APT: Atomic Physical Transitions for Causal Video-Language Understanding
Pith reviewed 2026-06-26 22:03 UTC · model grok-4.3
The pith
Atomic Physical Transitions give VLMs ordered causal sequences instead of single event labels for physical videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Atomic Physical Transitions are minimal, temporally localized state changes that bind a visible cue to an active physical mechanism and before/after dynamical regimes; representing a video as an APT chain supplies the causal sequence that explains why an event occurs, and APT-Tune teaches VLMs to treat these chains as a grounded representation rather than an isolated answer format.
What carries the argument
Atomic Physical Transitions (APTs): minimal temporally localized state changes that bind visible cues to physical mechanisms and before/after dynamical regimes.
If this is right
- Current VLMs achieve at most 14 percent zero-shot recall on the defined transition types.
- Direct fine-tuning on APT chains raises transition detection but produces measurable forgetting on standard event-level video tasks.
- APT-Tune with 11 million LoRA parameters on a 2B-parameter VLM raises APT recall while also raising event-level video transfer performance.
- APTs function as a human-aligned causal supervision signal rather than merely a new answer format.
Where Pith is reading between the lines
- If APT chains remain stable across new video domains, the same supervision recipe could be applied to embodied agents that must predict physical outcomes.
- The distinction between format learning and mechanism learning suggests similar conditional co-training could be tested on other structured prediction tasks in video.
- Extending the transition vocabulary beyond the current 14 types would test whether the same tuning approach continues to avoid forgetting at larger scale.
Load-bearing premise
The mixed-source APT data from human annotations and simulator ground truth accurately captures the true causal mechanisms and before/after regimes without introducing annotation artifacts or simulator-reality gaps.
What would settle it
A model trained with APT-Tune that still shows the same degree of event-level forgetting on held-out video questions as a model trained directly on APT chains would falsify the claim that APTs supply a reusable physical representation.
Figures


read the original abstract
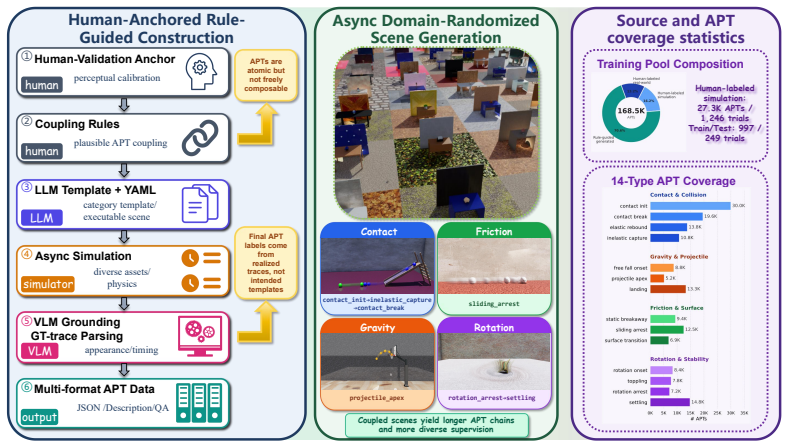
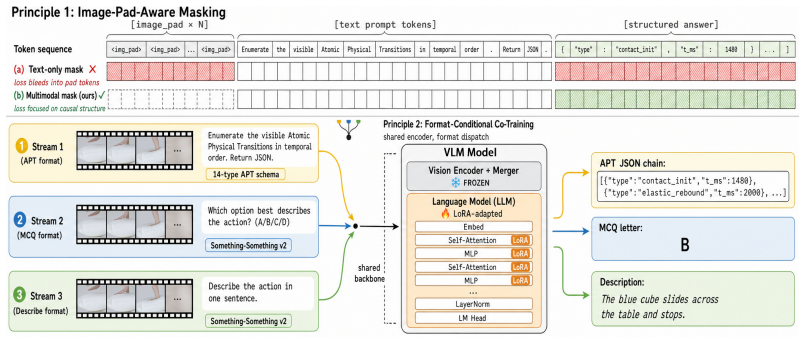
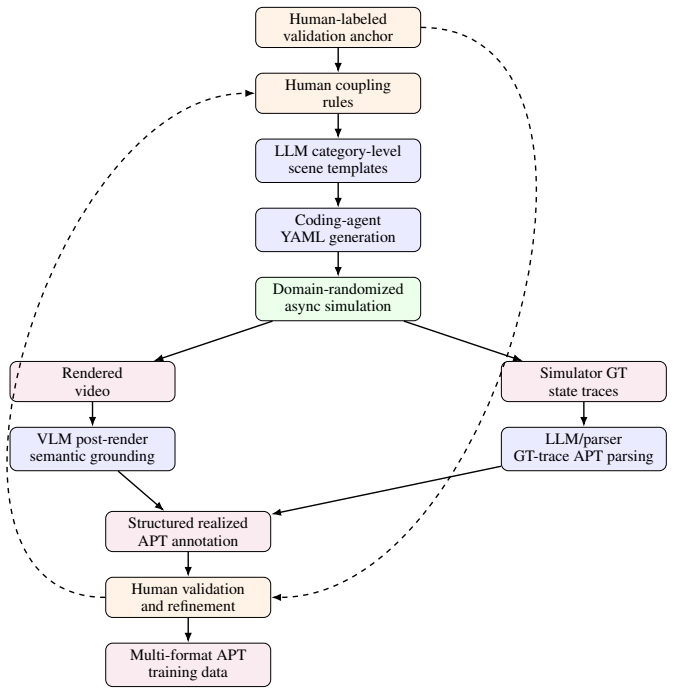
Physical events are not understood by their names alone, but by the causal state changes that compose them. A clip-level label such as "bounce" can be correct while hiding the process that makes the event physically valid, from support loss and contact onset to rebound and settling. To make this hidden process explicit, we introduce Atomic Physical Transitions (APTs): minimal, temporally localized state changes that bind a visible cue to an active physical mechanism and before/after dynamical regimes. An APT chain represents a video as an ordered causal transition sequence rather than a single aggregate event label: event labels tell what happened; APT chains explain why it happened. To make APTs learnable by VLMs, we construct mixed-source APT data from human annotations and simulator ground truth, covering 14 transition types across contact, gravity, friction, and rotation/stability, with 27,303 timed instances over 1,246 trials. Using this data, we find that current VLMs miss transition-level physics, with zero-shot recall at most 14% and errors dominated by missed transitions. Direct fine-tuning on APT chains improves transition detection but causes event-level forgetting, indicating that the model learns a specialized answer format rather than a reusable physical representation. We therefore propose APT-Tune, a parameter-efficient recipe that teaches VLMs to use causal transitions without forgetting how to answer video questions. It combines image-pad-aware supervision, format-conditional co-training, and mechanism-conditioned domain-to-type decoding to make APT learning format-robust and physically grounded. With only 11 M LoRA parameters on Qwen3-VL-2B, APT-Tune substantially improves APT recall while also improving event-level video transfer. These results show that APTs are not a new answer format, but a human-aligned causal supervision signal for physical video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Atomic Physical Transitions (APTs) as minimal, temporally localized state changes that bind visible cues to physical mechanisms and before/after regimes, representing videos as causal transition chains rather than aggregate event labels. It constructs a mixed human-annotation and simulator-ground-truth dataset covering 14 transition types with 27,303 timed instances over 1,246 trials, shows that current VLMs achieve at most 14% zero-shot APT recall with errors dominated by missed transitions, and proposes APT-Tune (image-pad-aware supervision, format-conditional co-training, and mechanism-conditioned decoding) that uses 11M LoRA parameters on Qwen3-VL-2B to improve both APT recall and event-level video transfer without forgetting.
Significance. If the mixed-source APT labels faithfully encode true causal mechanisms, the work supplies a reusable, human-aligned supervision signal that moves VLMs beyond format learning toward genuine physical video understanding; the parameter-efficient recipe and reported transfer gains would be a concrete advance for causal reasoning in vision-language models.
major comments (2)
- [Abstract / Data Construction] Abstract and Data Construction: the central interpretation that APT-Tune teaches 'human-aligned causal supervision' rather than a specialized answer format rests on the 27,303 mixed human/simulator instances correctly capturing true before/after dynamical regimes across the 14 transition types; however, no inter-source agreement statistics, alignment procedure between human and simulator labels, or external validation against real-world physics are supplied, leaving open the possibility that reported zero-shot baselines and APT-Tune gains measure dataset fidelity instead of physical understanding.
- [Results] Results section (APT-Tune evaluation): the claim that the method improves event-level video transfer while preserving performance requires explicit controls showing that gains survive after matching for answer format and training data volume; without such controls the transfer result cannot be cleanly attributed to the causal supervision signal.
minor comments (2)
- [Abstract] The abstract states zero-shot recall is 'at most 14%' but does not specify the exact models, prompts, or decoding settings used to obtain this figure.
- [Introduction] Notation for the 14 transition types and the precise definition of 'timed instances' versus 'trials' should be introduced with a table or explicit list early in the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Data Construction] Abstract and Data Construction: the central interpretation that APT-Tune teaches 'human-aligned causal supervision' rather than a specialized answer format rests on the 27,303 mixed human/simulator instances correctly capturing true before/after dynamical regimes across the 14 transition types; however, no inter-source agreement statistics, alignment procedure between human and simulator labels, or external validation against real-world physics are supplied, leaving open the possibility that reported zero-shot baselines and APT-Tune gains measure dataset fidelity instead of physical understanding.
Authors: We agree that explicit documentation of label quality would strengthen the claims. Simulator labels are produced deterministically from a physics engine using known parameters for each of the 14 transition types. Human annotations follow a written protocol that identifies the same visible state changes and mechanisms. In revision we will add inter-annotator agreement figures for the human subset and a clear description of how the two sources are merged under a shared taxonomy. Full external validation against independent real-world physics experiments is not present in the current work and would require physical apparatus outside the scope of the released dataset; we will note this as a limitation rather than assert perfect fidelity. revision: partial
-
Referee: [Results] Results section (APT-Tune evaluation): the claim that the method improves event-level video transfer while preserving performance requires explicit controls showing that gains survive after matching for answer format and training data volume; without such controls the transfer result cannot be cleanly attributed to the causal supervision signal.
Authors: We accept that stronger controls would make the attribution clearer. The existing results already show that plain fine-tuning on APT chains produces event-level forgetting while APT-Tune does not, which is consistent with learning reusable physical representations rather than format alone. To isolate the contribution of the causal content, we will add an ablation that trains on an equal volume of data using a matched answer format but with non-causal event descriptions. This control will be reported in the revised results section. revision: yes
Circularity Check
No circularity; empirical work with new data and tuning procedure
full rationale
The manuscript introduces APTs as a novel annotation scheme, constructs a mixed human/simulator dataset of 27,303 instances, and evaluates APT-Tune (LoRA fine-tuning with image-pad-aware supervision, format-conditional co-training, and mechanism-conditioned decoding). No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear. All load-bearing claims rest on external data collection and standard VLM fine-tuning rather than reducing to quantities defined inside the paper itself. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MS-TCN: Multi-stage temporal convolutional network for action segmentation
Yazan Abu Farha and Juergen Gall. MS-TCN: Multi-stage temporal convolutional network for action segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3575–3584, 2019. URL https://openaccess.thecvf. com/content_CVPR_2019/html/Abu_Farha_MS-TCN_Multi-Stage_Temporal_ Convolutional_Network_for_Action_Segmentat...
2019
-
[2]
Interaction networks for learning about objects, rela- tions and physics
Peter Battaglia, Razvan Pascanu, Matthew Lai, Danilo Jimenez Rezende, and Koray Kavukcuoglu. Interaction networks for learning about objects, rela- tions and physics. InAdvances in Neural Information Processing Systems, vol- ume 29, 2016. URL https://proceedings.neurips.cc/paper/2016/hash/ 3147da8ab4a0437c15ef51a5cc7f2dc4-Abstract.html
2016
-
[3]
Bear, Elias Wang, Damian Mrowca, Felix J
Daniel M. Bear, Elias Wang, Damian Mrowca, Felix J. Binder, Hsiao-Yu Fish Tung, R. T. Pramod, Cameron Holdaway, Sirui Tao, Kevin A. Smith, Fan-Yun Sun, Fei-Fei Li, Nancy Kanwisher, Joshua B. Tenenbaum, Daniel L. K. Yamins, and Judith E. Fan. Physion: Eval- uating physical prediction from vision in humans and machines. InProceedings of the Neu- ral Informa...
2021
-
[4]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. ActivityNet: A large-scale video benchmark for human activity understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 961–970, June 2015. doi: 10.1109/CVPR.2015.7298698. URL https://openaccess.thecvf.com/content_cvpr_ 2015/html/Hei...
-
[5]
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, et al. Temporalbench: Benchmarking fine-grained temporal understanding for multimodal video models.arXiv preprint arXiv:2410.10818, 2024
arXiv 2024
-
[6]
InternVL3.5: Advancing open-source multimodal understanding.arXiv preprint, 2025
Zhe Chen et al. InternVL3.5: Advancing open-source multimodal understanding.arXiv preprint, 2025
2025
-
[7]
Michelene T. H. Chi, Paul J. Feltovich, and Robert Glaser. Categorization and representation of physics problems by experts and novices.Cognitive Science, 5(2):121–152, 1981. doi: 10.1207/s15516709cog0502_2. URLhttps://doi.org/10.1207/s15516709cog0502_2. 11
-
[8]
PhysBench: Benchmarking and enhancing vision-language models for physical world understanding
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, and Yue Wang. PhysBench: Benchmarking and enhancing vision-language models for physical world understanding. InInternational Conference on Learning Representa- tions, 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/ f38cb4cf9a5eaa92b3cfa481832719c6-Abstract-Conference.html
2025
-
[9]
Scaling egocentric vision: The EPIC-KITCHENS dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Scaling egocentric vision: The EPIC-KITCHENS dataset. InPro- ceedings of the European Conference on Computer Vision, pages 720–736, Septem- ber 2018. URL https://openaccess.t...
2018
-
[10]
Bear, Dan Gutfreund, David Cox, Antonio Torralba, James J
Chuang Gan, Jeremy Schwartz, Seth Alter, Damian Mrowca, Martin Schrimpf, James Traer, Julian De Freitas, Jonas Kubilius, Abhishek Bhandwaldar, Nick Haber, Megumi Sano, Kuno Kim, Elias Wang, Michael Lingelbach, Aidan Curtis, Kevin Feigelis, Daniel M. Bear, Dan Gutfreund, David Cox, Antonio Torralba, James J. DiCarlo, Joshua B. Tenenbaum, Josh H. McDermott,...
2021
-
[11]
Gemini 2.5 technical report.Technical Report, 2025
Google. Gemini 2.5 technical report.Technical Report, 2025
2025
-
[12]
Yolact: Real- time instance segmentation,
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The “Something Something” video database for learning and evaluating visual common sense. InProceedings of the IEEE I...
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
2022
-
[14]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Fei-Fei Li, C. Lawrence Zitnick, and Ross Girshick. CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recog- nition, pages 2901–2910, July 2017. URL https://openaccess.thecvf.com/content_ cvpr...
2017
-
[15]
Neural relational inference for interacting systems
Thomas Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard Zemel. Neural relational inference for interacting systems. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 2688–
-
[16]
URLhttps://proceedings.mlr.press/v80/kipf18a.html
PMLR, 2018. URLhttps://proceedings.mlr.press/v80/kipf18a.html
2018
-
[17]
Larkin, John McDermott, Dorothea P
Jill H. Larkin, John McDermott, Dorothea P. Simon, and Herbert A. Simon. Expert and novice performance in solving physics problems.Science, 208(4450):1335–1342, 1980. doi: 10.1126/ science.208.4450.1335. URLhttps://doi.org/10.1126/science.208.4450.1335
-
[18]
Flynn, René Vidal, Austin Reiter, and Gregory D
Colin Lea, Michael D. Flynn, René Vidal, Austin Reiter, and Gregory D. Hager. Temporal convolutional networks for action segmentation and detection. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 156– 165, 2017. URL https://openaccess.thecvf.com/content_cvpr_2017/html/Lea_ Temporal_Convolutional_Networks_CVPR_2017...
2017
-
[19]
MVBench: A comprehensive multi-modal video understanding benchmark
Kunchang Li et al. MVBench: A comprehensive multi-modal video understanding benchmark. InCVPR, 2024
2024
-
[20]
Arxiv Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual representation by alignment before projection. InProceedings of the 12 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971–5984, Miami, Florida, USA, 2024. Association for Computational Linguistics. doi: 10.18653/v1/202...
-
[21]
Ling, Jeff Sanny, and William Moebs.University Physics Volume 1
Samuel J. Ling, Jeff Sanny, and William Moebs.University Physics Volume 1. OpenStax, Rice University, 2016. URL https://openstax.org/details/books/ university-physics-volume-1
2016
-
[22]
Visual in- struction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual in- struction tuning. InAdvances in Neural Information Processing Systems, vol- ume 36, 2023. URL https://papers.neurips.cc/paper_files/paper/2023/hash/ 6dcf277ea32ce3288914faf369fe6de0-Abstract-Conference.html
2023
-
[23]
UniGarment: A unified simulation and benchmark for garment manipulation
Haoran Lu, Yitong Li, Ruihai Wu, Chuanruo Ning, Yan Shen, and Hao Dong. UniGarment: A unified simulation and benchmark for garment manipulation. InICRA Workshop on Representing and Manipulating Deformable Objects, 2024. URL https://garmentlab.github.io/. Extended Abstract; Oral
2024
-
[24]
Garmentlab: A unified simulation and benchmark for garment manipula- tion
Haoran Lu, Ruihai Wu, Yitong Li, Sijie Li, Ziyu Zhu, Chuanruo Ning, Yan Shen, Longzan Luo, Yuanpei Chen, and Hao Dong. GarmentLab: A unified simulation and benchmark for garment manipulation. InAdvances in Neural Information Processing Systems, volume 37, pages 11866–11903, 2024. doi: 10.52202/079017-0379. URL https://openreview.net/ forum?id=bIRcf8i1kp
-
[25]
Haoran Lu, Shang Wu, Jianshu Zhang, Maojiang Su, Guo Ye, Chenwei Xu, Lie Lu, Pranav Maneriker, Fan Du, Manling Li, Zhaoran Wang, and Han Liu. Phys4D: Fine-grained physics- consistent 4d modeling from video diffusion.arXiv preprint arXiv:2603.03485, 2026
Pith/arXiv arXiv 2026
-
[26]
Chak-Wing Mak, Guanyu Zhu, Boyi Zhang, Hongji Li, Xiaowei Chi, Kevin Zhang, Yichen Wu, Yangfan He, Chun-Kai Fan, Wentao Lu, Kuangzhi Ge, Xinyu Fang, Hongyang He, Kuan Lu, Tianxiang Xu, Li Zhang, Yongxin Ni, Youhua Li, and Shanghang Zhang. PhysicsMind: Sim and real mechanics benchmarking for physical reasoning and prediction in foundational vlms and world ...
-
[27]
Jiayuan Mao, Xuelin Yang, Xikun Zhang, Noah D. Goodman, and Jiajun Wu. CLEVRER- humans: Describing physical and causal events the human way.arXiv preprint arXiv:2310.03635, 2023. URLhttps://arxiv.org/abs/2310.03635
arXiv 2023
-
[28]
Mayank Mittal et al. Isaac Lab: A GPU-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[29]
Do generative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, March 2026
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, March 2026. URL https: //openaccess.thecvf.com/content/WACV2026/html/Motamed_Do_Generative_ Video_Models_Understand_Physic...
2026
-
[30]
Isaac sim, 2025
NVIDIA. Isaac sim, 2025. URLhttps://github.com/isaac-sim/IsaacSim
2025
-
[31]
GPT-4.1 technical report.Technical Report, 2025
OpenAI. GPT-4.1 technical report.Technical Report, 2025
2025
-
[32]
Qwen3-VL: Multimodal understanding at scale.Technical Report, 2025
Qwen Team. Qwen3-VL: Multimodal understanding at scale.Technical Report, 2025
2025
-
[33]
Tenenbaum, Daniel L
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Joshua B. Tenenbaum, Daniel L. K. Yamins, Judith E. Fan, and Kevin A. Smith. Physion++: Evaluating physical scene understanding that requires online inference of different phys- ical properties. InAdvances in Neural Information Processing Systems, volume 36,
-
[34]
URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/ d3e8011c912e651ab2a76e7935a1e464-Abstract-Datasets_and_Benchmarks.html. 13
2023
-
[35]
Xiyang Wu, Zongxia Li, Jihui Jin, Guangyao Shi, Gouthaman KV, Vishnu Raj, Nilotpal Sinha, Jingxi Chen, Fan Du, and Dinesh Manocha. MASS: Motion-aware spatial-temporal grounding for physics reasoning and comprehension in vision-language models.arXiv preprint arXiv:2511.18373, 2025. doi: 10.48550/arXiv.2511.18373. URL https://arxiv.org/abs/ 2511.18373
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.18373 2025
-
[36]
Tenenbaum
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B. Tenenbaum. CLEVRER: CoLlision events for video representation and rea- soning. InInternational Conference on Learning Representations, 2020. URL https: //openreview.net/forum?id=HkxYzANYDB
2020
-
[37]
Young and Roger A
Hugh D. Young and Roger A. Freedman.University Physics with Modern Physics. Pearson, 15 edition, 2020
2020
-
[38]
Jeffrey M. Zacks and Khena M. Swallow. Event segmentation.Current Directions in Psychological Science, 16(2):80–84, 2007. doi: 10.1111/j.1467-8721.2007.00480.x. URL https://doi.org/10.1111/j.1467-8721.2007.00480.x
-
[39]
Chenyu Zhang, Daniil Cherniavskii, Antonios Tragoudaras, Antonios V ozikis, Thijmen Nijdam, Derck W. E. Prinzhorn, Mark Bodracska, Nicu Sebe, Andrii Zadaianchuk, and Efstratios Gavves. Morpheus: Benchmarking physical reasoning of video generative models with real physical experiments.arXiv preprint arXiv:2504.02918, 2025. doi: 10.48550/arXiv.2504.02918. U...
-
[40]
The test split contains 249 trials, approximately 5.5K APT instances, consisting of 100 CLEVRER trials and 149 Physion++ trials
The training split contains 997 trials, approximately 21.8K APT instances, consisting of 400 CLEVRER trials and 597 Physion++ trials. The test split contains 249 trials, approximately 5.5K APT instances, consisting of 100 CLEVRER trials and 149 Physion++ trials. All 14 APT types are represented, but the distribution is naturally imbalanced: contact_init a...
-
[41]
Models with separate frame-rate conventions receive matched 16-frame samples
Input normalization.Each model receives the same 16 uniformly sampled frames per video at source resolution. Models with separate frame-rate conventions receive matched 16-frame samples. 38
-
[42]
type": <label>,
Structured output.A single shared APT-schema prompt asks the model to enumerate timed APTs as a JSON array of records: {"type": <label>, "t_ms": <int>} . The 14 type names are listed verbatim with one-line definitions. No chain-of-thought is requested
-
[43]
Robust parsing.Predictions are parsed with a tolerant JSON parser that recovers from common formatting errors, including trailing commas, unterminated arrays, and missing closing braces
-
[44]
Matching is one-to-one and greedy by confidence when confidence is available, or by parsing order otherwise
Matching.A predicted APT matches a ground-truth APT if the type matches and the timestamp lies within ∆t=±200 ms. Matching is one-to-one and greedy by confidence when confidence is available, or by parsing order otherwise. Each ground-truth APT can be matched at most once
-
[45]
type": "free_fall_onset
Controlled comparison.The same prompt and frame list are used for zero-shot baselines and fine-tuned models. The only difference across rows in the result table is the model weights. Listing 16: Evaluation-time APT-schema prompt. You are given 16 frames sampled uniformly from a physics video. Task: Enumerate all visible Atomic Physical Transitions (APTs) ...
-
[46]
Guidelines: 46 • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.