SFT Overtraining Predicts Rank Inversion via Entropy Collapse Under RLVR
Pith reviewed 2026-06-27 01:12 UTC · model grok-4.3
The pith
Overtrained SFT checkpoints can invert GRPO performance rankings via entropy collapse
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
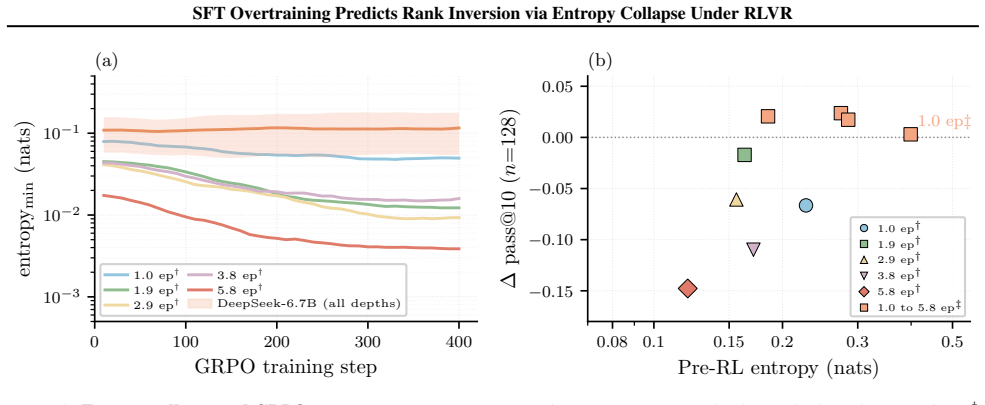
When SFT depth increases, pre-RL pass@1 rises but the rollout entropy falls, driving p below p*(g) and collapsing the within-group advantage variance p(1-p)(g-1)/g; this removes the relative reward signal needed for effective GRPO updates, so that the checkpoint with the highest SFT pass@1 produces the lowest post-GRPO performance on Qwen2.5-Coder-3B while the effect is milder on DeepSeek-Coder-6.7B where p remains above the threshold.
What carries the argument
The formula for expected within-group advantage variance under binary rewards, p(1-p)(g-1)/g, which drops sharply once the success probability p falls below the critical value p*(g) and thereby removes distinguishable advantage signals inside groups.
If this is right
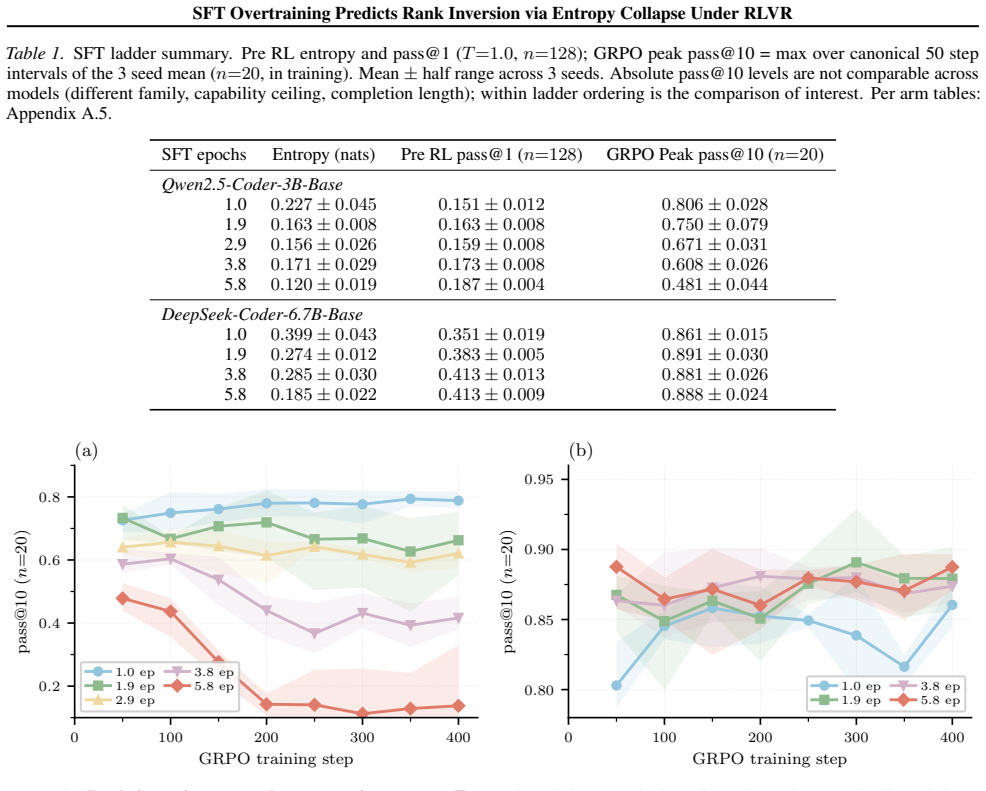
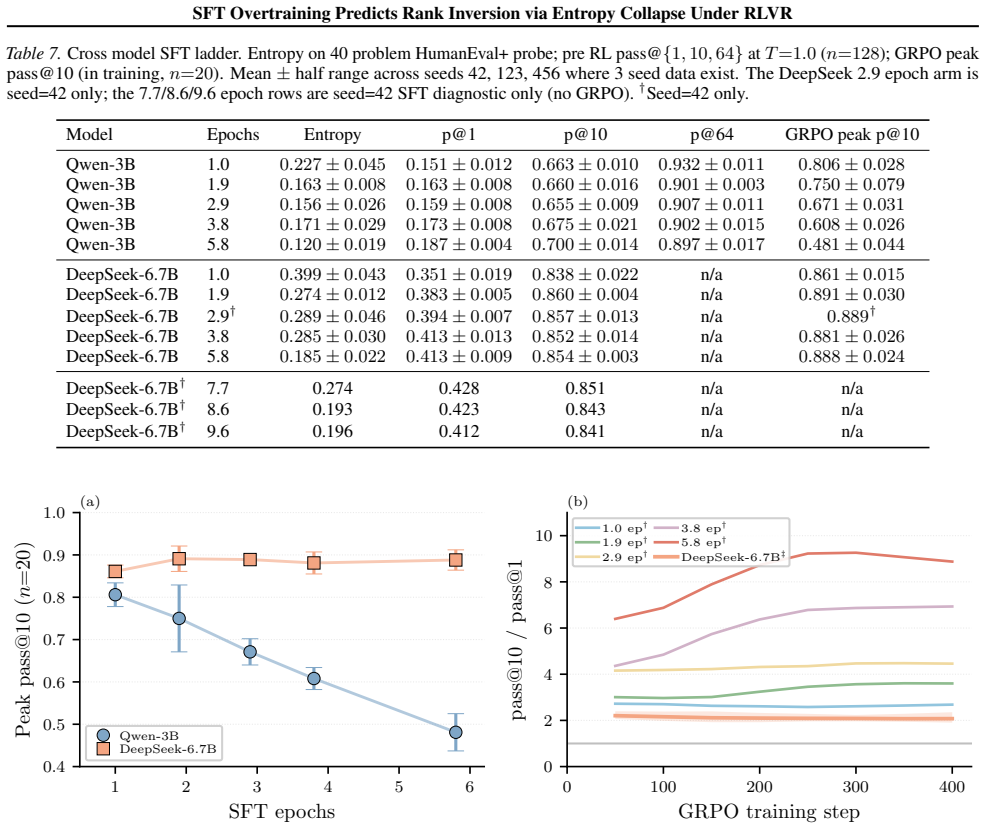
- On Qwen2.5-Coder-3B, deeper SFT raises pass@1 yet lowers peak GRPO pass@10 from 0.806 to 0.481 across three seeds.
- Pre-RL entropy correlates positively (rho = +0.69) with final GRPO outcome on the Qwen model.
- A two-stage diagnostic that combines pre-RL entropy triage with an early GRPO entropy monitor can flag and stop failing runs.
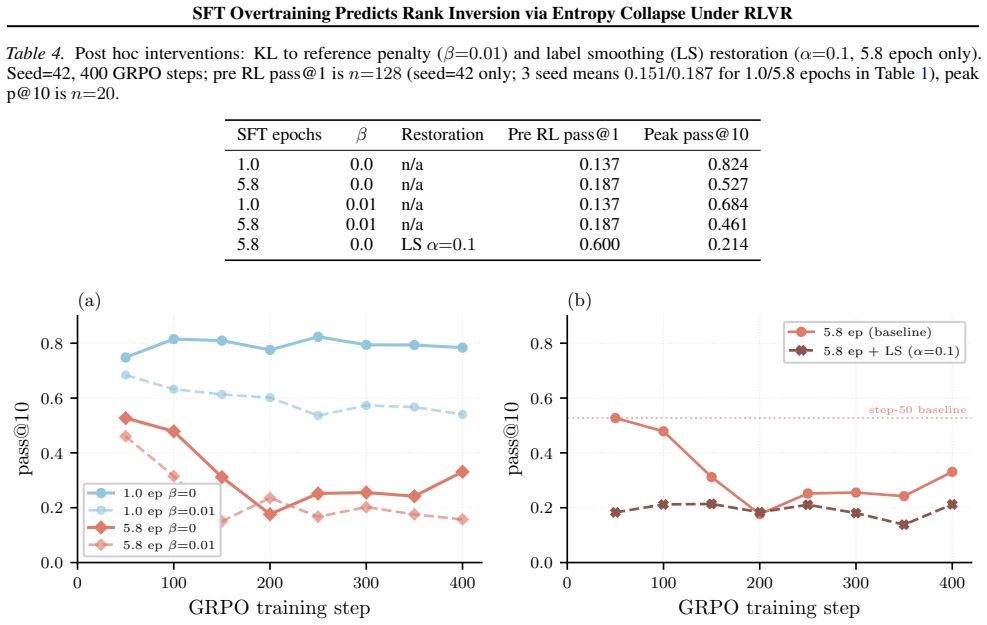
- KL-to-reference regularisation and label-smoothing variants do not rescue the collapsed Qwen checkpoint.
- On DeepSeek-Coder-6.7B, where pass@1 remains above p*(8) = 0.083, GRPO outcomes compress rather than fully invert.
Where Pith is reading between the lines
- Entropy measured on the rollout distribution before RL could replace pass@1 as the primary criterion for selecting an SFT starting checkpoint.
- The inversion effect appears model-dependent, as the two architectures tested exhibit different thresholds and severity.
- Similar variance-collapse conditions may exist for non-binary rewards or other group-relative RL methods beyond GRPO.
Load-bearing premise
The observed drop in GRPO performance with greater SFT depth is produced by entropy collapse lowering group advantage variance rather than by other unmeasured differences between checkpoints or model families.
What would settle it
A controlled experiment in which an SFT checkpoint with low pre-RL entropy and p below p*(g) still reaches high GRPO pass@10, or in which measured within-group advantage variance stays high despite low p, would falsify the claimed causal link.
Figures

read the original abstract
The standard heuristic of selecting the SFT checkpoint with the highest pass@1 for GRPO can fail when SFT compresses the rollout distribution. For binary rewards, the expected within group advantage variance is $p(1{-}p)(g{-}1)/g$; when early GRPO drives $p$ below $p^*(g)$, most groups have identical rewards and provide no group relative signal. We study SFT depth ladders for Qwen2.5-Coder-3B and DeepSeek-Coder-6.7B. We test Qwen2.5-Coder-3B across five depths and three seeds, and DeepSeek-Coder-6.7B across four matched depths and three seeds. On Qwen, pre RL pass@1 rises with SFT depth, but peak GRPO pass@10 falls from $0.806$ to $0.481$ (3 seed mean, $n{=}20$); pre RL entropy is positively associated with the GRPO outcome ($\rho{=}{+}0.69$). On DeepSeek, pass@1 remains far above $p^*(8){=}0.083$, and GRPO outcomes compress rather than invert. A two stage diagnostic, combining pre RL entropy triage with an early GRPO entropy monitor, flags high risk checkpoints and can stop failing runs early. Simple KL to reference regularisation and label smoothing variants do not rescue the collapsed Qwen checkpoint in our setting, suggesting the failure is not a trivial GRPO hyperparameter artefact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the common heuristic of selecting the SFT checkpoint with highest pass@1 for subsequent GRPO can fail due to SFT-induced entropy collapse in the rollout distribution. For binary rewards this reduces expected within-group advantage variance below the independent Bernoulli baseline p(1-p)(g-1)/g once p falls below p*(g), causing most groups to yield identical rewards and no relative signal. Experiments on Qwen2.5-Coder-3B (five SFT depths, three seeds) show pre-RL pass@1 rising while peak GRPO pass@10 falls from 0.806 to 0.481 (3-seed mean); pre-RL entropy correlates with GRPO outcome at ρ=+0.69. DeepSeek-Coder-6.7B avoids inversion because its pass@1 remains above p*(8)=0.083. A two-stage entropy-based diagnostic is proposed, and KL regularization plus label-smoothing variants fail to rescue the collapsed Qwen checkpoint.
Significance. If the proposed mechanism is confirmed, the result would directly affect checkpoint-selection practice in SFT-then-RL pipelines and motivate routine entropy monitoring. The variance formula is a clear strength: it is a direct, parameter-free derivation from Bernoulli statistics that supplies an explicit, falsifiable threshold p*(g) rather than a fitted quantity. The cross-model contrast (Qwen inversion versus DeepSeek compression) supplies a useful control, though model-specific factors are left open.
major comments (3)
- [Abstract] Abstract: the central causal claim—that SFT-induced entropy collapse (rather than other depth-dependent changes in policy quality or output distribution) reduces effective group-relative advantage variance and produces the observed GRPO rank inversion—is supported only by the pre-RL entropy correlation (ρ=+0.69) and the theoretical variance formula; the manuscript reports no direct empirical comparison of within-group reward variance or effective sample diversity during the first GRPO steps across the SFT-depth ladder.
- [Abstract] Abstract: the statement that KL regularization and label-smoothing variants “do not rescue the collapsed Qwen checkpoint” is used to argue the failure is not a trivial hyper-parameter artefact, yet the manuscript supplies neither the regularization coefficients nor the precise implementation details, leaving open whether the interventions were sufficient to restore rollout entropy.
- [Abstract] Abstract: the independence assumption underlying the variance formula p(1-p)(g-1)/g and the threshold p*(g) is not tested against the actual empirical distribution of group rewards in the low-entropy regime; any systematic dependence among the g samples would alter the effective variance and the location of p*.
minor comments (2)
- [Abstract] Abstract: the reported n=20 is not defined (e.g., evaluations per seed, total rollouts, or something else).
- [Abstract] Abstract: the precise definition of “pre RL entropy” (token-level, sequence-level, or rollout-level) and the exact number of samples used to compute it should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The points raised highlight opportunities to strengthen the empirical support for our proposed mechanism. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central causal claim—that SFT-induced entropy collapse (rather than other depth-dependent changes in policy quality or output distribution) reduces effective group-relative advantage variance and produces the observed GRPO rank inversion—is supported only by the pre-RL entropy correlation (ρ=+0.69) and the theoretical variance formula; the manuscript reports no direct empirical comparison of within-group reward variance or effective sample diversity during the first GRPO steps across the SFT-depth ladder.
Authors: We agree that direct measurement of within-group reward variance and sample diversity during early GRPO steps would provide stronger causal evidence beyond the pre-RL correlation and theoretical formula. In the revised manuscript we will add these empirical comparisons (computed from the rollout buffers of the first 50–100 GRPO steps) across the five SFT-depth checkpoints, plotted against both the theoretical baseline and the observed GRPO outcomes. revision: yes
-
Referee: [Abstract] Abstract: the statement that KL regularization and label-smoothing variants “do not rescue the collapsed Qwen checkpoint” is used to argue the failure is not a trivial hyper-parameter artefact, yet the manuscript supplies neither the regularization coefficients nor the precise implementation details, leaving open whether the interventions were sufficient to restore rollout entropy.
Authors: We acknowledge that the regularization experiments lack sufficient detail. In the revision we will report the exact KL coefficients (e.g., 0.01 and 0.05), label-smoothing strengths, the precise application schedule within the GRPO objective, and the resulting pre- and post-intervention entropy values on the collapsed checkpoint to demonstrate that entropy was not restored to levels that would avoid the variance collapse. revision: yes
-
Referee: [Abstract] Abstract: the independence assumption underlying the variance formula p(1-p)(g-1)/g and the threshold p*(g) is not tested against the actual empirical distribution of group rewards in the low-entropy regime; any systematic dependence among the g samples would alter the effective variance and the location of p*.
Authors: The Bernoulli independence assumption is standard for binary rewards but merits empirical scrutiny. We will add an analysis that computes the empirical within-group reward variance directly from the low-entropy rollouts and compares it to the theoretical p(1-p)(g-1)/g prediction; any systematic deviation will be quantified and its effect on the location of p*(g) discussed in the revised text. revision: yes
Circularity Check
No circularity: empirical correlations and Bernoulli variance formula are independent of the central claims.
full rationale
The paper presents an observational study across SFT depth ladders on two models, reporting measured pass@1, entropy values, and downstream GRPO pass@10 outcomes along with an empirical Spearman correlation ρ=+0.69. The within-group variance expression p(1-p)(g-1)/g is the direct algebraic consequence of the Bernoulli variance for g i.i.d. binary samples and does not depend on any fitted parameter or result from the present experiments. No derivation step reduces a claimed prediction to a fitted input by construction, no self-citation chain is invoked as load-bearing justification, and the diagnostic is described as a post-hoc combination of the observed quantities rather than a closed-form tautology. The central claim therefore rests on external experimental measurements rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Expected within-group advantage variance for binary rewards equals p(1-p)(g-1)/g
Reference graph
Works this paper leans on
-
[1]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint, arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[2]
Chen, Z., Qin, X., Wu, Y., Ling, Y., Ye, Q., Zhao, W. X., and Shi, G. Pass@k training for adaptively balancing exploration and exploitation of large reasoning models. arXiv preprint arXiv:2508.10751, 2025
arXiv 2025
-
[3]
Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q. V., Levine, S., and Ma, Y. SFT memorizes, RL generalizes: A comparative study of foundation model post-training. In International Conference on Machine Learning, 2025. arXiv:2501.17161
Pith/arXiv arXiv 2025
-
[4]
Cui, G. et al. The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617, 2025
Pith/arXiv arXiv 2025
-
[5]
F., Lan, Q., Rahman, P., Mahmood, A
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. Loss of plasticity in deep continual learning. Nature, 2024
2024
-
[6]
Dragoi, M. et al. Beyond pass@k: Breadth-depth metrics for reasoning boundaries. arXiv preprint arXiv:2510.08325, 2025
arXiv 2025
-
[7]
Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y. K., et al. DeepSeek-Coder : When the large language model meets programming -- the rise of code intelligence. arXiv preprint arXiv:2401.14196, 2024
Pith/arXiv arXiv 2024
-
[8]
Qwen2.5-coder technical report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al. Qwen2.5-coder technical report. arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[9]
Quagmires in SFT - RL post-training: When high SFT scores mislead and what to use instead
Kang, F., Kuchnik, M., Padthe, K., Vlastelica, M., Jia, R., Wu, C.-J., and Ardalani, N. Quagmires in SFT - RL post-training: When high SFT scores mislead and what to use instead. arXiv preprint arXiv:2510.01624, 2025
arXiv 2025
-
[10]
Maintaining plasticity in continual learning via regenerative regularization
Kumar, S., Marklund, H., and Van Roy, B. Maintaining plasticity in continual learning via regenerative regularization. arXiv preprint arXiv:2308.11958, 2023
arXiv 2023
-
[11]
Liu, J., Xia, C. S., Wang, Y., and Zhang, L. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models with EvalPlus . In Advances in Neural Information Processing Systems, 2023. arXiv:2305.01210
Pith/arXiv arXiv 2023
-
[12]
A., Pascanu, R., and Dabney, W
Lyle, C., Zheng, Z., Nikishin, E., Pires, B. A., Pascanu, R., and Dabney, W. Understanding plasticity in neural networks. In International Conference on Machine Learning, 2023. arXiv:2303.01486
arXiv 2023
-
[13]
The primacy bias in deep reinforcement learning
Nikishin, E., Schwarzer, M., D'Oro, P., Bacon, P.-L., and Courville, A. The primacy bias in deep reinforcement learning. In International Conference on Machine Learning, 2022. arXiv:2205.07802
arXiv 2022
-
[14]
DeepSeekMath : Pushing the limits of mathematical reasoning in open language models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[15]
Walder, C. and Karkhanis, D. Pass@ K policy optimization: Solving harder reinforcement learning problems. In Advances in Neural Information Processing Systems, 2025. arXiv:2505.15201
Pith/arXiv arXiv 2025
-
[16]
Xu, X. et al. KodCode : A diverse, challenging, and verifiable synthetic dataset for coding. In Annual Meeting of the Association for Computational Linguistics, 2025. arXiv:2503.02951
arXiv 2025
-
[17]
Yu, Q. et al. DAPO : An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[18]
Yue, Y. et al. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? In Advances in Neural Information Processing Systems, 2025. arXiv:2504.13837
Pith/arXiv arXiv 2025
-
[19]
Good SFT optimizes for SFT , better SFT prepares for reinforcement learning
Zhang, D., Xu, Y., Wang, H., Chen, Q., and Peng, H. Good SFT optimizes for SFT , better SFT prepares for reinforcement learning. arXiv preprint arXiv:2602.01058, 2026
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.