Skill-MAS: Evolving Meta-Skill for Automatic Multi-Agent Systems
Pith reviewed 2026-06-26 18:44 UTC · model grok-4.3
The pith
Skill-MAS evolves a reusable Meta-Skill for multi-agent LLM systems by distilling strategy principles from task trajectories without parametric updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
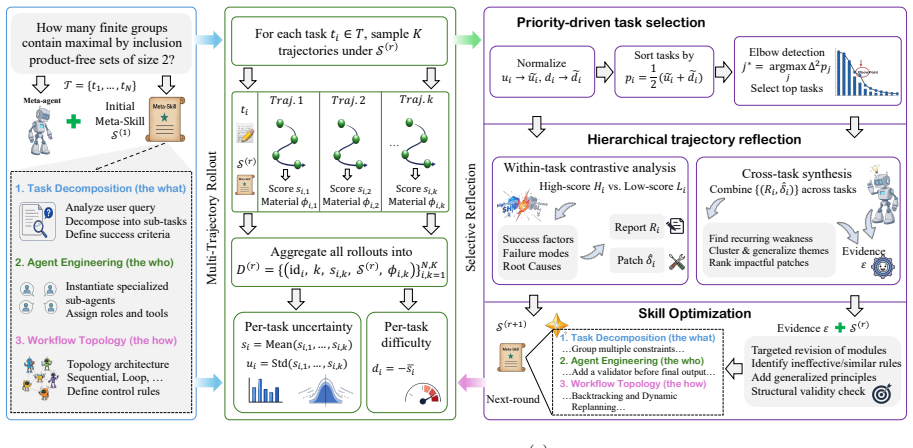
Skill-MAS conceptualizes the high-level orchestration capability as an evolvable Meta-Skill and refines architectural knowledge through a closed optimization loop of Multi-Trajectory Rollout, which samples a behavioral distribution for each task, and Selective Reflection, which adaptively selects priority tasks and applies hierarchical contrastive analysis to distill systemic experience into generalizable, strategy-level principles.
What carries the argument
The Meta-Skill as high-level orchestration capability, refined via the closed loop of Multi-Trajectory Rollout and Selective Reflection with hierarchical contrastive analysis.
If this is right
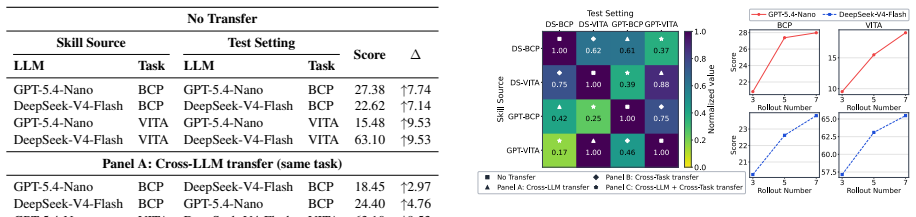
- Automatic MAS generation can achieve performance gains on complex benchmarks while using frontier LLMs without gradient updates.
- The method maintains a favorable cost-performance trade-off by avoiding repeated identical searches and large-scale training.
- Evolved Meta-Skills exhibit robustness and strong transferability across unseen tasks and different LLMs.
- Experience retention is decoupled from parametric updates, allowing scaling to large models.
Where Pith is reading between the lines
- The method could support continual adaptation of agent orchestration rules across entirely new domains without retraining base models.
- If the distillation step generalizes, similar rollout-plus-reflection loops might apply to other LLM orchestration problems such as tool-use planning.
- Transferability across LLMs suggests the Meta-Skill captures structural patterns that are somewhat model-agnostic.
Load-bearing premise
Hierarchical contrastive analysis on selectively chosen tasks can reliably distill generalizable strategy-level principles rather than task-specific patterns or noise.
What would settle it
Testing whether the evolved Meta-Skill produces no performance gain or loses transferability when applied to unseen benchmarks or switched to a different LLM.
Figures



















read the original abstract
Large Language Model (LLM)-based automatic Multi-Agent Systems (MAS) generation has become a crucial frontier for tackling complex tasks. However, existing methods face a dilemma between model capability and experience retention. Inference-time MAS leverages frozen frontier LLMs but repeats identical searches without learning from past experience. Conversely, Training-time MAS internalizes experience via gradient updates but is constrained by the low capability ceiling of smaller models, and is hard to scale to large frontier LLMs. To bridge this gap, we propose Skill-MAS, a novel third path that decouples experience retention from parametric updates by conceptualizing the high-level orchestration capability as an evolvable Meta-Skill. Skill-MAS refines this architectural knowledge through a closed optimization loop: (1) Multi-Trajectory Rollout samples a behavioral distribution for each task under the current Meta-Skill; and (2) Selective Reflection adaptively selects priority tasks and applies hierarchical contrastive analysis to distill systemic experience into generalizable, strategy-level principles. Extensive experiments across four complex benchmarks and four distinct LLMs demonstrate that Skill-MAS not only achieves remarkable performance gains but also maintains a favorable cost-performance trade-off. Further analysis reveals that the evolved Meta-Skills are highly robust and exhibit strong transferability across unseen tasks and different LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Skill-MAS, a third path for LLM-based automatic multi-agent system generation that evolves a Meta-Skill to retain orchestration experience without parametric updates. It employs a closed loop consisting of (1) Multi-Trajectory Rollout to sample behavioral distributions under the current Meta-Skill and (2) Selective Reflection that adaptively selects priority tasks and applies hierarchical contrastive analysis to distill systemic experience into generalizable strategy-level principles. Experiments across four complex benchmarks and four LLMs are claimed to demonstrate remarkable performance gains, a favorable cost-performance trade-off, robustness, and strong transferability to unseen tasks and different LLMs.
Significance. If the empirical claims hold, the work offers a conceptually appealing bridge between inference-time MAS (which cannot retain experience) and training-time MAS (which are limited by model scale). The decoupling of experience retention from gradient updates via an evolvable Meta-Skill could enable scalable, high-capability automatic MAS. The closed optimization loop and emphasis on hierarchical contrastive distillation represent a novel framing, though the significance hinges on whether the distilled principles are demonstrably general rather than benchmark-specific.
major comments (2)
- [§3.2] §3.2 (Selective Reflection): the description of hierarchical contrastive analysis does not specify how contrastive pairs are constructed, how hierarchy levels are defined, or the precise selection criteria for priority tasks. Without these details it is impossible to evaluate whether the procedure reliably extracts transferable orchestration strategies or instead amplifies task idiosyncrasies from the four benchmarks; this mechanism is load-bearing for the robustness and cross-task/cross-LLM transferability claims.
- [Experiments] Experiments section (transferability results): the reported strong transferability to unseen tasks is presented without explicit controls that isolate the contribution of the evolved Meta-Skill from possible memorization of benchmark patterns. A direct comparison against a baseline that applies task-specific heuristics distilled from the same rollouts would be required to substantiate that the output constitutes generalizable strategy-level principles rather than benchmark-tuned heuristics.
minor comments (2)
- [Abstract] The abstract states performance gains and cost trade-offs but does not name the four benchmarks or the four LLMs; adding these identifiers would improve reproducibility.
- [§3] Notation for the Meta-Skill and the contrastive loss (if any) should be introduced consistently in §3 and reused in the experimental tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas for improved clarity and rigor. We address each major comment point by point below and will revise the manuscript accordingly to strengthen the presentation of the Selective Reflection mechanism and the transferability analysis.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Selective Reflection): the description of hierarchical contrastive analysis does not specify how contrastive pairs are constructed, how hierarchy levels are defined, or the precise selection criteria for priority tasks. Without these details it is impossible to evaluate whether the procedure reliably extracts transferable orchestration strategies or instead amplifies task idiosyncrasies from the four benchmarks; this mechanism is load-bearing for the robustness and cross-task/cross-LLM transferability claims.
Authors: We agree that the current description in §3.2 is high-level and would benefit from explicit specifications to allow readers to assess the mechanism's ability to produce generalizable principles. In the revised manuscript we will expand this section to detail: contrastive pairs are formed from trajectories sampled under the same Meta-Skill that differ substantially in end-to-end task success; hierarchy levels are organized as task-specific orchestration patterns, agent-role coordination rules, and system-wide workflow abstractions; and priority tasks are chosen by ranking tasks according to performance variance across the multi-trajectory rollout combined with a diversity score that favors tasks exposing systemic rather than idiosyncratic failures. These additions will directly address concerns about benchmark idiosyncrasies versus transferable strategy-level principles. revision: yes
-
Referee: [Experiments] Experiments section (transferability results): the reported strong transferability to unseen tasks is presented without explicit controls that isolate the contribution of the evolved Meta-Skill from possible memorization of benchmark patterns. A direct comparison against a baseline that applies task-specific heuristics distilled from the same rollouts would be required to substantiate that the output constitutes generalizable strategy-level principles rather than benchmark-tuned heuristics.
Authors: We acknowledge that the transferability results, while showing gains on unseen tasks and across LLMs, would be more convincing with an explicit control isolating the Meta-Skill from potential benchmark-specific memorization. In the revision we will add a new baseline experiment that distills task-specific heuristics directly from the identical multi-trajectory rollouts (without the selective reflection and hierarchical contrastive steps) and compares its transfer performance against the full Skill-MAS Meta-Skill. This comparison will provide evidence that the evolved Meta-Skill captures generalizable orchestration strategies beyond task-tuned heuristics. revision: yes
Circularity Check
No circularity in derivation chain; method is empirical and self-contained
full rationale
The paper describes Skill-MAS as an iterative loop of Multi-Trajectory Rollout followed by Selective Reflection via hierarchical contrastive analysis to evolve a Meta-Skill. No equations, fitted parameters, predictions, or first-principles derivations are presented that could reduce to inputs by construction. Claims of robustness and transferability rest on external benchmark experiments across four tasks and four LLMs, not on any self-referential fitting or self-citation chain. No self-definitional steps, ansatz smuggling, or renaming of known results appear. The derivation is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Meta-Skill
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan
A survey on llm-based multi-agent sys- tems: workflow, infrastructure, and challenges.Vici- nagearth, 1(1):9. Yu Li, Rui Miao, Zhengling Qi, and Tian Lan. 2026. Arise: Agent reasoning with intrinsic skill evolu- tion in hierarchical reinforcement learning.arXiv preprint arXiv:2603.16060. Hehai Lin, Shilei Cao, Sudong Wang, Haotian Wu, Minzhi Li, Linyi Yan...
arXiv 2026
-
[2]
Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158. Shuai Pan, Yixiang Liu, Jiaye Gao, Te Gao, Weiwen Liu, Jianghao Lin, Zhihui Fu, Jun Wang, Weinan Zhang, and Yong Yu. 2026. Skillmas: Skill co-evolution with llm-based multi-agent system.arXiv preprint arXiv:2605.09341. Long Phan, Alice Gatti, Ziwe...
Pith/arXiv arXiv 2026
-
[3]
Skill-r1: Agent skill evolution via reinforce- ment learning.arXiv preprint arXiv:2605.09359. Kun Wang, Guibin Zhang, ManKit Ye, Xinyu Deng, Dongxia Wang, Xiaobin Hu, Jinyang Guo, Yang Liu, and Yufei Guo. 2025a. Mas 2: Self-generative, self-configuring, self-rectifying multi-agent systems. arXiv preprint arXiv:2509.24323. Qian Wang, Tianyu Wang, Zhenheng ...
Pith/arXiv arXiv 2025
-
[4]
Furina: A fully customizable role-playing benchmark via scalable multi-agent collaboration pipeline.arXiv preprint arXiv:2510.06800. Xiyang Wu, Zongxia Li, Guangyao Shi, Alexander Duffy, Tyler Marques, Matthew Lyle Olson, Tianyi Zhou, and Dinesh Manocha. 2026. Co-evolving llm decision and skill bank agents for long-horizon tasks. arXiv preprint arXiv:2604...
Pith/arXiv arXiv 2026
-
[5]
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Feng Xiong, Zengbin Wang, Yong Wang, Xuecai Hu, Jinghan He, Liang Lin, Yuan Liu, and Xiangxiang Chu. 2026. Ace-skill: Bootstrapping multimodal agents with prioritized and clustered evolution.arXiv preprint arXiv:2605.08887. Fengli Xu, Qianyue Ha...
Pith/arXiv arXiv 2026
-
[6]
- Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task
Task Decomposition Module (The "What") Core Objective: Analyze the user query and break it down into a logical blueprint. - Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task. - Sub-task Breakdown: Decompose the high-level request into a set of discrete, manageable, and logically cohe...
-
[7]
- Role Profiling: Assign a unique identity and specialized role to each sub-agent based on its target sub-task
Agent Engineering Module (The "Who") Core Objective: Design specialized sub-agents tailored for the sub-tasks defined in Stage 1. - Role Profiling: Assign a unique identity and specialized role to each sub-agent based on its target sub-task. - Instruction Design: Draft precise system prompts/instructions. Define the agent’s specific goals, behavioral boun...
-
[8]
Workflow & Orchestration Module (The "How") Core Objective: Wire the distinct agents from Stage 2 into a functional, executable Multi-Agent System (MAS). - Architectural Topology: You can design the optimal MAS architecture (e.g., Sequential Pipeline, Router-based, Hierarchi- cal, or Blackboard) based on Stage 1’s logical dependencies. For those complex b...
-
[9]
- Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task
Task Decomposition Module (The "What") Core Objective: Analyze the user query and break it down into a logical blueprint. - Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task. - Sub-task Breakdown: Decompose the high-level request into a set of discrete, manageable, and logically cohe...
-
[10]
This node frames the entire problem space and ensures all downstream agents operate under a shared understanding
Context-Scoping Root Node: A dedicated root sub-task that defines scope, key concepts, metrics, terminology, and evaluation criteria before any analytical work begins. This node frames the entire problem space and ensures all downstream agents operate under a shared understanding
-
[11]
These must be designed to run in parallel from the context-scoping root, with no intermediate sequential dependencies among them
Parallel Analytical Branches: One sub-task per distinct analytical component (capped at four branches). These must be designed to run in parallel from the context-scoping root, with no intermediate sequential dependencies among them
-
[12]
Capability to analyze methods for
Dedicated Synthesis Terminal Node: A final sub-task that receives the outputs of all parallel branches and integrates them into the requested cohesive output (e.g., report, article, synthesis). The synthesis node must be the only terminal node. - Hard Constraint: Strict sequential chaining of analytical components is disallowed for such tasks. If the quer...
-
[13]
Soft pass: coverage of <missing terms> and token count <X%> below threshold. Please expand in synthesis
Agent Engineering Module (The "Who") Core Objective: Design specialized sub-agents tailored for the sub-tasks defined in Stage 1. - Role Profiling: Assign a unique identity and specialized role to each sub-agent based on its target sub-task. - Instruction Design: Draft precise system prompts/instructions. Define the agent’s specific goals, behavioral boun...
-
[14]
The following required dimension appears to have insufficient coverage: <dimension>. You must include a dedicated section addressing it
Workflow & Orchestration Module (The "How") Core Objective: Wire the distinct agents from Stage 2 into a functional, executable Multi-Agent System (MAS). - Architectural Topology: Design the optimal MAS architecture (e.g., Sequential Pipeline, Router-based, Hierarchical, or Blackboard) based on Stage 1’s logical dependencies. For complex sub-tasks, embed ...
-
[15]
- Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task
Task Decomposition Module (The "What") Core Objective: Analyze the user query and break it down into a logical blueprint. - Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task. - Sub-task Breakdown: Decompose the high-level request into a set of discrete, manageable, and logically cohe...
-
[16]
verification report
Agent Engineering Module (The "Who") Core Objective: Design specialized sub-agents tailored for the sub-tasks defined in Stage 1. - Role Profiling: Assign a unique identity and specialized role to each sub-agent based on its target sub-task. - Instruction Design: Draft precise system prompts/instructions. Define the agent’s specific goals, behavioral boun...
-
[17]
Workflow & Orchestration Module (The "How") Core Objective: Wire the distinct agents from Stage 2 into a functional, executable Multi-Agent System (MAS). - Architectural Topology: You can design the optimal MAS architecture (e.g., Sequential Pipeline, Router-based, Hierarchi- cal, or Blackboard) based on Stage 1’s logical dependencies. For those complex b...
-
[18]
- Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task
Task Decomposition Module (The "What") Core Objective: Analyze the user query and break it down into a logical blueprint. - Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task. - Sub-task Breakdown: Decompose the high-level request into a set of discrete, manageable, and logically cohe...
-
[19]
Best guess: [answer] (unverified constraints: [list])
Agent Engineering Module (The "Who") Core Objective: Design specialized sub-agents tailored for the sub-tasks defined in Stage 1. - Role Profiling: Assign a unique identity and specialized role to each sub-agent based on its target sub-task. - Weighted Constraint Satisfaction Protocol with Partial-Evidence Fallback: Every agent that evaluates or synthesiz...
-
[20]
Workflow & Orchestration Module (The "How") Core Objective: Wire the distinct agents from Stage 2 into a functional, executable Multi-Agent System (MAS). - Architectural Topology: You can design the optimal MAS architecture (e.g., Sequential Pipeline, Router-based, Hierar- chical, or Blackboard) based on Stage 1’s logical dependencies. For complex but imp...
-
[21]
- Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task
Task Decomposition Module (The "What") Core Objective: Analyze the user query and break it down into a logical blueprint. - Intent & Scope Analysis: Understand the macro objective, identify core requirements, and define the boundaries of the task. - Sub-task Breakdown: Decompose the high-level request into a set of discrete, manageable, and logically cohe...
-
[22]
Selector
Agent Engineering Module (The "Who") Core Objective: Design specialized sub-agents tailored for the sub-tasks defined in Stage 1. - Role Profiling: Assign a unique identity and specialized role to each sub-agent based on its target sub-task. - Instruction Design: Draft precise system prompts/instructions. Define the agent’s specific goals, behavioral boun...
-
[23]
Reality Check
Workflow & Orchestration Module (The "How") Core Objective: Wire the distinct agents from Stage 2 into a functional, executable Multi-Agent System (MAS). - Architectural Topology: Design the optimal MAS architecture (e.g., Sequential Pipeline, Router-based, Hierarchical, or Blackboard) based on Stage 1’s logical dependencies. For complex but important sub...
-
[24]
Analyze Each Criterion: Consider how each article fulfills the requirements of each criterion
-
[25]
Comparative Evaluation: Analyze how the two articles perform on each criterion, referencing the content and criterion explanation
-
[26]
Standard 1
Score Separately: Based on your comparative analysis, score each article on each criterion (0-10 points). Scoring Rules For each criterion, score both articles on a scale of 0-10 (continuous values). The score should reflect the quality of performance on that criterion: - 0-2 points: Very poor performance. Almost completely fails to meet the criterion req...
-
[27]
trajectory fails due to poor reasoning
Be specific: Avoid vague statements like "trajectory fails due to poor reasoning". Instead: "trajectory fails at step 5 because it incorrectly assumes X when the constraint requires Y"
-
[28]
Reference specific steps, actions, or outputs
Use evidence: Ground every claim in concrete observations. Reference specific steps, actions, or outputs
-
[29]
The DIFFERENCE is where the insight lies
Think contrastively: Always compare high vs low trajectories. The DIFFERENCE is where the insight lies
-
[30]
task is too hard
Focus on actionability: Every diagnosis should lead to a concrete, implementable fix. Avoid unfixable issues like "task is too hard"
-
[31]
Quantify when possible: Use numbers (frequencies, percentages, counts) to support claims about patterns
-
[32]
Start with { and end with }
Output pure JSON: No markdown code blocks, no extra text. Start with { and end with }. Begin your analysis now. Figure 19: Within-task reflection prompt in Skill-MAS evolution. 28 Skill-MAS Evolution (Cross-Task Reflection) System Prompt You are the diagnosis agent for Skill_MAS Step 2 (Trajectory Reflection Synthesis). Your task is to synthesize cross- s...
-
[33]
High cross-trajectory volatility: Large score variance across rollouts indicates unstable/inconsistent policy behavior
-
[34]
struggles with multi-step reasoning
High intrinsic difficulty: Low average scores suggest systematic capability gaps === INPUT DATA === Phase 1 already analyzed each task’s rollouts. Below, each block contains: (1) the original problem / instruction text, and (2) the COMPLETE Phase-1 structured JSON for that task — every field in the Phase-1 schema (task_id, num_trajectories, score_statisti...
-
[35]
Be specific: Tie weaknesses/strengths to task_ids and concrete themes from the summaries when possible
-
[36]
Use evidence: Ground claims in the Phase-1 structured outputs and task text — do not invent unseen trajectory detail
-
[37]
Think globally: Patterns across samples drive prioritization
-
[38]
Focus on actionability: prioritized_fixes must be implementable in Step 3
-
[39]
Quantify when possible: Use counts where summaries allow
-
[40]
if text contains ’and’, split it
Output pure JSON: No markdown code blocks, no extra text. Start with { and end with }. Begin your synthesis now. Figure 20: Cross-task reflection prompt in Skill-MAS evolution. 29 Skill-MAS Evolution (Skill Optimization) System PromptYou are an expert author and optimizer for Skill-MAS three-stage SKILL.md files. Your task is to improve the current SKILL....
-
[41]
Evidence-Driven Abstraction: Every change must resolve a flaw found in Step2, but the solution MUST be abstracted into a universal systems-engineering principle
-
[42]
Make dependencies clear
Meaningful Depth: Do not just add adjectives. Add new sub-bullet points that introduce a concrete conceptual framework (e.g., instead of "Make dependencies clear", use "Build a Directed Acyclic Graph (DAG) mapping of logic state transitions")
-
[43]
Do not pile on multiple unrelated changes in a single pass
Incremental evolution (hard limit): In this round, introduce at most one substantive conceptual upgrade per SKILL stage section (1, 2, 3 — each stage at most one focused improvement). Do not pile on multiple unrelated changes in a single pass
-
[44]
Format Requirements: - MUST start directly with the Y AML frontmatter (—)
Output Format: Produce ONLY the complete updated SKILL.md. Format Requirements: - MUST start directly with the Y AML frontmatter (—). - MUST preserve the exact same Y AML keys and the exactly three-stage markdown structure (1, 2, 3). - NO markdown code fences around the entire output. - NO preamble, NO explanations, NO summary of changes. Output raw SKILL...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.