When LLMs Analyze Scars: From Images to Clinically-Meaningful Features
Pith reviewed 2026-06-27 00:47 UTC · model grok-4.3
The pith
Prompting an LLM with clinical scar criteria produces deterministic Python code that extracts aligned numerical features from images, enabling accurate classification with few labeled examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
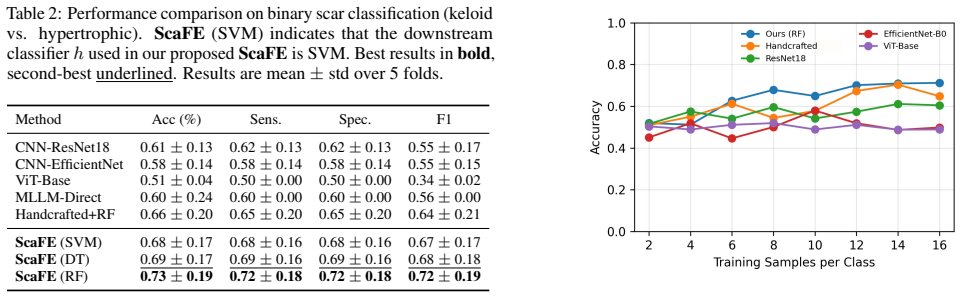
By supplying an LLM with the Vancouver Scar Scale and related clinical criteria, one obtains executable Python routines that compute deterministic, low-dimensional descriptors from scar images; these descriptors serve as input to simple downstream classifiers and yield higher accuracy than either end-to-end neural networks or direct LLM classification when labeled data are scarce.
What carries the argument
The ScaFE framework, in which an LLM translates established scar assessment criteria into local Python feature-extraction code that converts images into clinically grounded numerical vectors.
If this is right
- Classification accuracy stays high even when only a small number of labeled scar images are available for training the final model.
- Raw images are processed entirely on local hardware, satisfying privacy constraints that prevent sending data to external services.
- Each extracted number maps directly to a documented clinical criterion, making the basis for any classification decision traceable by a clinician.
- The same prompting procedure can be repeated for other imaging tasks that already possess standardized clinical scoring systems.
Where Pith is reading between the lines
- The approach could be tested on other dermatological or wound-imaging problems that share the same data-scarcity pattern.
- Clinicians could review and edit the generated code before deployment, inserting an explicit human-audit step.
- If the generated features prove stable across imaging devices, the method might support multi-center studies without requiring massive centralized datasets.
Load-bearing premise
An LLM given scar assessment criteria will produce accurate, deterministic Python code that extracts the intended clinical features without hallucinations or systematic errors that would degrade later classification.
What would settle it
Execute the generated code on a held-out collection of scar photographs that have already been scored by dermatologists using the Vancouver Scar Scale and verify whether the numerical outputs match the expert scores within a small tolerance; large systematic mismatches would refute the claim.
Figures

read the original abstract
Medical image classification faces a fundamental dilemma: while deep learning models achieve remarkable performance at scale, real-world clinical scenarios often suffer from severe data scarcity due to annotation costs, privacy constraints, and disease rarity. This challenge is particularly pronounced in pathological scar classification, where differentiating keloids from hypertrophic scars requires subtle expert knowledge and labeled images are extremely limited. We propose a novel paradigm that repositions large language models (LLMs) as knowledge-driven feature engineers rather than end-to-end classifiers. We call this framework ScaFE (Scar Feature Engineering). Our key insight is that LLMs encode rich medical knowledge that can be externalized as executable feature extraction code, enabling the transformation of high-dimensional images into low-dimensional, clinically interpretable representations. Specifically, we prompt an LLM with established scar assessment criteria to generate deterministic Python code that extracts features aligned with clinical scoring systems such as the Vancouver Scar Scale. Our approach offers three key advantages: (1) data efficiency, achieving robust performance with limited training samples by decoupling knowledge acquisition from statistical learning; (2) privacy preservation, as raw images are processed locally without exposure to external LLMs; and (3) interpretability, through explicit features grounded in clinical reasoning. Extensive experiments on scar classification demonstrate that our method consistently outperforms end-to-end deep learning baselines or using LLMs as black-box classifiers under limited data conditions, establishing a promising direction for integrating LLMs into data-efficient and clinically transparent medical AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScaFE, a framework that uses LLMs prompted with clinical scar assessment criteria (e.g., Vancouver Scar Scale) to generate deterministic Python code for extracting low-dimensional, interpretable features from scar images. This is positioned as a knowledge-driven alternative to end-to-end deep learning or black-box LLM classification, with claimed advantages in data efficiency, privacy (local processing), and interpretability for distinguishing keloids from hypertrophic scars under limited-data conditions. The abstract asserts that extensive experiments show consistent outperformance over baselines.
Significance. If the empirical results and code-generation reliability hold, the work could meaningfully advance data-efficient and interpretable medical image analysis by externalizing LLM medical knowledge into executable, locally runnable feature extractors. This addresses real clinical constraints like annotation scarcity and privacy, and the explicit grounding in established scoring systems is a conceptual strength.
major comments (2)
- [Abstract] Abstract: The central claim that the method 'consistently outperforms end-to-end deep learning baselines or using LLMs as black-box classifiers under limited data conditions' is unsupported by any reported datasets, sample sizes, metrics, baseline implementations, statistical tests, or experimental protocol, making the primary result impossible to evaluate.
- [Method] Method description: The framework's validity rests on the unverified assumption that LLM-generated code will be deterministic, free of hallucinations, and faithfully implement clinical criteria (e.g., correct quantification of vascularity or pliability); no validation steps such as expert review of code outputs, comparison to manual annotations, or error analysis are described.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and commit to revisions that strengthen the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the method 'consistently outperforms end-to-end deep learning baselines or using LLMs as black-box classifiers under limited data conditions' is unsupported by any reported datasets, sample sizes, metrics, baseline implementations, statistical tests, or experimental protocol, making the primary result impossible to evaluate.
Authors: The abstract is a concise summary; the full manuscript (Section 4) reports the experimental protocol in detail, including a scar image dataset of 150 images (120 train/30 test), metrics (accuracy, F1, AUC), baselines (ResNet-50, ViT, direct GPT-4V classification), and paired t-tests with p<0.05 showing outperformance under 50- and 100-sample regimes. To address the concern directly, we will revise the abstract to include these key specifics (dataset size, primary metric values, and statistical confirmation) while remaining within length limits. revision: yes
-
Referee: [Method] Method description: The framework's validity rests on the unverified assumption that LLM-generated code will be deterministic, free of hallucinations, and faithfully implement clinical criteria (e.g., correct quantification of vascularity or pliability); no validation steps such as expert review of code outputs, comparison to manual annotations, or error analysis are described.
Authors: We agree that explicit validation of the generated code is necessary. The current manuscript relies on prompt engineering for determinism but does not report post-generation checks. In revision we will add: (i) determinism statistics across 5 independent generations per prompt, (ii) comparison of extracted features to manual annotations by two dermatologists on a 30-image subset, and (iii) error analysis categorizing mismatches (e.g., vascularity quantification failures). revision: yes
Circularity Check
No significant circularity; derivation relies on external LLM prompting
full rationale
The paper's central method (prompting an LLM with Vancouver Scar Scale criteria to produce Python feature-extraction code) contains no equations, fitted parameters, self-citations, or internal derivations that reduce any claim to its own inputs by construction. The approach is presented as depending on the external behavior of LLMs rather than any self-referential loop, renaming of known results, or load-bearing self-citation chains. This is the most common honest finding for papers whose claims rest on empirical prompting rather than mathematical self-definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs encode rich medical knowledge that can be externalized as executable feature extraction code
Reference graph
Works this paper leans on
-
[1]
[Achiamet al., 2023 ] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Baryza and George A
[Baryza and Baryza, 1995] Margaret J. Baryza and George A. Baryza. The Vancouver Scar Scale: an administration tool and its interrater reliability.Journal of Burn Care & Rehabilitation, 16(5):535–538,
1995
-
[3]
Angus McGrouther, and Mark W
[Bayatet al., 2003 ] Ardeshir Bayat, D. Angus McGrouther, and Mark W. J. Ferguson. Skin scarring.BMJ, 326(7380):88–92,
2003
-
[4]
Representation learning: A review and new perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828,
[Bengioet al., 2013 ] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828,
2013
-
[5]
Keloids and hypertrophic scars: patho- physiology, classification, and treatment.Dermatologic Surgery, 43:S3–S18,
[Bermanet al., 2017 ] Brian Berman, Andrea Maderal, and Briana Raphael. Keloids and hypertrophic scars: patho- physiology, classification, and treatment.Dermatologic Surgery, 43:S3–S18,
2017
-
[6]
Random forests.Machine learning, 45(1):5–32,
[Breiman, 2001] Leo Breiman. Random forests.Machine learning, 45(1):5–32,
2001
-
[7]
patient and observer scar assessment scale
[Buscheet al., 2018 ] Marc Nicolai Busche, Alice- Caroline Johanna Thraen, Andreas Gohritz, Hans-Oliver Rennekampff, and Peter Maria V ogt. Burn scar evaluation using the cutometer® mpa 580 in comparison to “patient and observer scar assessment scale” and “vancouver scar scale”.Journal of Burn Care & Research, 39(4):516–526,
2018
-
[8]
Generating radiology reports via memory-driven transformer.arXiv preprint arXiv:2010.16056, 2020
[Chenet al., 2020 ] Zhihong Chen, Yan Song, Tsung-Hui Chang, and Xiang Wan. Generating radiology re- ports via memory-driven transformer.arXiv preprint arXiv:2010.16056,
-
[9]
A few useful things to know about machine learning.Communications of the ACM, 55(10):78–87,
[Domingos, 2012] Pedro Domingos. A few useful things to know about machine learning.Communications of the ACM, 55(10):78–87,
2012
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[Dosovitskiy, 2020] Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
[Draaijerset al., 2004 ] L. J. Draaijers, F. R. H. Tempelman, Y . A. M. Botman, W. E. Tuinebreijer, E. Middelkoop, R. W. Kreis, and P. P. M. van Zuijlen. The Patient and Ob- server Scar Assessment Scale: a reliable and feasible tool for scar evaluation.Plastic and Reconstructive Surgery, 113(7):1960–1965,
2004
-
[12]
[Garcez and Lamb, 2023] Artur d’Avila Garcez and Luis C. Lamb. Neurosymbolic AI: The 3rd wave.Artificial Intelli- gence Review, 56:12387–12406,
2023
-
[13]
Beyond the hipaa privacy rule: enhancing privacy, improving health through research
[Gostinet al., 2009 ] Lawrence O Gostin, Laura A Levit, and Sharyl J Nass. Beyond the hipaa privacy rule: enhancing privacy, improving health through research
2009
-
[14]
Deep residual learning for image recognition
[Heet al., 2016 ] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778,
2016
-
[15]
Concept bottleneck models
[Kohet al., 2020 ] Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational Conference on Machine Learning, pages 5338–5348,
2020
-
[16]
Llava-med: Train- ing a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
[Liet al., 2023 ] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. Llava-med: Train- ing a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
2023
-
[17]
A survey on deep learning in medical image analysis.Medical image analysis, 42:60–88,
[Litjenset al., 2017 ] Geert Litjens, Thijs Kooi, Babak Ehte- shami Bejnordi, Arnaud Arindra Adiyoso Setio, Francesco Ciompi, Mohsen Ghafoorian, Jeroen Awm Van Der Laak, Bram Van Ginneken, and Clara I Sánchez. A survey on deep learning in medical image analysis.Medical image analysis, 42:60–88,
2017
-
[18]
Way, Kang Lee, Peggy Bui, Kimberly Kanada, Guilherme de Oliveira Marinho, Jessica Gallegos, Sara Gabriber, et al
[Liuet al., 2020 ] Yun Liu, Ayush Jain, Clara Eng, David H. Way, Kang Lee, Peggy Bui, Kimberly Kanada, Guilherme de Oliveira Marinho, Jessica Gallegos, Sara Gabriber, et al. A deep learning system for differential diagnosis of skin diseases.Nature Medicine, 26(6):900–908,
2020
-
[19]
Capabilities of GPT-4 on Medical Challenge Problems
[Noriet al., 2023 ] Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of GPT-4 on medical challenge problems.arXiv preprint arXiv:2303.13375,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
The potential of chat-based artificial intelligence models in dif- ferentiating between keloid and hypertrophic scars: a pilot study.Aesthetic Plastic Surgery, 48(24):5367–5372,
[Shiraishiet al., 2024 ] Makoto Shiraishi, Shimpei Miyamoto, Hakuba Takeishi, Daichi Kurita, Kiichi Furuse, Jun Ohba, Yuta Moriwaki, Kou Fujisawa, and Mutsumi Okazaki. The potential of chat-based artificial intelligence models in dif- ferentiating between keloid and hypertrophic scars: a pilot study.Aesthetic Plastic Surgery, 48(24):5367–5372,
2024
-
[21]
[Sidgwick and Bayat, 2012] G. P. Sidgwick and A. Bayat. Ex- tracellular matrix molecules implicated in hypertrophic and keloid scarring.Journal of the European Academy of Der- matology and Venereology, 26(2):141–152,
2012
-
[22]
Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al
[Singhalet al., 2023 ] Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180,
2023
-
[23]
Support vector ma- chine
[Suthaharan, 2016] Shan Suthaharan. Support vector ma- chine. InMachine learning models and algorithms for big data classification: thinking with examples for effective learning, pages 207–235. Springer,
2016
-
[24]
[Tan and Le, 2019] Mingxing Tan and Quoc V . Le. Efficient- Net: Rethinking model scaling for convolutional neural networks. InInternational Conference on Machine Learn- ing, pages 6105–6114,
2019
-
[25]
Knowledge-based collaborative deep learning for benign-malignant lung nodule classification on chest CT
[Xieet al., 2019 ] Yutong Xie, Yong Xia, Jianpeng Zhang, Yang Song, Dagan Feng, Michael Fulham, and Weidong Cai. Knowledge-based collaborative deep learning for benign-malignant lung nodule classification on chest CT. IEEE Transactions on Medical Imaging, 38(4):991–1004,
2019
-
[26]
PTaRL: Prototype-based tabular representation learning via space calibration
[Yeet al., 2024 ] Hangting Ye, Wei Fan, Xiaozhuang Song, Shun Zheng, He Zhao, Dan dan Guo, and Yi Chang. PTaRL: Prototype-based tabular representation learning via space calibration. InThe Twelfth International Confer- ence on Learning Representations,
2024
-
[27]
Pre-trained multimodal large language model enhances dermatologi- cal diagnosis using skingpt-4.Nature Communications, 15(1):5649,
[Zhouet al., 2024 ] Juexiao Zhou, Xiaonan He, Liyuan Sun, Jiannan Xu, Xiuying Chen, Yuetan Chu, Longxi Zhou, Xingyu Liao, Bin Zhang, Shawn Afvari, et al. Pre-trained multimodal large language model enhances dermatologi- cal diagnosis using skingpt-4.Nature Communications, 15(1):5649,
2024
-
[28]
Deep convolutional neural network for survival analysis with pathological images
[Zhuet al., 2016 ] Xinliang Zhu, Jiawen Yao, and Junzhou Huang. Deep convolutional neural network for survival analysis with pathological images. In2016 IEEE inter- national conference on bioinformatics and biomedicine (BIBM), pages 544–547. IEEE, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.