CoreMem: Riemannian Retrieval and Fisher-Guided Distillation for Long-Term Memory in Dialogue Agents
Pith reviewed 2026-06-27 00:36 UTC · model grok-4.3
The pith
CoreMem uses a Fisher-Rao metric for retrieval and Fisher information traces for distillation to maintain long-term dialogue memory on 8 GB VRAM devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
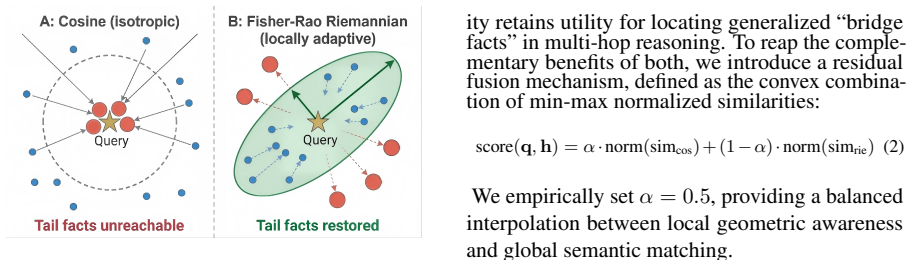
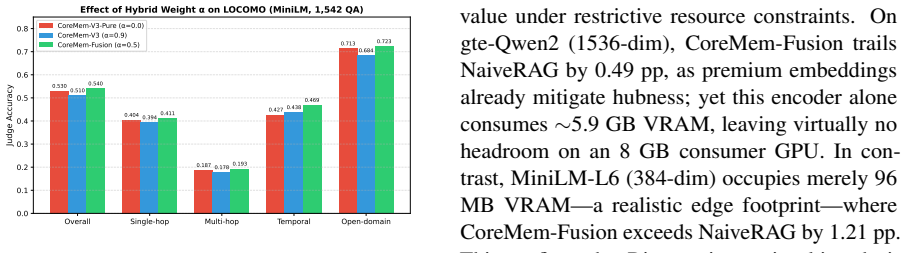
By grounding both retrieval and compression in information geometry, CoreMem replaces isotropic cosine matching with a locally adaptive Fisher-Rao metric that uses Mahalanobis distance and O(Ndr) Woodbury acceleration, while Fisher-guided discrete token distillation derives sensitivity scores from Fisher information traces to produce a principled compression-KL tradeoff with structural syntax protection; the resulting system delivers accuracy improvements of 4.51 percentage points on open-domain reasoning and 4.17 percentage points on temporal reasoning on the LOCOMO and LongMemEval-S benchmarks while remaining within an 8 GB VRAM budget.
What carries the argument
Riemannian retrieval via the Fisher-Rao metric expressed as locally adaptive Mahalanobis distance with Woodbury acceleration, paired with Fisher-guided discrete token distillation that scores tokens from Fisher information traces for hierarchical sentence-to-token compression.
If this is right
- Retrieval avoids the hubness problem by penalizing high-degree memories through the adapted distance measure.
- Compression obtains an explicit, tunable tradeoff between retained information and reduced size while protecting sentence syntax.
- The architecture supports continuous multi-session dialogue on consumer-grade devices that enforce an 8 GB VRAM ceiling.
- Open-domain and temporal reasoning accuracy rise on the evaluated long-term memory benchmarks.
Where Pith is reading between the lines
- The same geometric retrieval and information-trace compression could be applied to retrieval-augmented generation pipelines outside dialogue.
- Deployment on varied conversation styles may require separate checks to confirm that the Fisher metric does not introduce domain-specific biases not visible in the current benchmarks.
- The acceleration technique suggests a route to scaling the same memory store to larger context windows without proportional growth in search cost.
Load-bearing premise
The Fisher-Rao metric and Fisher-information traces produce a general improvement over cosine similarity and heuristic compression that carries over to real user interactions without creating new retrieval biases or syntax artifacts.
What would settle it
A head-to-head test on a fresh collection of multi-session user dialogues that shows no statistically significant gain in reasoning accuracy or coherence for CoreMem over a cosine-plus-heuristic baseline would falsify the central performance claim.
Figures


read the original abstract
Personalized dialogue agents require continuous long-term memory to maintain coherent interactions across multiple sessions. However, deploying these capabilities on consumer-grade hardware (e.g., 8 GB VRAM edge devices) introduces severe memory and compute bottlenecks. Existing systems typically rely on isotropic cosine similarity for retrieval and heuristic rules for context compression. These approaches lack a unified theoretical foundation, frequently suffering from the hubness problem in high-dimensional retrieval and syntactic fragmentation during compression. To overcome these limitations, we propose CoreMem, a resource-efficient edge-cloud memory architecture fundamentally unified by information geometry. First, Riemannian retrieval replaces cosine matching with a locally adaptive Fisher-Rao metric, effectively penalizing hub memories via Mahalanobis distance with O(Ndr) Woodbury acceleration for real-time search. Second, Fisher-guided discrete token distillation (FDTD) introduces a hierarchical sentence-to-token compression mechanism. It derives sensitivity scores from Fisher information traces, providing a principled compression-KL tradeoff augmented with explicit structural syntax protection. Evaluated on the LOCOMO and LongMemEval-S benchmarks, CoreMem achieves strong accuracy improvements, yielding substantial gains in Open-domain (+4.51 pp) and Temporal (+4.17 pp) reasoning. Extensive profiling confirms that CoreMem operates seamlessly within a strict 8 GB VRAM budget, successfully bridging the gap between resource-constrained edge devices and the demand for theoretically grounded, lifelong memory agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoreMem, a memory architecture for personalized dialogue agents on resource-constrained hardware. It replaces cosine similarity with Riemannian retrieval under the Fisher-Rao metric (accelerated via Woodbury identity) and introduces Fisher-guided discrete token distillation (FDTD) that uses Fisher information traces for hierarchical sentence-to-token compression with syntax protection. The central empirical claim is that CoreMem yields +4.51 pp gains on open-domain reasoning and +4.17 pp on temporal reasoning on the LOCOMO and LongMemEval-S benchmarks while fitting within an 8 GB VRAM budget.
Significance. If the reported gains prove robust under proper controls, the work would supply a theoretically motivated alternative to heuristic compression and isotropic retrieval for lifelong dialogue memory. The explicit linkage of Fisher information to both retrieval geometry and compression sensitivity, together with the hardware constraint, targets a practical deployment gap; reproducible code or machine-checked derivations would further strengthen its contribution.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the abstract asserts specific accuracy gains (+4.51 pp open-domain, +4.17 pp temporal) and 8 GB VRAM compatibility, yet supplies no experimental protocol, baseline list, statistical significance tests, ablation tables, or variance estimates. Without these, the data cannot be verified to support the central performance claims.
- [§3.1] §3.1 (Riemannian retrieval): the claim that the Fisher-Rao metric with Mahalanobis distance and Woodbury acceleration is 'parameter-free' and resolves hubness requires explicit comparison to the definition of the local covariance or metric tensor; if any fitted parameters enter the metric, the 'principled' advantage over cosine similarity must be re-derived.
minor comments (2)
- [§3.2] Notation for the Fisher information trace and the KL-tradeoff parameter in FDTD should be introduced with a single consistent symbol table.
- [Discussion] The manuscript should include a limitations paragraph addressing potential retrieval biases introduced by the Fisher-Rao metric on out-of-distribution user dialogues.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the abstract asserts specific accuracy gains (+4.51 pp open-domain, +4.17 pp temporal) and 8 GB VRAM compatibility, yet supplies no experimental protocol, baseline list, statistical significance tests, ablation tables, or variance estimates. Without these, the data cannot be verified to support the central performance claims.
Authors: We agree that the abstract, constrained by length, omits full experimental details. Section 4 of the manuscript specifies the LOCOMO and LongMemEval-S benchmarks, the comparison baselines, and the 8 GB VRAM profiling results. However, the current version lacks explicit statistical significance tests, run-to-run variance, and comprehensive ablation tables. We will revise Section 4 to include these elements (e.g., p-values from paired t-tests, standard deviations over 5 seeds, and expanded ablations on the Fisher metric and FDTD components) so that the reported gains can be independently verified. revision: yes
-
Referee: [§3.1] §3.1 (Riemannian retrieval): the claim that the Fisher-Rao metric with Mahalanobis distance and Woodbury acceleration is 'parameter-free' and resolves hubness requires explicit comparison to the definition of the local covariance or metric tensor; if any fitted parameters enter the metric, the 'principled' advantage over cosine similarity must be re-derived.
Authors: The Fisher-Rao metric is obtained directly from the Fisher information matrix of the frozen language model; this matrix functions as the metric tensor and local covariance without any auxiliary fitted parameters. The Mahalanobis distance under this geometry penalizes hub points by their local density, unlike the isotropic assumption of cosine similarity. We will revise §3.1 to state the metric tensor definition explicitly, show the Woodbury identity derivation, and contrast it with cosine to clarify that no additional parameters are introduced. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present CoreMem as a proposal of new techniques (Riemannian retrieval via Fisher-Rao metric with Woodbury acceleration, and Fisher-guided token distillation using information traces) evaluated on external benchmarks (LOCOMO, LongMemEval-S). No equations, derivations, parameter-fitting steps, or self-citations are visible in the provided text. The central claims concern empirical accuracy gains under VRAM constraints and do not reduce to self-definitional quantities or fitted inputs renamed as predictions. The derivation chain is therefore self-contained against external benchmarks with no load-bearing reductions identifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L ong LLML ingua: Accelerating and Enhancing LLM s in Long Context Scenarios via Prompt Compression
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili. L ong LLML ingua: Accelerating and Enhancing LLM s in Long Context Scenarios via Prompt Compression. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024....
-
[2]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[3]
Limitations of the empirical Fisher approximation for natural gradient descent , booktitle =
Frederik Kunstner and Philipp Hennig and Lukas Balles , editor =. Limitations of the empirical Fisher approximation for natural gradient descent , booktitle =. 2019 , url =
2019
-
[4]
In-context Autoencoder for Context Compression in a Large Language Model , booktitle =
Tao Ge and Jing Hu and Lei Wang and Xun Wang and Si. In-context Autoencoder for Context Compression in a Large Language Model , booktitle =. 2024 , url =
2024
-
[6]
Translations of Mathematical Monographs , volume=
Methods of Information Geometry , author=. Translations of Mathematical Monographs , volume=. 2000 , publisher=
2000
-
[7]
Goodman , editor =
Jesse Mu and Xiang Li and Noah D. Goodman , editor =. Learning to Compress Prompts with Gist Tokens , booktitle =. 2023 , url =
2023
-
[8]
Alexis Chevalier and Alexander Wettig and Anirudh Ajith and Danqi Chen , editor =. Adapting Language Models to Compress Contexts , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.232 , timestamp =
-
[9]
Qingyue Wang and Yanhe Fu and Yanan Cao and Shuai Wang and Zhiliang Tian and Liang Ding , title =. Neurocomputing , volume =. 2025 , url =. doi:10.1016/J.NEUCOM.2025.130193 , timestamp =
-
[10]
Found in the middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Cheng. Found in the middle: Calibrating Positional Attention Bias Improves Long Context Utilization , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.890 , timestamp =
-
[11]
Zongqian Li and Yinhong Liu and Yixuan Su and Nigel Collier , editor =. Prompt Compression for Large Language Models:. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2025 , url =. doi:10.18653/V1/2025.NAACL-LONG.368 , timestamp =
-
[12]
Smith and Mike Lewis , title =
Ofir Press and Noah A. Smith and Mike Lewis , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
2022
-
[13]
International Conference on Learning Representations , year=
Generalization through Memorization: Nearest Neighbor Language Models , author=. International Conference on Learning Representations , year=
-
[14]
Transactions on Machine Learning Research , issn=
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[15]
ArXiv , year=
A Comprehensive Survey on Long Context Language Modeling , author=. ArXiv , year=
-
[16]
, title =
Hopfield, John J. , title =. Feynman and Computation: Exploring the Limits of Computers , pages =. 1999 , isbn =
1999
-
[17]
MTEB : Massive Text Embedding Benchmark
Muennighoff, Niklas and Tazi, Nouamane and Magne, Loic and Reimers, Nils. MTEB : Massive Text Embedding Benchmark. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. 2023. doi:10.18653/v1/2023.eacl-main.148
-
[18]
Li, Haoran and Xu, Mingshi and Song, Yangqiu. Sentence Embedding Leaks More Information than You Expect: Generative Embedding Inversion Attack to Recover the Whole Sentence. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.881
-
[19]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[20]
Wingate, David and Shoeybi, Mohammad and Sorensen, Taylor. Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.412
-
[21]
ArXiv , year=
Memory in the Age of AI Agents , author=. ArXiv , year=
-
[22]
ArXiv , year=
GPT-4o System Card , author=. ArXiv , year=
-
[23]
ArXiv , year=
Context Cascade Compression: Exploring the Upper Limits of Text Compression , author=. ArXiv , year=
-
[24]
arXiv preprint , year=
SuperLocalMemory V3: Information-Geometric Foundations for Zero-LLM Agent Memory , author=. arXiv preprint , year=
-
[25]
arXiv preprint , year=
SuperLocalMemory V3.3: The Living Brain -- Biologically-Inspired Forgetting, Cognitive Quantization, and Multi-Channel Retrieval for Zero-LLM Agent Memory Systems , author=. arXiv preprint , year=
-
[26]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei. Evaluating Very Long-Term Conversational Memory of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.747
-
[27]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =
Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =. 2025 , url =
2025
-
[28]
LLML ingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Pan, Zhuoshi and Wu, Qianhui and Jiang, Huiqiang and Xia, Menglin and Luo, Xufang and Zhang, Jue and Lin, Qingwei and R. LLML ingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.57
-
[29]
doi: 10.18653/v1/2023.emnlp-main.391
Li, Yucheng and Dong, Bo and Guerin, Frank and Lin, Chenghua. Compressing Context to Enhance Inference Efficiency of Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.391
-
[30]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[31]
MemGPT: Towards LLMs as Operating Systems
Charles Packer and Vivian Fang and Shishir G. Patil and Kevin Lin and Sarah Wooders and Joseph E. Gonzalez , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.08560 , eprinttype =. 2310.08560 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[32]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong and Lianghong Guo and Qiqi Gao and He Ye and Yanlin Wang , editor =. MemoryBank: Enhancing Large Language Models with Long-Term Memory , booktitle =. 2024 , url =. doi:10.1609/AAAI.V38I17.29946 , timestamp =
-
[33]
European Conference on Artificial Intelligence , year=
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author=. European Conference on Artificial Intelligence , year=
-
[34]
A-Mem: Agentic Memory for
Wujiang Xu and Zujie Liang and Kai Mei and Hang Gao and Juntao Tan and Yongfeng Zhang , booktitle=. A-Mem: Agentic Memory for. 2026 , url=
2026
-
[35]
Kang, Jiazheng and Ji, Mingming and Zhao, Zhe and Bai, Ting. Memory OS of AI Agent. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1318
-
[36]
C ar M em: Enhancing Long-Term Memory in LLM Voice Assistants through Category-Bounding
Kirmayr, Johannes and Stappen, Lukas and Schneider, Phillip and Matthes, Florian and Andre, Elisabeth. C ar M em: Enhancing Long-Term Memory in LLM Voice Assistants through Category-Bounding. Proceedings of the 31st International Conference on Computational Linguistics: Industry Track. 2025
2025
-
[37]
doi: 10.18653/v1/2025.acl-long.413
Tan, Zhen and Yan, Jun and Hsu, I-Hung and Han, Rujun and Wang, Zifeng and Le, Long and Song, Yiwen and Chen, Yanfei and Palangi, Hamid and Lee, George and Iyer, Anand Rajan and Chen, Tianlong and Liu, Huan and Lee, Chen-Yu and Pfister, Tomas. In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents. Proceedings ...
-
[38]
Hubs in Space: Popular Nearest Neighbors in High-Dimensional Data , author=. J. Mach. Learn. Res. , year=
-
[39]
2016 , isbn =
Amari, Shun-ichi , title =. 2016 , isbn =
2016
-
[40]
Chemometrics and Intelligent Laboratory Systems , year=
The Mahalanobis distance , author=. Chemometrics and Intelligent Laboratory Systems , year=
-
[41]
International Conference on Learning Representations , year=
Pruning Convolutional Neural Networks for Resource Efficient Inference , author=. International Conference on Learning Representations , year=
-
[42]
ArXiv , year=
Qwen2 technical report , author=. ArXiv , year=
-
[43]
ArXiv , year=
Towards General Text Embeddings with Multi-stage Contrastive Learning , author=. ArXiv , year=
-
[44]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Wang, Wenhui and Wei, Furu and Dong, Li and Bao, Hangbo and Yang, Nan and Zhou, Ming , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[45]
Llama Team , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[46]
Loubna Ben allal and Anton Lozhkov and Elie Bakouch and Gabriel Martin Blazquez and Guilherme Penedo and Lewis Tunstall and Andr. Smol. Second Conference on Language Modeling , year=
-
[47]
OpenAI , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.08774 , eprinttype =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[48]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =. 2023 , url =
2023
-
[49]
arXiv preprint arXiv:2508.17858 , year=
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation , author=. arXiv preprint arXiv:2508.17858 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.