arXiv preprint arXiv:1802.06955 (2018)
Pith/arXiv arXiv 2018
-
[2]
In: 2024 IEEE International Symposium on Biomedical Imaging (ISBI)
Ayzenberg, L., Giryes, R., Greenspan, H.: Dinov2 based self supervised learning for few shot medical image segmentation. In: 2024 IEEE International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2024)
2024
-
[3]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Azad,R.,Aghdam,E.K.,Rauland,A.,Jia,Y.,Avval,A.H.,Bozorgpour,A.,Karim- ijafarbigloo, S., Cohen, J.P., Adeli, E., Merhof, D.: Medical image segmentation review: The success of u-net. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[4]
IEEE transactions on pat- tern analysis and machine intelligence39(12), 2481–2495 (2017)
Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pat- tern analysis and machine intelligence39(12), 2481–2495 (2017)
2017
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[6]
arXiv preprint arXiv:2102.04306 (2021)
Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., Lu, L., Yuille, A.L., Zhou, Y.:Transunet:Transformersmakestrongencodersformedicalimagesegmentation. arXiv preprint arXiv:2102.04306 (2021)
Pith/arXiv arXiv 2021
-
[7]
In: 2018 IEEE 15th international symposium on biomedical imaging (ISBI 2018)
Codella, N.C., Gutman, D., Celebi, M.E., Helba, B., Marchetti, M.A., Dusza, S.W., Kalloo, A., Liopyris, K., Mishra, N., Kittler, H., et al.: Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomed- ical imaging (isbi), hosted by the international skin imaging collaboration (isic). In: 2018 IEEE 15th intern...
2017
-
[8]
In: 2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV)
Damm, S., Laszkiewicz, M., Lederer, J., Fischer, A.: Anomalydino: Boosting patch- based few-shot anomaly detection with dinov2. In: 2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV). pp. 1319–1329. IEEE (2025)
2025
-
[9]
arXiv preprint arXiv:2508.20909 (2025) 10 S
Gao, Y., Li, H., Yuan, F., Wang, X., Gao, X.: Dino u-net: Exploiting high-fidelity dense features from foundation models for medical image segmentation. arXiv preprint arXiv:2508.20909 (2025) 10 S. Yang et al
Pith/arXiv arXiv 2025
-
[10]
Computers in biology and medicine155, 106389 (2023)
Gong, H., Chen, J., Chen, G., Li, H., Li, G., Chen, F.: Thyroid region prior guided attention for ultrasound segmentation of thyroid nodules. Computers in biology and medicine155, 106389 (2023)
2023
-
[11]
In: International con- ference on multimedia modeling
Jha, D., Smedsrud, P.H., Riegler, M.A., Halvorsen, P., De Lange, T., Johansen, D., Johansen, H.D.: Kvasir-seg: A segmented polyp dataset. In: International con- ference on multimedia modeling. pp. 451–462. Springer (2019)
2019
-
[12]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, C., Liu, X., Li, W., Wang, C., Liu, H., Liu, Y., Chen, Z., Yuan, Y.: U-kan makes strong backbone for medical image segmentation and generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4652–4660 (2025)
2025
-
[14]
IEEE transactions on pattern analysis and machine intelligence (2024)
Li, X., Ding, H., Yuan, H., Zhang, W., Pang, J., Cheng, G., Chen, K., Liu, Z., Loy, C.C.: Transformer-based visual segmentation: A survey. IEEE transactions on pattern analysis and machine intelligence (2024)
2024
-
[15]
Li, Y., Wu, Y., Lai, Y., Hu, M., Yang, X.: Meddinov3: How to adapt vision foun- dation models for medical image segmentation? arXiv preprint arXiv:2509.02379 (2025)
arXiv 2025
-
[16]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
2017
-
[17]
In: International conference on medical image computing and computer- assisted intervention
Liu, J., Yang, H., Zhou, H.Y., Xi, Y., Yu, L., Li, C., Liang, Y., Shi, G., Yu, Y., Zhang, S., et al.: Swin-umamba: Mamba-based unet with imagenet-based pre- training. In: International conference on medical image computing and computer- assisted intervention. pp. 615–625. Springer (2024)
2024
-
[18]
arXiv preprint arXiv:1711.05101 (2017)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
Pith/arXiv arXiv 2017
-
[19]
arXiv preprint arXiv:1804.03999 (2018)
Oktay, O., Schlemper, J., Folgoc, L.L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N.Y., Kainz, B., et al.: Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999 (2018)
Pith/arXiv arXiv 2018
-
[20]
arXiv preprint arXiv:2304.07193 (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Pith/arXiv arXiv 2023
-
[21]
Advances in neural information processing sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing sys- tems32(2019)
2019
-
[22]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[23]
arXiv preprint arXiv:2508.10104 (2025)
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
Pith/arXiv arXiv 2025
-
[24]
In: International conference on medical image computing and computer-assisted intervention
Valanarasu, J.M.J., Patel, V.M.: Unext: Mlp-based rapid medical image segmen- tation network. In: International conference on medical image computing and computer-assisted intervention. pp. 23–33. Springer (2022)
2022
-
[25]
IEEE Transactions on Medical Imaging43(12), 4078–4090 (2024) SegDINO: Multi-Scale Adaptation of DINOv3 for Medical Segmentation 11
Wang, H., Chen, J., Zhang, S., He, Y., Xu, J., Wu, M., He, J., Liao, W., Luo, X.: Dual-reference source-free active domain adaptation for nasopharyngeal carci- noma tumor segmentation across multiple hospitals. IEEE Transactions on Medical Imaging43(12), 4078–4090 (2024) SegDINO: Multi-Scale Adaptation of DINOv3 for Medical Segmentation 11
2024
-
[26]
IEEE Transactions on Medical Imaging (2025)
Wang, H., Chen, Y., Chen, W., Xu, H., Zhao, H., Sheng, B., Fu, H., Yang, G., Zhu, L.: Serp-mamba: Advancing high-resolution retinal vessel segmentation with selective state-space model. IEEE Transactions on Medical Imaging (2025)
2025
-
[27]
IEEE Transactions on Medical Imaging (2024)
Wang, H., Yang, G., Zhang, S., Qin, J., Guo, Y., Xu, B., Jin, Y., Zhu, L.: Video- instrument synergistic network for referring video instrument segmentation in robotic surgery. IEEE Transactions on Medical Imaging (2024)
2024
-
[28]
arXiv preprint arXiv:2508.14809 (2025)
Wang,S.,Safari,M.,Hu,M.,Li,Q.,Chang,C.W.,Qiu,R.L.,Yang,X.:Dinov3with test-time training for medical image registration. arXiv preprint arXiv:2508.14809 (2025)
arXiv 2025
-
[29]
In: Medical Imaging with Deep Learning
Wu, J., Fu, R., Fang, H., Zhang, Y., Yang, Y., Xiong, H., Liu, H., Xu, Y.: Med- segdiff: Medical image segmentation with diffusion probabilistic model. In: Medical Imaging with Deep Learning. pp. 1623–1639. PMLR (2024)
2024
-
[30]
Visual Intelligence4(1), 2 (2026)
Xiong, X., Wu, Z., Tan, S., Li, W., Tang, F., Chen, Y., Li, S., Ma, J., Li, G.: Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation. Visual Intelligence4(1), 2 (2026)
2026
-
[31]
IEEE Transactions on Pattern Analysis and Machine In- telligence (2025)
Yang, L., Zhao, Z., Zhao, H.: Unimatch v2: Pushing the limit of semi-supervised semantic segmentation. IEEE Transactions on Pattern Analysis and Machine In- telligence (2025)
2025
-
[32]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, S., Hu, X., Wu, Q., Yang, D.: Vaevq: Enhancing discrete visual tokenization through variational modeling. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 11703–11711 (2026)
2026
-
[33]
arXiv preprint arXiv:2601.10124 (2026)
Yang, S., Xing, Z., Zhu, L.: Vq-seg: Vector-quantized token perturbation for semi- supervised medical image segmentation. arXiv preprint arXiv:2601.10124 (2026)
arXiv 2026
-
[34]
Communications of the ACM 64(3), 107–115 (2021)
Zhang, C., Bengio, S., Hardt, M., Recht, B., Vinyals, O.: Understanding deep learning (still) requires rethinking generalization. Communications of the ACM 64(3), 107–115 (2021)
2021
-
[35]
Zhou, T., Xia, W., Zhang, F., Chang, B., Wang, W., Yuan, Y., Konukoglu, E., Cremers,D.:Imagesegmentationinfoundationmodelera:Asurvey.arXivpreprint arXiv:2408.12957 (2024)
arXiv 2024
-
[36]
Advances in Neural Information Processing Systems 37, 12612–12635 (2024)
Zhu, L., Wei, F., Lu, Y., Chen, D.: Scaling the codebook size of vq-gan to 100,000 with a utilization rate of 99%. Advances in Neural Information Processing Systems 37, 12612–12635 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.