SAERec: Constructing Fine-grained Interpretable Intents Priors via Sparse Autoencoders for Recommendation
Pith reviewed 2026-06-26 19:27 UTC · model grok-4.3
The pith
SAERec extracts fine-grained interpretable intent priors from text embeddings via sparse autoencoders to guide user sequence modeling in recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A sparse autoencoder applied to LLM text embeddings disentangles a reusable set of fine-grained interpretable intents; retrieving personal and public subsets of this set as priors and feeding them through multi-branch attention produces user representations that outperform sequence-only baselines while remaining human understandable.
What carries the argument
Sparse autoencoder on LLM text embeddings that isolates intent semantics, followed by retrieval of personal and public intents and injection via multi-branch attention.
If this is right
- The constructed intent library supplies explicit semantic labels that can be shown to users as explanations.
- Personal intents adapt to an individual while public intents capture cross-user patterns without requiring explicit clustering on sequences.
- Multi-branch attention allows the model to weigh temporal sequence signals separately from the static intent priors.
- Because the intent space is built once from the full text corpus it remains stable even when individual user sequences are short or sparse.
Where Pith is reading between the lines
- The same SAE-derived intent space could be reused across different recommendation datasets that share the same item text corpus.
- If the extracted intents prove stable, they might serve as a fixed vocabulary for intent-based explanations in production systems.
- The approach separates the cost of building the intent library (done once on text) from the cost of personalizing per user.
Load-bearing premise
The sparse autoencoder successfully separates genuine user-intent semantics from other textual information in the embeddings.
What would settle it
An ablation that removes the sparse-autoencoder-derived intent priors and retrains the rest of the model shows no drop in ranking metrics on the same datasets.
Figures

read the original abstract
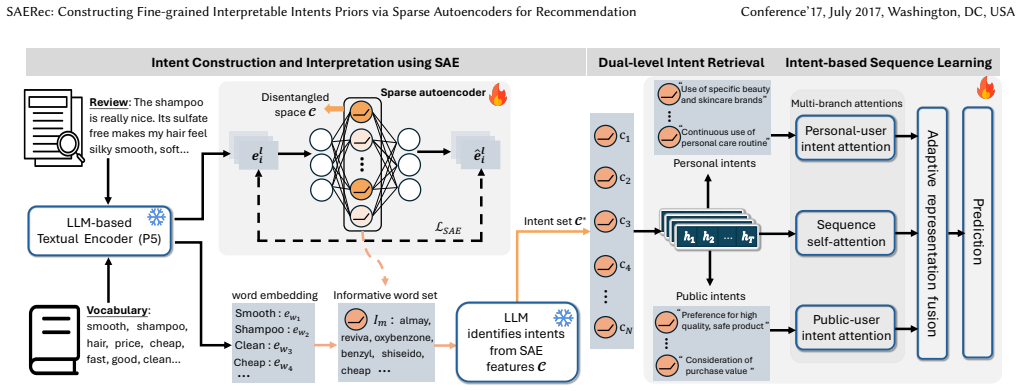
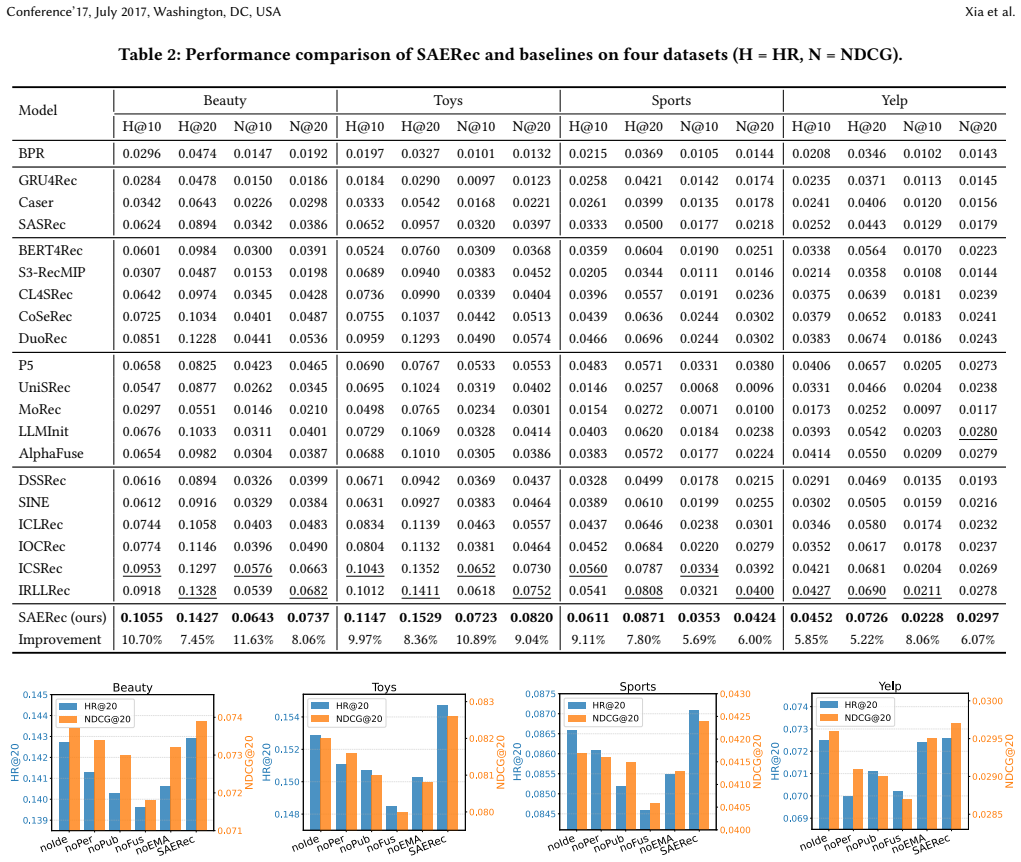
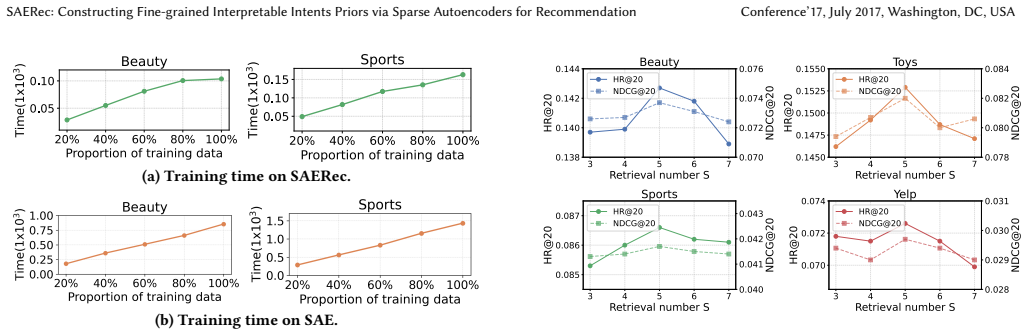
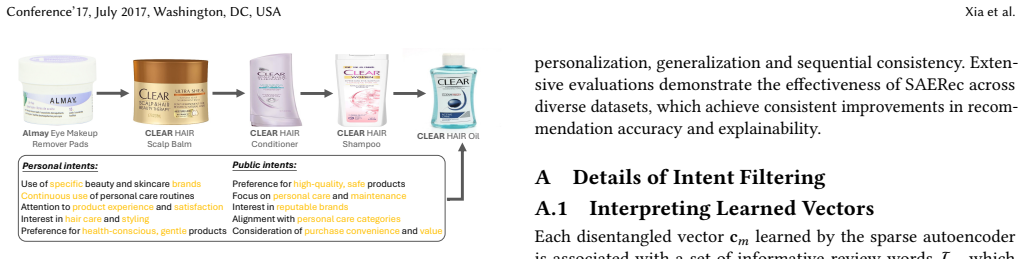
Intent-based recommender systems have gained significant attention for improving accuracy and interpretability by modeling the underlying motivations behind user behaviors. Most existing models derive intents directly from user sequences via clustering or prototype learning. However, they are sensitive to sequence quality, require presetting the number of intents, and lack explicit semantic grounding. These issues lead to an incomplete and coarse intent set and limit the effectiveness of recommendation. In this paper, we propose the Sparse Autoencoder for intent-based recommendation (SAERec), a novel recommender that automatically constructs a fine-grained and interpretable intent space from a textual corpus to guide recommendation. Rather than treating texts as side signals, SAERec leverages them as high information density evidence for intent construction. Specifically, we first extract a comprehensive set of fine-grained interpretable intents from the latent space of large language models (LLMs) by using a sparse autoencoder (SAE) to disentangle and interpret text embeddings, which isolates intent-related semantics from textual noise. Then, for each user, we retrieve relevant intents from this set as priors to guide recommendation. It contains personal intents matching a user's current interests and public intents capturing general item patterns shared across users (e.g., quality, price). Finally, to integrate retrieved intents into sequence modeling, we propose a multi-branch attention mechanism that captures temporal dependencies and injects both personal and public intent signals, followed by an adaptive fusion layer to construct the final user representation for recommendation. Extensive experiments on public datasets demonstrate the superiority of SAERec, consistently outperforming state-of-the-art baselines while providing human-understandable explanations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAERec, which applies a sparse autoencoder (SAE) to LLM text embeddings to automatically extract a fine-grained, interpretable set of intents from a textual corpus. These intents are retrieved per user as personal (user-specific) and public (general) priors, then injected into sequence modeling via a multi-branch attention mechanism and adaptive fusion layer to produce final user representations for recommendation. The central claims are that this addresses limitations of prior intent-based models (sensitivity to sequence quality, need to preset intent count, lack of semantic grounding) and yields consistent outperformance over SOTA baselines on public datasets while enabling human-understandable explanations.
Significance. If the core assumption holds—that the SAE successfully isolates intent semantics and that the retrieved priors causally improve modeling beyond the attention architecture—this could advance intent-based recommendation by providing an automatic, semantically grounded alternative to clustering or prototype methods. The approach of leveraging textual corpora as high-density evidence for intent construction and combining personal/public signals is a clear strength, as is the emphasis on interpretability. However, the absence of quantitative disentanglement validation means the significance remains conditional on further evidence.
major comments (3)
- [Method (SAE construction and intent retrieval)] Method section on SAE application to LLM embeddings: The claim that the SAE 'isolates intent-related semantics from textual noise' is load-bearing for attributing gains to the constructed intent priors rather than the multi-branch attention or fusion layer, yet no quantitative disentanglement metrics (e.g., factor isolation scores, comparison against non-sparse baselines, or ablation on sparsity coefficient) are reported. This directly matches the weakest assumption identified in the stress-test note.
- [Experiments] Experiments section: The abstract asserts 'consistent outperformance' and 'extensive experiments on public datasets,' but the manuscript supplies no dataset names, metric values, error bars, statistical tests, or ablation results isolating the contribution of the SAE-derived intents versus the attention architecture. Without these, the central performance claim cannot be verified and the attribution to intent priors remains untested.
- [Experiments / Qualitative analysis] Interpretability evaluation: The paper states that the approach 'provides human-understandable explanations,' but relies only on qualitative examples; no human evaluation scores, inter-annotator agreement, or comparison to baseline interpretability methods are included to substantiate that the extracted intents are meaningfully finer-grained or more interpretable than alternatives.
minor comments (2)
- [Abstract] The abstract would benefit from naming the public datasets and reporting at least one key metric (e.g., HR@10 or NDCG@10) to allow immediate assessment of the claimed gains.
- [Method] Notation for personal vs. public intent retrieval and the multi-branch attention branches could be clarified with explicit equations or a diagram to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Method (SAE construction and intent retrieval)] Method section on SAE application to LLM embeddings: The claim that the SAE 'isolates intent-related semantics from textual noise' is load-bearing for attributing gains to the constructed intent priors rather than the multi-branch attention or fusion layer, yet no quantitative disentanglement metrics (e.g., factor isolation scores, comparison against non-sparse baselines, or ablation on sparsity coefficient) are reported. This directly matches the weakest assumption identified in the stress-test note.
Authors: We agree that quantitative disentanglement metrics would strengthen attribution of performance gains specifically to the SAE-derived priors. The current manuscript relies on the design of the sparse autoencoder for this isolation but does not report explicit validation metrics. In the revised version we will add factor isolation scores, direct comparisons against non-sparse autoencoder baselines, and ablations on the sparsity coefficient. revision: yes
-
Referee: [Experiments] Experiments section: The abstract asserts 'consistent outperformance' and 'extensive experiments on public datasets,' but the manuscript supplies no dataset names, metric values, error bars, statistical tests, or ablation results isolating the contribution of the SAE-derived intents versus the attention architecture. Without these, the central performance claim cannot be verified and the attribution to intent priors remains untested.
Authors: We acknowledge that the experimental reporting requires greater explicitness and detail to allow verification. While the manuscript contains an experiments section, we will revise it to clearly name the public datasets, report all metric values together with error bars, include statistical significance tests, and add ablations that isolate the SAE intent priors from the multi-branch attention and fusion components. revision: yes
-
Referee: [Experiments / Qualitative analysis] Interpretability evaluation: The paper states that the approach 'provides human-understandable explanations,' but relies only on qualitative examples; no human evaluation scores, inter-annotator agreement, or comparison to baseline interpretability methods are included to substantiate that the extracted intents are meaningfully finer-grained or more interpretable than alternatives.
Authors: We agree that qualitative examples alone do not fully substantiate the interpretability claims. In the revision we will add a human evaluation study reporting quantitative scores and inter-annotator agreement, along with comparisons against baseline interpretability methods such as clustering-based intent extraction. revision: yes
Circularity Check
No circularity detected; derivation relies on external components and experiments
full rationale
The provided abstract and description outline a pipeline: SAE applied to LLM embeddings for intent extraction, intent retrieval as priors, and multi-branch attention for integration. No equations, parameter-fitting steps presented as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work are quoted. Claims of superiority rest on experiments on public datasets rather than reducing to self-definition or fitted inputs by construction. The central assumption about SAE disentanglement is presented as a methodological choice validated externally, not a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- SAE sparsity coefficient
axioms (1)
- domain assumption Text associated with items provides high-information-density evidence for user intents that can be isolated from noise via SAE.
Reference graph
Works this paper leans on
-
[1]
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, and Andrej Risteski. 2018. Linear algebraic structure of word senses, with applications to polysemy.Trans- actions of the Association for Computational Linguistics6 (2018), 483–495
2018
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
Pith/arXiv arXiv 2023
-
[3]
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. 2023. Language models can explain neurons in language models. https://openaipublic.blob.core. windows.net/neuron-explainer/paper/index.html
2023
-
[4]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al
-
[5]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread2 (2023)
2023
-
[6]
Maheep Chaudhary and Atticus Geiger. 2024. Evaluating open-source sparse autoencoders on disentangling factual knowledge in gpt-2 small.arXiv preprint arXiv:2409.04478(2024)
arXiv 2024
-
[7]
Yongjun Chen, Zhiwei Liu, Jia Li, Julian McAuley, and Caiming Xiong. 2022. Intent contrastive learning for sequential recommendation. InProceedings of the ACM web conference 2022. 2172–2182
2022
-
[8]
Jin Yao Chin, Yile Chen, and Gao Cong. 2022. The datasets dilemma: How much do we really know about recommendation datasets?. InProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 141–149
2022
-
[9]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey
-
[10]
arXiv preprint arXiv:2309.08600(2023)
Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600(2023)
Pith/arXiv arXiv 2023
-
[11]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[12]
Kingma Diederik. 2014. Adam: A method for stochastic optimization.(No Title) (2014)
2014
-
[13]
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2024. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093(2024)
Pith/arXiv arXiv 2024
-
[14]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
2022
-
[15]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[16]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
Pith/arXiv arXiv 2015
-
[17]
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards universal sequence representation learning for recommender systems. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 585–593
2022
-
[18]
Guoqing Hu, An Zhang, Shuo Liu, Zhibo Cai, Xun Yang, and Xiang Wang. 2025. Alphafuse: Learn id embeddings for sequential recommendation in null space of language embeddings. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1614–1623
2025
-
[19]
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang, and Jun Zhou. 2024. Enhancing sequential recommendation via llm-based semantic embedding learning. InCompanion Proceedings of the ACM Web Conference 2024. 103–111
2024
-
[20]
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. 2023. Sparse Autoencoders Find Highly Interpretable Features in Lan- guage Models. InThe Twelfth International Conference on Learning Representations (ICLR)
2023
-
[21]
Dietmar Jannach and Zanker. 2024. A survey on intent-aware recommender systems.ACM Transactions on Recommender Systems3, 2 (2024), 1–32
2024
-
[22]
Bo-Jian Jiang, Alexander Wettig, and Tengyu Ma. 2023. Mistral: A Simple and Effective Architecture for Language Modeling.arXiv preprint arXiv:2310.06825 (2023). https://arxiv.org/abs/2310.06825
Pith/arXiv arXiv 2023
-
[23]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[24]
Anton Klenitskiy, Konstantin Polev, Daria Denisova, Alexey Vasilev, et al. 2025. Sparse Autoencoders for Sequential Recommendation Models: Interpretation and Flexible Control.arXiv preprint arXiv:2507.12202(2025)
arXiv 2025
-
[25]
Xuewei Li, Aitong Sun, Mankun Zhao, Jian Yu, Kun Zhu, Di Jin, Mei Yu, and Ruiguo Yu. 2023. Multi-intention oriented contrastive learning for sequential recommendation. InProceedings of the sixteenth ACM international conference on web search and data mining. 411–419
2023
-
[26]
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. 2024. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.arXiv preprint arXiv:2408.05147(2024)
Pith/arXiv arXiv 2024
-
[27]
Ninghao Liu, Yong Ge, Li Li, Xia Hu, Rui Chen, and Soo-Hyun Choi. 2020. Explain- able recommender systems via resolving learning representations. InProceedings of the 29th ACM international conference on information & knowledge management. 895–904
2020
-
[28]
Liu, Matt Gardner, Yonatan Belinkov, Matthew E
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. Linguistic knowledge and transferability of contextual representa- tions. InNAACL
2019
-
[29]
Zhiwei Liu, Yongjun Chen, Jia Li, Philip S Yu, Julian McAuley, and Caiming Xiong. 2021. Contrastive self-supervised sequential recommendation with robust augmentation.arXiv preprint arXiv:2108.06479(2021)
arXiv 2021
-
[30]
Jianxin Ma, Chang Zhou, Hongxia Yang, Peng Cui, Xin Wang, and Wenwu Zhu
-
[31]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Disentangled self-supervision in sequential recommenders. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 483–491
-
[32]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel
-
[33]
InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval
Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
-
[34]
Xiuyuan Qin, Huanhuan Yuan, Pengpeng Zhao, Guanfeng Liu, Fuzhen Zhuang, and Victor S Sheng. 2024. Intent contrastive learning with cross subsequences for sequential recommendation. InProceedings of the 17th ACM international conference on web search and data mining. 548–556
2024
-
[35]
Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive learning for representation degeneration problem in sequential recommendation. InProceedings of the fifteenth ACM international conference on web search and data mining. 813–823
2022
-
[36]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[37]
BPR: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618(2012)
Pith/arXiv arXiv 2012
-
[38]
Adam Scherlis, Kshitij Sachan, Adam S Jermyn, Joe Benton, and Buck Shlegeris
-
[39]
Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892(2022)
arXiv 2022
-
[40]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[41]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[42]
Zhu Sun, Hongyang Liu, Xinghua Qu, Kaidong Feng, Yan Wang, and Yew Soon Ong. 2024. Large language models for intent-driven session recommendations. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 324–334
2024
-
[43]
Qiaoyu Tan, Jianwei Zhang, Jiangchao Yao, Ninghao Liu, Jingren Zhou, Hongxia Yang, and Xia Hu. 2021. Sparse-interest network for sequential recommendation. InProceedings of the 14th ACM international conference on web search and data mining. 598–606
2021
-
[44]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
2018
-
[45]
Antti Tarvainen and Harri Valpola. 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.Advances in neural information processing systems30 (2017)
2017
-
[46]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupati- raju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295(2024)
Pith/arXiv arXiv 2024
-
[47]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. BERT rediscovers the classical NLP pipeline. InACL
2019
-
[48]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
Pith/arXiv arXiv 2023
-
[49]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[50]
Jiayin Wang, Xiaoyu Zhang, Weizhi Ma, Zhiqiang Guo, and Min Zhang. 2024. Interpret the internal states of recommendation model with sparse autoencoder. arXiv preprint arXiv:2411.06112(2024). Conference’17, July 2017, Washington, DC, USA Xia et al
arXiv 2024
-
[51]
Xiang Wang, Tinglin Huang, Dingxian Wang, Yancheng Yuan, Zhenguang Liu, Xiangnan He, and Tat-Seng Chua. 2021. Learning intents behind interactions with knowledge graph for recommendation. InProceedings of the web conference
2021
-
[52]
Yu Wang, Lei Sang, Yi Zhang, and Yiwen Zhang. 2025. Intent representation learning with large language model for recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1870–1879
2025
-
[53]
Xuansheng Wu, Wenhao Yu, Xiaoming Zhai, and Ninghao Liu. 2025. Self- regularization with latent space explanations for controllable llm-based clas- sification.arXiv preprint arXiv:2502.14133(2025)
arXiv 2025
-
[54]
Xuansheng Wu, Jiayi Yuan, Wenlin Yao, Xiaoming Zhai, and Ninghao Liu. 2025. Interpreting and steering llms with mutual information-based explanations on sparse autoencoders.arXiv preprint arXiv:2502.15576(2025)
arXiv 2025
-
[55]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
2022
-
[56]
Jun Yin, Zhengxin Zeng, Mingzheng Li, Hao Yan, Chaozhuo Li, Weihao Han, Jianjin Zhang, Ruochen Liu, Hao Sun, Weiwei Deng, et al. 2025. Unleash LLMs Potential for Sequential Recommendation by Coordinating Dual Dynamic Index Mechanism. InProceedings of the ACM on Web Conference 2025. 216–227
2025
-
[57]
Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to go next for recommender systems? id- vs. modality-based recommender models revisited. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2639–2649
2023
-
[58]
Peiyan Zhang, Jiayan Guo, Chaozhuo Li, Yueqi Xie, Jae Boum Kim, Yan Zhang, Xing Xie, Haohan Wang, and Sunghun Kim. 2023. Efficiently leveraging multi- level user intent for session-based recommendation via atten-mixer network. In Proceedings of the sixteenth ACM international conference on web search and data mining. 168–176
2023
-
[59]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024. Recommender systems in the era of large language models (llms).IEEE Transactions on Knowledge and Data Engineering36, 11 (2024), 6889–6907
2024
-
[60]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-rec: Self-supervised learning for se- quential recommendation with mutual information maximization. InProceedings of the 29th ACM international conference on information & knowledge management. 1893–1902
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.