Who Wins the Conflict? Mechanistic Interpretability of Text Bias in Audio LLMs
Pith reviewed 2026-06-26 19:34 UTC · model grok-4.3
The pith
Text pathways in Audio LLMs actively suppress intact audio representations instead of erasing them when inputs conflict.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
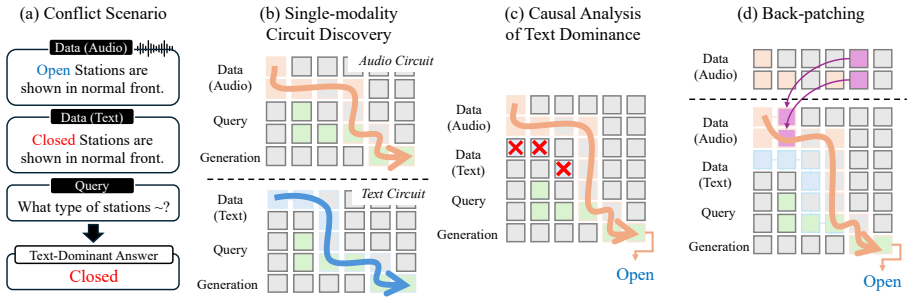
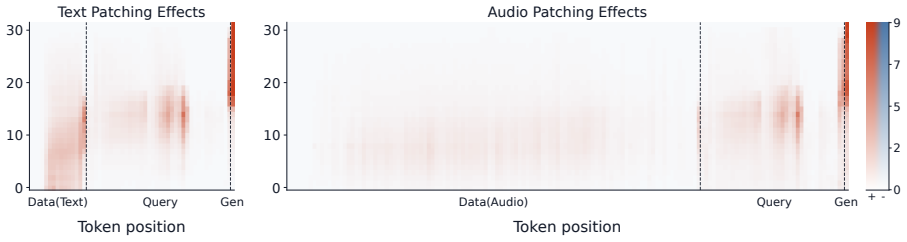
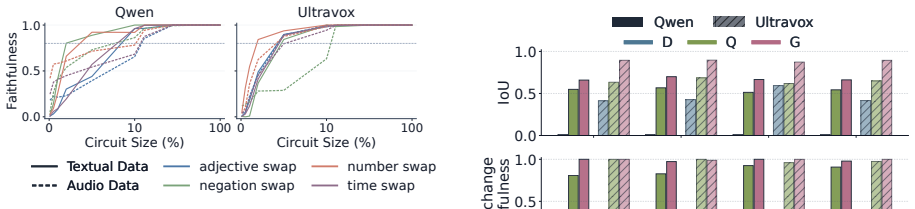
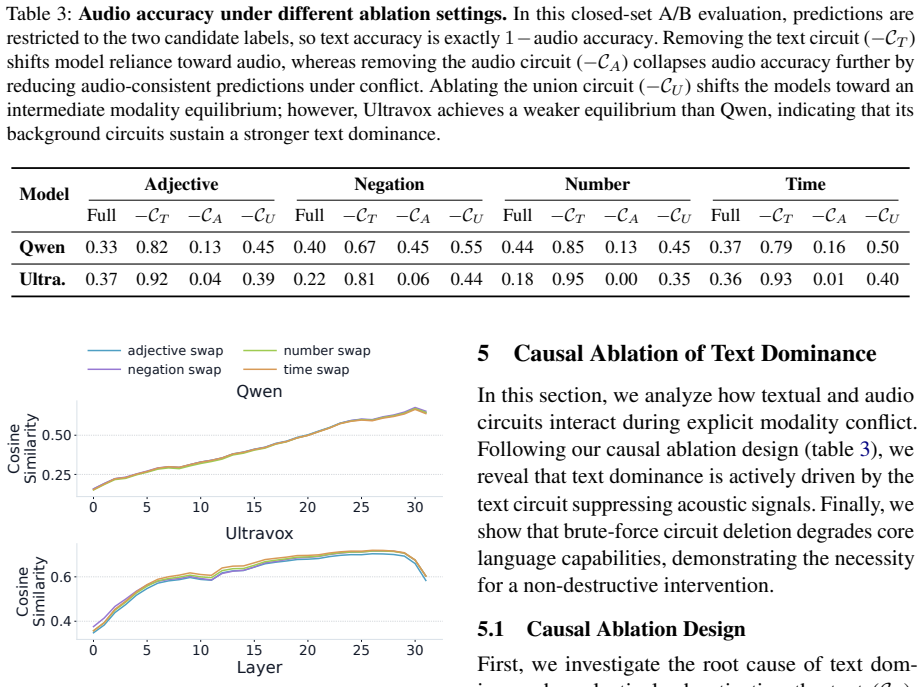
Text dominance is systematic across models. Text and audio use functionally distinct pathways that converge into a shared semantic space in late layers. The text pathway does not erase audio information but actively suppresses intact audio representations. Back-patching routes late-layer audio activations back into earlier layers, amplifying the audio representations so they overcome textual suppression and reduce the bias.
What carries the argument
Back-patching, a training-free intervention that routes late-layer audio activations back into earlier layers to amplify audio representations against textual suppression.
If this is right
- Text dominance appears reliably across different Audio LLMs when audio and text contradict.
- Audio and text inputs travel separate functional pathways until they merge in late layers.
- Back-patching consistently lowers the rate of text dominance on conflicting inputs.
- The approach opens a route to mechanistic multimodal alignment without additional training.
Where Pith is reading between the lines
- The same suppression pattern may appear in other multimodal models that combine language with another modality.
- Back-patching could be tested on real-world inputs where audio evidence directly contradicts text instructions.
- Identifying the exact layers where suppression begins could allow more targeted interventions.
Load-bearing premise
That tracing representation propagation and applying back-patching reveals the causal mechanism of text dominance rather than a side effect of the chosen models and prompts.
What would settle it
A test in which back-patching is applied across multiple conflicting audio-text pairs yet the rate of text dominance stays the same or rises, or in which audio representations are shown to be overwritten before any suppression occurs.
Figures
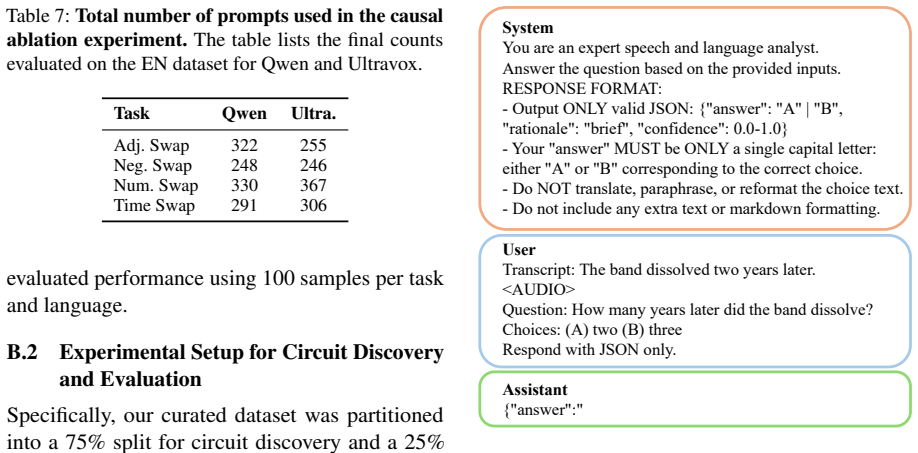
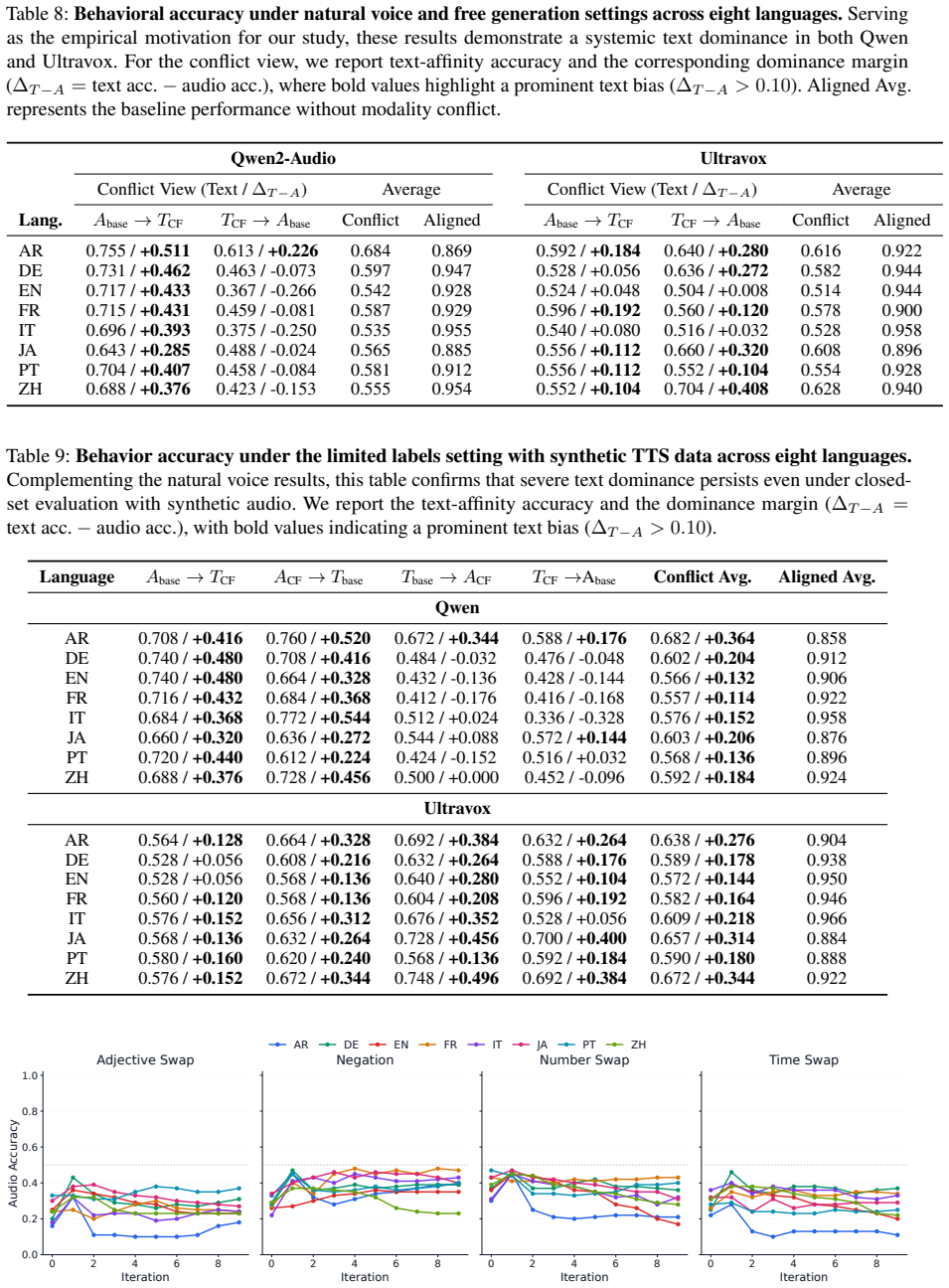
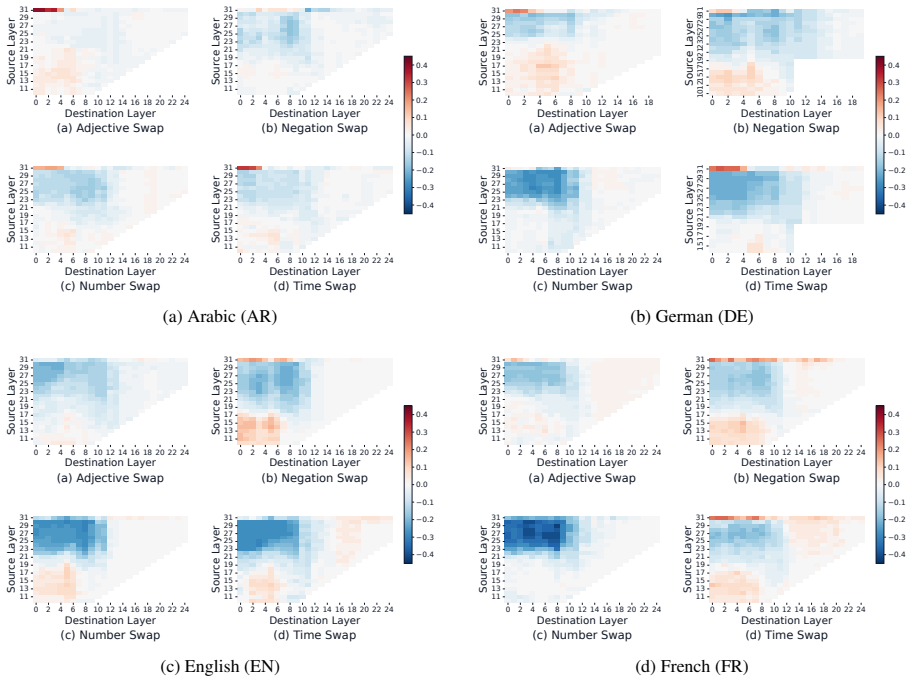
read the original abstract
While Audio Large Language Models (Audio LLMs) excel at multimodal understanding, they suffer from text dominance, a bias where models blindly favor text over acoustic evidence, causing hallucinations. However, the internal mechanisms underlying how these models behave when audio and textual inputs contradict each other remain unexplored. In this work, we present the first mechanistic analysis of this phenomenon by tracing the propagation of internal representations across layers. Our investigation reveals three key findings: (i) text dominance is systematically and empirically across models; (ii) while text and audio rely on functionally distinct pathways, they ultimately converge into a shared semantic space in late layers; and (iii) the text pathway does not erase audio information, but rather actively suppresses intact audio representations. Building on these insights, we leverage back-patching, a training-free intervention that routes late-layer audio activations back into earlier layers. This amplifies the audio representations, enabling them to overcome textual suppression. Our evaluation shows that back-patching consistently reduces text dominance, paving the way for mechanistic multimodal alignment under conflict.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts the first mechanistic interpretability analysis of text dominance in Audio LLMs under conflicting audio-text inputs. By tracing representation propagation across layers, it reports three findings: (i) text dominance is systematic across models, (ii) text and audio pathways are distinct but converge in late-layer semantic space, and (iii) text actively suppresses rather than erases intact audio representations. It introduces back-patching, a training-free intervention routing late-layer audio activations backward to amplify audio signals and overcome suppression, with evaluation claiming consistent bias reduction.
Significance. If the causal claims hold, the work supplies concrete mechanistic evidence for multimodal bias and a simple intervention for mitigation, advancing interpretability beyond correlational observations. The layer-tracing plus intervention approach offers a template for testing suppression hypotheses in other multimodal settings.
major comments (2)
- [Findings (iii) and evaluation of back-patching] Findings (iii) and back-patching evaluation: the claim that audio representations remain intact after text input and are actively suppressed is not directly tested; activation tracing alone does not distinguish suppression from other forms of interference or overwriting, and no measurement (e.g., probe accuracy on audio features post-text) confirms intactness.
- [Evaluation of back-patching] Back-patching results: the reported reduction in text dominance could arise from any early-layer amplification of audio signals rather than specifically countering a suppression mechanism. No control condition (e.g., equivalent-magnitude perturbations to non-suppressive pathways or random activations) is described to isolate the effect.
minor comments (1)
- [Abstract] Abstract: the sentence 'text dominance is systematically and empirically across models' is grammatically incomplete and should be revised for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important gaps in directly testing the suppression claim and in controlling for the specificity of back-patching. We address each point below and commit to revisions that strengthen the evidence without altering the core findings.
read point-by-point responses
-
Referee: [Findings (iii) and evaluation of back-patching] Findings (iii) and back-patching evaluation: the claim that audio representations remain intact after text input and are actively suppressed is not directly tested; activation tracing alone does not distinguish suppression from other forms of interference or overwriting, and no measurement (e.g., probe accuracy on audio features post-text) confirms intactness.
Authors: We agree that layer-wise activation tracing alone provides indirect rather than direct evidence for intact audio representations. Our tracing demonstrates persistence of audio-specific signals into late layers under text conflict, which we interpret as suppression rather than erasure; however, this does not rule out alternative interference mechanisms. In the revised version we will add linear probe experiments measuring audio feature classification accuracy from late-layer activations both with and without conflicting text input. These probes will directly test intactness and help differentiate suppression from overwriting or other forms of interference. revision: yes
-
Referee: [Evaluation of back-patching] Back-patching results: the reported reduction in text dominance could arise from any early-layer amplification of audio signals rather than specifically countering a suppression mechanism. No control condition (e.g., equivalent-magnitude perturbations to non-suppressive pathways or random activations) is described to isolate the effect.
Authors: The back-patching procedure is motivated by our tracing results showing late-layer convergence and selective suppression of audio pathways. Nevertheless, we acknowledge that the current evaluation lacks controls to isolate the mechanism. In revision we will include two control conditions: (1) injecting equivalent-magnitude random noise activations into the same early layers, and (2) applying matched perturbations to non-audio semantic pathways identified in our analysis. These controls will test whether bias reduction is specific to routing intact late-layer audio signals or arises from generic amplification. revision: yes
Circularity Check
No circularity: empirical activation tracing and intervention
full rationale
The paper's core claims rest on tracing internal representations across layers in Audio LLMs to identify three empirical findings about text dominance, followed by a training-free back-patching intervention. No equations, fitted parameters presented as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described chain. The derivation is self-contained via experimental observations rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation tracing and back-patching can identify and alter causal pathways responsible for observed model behavior
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Nikankin, Yaniv and Arad, Dana and Gandelsman, Yossi and Belinkov, Yonatan , booktitle=nips, year=
-
[9]
Transformer feed-forward layers are key-value memories , author=
-
[10]
Arithmetic without algorithms: Language models solve math with a bag of heuristics , author=
-
[11]
Axiomatic attribution for deep networks , author=
-
[12]
Have faith in faithfulness: Going beyond circuit overlap when finding model mechanisms , author=
-
[13]
2022 , url=
Attribution Patching: Activation Patching at Industrial Scale , author=. 2022 , url=
2022
-
[14]
2022 , url =
Nanda, Neel and Bloom, Joseph , title =. 2022 , url =
2022
-
[15]
A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models , author=
-
[16]
Locating and editing factual associations in gpt , author=
-
[17]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=
-
[18]
Towards automated circuit discovery for mechanistic interpretability , author=
-
[19]
Causal analysis of syntactic agreement mechanisms in neural language models , author=
-
[20]
Towards vision-language mechanistic interpretability: A causal tracing tool for blip , author=
-
[21]
What do vlms notice? a mechanistic interpretability pipeline for gaussian-noise-free text-image corruption and evaluation , author=
-
[22]
Behind the Scenes: Mechanistic Interpretability of LoRA-adapted Whisper for Speech Emotion Recognition , author=
-
[23]
arXiv preprint arXiv:2605.12225 , year=
Mechanistic Interpretability of ASR models using Sparse Autoencoders , author=. arXiv preprint arXiv:2605.12225 , year=
-
[24]
arXiv preprint arXiv:2502.17516 , year=
A survey on mechanistic interpretability for multi-modal foundation models , author=. arXiv preprint arXiv:2502.17516 , year=
-
[25]
Probing Cross-modal Information Hubs in Audio-Visual LLMs , author=
-
[26]
arXiv preprint arXiv:2602.11488 , year=
When Audio-LLMs Don't Listen: A Cross-Linguistic Study of Modality Arbitration , author=. arXiv preprint arXiv:2602.11488 , year=
-
[27]
arXiv preprint arXiv:2407.10759 , year=
Qwen2-audio technical report , author=. arXiv preprint arXiv:2407.10759 , year=
-
[28]
2024 , url =
Ultravox: A fast multimodal. 2024 , url =
2024
-
[29]
arXiv preprint arXiv:2508.10552 , year=
When language overrules: Revealing text dominance in multimodal large language models , author=. arXiv preprint arXiv:2508.10552 , year=
-
[30]
Muchomusic: Evaluating music understanding in multimodal audio-language models , author=
-
[31]
What's in the Image? A Deep-Dive into the Vision of Vision Language Models , author=
-
[32]
Hopping too late: Exploring the limitations of large language models on multi-hop queries , author=
-
[33]
Racing thoughts: Explaining contextualization errors in large language models , author=
-
[34]
arXiv preprint arXiv:2603.06854 , year=
Are Audio-Language Models Listening? Audio-Specialist Heads for Adaptive Audio Steering , author=. arXiv preprint arXiv:2603.06854 , year=
-
[35]
AR&D: A Framework for Retrieving and Describing Concepts for Interpreting AudioLLMs , author=
-
[36]
arXiv preprint arXiv:2603.13768 , year=
Causal Tracing of Audio-Text Fusion in Large Audio Language Models , author=. arXiv preprint arXiv:2603.13768 , year=
-
[37]
Gama: A large audio-language model with advanced audio understanding and complex reasoning abilities , author=
-
[38]
Beyond single-audio: Advancing multi-audio processing in audio large language models , author=
-
[39]
Evaluating robustness of large audio language models to audio injection: An empirical study , author=
-
[40]
Soundmind: Rl-incentivized logic reasoning for audio-language models , author=
-
[41]
In-the-wild Audio Spatialization with Flexible Text-guided Localization , author=
-
[42]
Listen, think, and understand , author=
-
[43]
Learning to See through Sound: From VggCaps to Multi2Cap for Richer Automated Audio Captioning , author=
-
[44]
Audio entailment: Assessing deductive reasoning for audio understanding , author=
-
[45]
Can large language models understand spatial audio? , author=
-
[46]
Hurst, Aaron and Lerer, Adam and Goucher, Adam P and Perelman, Adam and Ramesh, Aditya and Clark, Aidan and Ostrow, AJ and Welihinda, Akila and Hayes, Alan and Radford, Alec and others , journal=
-
[47]
arXiv preprint arXiv:2605.16403 , year=
When Vision Speaks for Sound , author=. arXiv preprint arXiv:2605.16403 , year=
-
[48]
arXiv preprint arXiv:2604.16902 , year=
Beyond Text-Dominance: Understanding Modality Preference of Omni-modal Large Language Models , author=. arXiv preprint arXiv:2604.16902 , year=
-
[49]
Avhbench: A cross-modal hallucination benchmark for audio-visual large language models , author=
-
[50]
Chenshuang Zhang, Kyeong Seon Kim, Chengxin Liu and Tae-Hyun Oh , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.