RegimeVGGT: Layer-Wise Spatially Preserving Redundancy Removal for Visual Geometry Grounded Transformer
Pith reviewed 2026-06-27 01:03 UTC · model grok-4.3
The pith
RegimeVGGT compresses VGGT layer by layer to achieve 6.7 times faster 3D scene reconstruction at the same quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
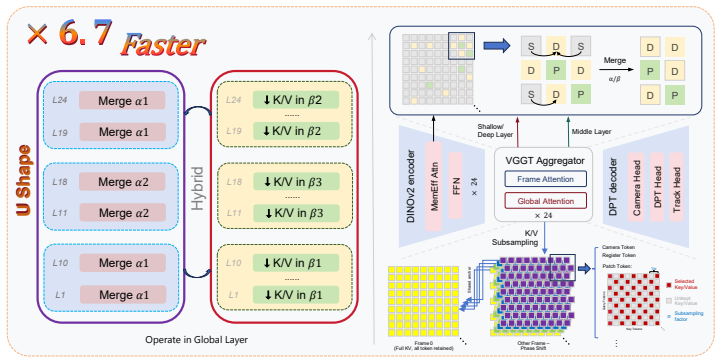
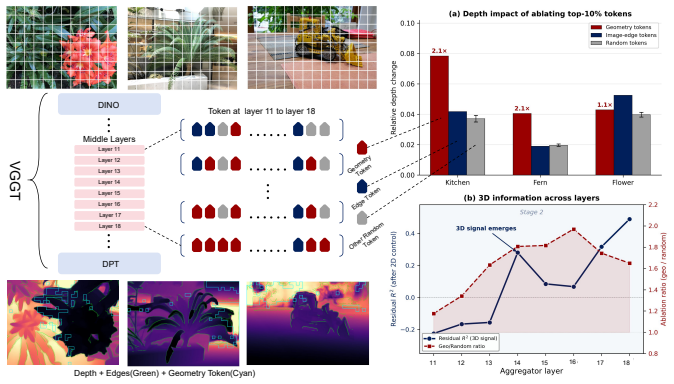
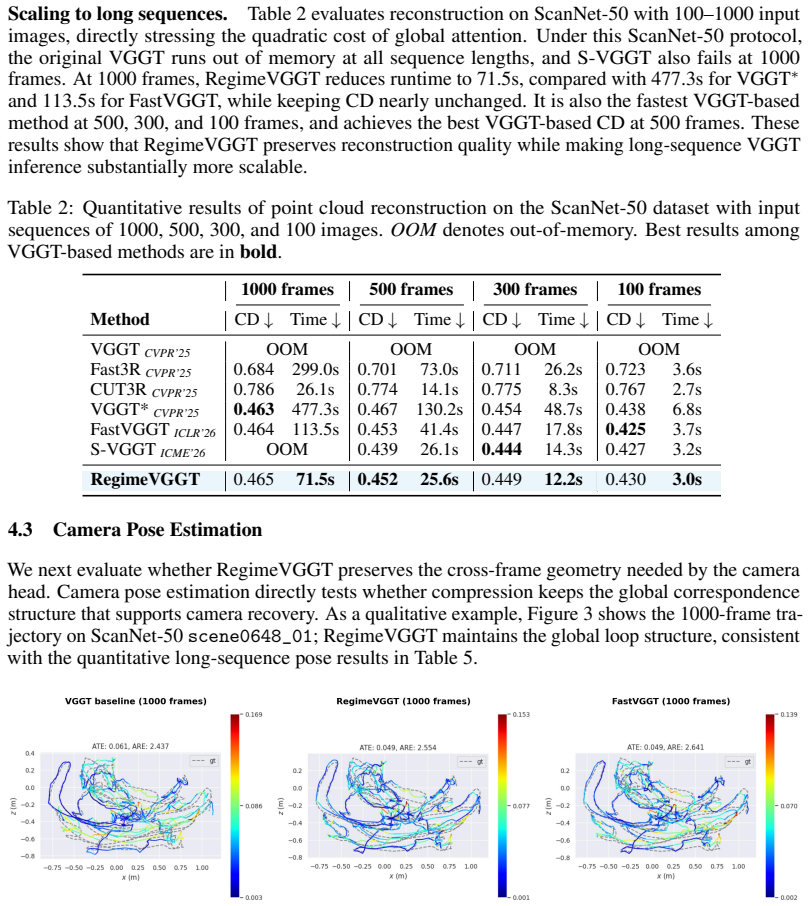
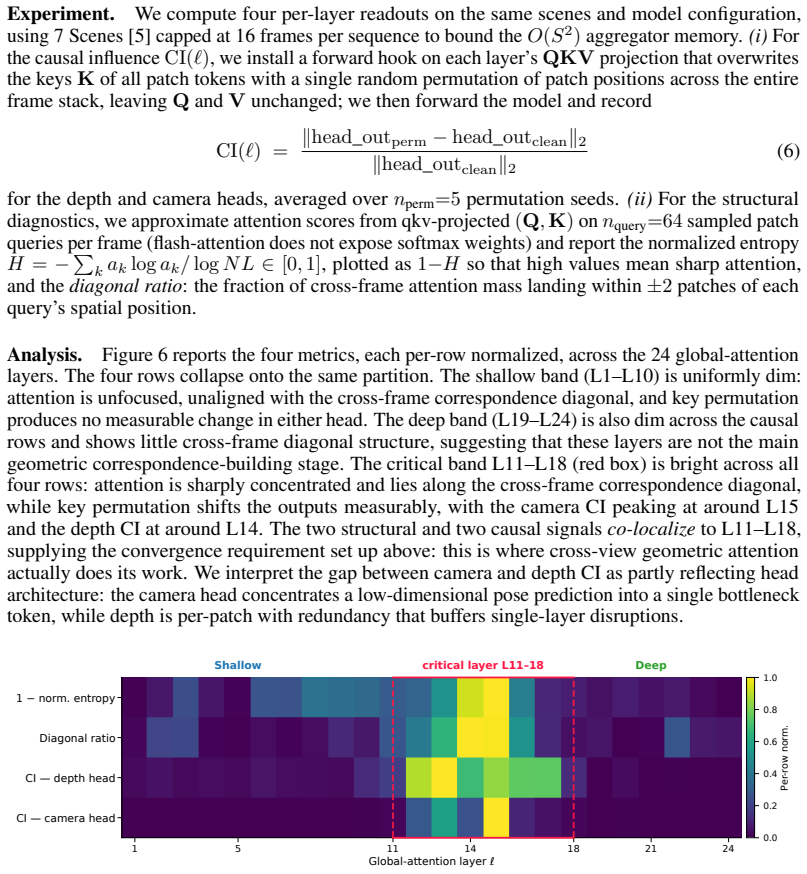
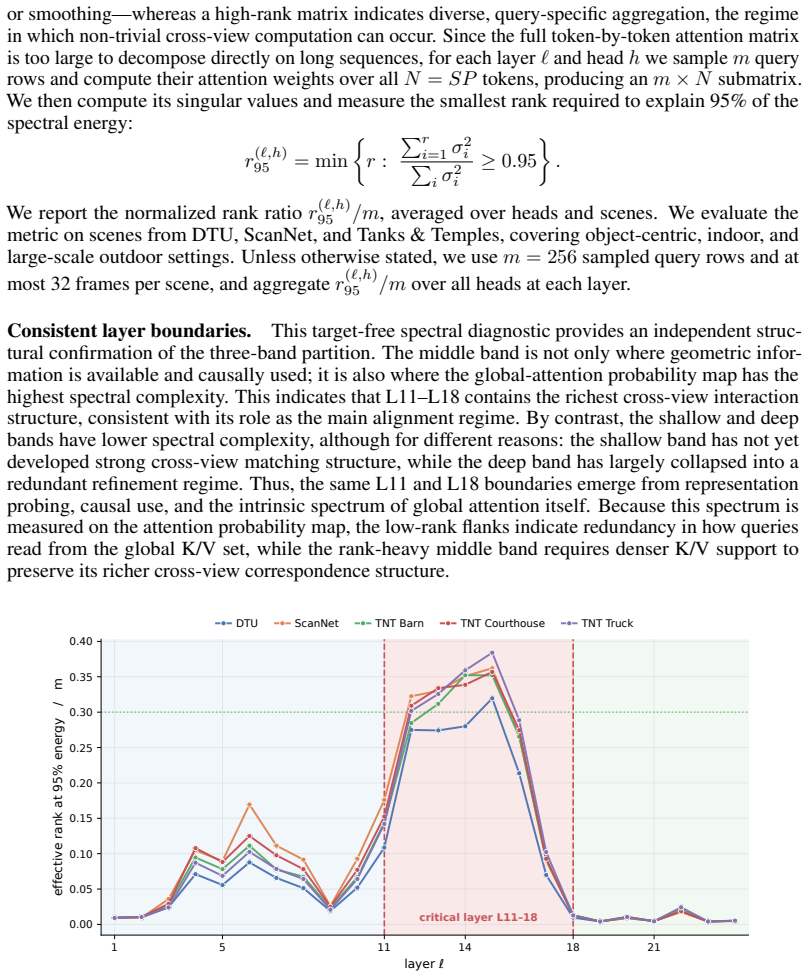
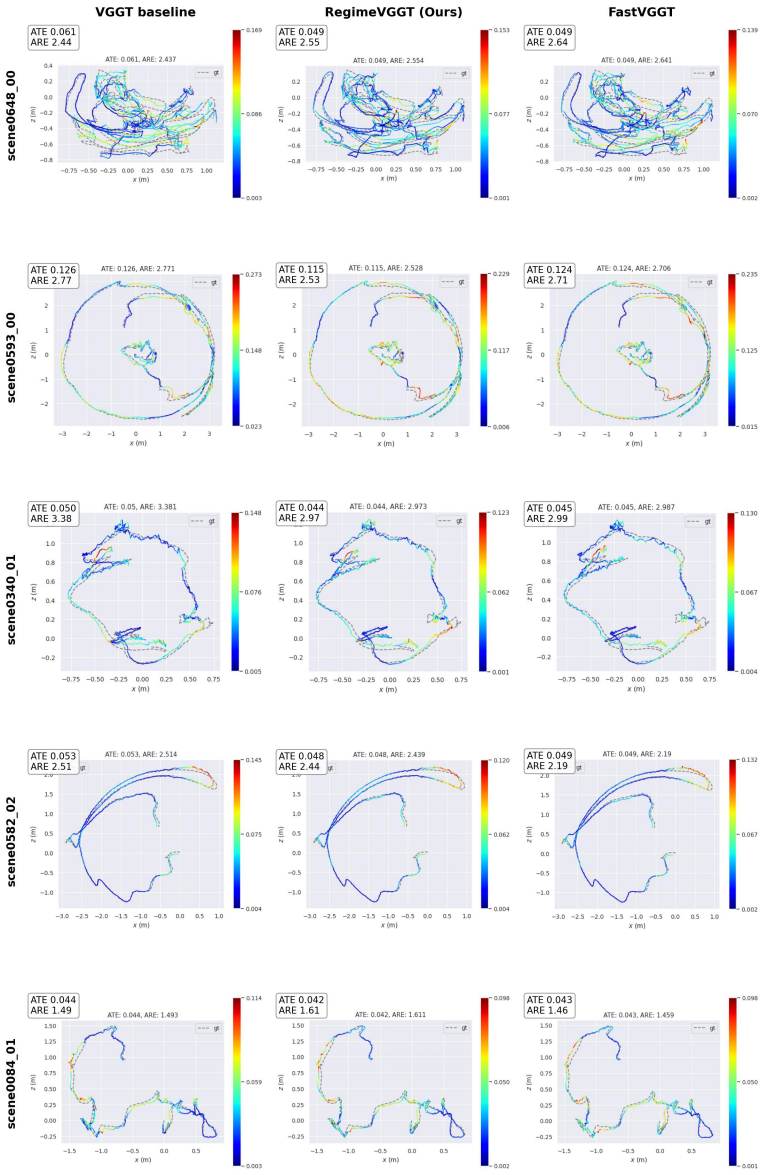
RegimeVGGT identifies three regimes in VGGT via spectral, probing, and causal analyses: shallow layers lack cross-view structure, middle layers drive cross-view alignment, and deep layers are redundant for dense geometry yet their cross-frame attention is essential for pose. It then applies layer-wise U-shaped compression with Saliency-Guided Banded Merging to protect salient tokens and Selectively Protected K/V Downsampling to preserve spatial coverage and pose-critical paths, resulting in 6.7x speedup over VGGT* at matched reconstruction quality.
What carries the argument
Layer-wise U-shaped compression using Saliency-Guided Banded Merging and Selectively Protected K/V Downsampling, guided by the three identified regimes in attention layers.
If this is right
- Training-free acceleration allows deployment on resource-limited devices for multi-view 3D tasks.
- Preservation of pose estimation alongside geometry enables accurate camera registration in compressed models.
- Uniform compression is avoided by tailoring to layer heterogeneity, improving efficiency over prior accelerators.
Where Pith is reading between the lines
- Similar regime analysis could apply to other multi-view or video transformers to find compressible layers.
- The method might extend to other dense prediction tasks like optical flow if regimes are analogous.
Load-bearing premise
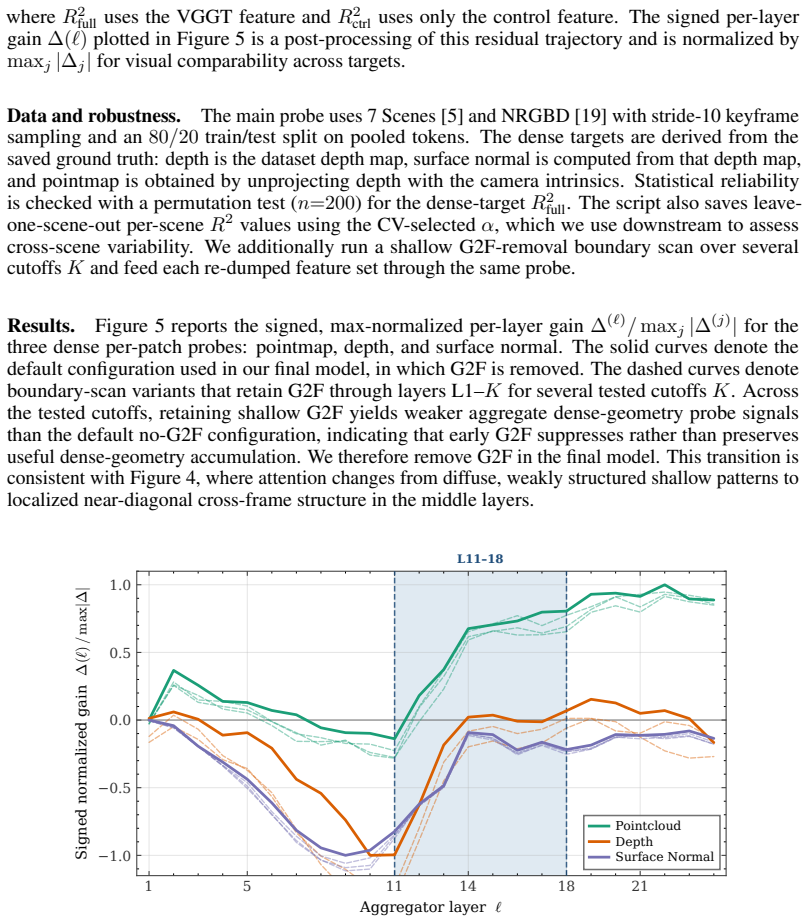
The three regimes in VGGT layers remain consistent across different scenes and datasets, and the saliency and phase-shifted protection methods retain all necessary information for geometry and pose without new errors.
What would settle it
Running RegimeVGGT on a held-out dataset and observing a significant drop in reconstruction metrics like accuracy or pose error compared to the original VGGT would falsify the claim of matched quality at speedup.
Figures


read the original abstract
Visual Geometry Grounded Transformer (VGGT) recovers dense 3D scene structure from multi-view images in one forward pass, but quadratic cross-frame attention limits its scalability. Existing training-free accelerators reduce computation uniformly along one axis, missing layer heterogeneity. Our spectral, probing, and causal analyses reveal three regimes: shallow layers lack cross-view structure, middle layers drive cross-view alignment, and deep layers are redundant for dense geometry yet their cross-frame attention remains essential for pose. RegimeVGGT applies layer-wise U-shaped compression along two axes: Saliency-Guided Banded Merging protects geometry- and edge-salient tokens, while Selectively Protected K/V Downsampling preserves cross-frame spatial coverage and the pose-critical path through a phase-shifted spatial grid, a reference-frame anchor, and uncompressed camera/register tokens. Training-free, RegimeVGGT achieves a 6.7x speedup over VGGT* at matched reconstruction quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RegimeVGGT, a training-free acceleration for the Visual Geometry Grounded Transformer (VGGT) used in one-pass dense 3D scene reconstruction from multi-view images. Spectral, probing, and causal analyses identify three layer regimes (shallow: no cross-view structure; middle: cross-view alignment; deep: redundant for geometry but pose-critical). Layer-wise U-shaped compression is applied along two axes—Saliency-Guided Banded Merging (protecting geometry/edge-salient tokens) and Selectively Protected K/V Downsampling (phase-shifted grid, reference-frame anchor, uncompressed camera/register tokens)—yielding a claimed 6.7x speedup over VGGT* at matched reconstruction quality.
Significance. If the regime boundaries prove stable and the protection rules preserve all tokens required for both dense geometry and pose, the work would offer a practical, training-free route to scaling quadratic-attention geometry transformers by exploiting layer heterogeneity rather than uniform pruning. The dual-axis, spatially preserving design and explicit reference-frame anchoring are concrete strengths that could be adopted in related efficient-ViT efforts for 3D vision.
major comments (2)
- [Abstract] Abstract: the central 6.7x speedup at matched reconstruction quality is asserted without any supporting quantitative numbers, error bars, dataset statistics, ablation tables, or controls, which is load-bearing for the empirical claim.
- [Abstract] Abstract (regime analyses): the three regimes are presented as stable enough for fixed layer-wise rules to never drop essential tokens, yet no cross-dataset regime-consistency metrics or ablation removing the reference-frame anchor are supplied; if regime transitions shift with scene scale or lighting, the matched-quality guarantee is at risk.
minor comments (2)
- [Abstract] The baseline VGGT* is referenced without an explicit definition or citation; clarify whether it denotes the original model, a re-implementation, or a modified variant.
- [Abstract] The abstract would benefit from naming the concrete metrics (e.g., accuracy, completeness, pose error) used to declare 'matched reconstruction quality'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for noting the potential practical value of exploiting layer heterogeneity in geometry transformers. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central 6.7x speedup at matched reconstruction quality is asserted without any supporting quantitative numbers, error bars, dataset statistics, ablation tables, or controls, which is load-bearing for the empirical claim.
Authors: We agree that the abstract would benefit from concrete quantitative anchors for the primary claim. In the revised manuscript we will insert a concise statement of the 6.7x speedup together with the corresponding reconstruction-quality metric (mean error) and the number of scenes/views used for the main result. The full supporting evidence—error bars, per-dataset statistics, ablation tables, and controls—already appears in Sections 4 and 5; the abstract change simply makes this evidence visible at the summary level. revision: yes
-
Referee: [Abstract] Abstract (regime analyses): the three regimes are presented as stable enough for fixed layer-wise rules to never drop essential tokens, yet no cross-dataset regime-consistency metrics or ablation removing the reference-frame anchor are supplied; if regime transitions shift with scene scale or lighting, the matched-quality guarantee is at risk.
Authors: The regime boundaries were derived from spectral, probing, and causal analyses performed on the primary multi-view evaluation sets; the protection mechanisms (saliency-guided banded merging, phase-shifted grid downsampling, reference-frame anchoring, and uncompressed camera/register tokens) were explicitly introduced to keep geometry- and pose-critical tokens intact even if boundaries shift modestly. We nevertheless recognize that explicit cross-dataset regime-consistency statistics and a dedicated ablation that removes the reference-frame anchor would strengthen the stability argument. Both will be added in the revision. revision: yes
Circularity Check
No significant circularity; empirical outcome of compression rules
full rationale
The paper presents the 6.7x speedup as the measured result of applying fixed layer-wise rules (Saliency-Guided Banded Merging and phase-shifted K/V downsampling) after identifying regimes via spectral/probing/causal analyses. No equations, fitted parameters, or self-citations are shown that would make the speedup equivalent to its inputs by construction. The central claim remains an independent empirical outcome rather than a renaming or self-referential definition.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard multi-head attention and positional encoding mechanics in vision transformers
- domain assumption Multi-view geometry provides consistent cross-frame correspondences that can be protected by saliency and spatial-grid rules
Reference graph
Works this paper leans on
-
[1]
Building rome in a day.Communications of the ACM, 54(10):105–112, 2011
Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day.Communications of the ACM, 54(10):105–112, 2011
2011
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6290–6301, 2022
2022
-
[3]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4599–4603, 2023
2023
-
[4]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[6]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[7]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Vision Transformers Need Registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Vision meets robotics: The kitti dataset.The international journal of robotics research, 32(11):1231–1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The international journal of robotics research, 32(11):1231–1237, 2013
2013
-
[10]
Which tokens to use? investigating token reduction in vision transformers
Joakim Bruslund Haurum, Sergio Escalera, Graham W Taylor, and Thomas B Moeslund. Which tokens to use? investigating token reduction in vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 773–783, 2023
2023
-
[11]
Kinectfusion: real-time 3d reconstruction and interaction using a moving depth camera
Shahram Izadi, David Kim, Otmar Hilliges, David Molyneaux, Richard Newcombe, Pushmeet Kohli, Jamie Shotton, Steve Hodges, Dustin Freeman, Andrew Davison, et al. Kinectfusion: real-time 3d reconstruction and interaction using a moving depth camera. InProceedings of the 24th annual ACM symposium on User interface software and technology, pages 559–568, 2011
2011
-
[12]
Large scale multi-view stereopsis evaluation
Rasmus Jensen, Anders Dahl, George V ogiatzis, Engin Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 406–413, 2014
2014
-
[13]
Token fusion: Bridging the gap between token pruning and token merging
Minchul Kim, Shangqian Gao, Yen-Chang Hsu, Yilin Shen, and Hongxia Jin. Token fusion: Bridging the gap between token pruning and token merging. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1383–1392, 2024
2024
-
[14]
Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Bench- marking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36(4):1–13, 2017
2017
-
[15]
Video token merging for long-form video understanding.arXiv preprint arXiv:2410.23782, 2024
Seon-Ho Lee, Jue Wang, Zhikang Zhang, David Fan, and Xinyu Li. Video token merging for long-form video understanding.arXiv preprint arXiv:2410.23782, 2024
-
[16]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[17]
Xinze Li, Pengxu Chen, Yiyuan Wang, Weifeng Su, and Wentao Cheng. S-vggt: Structure-aware subscene decomposition for scalable 3d foundation models.arXiv preprint arXiv:2603.17625, 2026. 10
-
[18]
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations.arXiv preprint arXiv:2202.07800, 2022
-
[19]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras.IEEE transactions on robotics, 33(5):1255–1262, 2017
Raul Mur-Artal and Juan D Tardós. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras.IEEE transactions on robotics, 33(5):1255–1262, 2017
2017
-
[20]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12179–12188, October 2021
2021
-
[22]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
2021
-
[23]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[24]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean conference on computer vision, pages 501–518. Springer, 2016
2016
-
[25]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Jiayi Ji, Shengchuan Zhang, and Liujuan Cao. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013
2013
-
[27]
Litevggt: Boosting vanilla vggt via geometry-aware cached token merging
Zhijian Shu, Cheng Lin, Tao Xie, Wei Yin, Ben Li, Zhiyuan Pu, Weize Li, Yao Yao, Xun Cao, Xiaoyang Guo, et al. Litevggt: Boosting vanilla vggt via geometry-aware cached token merging. arXiv preprint arXiv:2512.04939, 2025
-
[28]
Avggt: Rethinking global attention for accelerating vggt.arXiv preprint arXiv:2512.02541, 2025
Xianbing Sun, Zhikai Zhu, Zhengyu Lou, Bo Yang, Jinyang Tang, Liqing Zhang, He Wang, and Jianfu Zhang. Avggt: Rethinking global attention for accelerating vggt.arXiv preprint arXiv:2512.02541, 2025
-
[29]
Probabilistic robotics.Communications of the ACM, 45(3):52–57, 2002
Sebastian Thrun. Probabilistic robotics.Communications of the ACM, 45(3):52–57, 2002
2002
-
[30]
Bold features to detect texture- less objects
Federico Tombari, Alessandro Franchi, and Luigi Di Stefano. Bold features to detect texture- less objects. InProceedings of the IEEE international conference on computer vision, pages 1265–1272, 2013
2013
-
[31]
Block-Sparse Global Attention for Efficient Multi-View Geometry Transformers
Chung-Shien Brian Wang, Christian Schmidt, Jens Piekenbrinck, and Bastian Leibe. Faster vggt with block-sparse global attention.arXiv preprint arXiv:2509.07120, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[33]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[34]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024. 11
2024
-
[35]
Httm: Head-wise temporal token merging for faster vggt.arXiv preprint arXiv:2511.21317, 2025
Weitian Wang, Lukas Meiner, Rai Shubham, Cecilia De La Parra, and Akash Kumar. Httm: Head-wise temporal token merging for faster vggt.arXiv preprint arXiv:2511.21317, 2025
-
[36]
π3: Scalable permutation-equivariant visual geometry learning.arXiv e-prints, pages arXiv–2507, 2025
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Scalable permutation-equivariant visual geometry learning.arXiv e-prints, pages arXiv–2507, 2025
2025
-
[37]
Multi- modal token fusion for vision transformers
Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, and Yunhe Wang. Multi- modal token fusion for vision transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12186–12195, 2022
2022
-
[38]
Dymu: Dynamic merging and virtual unmerging for efficient vlms.arXiv preprint arXiv:2504.17040, 2025
Zhenhailong Wang, Senthil Purushwalkam, Caiming Xiong, Silvio Savarese, Heng Ji, and Ran Xu. Dymu: Dynamic merging and virtual unmerging for efficient vlms.arXiv preprint arXiv:2504.17040, 2025
-
[39]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[40]
MVSNet: Depth inference for unstructured multi-view stereo
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. MVSNet: Depth inference for unstructured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), pages 767–783, 2018
2018
-
[41]
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattention: Accurate and training-free sparse attention accelerating any model inference.arXiv preprint arXiv:2502.18137, 2025
-
[42]
Streaming 4D Visual Geometry Transformer
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Streaming 4d visual geometry transformer.arXiv preprint arXiv:2507.11539, 2025. 12 A Extended Analysis Evidence This appendix collects the empirical evidence underlying RegimeVGGT’s two design axes—token merging and K/V downsampling—together with the experiments that motivated each desi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.