Next-Turn: Duration-Aware Streaming Endpoint Detection via Time-to-Next-Speech-Onset Prediction
Pith reviewed 2026-06-26 22:40 UTC · model grok-4.3
The pith
A streaming endpoint detector trained to predict time until next speech onset outperforms acoustic and semantic baselines without extra labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Next-Turn shows that training on the time-to-next-speech-onset objective supplies unambiguous supervision for streaming endpoint detection. Targets come directly from speech timestamps, satisfy strict latency limits, and produce higher endpoint accuracy within short windows than acoustic or recent semantic baselines. When the same model is trained jointly with conventional binary detection, performance improves further as pause lengths increase.
What carries the argument
The time-to-next-speech-onset regression objective, which generates training targets from speech timestamps alone.
If this is right
- Endpoint accuracy within 320 ms rises by 25.9 percentage points over the strongest prior baseline.
- Joint training with binary endpoint detection produces gains that increase steadily with longer pauses.
- No additional human annotation is needed beyond the speech timestamps already present in the data.
- The method meets streaming constraints while reducing errors caused by hesitations and disfluencies.
Where Pith is reading between the lines
- Voice interfaces could wait longer during natural pauses without risking missed turns.
- The same timestamp-derived target might transfer to other real-time audio segmentation tasks.
- Results on multi-speaker or accented data would test whether timestamp quality limits the gains.
- Adding language-model context could further sharpen the onset-time predictions.
Load-bearing premise
Speech timestamps supply enough clear information to train models that correctly mark utterance ends even when speakers pause mid-turn.
What would settle it
An evaluation on new utterances where the time-to-next-speech-onset model shows no accuracy advantage, or lower accuracy, than the strongest baseline for endpoint decisions reached inside 320 ms.
Figures


read the original abstract
Endpoint detection (EPD) is essential for natural turn-taking in streaming speech systems. However, reliably determining the endpoint of an utterance is challenging because speakers often pause mid-utterance due to hesitations and disfluencies. Semantic EPD has emerged as a promising direction to address this issue but is hindered by ambiguous supervision and strict streaming constraints. We propose Next-Turn that uses the time-to-next-speech-onset as the training objective, where targets are derived directly from speech timestamps and require no additional annotation. Experiments show that the proposed method outperforms conventional acoustic and recent semantic EPD baselines, achieving a 25.9% absolute improvement in endpoint accuracy within 320 ms over the strongest baseline. In addition, joint training with the duration-aware objective complements standard binary EPD, with gains that increase monotonically with increasing pauses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Next-Turn, a streaming endpoint detection method that trains on a time-to-next-speech-onset regression objective whose targets are derived directly from speech timestamps (no additional annotation required). It claims this duration-aware objective outperforms both conventional acoustic EPD and recent semantic EPD baselines, delivering a 25.9% absolute gain in endpoint accuracy within 320 ms over the strongest baseline, and that joint training with standard binary EPD yields monotonically increasing gains as pause length grows.
Significance. If the experimental claims are substantiated, the work would be significant: it supplies a lightweight, annotation-free supervision signal that explicitly models utterance duration and thereby addresses the core difficulty of mid-utterance disfluencies under strict streaming constraints. The monotonic improvement with pause length, if reproducible, would constitute a falsifiable prediction that distinguishes the approach from prior semantic EPD methods.
major comments (2)
- [Abstract] Abstract: the central claim of a 25.9% absolute improvement in endpoint accuracy within 320 ms is stated without any description of model architecture, training procedure, dataset, baseline implementations, or the precise definition of the accuracy metric, rendering the support for the primary result impossible to evaluate.
- [Abstract] Abstract: the assertion that timestamp-derived targets supply unambiguous supervision for disfluent pauses is load-bearing for attributing the reported gains to the duration-aware objective rather than label artifacts, yet the text provides no information on onset definition, VAD threshold, or handling of multiple short pauses within a single disfluency.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our manuscript. We address the major comments point by point below, indicating where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 25.9% absolute improvement in endpoint accuracy within 320 ms is stated without any description of model architecture, training procedure, dataset, baseline implementations, or the precise definition of the accuracy metric, rendering the support for the primary result impossible to evaluate.
Authors: We acknowledge that the abstract, due to its length constraints, does not include these experimental details. These are described in the Methods and Experiments sections of the full manuscript. To address the concern and make the primary result more evaluable from the abstract, we will revise the abstract to include brief mentions of the model architecture, training procedure, dataset, baselines, and the definition of the accuracy metric. revision: yes
-
Referee: [Abstract] Abstract: the assertion that timestamp-derived targets supply unambiguous supervision for disfluent pauses is load-bearing for attributing the reported gains to the duration-aware objective rather than label artifacts, yet the text provides no information on onset definition, VAD threshold, or handling of multiple short pauses within a single disfluency.
Authors: The targets are derived from speech timestamps obtained via forced alignment on the audio recordings, which provides direct and unambiguous next-onset times without manual annotation for disfluencies. However, we agree that the manuscript lacks explicit details on the precise onset definition, VAD threshold used for timestamp extraction, and handling of multiple short pauses in disfluencies. We will add this information to Section 3.2 of the revised manuscript, specifying the VAD parameters, the rule for selecting the next onset, and how clustered pauses are treated. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines its core training objective (time-to-next-speech-onset) directly from existing speech timestamps with no additional annotation required. This is a standard label extraction step in supervised learning and does not reduce any claimed prediction or result to the input by construction. No equations, self-citations, or uniqueness claims are shown that would create self-definitional, fitted-input, or load-bearing citation loops. The reported gains are presented as empirical comparisons against external baselines, satisfying the criteria for a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Speech timestamps can be used to derive targets for time-to-next-speech-onset without additional annotation.
- domain assumption The method satisfies strict streaming constraints while using the new objective.
Reference graph
Works this paper leans on
-
[1]
Next-Turn: Duration-Aware Streaming Endpoint Detection via Time-to-Next-Speech-Onset Prediction
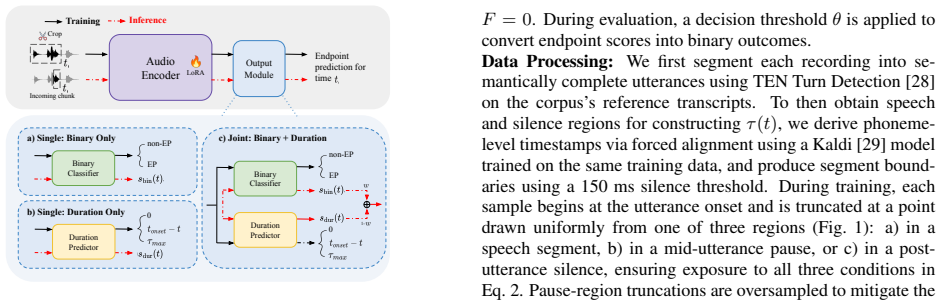
Introduction The growing demand for highly interactive speech interfaces has driven widespread adoption of streaming speech models, particularly for full-duplex conversation [1, 2, 3] and real-time speech translation [4, 5]. In these settings, the ability to deter- mine when a user has finished a meaningful speech unit is crit- ical for both perceived res...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Binary Endpoint Detection We first describe the binary semantic EPD, which serves both as a baseline and as the foundation for the duration-aware ex- tension in Section 3. 2.1. Binary Formulation Binary EPD aims to determine whether an utterance has reached endpoint by timet. Lett end denote the time when the speech ends. We define the binary targety(t)as...
-
[3]
The duration prediction objective can be used either as an alter- native to the binary formulation or jointly with it during train- ing
Duration-Aware Endpoint Detection We propose a semantic EPD framework based on time-to-next- onset prediction, which provides graded temporal supervision. The duration prediction objective can be used either as an alter- native to the binary formulation or jointly with it during train- ing. All duration-aware variants use the same architecture as the bina...
-
[4]
Dataset We train on an in-house corpus of 1,177 hours of Chi- nese speech (1,097,898 utterances), spanning conversational, command-style, and question–answer scenarios, at 16 kHz
Experiments 4.1. Dataset We train on an in-house corpus of 1,177 hours of Chi- nese speech (1,097,898 utterances), spanning conversational, command-style, and question–answer scenarios, at 16 kHz. The training set shows a long-tailed distribution over pause counts. For evaluation, we hold out 1,185 utterances disjoint from the training data and manually l...
-
[5]
LoRA matrices with rank r=8, scaling factorα=32, and dropoutp=0.05are inserted into the query, key, and value projections of every encoder block
encoder unless otherwise stated. LoRA matrices with rank r=8, scaling factorα=32, and dropoutp=0.05are inserted into the query, key, and value projections of every encoder block. Models are optimized with AdamW (β1=0.9,β 2=0.98, weight decay0.1) using a learning rate of1×10 −4, batch size of 32 across 8 GPUs with 4-step gradient accumulation, bf16 mixed p...
-
[6]
Conclusion We presented Next-Turn, a duration-aware streaming EPD framework that predicts the time-to-next-speech-onset as a supervision signal derived directly from speech timestamps. Experiments show that the proposed approach outperforms conventional acoustic and recent semantic EPD baselines, achieving a 25.9% absolute improvement inACC 320 over the s...
-
[7]
All AI-assisted content was reviewed and edited by the authors
Use of Generative AI Disclosure Generative AI tools were used for minor editing and language improvement. All AI-assisted content was reviewed and edited by the authors
-
[8]
FlexDuo: A pluggable system for enabling full- duplex capabilities in speech dialogue systems,
B. Liao, Y . Xu, J. Ou, K. Yang, W. Jian, P. Wan, and D. Zhang, “FlexDuo: A pluggable system for enabling full- duplex capabilities in speech dialogue systems,”arXiv preprint arXiv:2502.13472, 2025
-
[9]
J. Chen, Y . Hu, J. Li, K. Li, K. Liu, W. Li, Z. Li, F. Shen, X. Tang, M. Wei, Y . Wu, F. Xie, K. Xu, and K. Xie, “FireRed- Chat: A pluggable, full-duplex voice interaction system with cascaded and semi-cascaded implementations,”arXiv preprint arXiv:2509.06502, 2025
-
[10]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: A speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Seamless: Multilingual expressive and streaming speech translation,
Seamless Communication, L. Barrault, Y .-A. Chung, M. C. Meglioli, D. Dale, N. Dong, M. Duppenthaler, P.-A. Duquenne, B. Ellis, H. Elsaharet al., “Seamless: Multilingual expressive and streaming speech translation,”arXiv preprint arXiv:2312.05187, 2023
-
[12]
Simulspeech: End-to-end simultaneous speech to text translation,
Y . Ren, J. Liu, X. Tan, C. Zhang, T. Qin, Z. Zhao, and T.-Y . Liu, “Simulspeech: End-to-end simultaneous speech to text translation,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, jul 2020, pp. 3787–3796. [Online]. Available: https://aclanthology.org/2020.acl-...
2020
-
[13]
Recurrent neural networks for voice activity detection,
T. Hughes and K. Mierle, “Recurrent neural networks for voice activity detection,” inProc. ICASSP, 2013, pp. 7378–7382
2013
-
[14]
Deep belief networks based voice activity detection,
X. Zhang and J. Wu, “Deep belief networks based voice activity detection,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 4, pp. 697–710, 2013. [Online]. Available: https://doi.org/10.1109/TASL.2012.2229986
-
[15]
Speech activity detection on youtube using deep neural networks,
N. Ryant, M. Liberman, and J. Yuan, “Speech activity detection on youtube using deep neural networks,” inInterspeech 2013, 2013, pp. 728–731. [Online]. Available: https://www. isca-archive.org/interspeech 2013/ryant13 interspeech.html
2013
-
[16]
Is the speaker done yet? Faster and more accurate end-of-utterance detection using prosody,
L. Ferrer, E. Shriberg, and A. Stolcke, “Is the speaker done yet? Faster and more accurate end-of-utterance detection using prosody,” inProc. ICSLP, 2002
2002
-
[17]
A statistical model-based voice activity detection,
J. Sohn, N. S. Kim, and W. Sung, “A statistical model-based voice activity detection,”IEEE Signal Processing Letters, vol. 6, no. 1, pp. 1–3, 1999
1999
-
[18]
Pauses, gaps and overlaps in conver- sations,
M. Heldner and J. Edlund, “Pauses, gaps and overlaps in conver- sations,”Journal of Phonetics, vol. 38, no. 4, pp. 555–568, 2010
2010
-
[19]
Towards fast and accurate streaming end-to-end ASR,
B. Li, S.-y. Chang, T. N. Sainath, R. Pang, Y . He, T. Strohman, and Y . Wu, “Towards fast and accurate streaming end-to-end ASR,” inProc. ICASSP, 2020, pp. 6069–6073. [Online]. Available: https://ieeexplore.ieee.org/document/9054715
-
[20]
E2e segmenter: Joint segmenting and decoding for long-form ASR,
W. R. Huang, S.-Y . Chang, D. Rybach, T. N. Sainath, R. Prabhavalkar, C. Peyser, Z. Lu, and C. Allauzen, “E2e segmenter: Joint segmenting and decoding for long-form ASR,” inInterspeech 2022, 2022, pp. 4995–4999. [On- line]. Available: https://www.isca-archive.org/interspeech 2022/ huang22 interspeech.html
2022
-
[21]
Turn-taking and backchan- nel prediction with acoustic and large language model fusion,
J. Wang, L. Chen, A. Khare, A. Raju, P. Dheram, D. He, M. Wu, A. Stolcke, and V . Ravichandran, “Turn-taking and backchan- nel prediction with acoustic and large language model fusion,” in Proc. ICASSP, 2024
2024
-
[22]
LLM-Enhanced Dialogue Management for Full-Duplex Spoken Dialogue Systems
H. Zhang, W. Li, R. Chen, V . Kothapally, M. Yu, and D. Yu, “LLM-enhanced dialogue management for full-duplex spoken di- alogue systems,”arXiv preprint arXiv:2502.14145, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Unified end-to-end speech recognition and endpointing for fast and efficient speech systems,
S. Bijwadia, S.-y. Chang, B. Li, T. N. Sainath, C. Zhang, and Y . He, “Unified end-to-end speech recognition and endpointing for fast and efficient speech systems,” inProc. IEEE SLT, 2022, pp. 310–316
2022
-
[24]
Phoenix-V AD: Streaming semantic end- point detection for full-duplex speech interaction,
W. Wu, W. Guan, K. Wang, P. Chen, Z. Zha, J. Li, J. Fang, L. Li, and Q. Hong, “Phoenix-V AD: Streaming semantic end- point detection for full-duplex speech interaction,”arXiv preprint arXiv:2509.20410, 2025
-
[25]
G. Li, C. Wang, H. Xue, S. Wang, D. Gao, Z. Zhang, Y . Lin, W. Li, L. Xiao, Z. Fu, and L. Xie, “Easy turn: Integrating acoustic and linguistic modalities for robust turn-taking in full-duplex spoken dialogue systems,”arXiv preprint arXiv:2509.23938, 2025
-
[26]
Semantic V AD: Low-latency voice activity detection for speech interaction,
M. Shi, Y . Shu, L. Zuo, Q. Chen, S. Zhang, J. Zhang, and L.- R. Dai, “Semantic V AD: Low-latency voice activity detection for speech interaction,”arXiv preprint arXiv:2305.12450, 2023
-
[27]
Two-pass endpoint detection for speech recognition,
A. Raju, A. Khare, D. He, I. Sklyar, L. Chen, S. Alptekin, V . A. Trinh, Z. Zhang, C. Vaz, V . Ravichandran, R. Maas, and A. Rastrow, “Two-pass endpoint detection for speech recognition,”arXiv preprint arXiv:2401.08916, 2024. [Online]. Available: https://arxiv.org/pdf/2401.08916
-
[28]
Accurate endpointing with expected pause duration,
B. Liu, B. Hoffmeister, and A. Rastrow, “Accurate endpointing with expected pause duration,” inInterspeech 2015, 2015, pp. 2912–2916. [Online]. Available: https://www.isca-archive.org/ interspeech 2015/liu15d interspeech.html
2015
-
[29]
Projecting the end of a speaker’s turn: A cognitive cornerstone of conversation,
J. P. De Ruiter, H. Mitterer, and N. J. Enfield, “Projecting the end of a speaker’s turn: A cognitive cornerstone of conversation,”Lan- guage, vol. 82, no. 3, pp. 515–535, 2006
2006
-
[30]
V oice activity projection: Self- supervised learning of turn-taking events,
E. Ekstedt and G. Skantze, “V oice activity projection: Self- supervised learning of turn-taking events,”arXiv preprint arXiv:2205.09812, 2022
-
[31]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. ICML, 2023
2023
-
[32]
LoRA: Low-rank adaptation of large lan- guage models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large lan- guage models,” inProc. ICLR, 2022
2022
-
[33]
Rectified linear units improve restricted boltzmann machines,
V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” inProceedings of the 27th International Conference on Machine Learning (ICML), 2010, pp. 807–814
2010
-
[34]
Dropout: A simple way to prevent neural net- works from overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural net- works from overfitting,”Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014
1929
-
[35]
TEN turn detection,
TEN Framework, “TEN turn detection,” https://github.com/ ten-framework/ten-turn-detection, 2024
2024
-
[36]
The Kaldi speech recognition toolkit,
D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motl´ıˇcek, Y . Qian, P. Schwarzet al., “The Kaldi speech recognition toolkit,” inProc. ASRU, 2011
2011
-
[37]
Silero V AD: pre-trained enterprise-grade voice activity detector,
S. Team, “Silero V AD: pre-trained enterprise-grade voice activity detector,” 2021
2021
-
[38]
Smart turn: Audio-only turn-taking detection,
Pipecat AI, “Smart turn: Audio-only turn-taking detection,” https: //github.com/pipecat-ai/smart-turn, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.