The Stanford EDGAR Filings Dataset: Reconstructing U.S. Corporate and Financial Disclosures into Layout-Faithful and Token-Efficient Pretraining Data
Pith reviewed 2026-06-27 00:39 UTC · model grok-4.3
The pith
Reconstruction of SEC filings produces a 152 billion token open dataset in layout-faithful MultiMarkdown for financial pretraining and evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
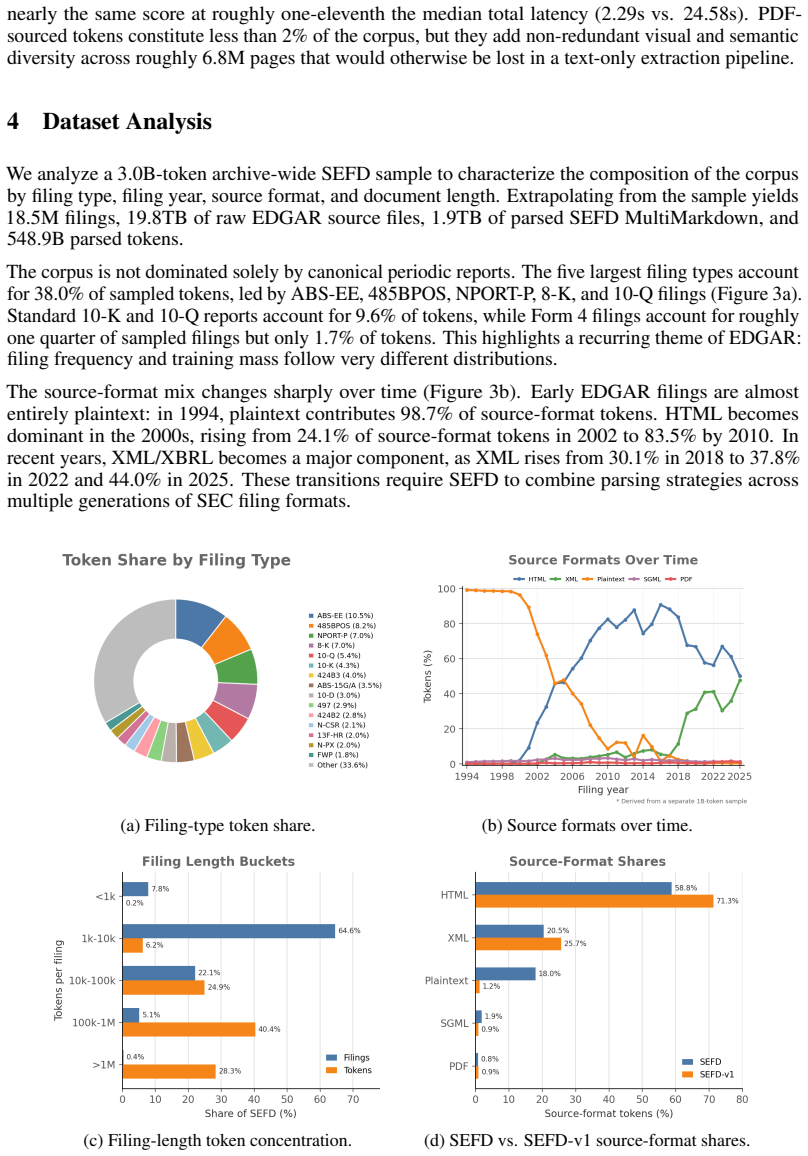
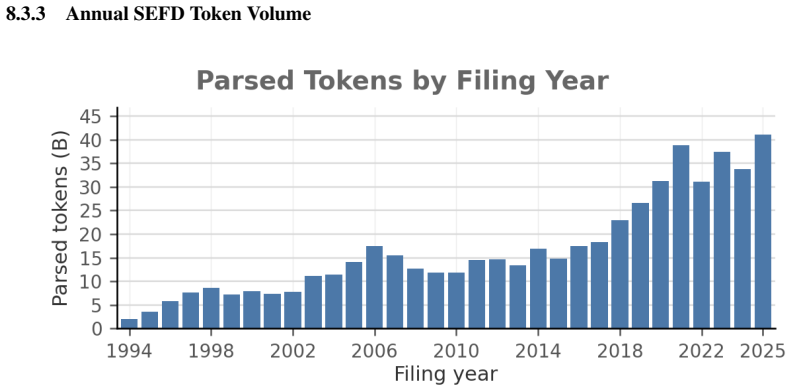
SEFD is an open reconstruction of SEC filings into layout-faithful MultiMarkdown for financial language modeling and evaluation. The resulting corpus is token-efficient, model-ready, and has less than 0.1% overlap with Common Crawl-derived corpora. SEFD-v1 is a 152B-token initial public snapshot, with corpus-level analyses of a larger 18.5M-filing archive estimated at 550B tokens. Two SEFD-derived benchmarks are introduced: EDGAR-Forecast for filing-grounded numerical forecasting after model knowledge cutoffs, and EDGAR-OCR for transcription of complex financial tables.
What carries the argument
The automated reconstruction of raw EDGAR filings into layout-faithful MultiMarkdown that preserves semantic content, tables, and structure.
If this is right
- SEFD supplies clean long-context documents usable directly for pretraining language models on financial and corporate disclosures.
- The low overlap with existing web corpora allows models to access novel data without duplication of Common Crawl content.
- EDGAR-Forecast provides a benchmark for testing numerical forecasting grounded in post-cutoff filings.
- EDGAR-OCR provides a benchmark for evaluating transcription accuracy on complex financial tables.
- The full 18.5 million filing archive can support further scaling of financial language models beyond the 152B token snapshot.
Where Pith is reading between the lines
- If reconstruction fidelity holds, organizations could build financial-specialized models at lower cost than with proprietary or synthetic data.
- The same reconstruction approach might apply to other public regulatory archives to generate additional domain-specific pretraining sources.
- Models trained on SEFD could be tested for improved handling of ownership reports and risk disclosures compared to general web data.
Load-bearing premise
The automated reconstruction process from raw EDGAR filings into MultiMarkdown preserves semantic content, table structure, and layout with sufficient fidelity for direct use in pretraining and benchmark evaluation without introducing material distortions or omissions.
What would settle it
A manual audit of reconstructed filings that finds frequent omissions of numerical values or table structures sufficient to degrade performance on the EDGAR-Forecast or EDGAR-OCR benchmarks relative to raw PDF inputs.
Figures





read the original abstract
As high-quality public web corpora become increasingly exhausted, clean long-context documents have become a scarce and expensive source of training data for large language models (LLMs). Existing long-context corpora are often proprietary and costly to acquire, synthetically generated, or concentrated in narrow domains such as programming. We introduce the Stanford EDGAR Filings Dataset (SEFD), an open reconstruction of SEC filings into layout-faithful MultiMarkdown for financial language modeling and evaluation. SEFD makes audited financial statements, risk disclosures, ownership reports, accounting notes, and market-moving event filings usable as long-context pretraining data and as a basis for financial reasoning, forecasting, compliance, and document understanding. The resulting corpus is token-efficient, model-ready, and has less than 0.1% overlap with Common Crawl-derived corpora. We release SEFD-v1, a 152B-token initial public snapshot, and provide corpus-level analyses of a larger 18.5M-filing archive estimated at 550B tokens. We further introduce two SEFD-derived benchmarks: EDGAR-Forecast, which evaluates filing-grounded numerical forecasting after model knowledge cutoffs, and EDGAR-OCR, which evaluates transcription of complex financial tables.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Stanford EDGAR Filings Dataset (SEFD), an open reconstruction of SEC filings into layout-faithful MultiMarkdown yielding a 152B-token corpus (SEFD-v1) with <0.1% overlap to Common Crawl-derived corpora. It provides corpus-level analyses of an 18.5M-filing archive estimated at 550B tokens and releases two derived benchmarks: EDGAR-Forecast for filing-grounded numerical forecasting after knowledge cutoffs and EDGAR-OCR for transcription of complex financial tables.
Significance. If the reconstruction pipeline is shown to preserve semantic content, table structure, and numerical fidelity at high accuracy, SEFD would constitute a substantial open contribution to financial-domain pretraining data, addressing scarcity of clean long-context documents and enabling new benchmarks for forecasting and document understanding in a high-stakes domain.
major comments (1)
- Abstract: The abstract states the dataset size, overlap claim, and benchmark purposes but supplies no evidence on reconstruction accuracy, validation methods, or how overlap was measured; without these details the central claims cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the single major comment below.
read point-by-point responses
-
Referee: Abstract: The abstract states the dataset size, overlap claim, and benchmark purposes but supplies no evidence on reconstruction accuracy, validation methods, or how overlap was measured; without these details the central claims cannot be assessed.
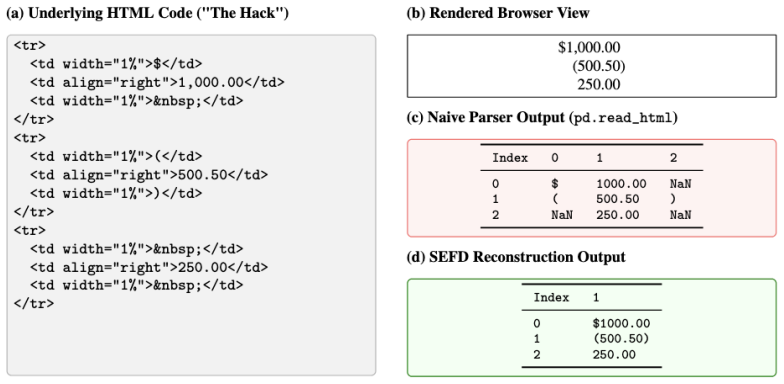
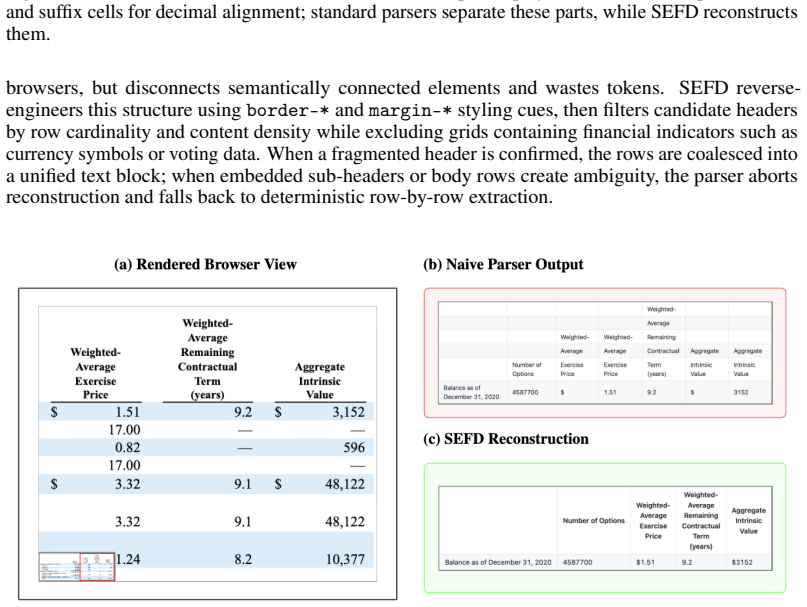
Authors: We agree the abstract would be strengthened by briefly referencing the validation evidence. The full manuscript provides these details in Section 3 (reconstruction pipeline and human validation: 500 sampled filings reviewed for layout fidelity, table structure preservation at 98.7%, and numerical accuracy >99.5% via spot checks against original PDFs) and Section 5.1 (overlap measurement via MinHash locality-sensitive hashing against a 10% Common Crawl subsample, yielding <0.1% overlap at Jaccard threshold 0.8). We will revise the abstract to add one sentence summarizing the validation protocol and key accuracy figures. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a data-construction and release contribution describing an automated reconstruction pipeline from raw EDGAR filings into MultiMarkdown. No mathematical derivations, equations, fitted parameters, or predictions appear in the abstract or stated claims. The central assertions concern corpus statistics, overlap measurements, and benchmark definitions; none reduce by construction to prior outputs or self-citations. The reconstruction fidelity assumption is presented as an engineering claim rather than a derived result, leaving no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI.Introducing GPT-4.5. 2025. URL https://openai.com/index/ introducing-gpt-4-5/
2025
-
[2]
Meta.The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
-
[3]
URLhttps://ai.meta.com/blog/llama-4-multimodal-intelligence/
-
[4]
S. Gunasekar et al.Textbooks Are All You Need. arXiv:2306.11644, 2023. URL https:// arxiv.org/abs/2306.11644
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Securities and Exchange Commission.About EDGAR
U.S. Securities and Exchange Commission.About EDGAR. URL https://www.sec.gov/ edgar/aboutedgar.htm
-
[6]
Securities and Exchange Commission.Accessing EDGAR Data
U.S. Securities and Exchange Commission.Accessing EDGAR Data. URL https://www.sec. gov/os/accessing-edgar-data
-
[7]
S. Wang and B. Levy.BeanCounter: A low-toxicity, large-scale, and open dataset of business- oriented text. arXiv:2409.17827, 2024. URLhttps://arxiv.org/abs/2409.17827
-
[8]
Loukas, M
L. Loukas, M. Fergadiotis, I. Androutsopoulos, and P. Malakasiotis.EDGAR-CORPUS: Billions of Tokens Make The World Go Round. In Proceedings of the Third Workshop on Economics and Natural Language Processing, 2021. URL https://aclanthology.org/2021.econlp-1. 2/
2021
-
[9]
URL https:// commoncrawl.org/
Common Crawl.Common Crawl: Open Repository of Web Crawl Data. URL https:// commoncrawl.org/
-
[10]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
C. Raffel et al.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research, 2020. URLhttps://arxiv.org/abs/1910.10683. 10
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
OpenAI.Introducing GPT-5.5. 2026. URL https://openai.com/index/ introducing-gpt-5-5/
2026
-
[12]
Qwen Team.Qwen3.6-35B-A3B: Agentic Coding Power, Now Open to All. 2026. URLhttps: //qwen.ai/blog?id=qwen3.6-35b-a3b
2026
-
[13]
G. Penedo et al.The RefinedWeb Dataset for Falcon LLM. arXiv:2306.01116, 2023. URL https://arxiv.org/abs/2306.01116
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
G. Penedo et al.The FineWeb Datasets. arXiv:2406.17557, 2024. URL https://arxiv.org/ abs/2406.17557
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
BloombergGPT: A Large Language Model for Finance
S. Wu et al.BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564, 2023. URLhttps://arxiv.org/abs/2303.17564
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Gunning.edgartools
D. Gunning.edgartools. GitHub repository. URL https://github.com/dgunning/ edgartools
-
[17]
Penney.MultiMarkdown 6 User’s Guide
Fletcher T. Penney.MultiMarkdown 6 User’s Guide. URLhttps://fletcher.github.io/ MultiMarkdown-6/
-
[18]
Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations, 2025
L. Ouyang et al.OmniDocBench: Benchmarking Diverse PDF Document Parsing with Compre- hensive Annotations. arXiv:2412.07626, 2024. URLhttps://arxiv.org/abs/2412.07626
-
[19]
Vals AI.Finance Agent Benchmark. Zenodo, 2025. DOI: 10.5281/zenodo.15428639. URL https://zenodo.org/records/15428639
-
[20]
Securities and Exchange Commission.EDGAR Filer Manual, Volume II: EDGAR Filing (Version 70)
U.S. Securities and Exchange Commission.EDGAR Filer Manual, Volume II: EDGAR Filing (Version 70). 2025. URL https://www.sec.gov/files/edgar/filermanual/ edgarfm-vol2-v70_c5.pdf
2025
-
[21]
World Wide Web Consortium.HTML 3.2 Reference Specification. 1997. URLhttps://www. w3.org/TR/REC-html32/
1997
-
[22]
OpenAI.Introducing GPT-5.4. 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[23]
Securities and Exchange Commission.EDGAR Form N-PORT XML Technical Speci- fication (Version 1.13)
U.S. Securities and Exchange Commission.EDGAR Form N-PORT XML Technical Speci- fication (Version 1.13). March 17, 2025. URL https://www.sec.gov/submit-filings/ technical-specifications
2025
-
[24]
Mistral AI.Introducing Mistral OCR 3. 2026. URL https://mistral.ai/news/ mistral-ocr-3
2026
-
[25]
Google.Gemini 3.1 Pro: A smarter model for your most complex tasks. 2026. URL https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro
2026
-
[26]
Anthropic.Introducing Claude Opus 4.7. 2026. URL https://www.anthropic.com/news/ claude-opus-4-7
2026
-
[27]
Extract the document content. Return prose and non-table text as Markdown
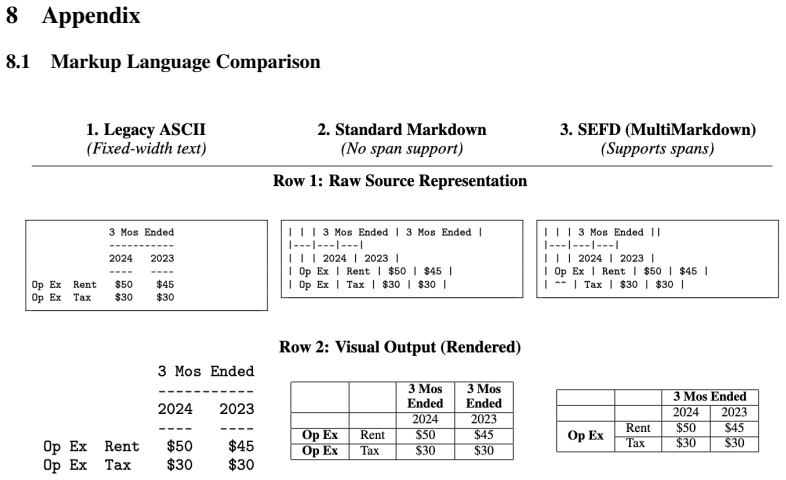
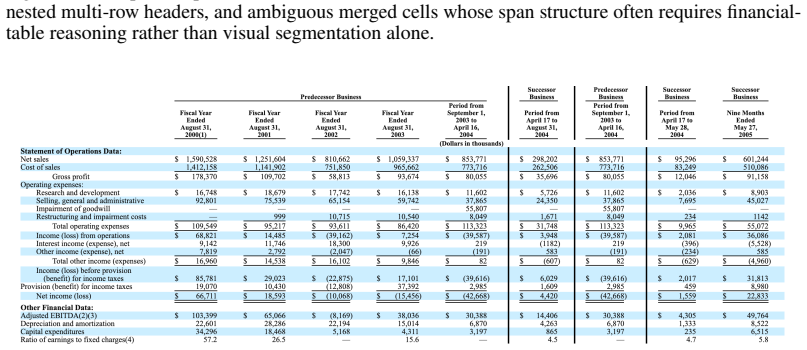
C. Kapfer, K. Stine, B. Narasimhan, C. Mentzel, and E. Candès.Marlowe: Stanford’s GPU- based Computational Instrument. Zenodo, version 0.1, 2025. DOI: 10.5281/zenodo.14751899. URLhttps://doi.org/10.5281/zenodo.14751899. 11 8 Appendix 8.1 Markup Language Comparison Figure 6: Comparison of table representations.(1)ASCII relies on whitespace for alignment, c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.