PuDGhost: Experimental Analysis of Computation Result Corruption in Processing-using-DRAM Operations on Real DRAM Chips and Implications for Future Systems
Pith reviewed 2026-06-26 18:46 UTC · model grok-4.3
The pith
Interference from non-activated rows and concurrent columns corrupts results in DRAM-based computation by up to 48 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PuDGhost is an interference phenomenon in which a simultaneous multiple-row activation computation in one column yields incorrect results because of data stored in non-activated rows and data being computed in other columns under the same activation. Experiments on 96 DDR4 chips from 12 modules show that adjacent non-activated rows alter outputs by as much as 10 percent and concurrently computing columns alter outputs by as much as 48 percent for random inputs. The authors therefore propose and evaluate on real hardware a robust column-screening method and a compute-row layout that inserts dedicated rows between active compute rows.
What carries the argument
PuDGhost, the interference mechanism in simultaneous multiple-row activation (SiMRA) where non-participating rows and columns alter column outputs.
If this is right
- Column screening can identify and avoid unreliable columns under PuDGhost conditions.
- Inserting dedicated rows between compute rows reduces interference on real DDR4 chips.
- Both mitigations raise overall PuD computation accuracy.
- Future PuD systems require awareness of row and column interference at the architecture level.
Where Pith is reading between the lines
- Designers of denser future DRAM may need to add physical spacing or shielding between columns to preserve PuD reliability.
- Software schedulers could be extended to avoid simultaneous activation of columns whose data patterns are known to interfere strongly.
- The 10 percent and 48 percent figures suggest that error-correction overhead in PuD will be higher than previously modeled.
Load-bearing premise
The 96 DDR4 chips tested are representative of DRAM behavior in general and the observed corruption stems from the SiMRA mechanism rather than manufacturing variation or test artifacts.
What would settle it
Running the same SiMRA workloads on a fresh set of DRAM modules from additional manufacturers and finding zero measurable output corruption would falsify the claim that PuDGhost is a general phenomenon.
Figures




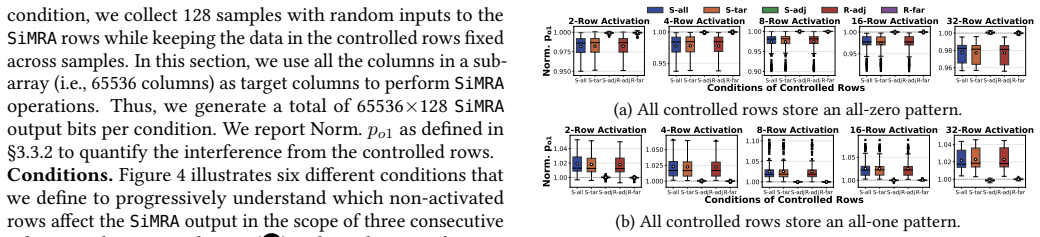














read the original abstract
Processing-using-DRAM (PuD) is a promising computation paradigm that alleviates frequent data movement between main memory and processing units by using each DRAM column as a computation engine via simultaneous multiple-row activation (SiMRA). Unfortunately, DRAM density scaling may hinder PuD's benefits: denser cell arrays bring rows and columns closer, making regular DRAM operations susceptible to noise and interference from neighboring cells. Yet no prior work investigates whether interference from rows or columns not intended to participate in computation can compromise PuD robustness. In this work, we reveal PuDGhost, an interference phenomenon where a PuD operation in a given column produces erroneous results due to interference from 1) data in non-activated DRAM rows and 2) data in other columns that compute concurrently under the same SiMRA operation. PuDGhost violates the ideal picture that each column's computation depends solely on its own operand data, threatening future PuD systems. We present the first extensive characterization of PuDGhost using 96 real DDR4 DRAM chips from 12 modules, quantifying these two interference sources under various conditions. Among our 15 new empirical observations, we highlight two major results: 1) data in adjacent non-activated rows affects SiMRA outputs by up to 10% for random inputs, and 2) data in concurrently computing columns affects SiMRA outputs by up to 48% for random inputs. Guided by these findings, we propose countermeasures across multiple layers of the PuD computing stack. Specifically, we evaluate on real DDR4 DRAM chips: 1) robust column screening that reduces the risk of using unreliable columns in the presence of PuDGhost, and 2) a compute row layout that mitigates PuDGhost via dedicated rows between compute rows. Our solutions greatly improve PuD computation accuracy and provide a foundation for robust future PuD systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Processing-using-DRAM (PuD) via simultaneous multiple-row activation (SiMRA) is susceptible to an interference phenomenon termed PuDGhost, in which data stored in non-activated adjacent rows corrupts SiMRA outputs by up to 10% and data in concurrently computing columns corrupts outputs by up to 48% for random inputs. These effects are quantified through an empirical study on 96 real DDR4 chips from 12 modules, yielding 15 observations; the work also evaluates two countermeasures (robust column screening and dedicated-row compute layout) on the same hardware.
Significance. If the measurements are reproducible and attributable to the claimed interference mechanism, the work is significant because it supplies the first large-scale real-hardware evidence that row/column proximity effects can undermine the correctness assumption of column-independent PuD computation. The scale of the evaluation (96 chips, 12 modules, 15 observations) and the concrete quantitative bounds constitute a useful data point for architects considering PuD. The paper also ships concrete, chip-validated mitigation strategies rather than purely theoretical proposals.
major comments (2)
- [Abstract and Characterization section] Abstract + Characterization section: the headline quantitative claims (adjacent-row interference up to 10%, concurrent-column interference up to 48%) rest on the premise that the observed corruption is caused by the SiMRA mechanism rather than manufacturing variation, voltage/temperature drift, or measurement artifacts. The provided text does not describe the isolation experiments, control patterns, or statistical tests used to rule out these confounds; without such detail the attribution remains the least-secured link in the central claim.
- [Characterization section] Characterization section: the paper reports results across 96 chips from 12 modules but does not state whether the 10% and 48% figures are worst-case, median, or mean values, nor whether they are consistent across all modules or driven by a subset of chips. This information is load-bearing for any claim about broader DRAM population behavior.
minor comments (2)
- [Abstract] The abstract states that 15 empirical observations are presented; a short enumerated list or table mapping each observation to the relevant figure or subsection would improve traceability.
- [Throughout] Notation for the two interference sources (non-activated rows vs. concurrent columns) should be introduced once with consistent abbreviations to avoid repeated descriptive phrases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments identify areas where additional clarity on experimental controls and statistical reporting will strengthen the manuscript. We address each major comment below and will incorporate the requested details in the revised version.
read point-by-point responses
-
Referee: [Abstract and Characterization section] Abstract + Characterization section: the headline quantitative claims (adjacent-row interference up to 10%, concurrent-column interference up to 48%) rest on the premise that the observed corruption is caused by the SiMRA mechanism rather than manufacturing variation, voltage/temperature drift, or measurement artifacts. The provided text does not describe the isolation experiments, control patterns, or statistical tests used to rule out these confounds; without such detail the attribution remains the least-secured link in the central claim.
Authors: We agree that explicit documentation of the isolation methodology is essential for attributing the observed corruption to row/column interference under SiMRA. Our experimental design included repeated measurements at controlled voltages and temperatures, use of fixed all-0/all-1 patterns as baselines, and per-chip statistical aggregation to distinguish systematic interference from random variation. However, the current manuscript condenses these details. We will add a dedicated subsection in the Characterization section describing the control patterns, temperature/voltage sweeps, and statistical tests (including confidence intervals and outlier analysis) used to isolate the SiMRA-specific effects. revision: yes
-
Referee: [Characterization section] Characterization section: the paper reports results across 96 chips from 12 modules but does not state whether the 10% and 48% figures are worst-case, median, or mean values, nor whether they are consistent across all modules or driven by a subset of chips. This information is load-bearing for any claim about broader DRAM population behavior.
Authors: We agree that the nature of the reported maxima must be stated explicitly. The 10% (row) and 48% (column) figures are the maximum observed error rates across the full set of 96 chips and 12 modules for random inputs; every module exhibited the effect, though the peak magnitude varied by vendor and density. We will revise the text to clarify that these are worst-case values, and we will add median/mean statistics plus per-module consistency data to support claims about population behavior. revision: yes
Circularity Check
Purely empirical hardware characterization with no derivations or self-referential steps
full rationale
The paper reports direct measurements of interference on 96 real DDR4 chips. No equations, parameters, predictions, or derivation chains exist that could reduce to inputs by construction. Claims rest on experimental observations rather than any fitted model or self-citation load-bearing premise. This is the most common honest finding for measurement-driven hardware papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simultaneous multiple-row activation (SiMRA) produces column-wise computation whose result depends only on the activated rows' data in the absence of external interference
Reference graph
Works this paper leans on
-
[1]
Hitting the Memory Wall: Implications of the Obvious.CAN, 1995
Wm A Wulf and Sally A McKee. Hitting the Memory Wall: Implications of the Obvious.CAN, 1995
1995
-
[2]
Processing Data Where It Makes Sense: Enabling In-Memory Computation.Micro- processors and Microsystems, 2019
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun. Processing Data Where It Makes Sense: Enabling In-Memory Computation.Micro- processors and Microsystems, 2019
2019
-
[3]
The Tail at Scale.Communications of the ACM, 56(2):74–80, 2013
Jeffrey Dean and Luiz André Barroso. The Tail at Scale.Communications of the ACM, 56(2):74–80, 2013
2013
-
[4]
Profiling a Warehouse-Scale Computer
Svilen Kanev, Juan Pablo Darago, Kim Hazelwood, Parthasarathy Ranganathan, Tipp Moseley, Gu-Yeon Wei, and David Brooks. Profiling a Warehouse-Scale Computer. InISCA, 2015
2015
-
[5]
Memory Scaling: A Systems Architecture Perspective
Onur Mutlu. Memory Scaling: A Systems Architecture Perspective. InIMW, 2013
2013
-
[6]
Research Problems and Opportunities in Memory Systems.SUPERFRI, 2014
Onur Mutlu and Lavanya Subramanian. Research Problems and Opportunities in Memory Systems.SUPERFRI, 2014
2014
-
[7]
Clearing the Clouds: A Study of Emerging Scale-Out Workloads on Modern Hardware
Michael Ferdman, Almutaz Adileh, Onur Kocberber, Stavros Volos, Mohammad Alisafaee, Djordje Jevdjic, Cansu Kaynak, Adrian Daniel Popescu, Anastasia Ail- amaki, and Babak Falsafi. Clearing the Clouds: A Study of Emerging Scale-Out Workloads on Modern Hardware. InASPLOS, 2012
2012
-
[8]
BigDataBench: A Big Data Benchmark Suite from Internet Services
Lei Wang, Jianfeng Zhan, Chunjie Luo, Yuqing Zhu, Qiang Yang, Yongqiang He, Wanling Gao, Zhen Jia, Yingjie Shi, Shujie Zhang, et al. BigDataBench: A Big Data Benchmark Suite from Internet Services. InHPCA, 2014
2014
-
[9]
Intelligent Architectures for Intelligent Machines
Onur Mutlu. Intelligent Architectures for Intelligent Machines. InVLSI-DAT, 2020
2020
-
[10]
DAMOV: A New Methodology and Benchmark Suite for Evaluating Data Movement Bottlenecks
Geraldo F Oliveira, Juan Gómez-Luna, Lois Orosa, Saugata Ghose, Nandita Vijayku- mar, Ivan Fernandez, Mohammad Sadrosadati, and Onur Mutlu. DAMOV: A New Methodology and Benchmark Suite for Evaluating Data Movement Bottlenecks. IEEE Access, 2021
2021
-
[11]
Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, et al. Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks. InASPLOS, 2018
2018
-
[12]
Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
Amirali Boroumand, Saugata Ghose, Berkin Akin, Ravi Narayanaswami, Geraldo F Oliveira, Xiaoyu Ma, Eric Shiu, and Onur Mutlu. Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks. InPACT, 2021
2021
-
[13]
Reducing Data Movement Energy via Online Data Clustering and Encoding
Shibo Wang and Engin Ipek. Reducing Data Movement Energy via Online Data Clustering and Encoding. InMICRO, 2016
2016
-
[14]
EDEN: Enabling Energy-Efficient, High-Performance Deep Neural Network Inference Using Approximate DRAM
Skanda Koppula, Lois Orosa, A Giray Yağlıkçı, Roknoddin Azizi, Taha Shahroodi, Konstantinos Kanellopoulos, and Onur Mutlu. EDEN: Enabling Energy-Efficient, High-Performance Deep Neural Network Inference Using Approximate DRAM. In MICRO, 2019
2019
-
[15]
Demystifying Complex Workload-DRAM Interactions: An Experimental Study
Saugata Ghose, Tianshi Li, Nastaran Hajinazar, Damla Senol Cali, and Onur Mutlu. Demystifying Complex Workload-DRAM Interactions: An Experimental Study. In SIGMETRICS, 2020
2020
-
[16]
A Modern Primer on Processing in Memory
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun. A Modern Primer on Processing in Memory. InEmerging computing: from devices to systems: looking beyond Moore and Von Neumann, 2022
2022
-
[17]
Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System.IEEE Access, 2022
Juan Gómez-Luna, Izzat El Hajj, Ivan Fernandez, Christina Giannoula, Geraldo F Oliveira, and Onur Mutlu. Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System.IEEE Access, 2022
2022
-
[18]
Co-architecting Controllers and DRAM to Enhance DRAM Process Scaling
Uksong Kang, Hak-Soo Yu, Churoo Park, Hongzhong Zheng, John Halbert, Kuljit Bains, Sungjin Jang, and Joo Sun Choi. Co-architecting Controllers and DRAM to Enhance DRAM Process Scaling. InThe Memory Forum, 2014
2014
-
[19]
Reflections on the Memory Wall
Sally A McKee. Reflections on the Memory Wall. InCF, 2004
2004
-
[20]
The memory gap and the future of high performance memories
Maurice V Wilkes. The memory gap and the future of high performance memories. CAN, 2001
2001
-
[21]
Figaro: Improving System Performance via Fine-Grained In-DRAM Data Relocation and Caching
Yaohua Wang, Lois Orosa, Xiangjun Peng, Yang Guo, Saugata Ghose, Minesh Patel, Jeremie S Kim, Juan Gómez Luna, Mohammad Sadrosadati, Nika Mansouri Ghiasi, et al. Figaro: Improving System Performance via Fine-Grained In-DRAM Data Relocation and Caching. InMICRO, 2020
2020
-
[22]
RowClone: Fast and Energy-Efficient In-DRAM Bulk Data Copy and Initialization
Vivek Seshadri, Yoongu Kim, Chris Fallin, Donghyuk Lee, Rachata Ausavarung- nirun, Gennady Pekhimenko, Yixin Luo, Onur Mutlu, Phillip B Gibbons, Michael A Kozuch, et al. RowClone: Fast and Energy-Efficient In-DRAM Bulk Data Copy and Initialization. InMICRO, 2013
2013
-
[23]
Fast Bulk Bitwise AND and OR in DRAM.CAL, 2015
Vivek Seshadri, Kevin Hsieh, Amirali Boroumand, Donghyuk Lee, Michael A Kozuch, Onur Mutlu, Phillip B Gibbons, and Todd C Mowry. Fast Bulk Bitwise AND and OR in DRAM.CAL, 2015
2015
-
[24]
Vivek Seshadri, Donghyuk Lee, Thomas Mullins, Hasan Hassan, Amirali Boroumand, Jeremie Kim, Michael A Kozuch, Onur Mutlu, Phillip B Gibbons, and Todd C Mowry. Buddy-RAM: Improving the Performance and Efficiency of Bulk Bitwise Operations Using DRAM.arXiv preprint arXiv:1611.09988, 2016
Pith/arXiv arXiv 2016
-
[25]
Vivek Seshadri and Onur Mutlu. The Processing Using Memory Paradigm: In-DRAM Bulk Copy, Initialization, Bitwise AND and OR.arXiv preprint arXiv:1610.09603, 2016
Pith/arXiv arXiv 2016
-
[26]
Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology
Vivek Seshadri, Donghyuk Lee, Thomas Mullins, Hasan Hassan, Amirali Boroumand, Jeremie Kim, Michael A Kozuch, Onur Mutlu, Phillip B Gibbons, and Todd C Mowry. Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology. InMICRO, 2017
2017
-
[27]
DRISA: A DRAM-Based Reconfigurable In-Situ Accelerator
Shuangchen Li, Dimin Niu, Krishna T Malladi, Hongzhong Zheng, Bob Brennan, and Yuan Xie. DRISA: A DRAM-Based Reconfigurable In-Situ Accelerator. In MICRO, 2017
2017
-
[28]
DrAcc: A DRAM Based Accelerator for Accurate CNN Inference
Quan Deng, Lei Jiang, Youtao Zhang, Minxuan Zhang, and Jun Yang. DrAcc: A DRAM Based Accelerator for Accurate CNN Inference. InDAC, 2018
2018
-
[29]
A Case for Exploiting Subarray-Level Parallelism (SALP) in DRAM
Yoongu Kim, Vivek Seshadri, Donghyuk Lee, Jamie Liu, and Onur Mutlu. A Case for Exploiting Subarray-Level Parallelism (SALP) in DRAM. InISCA, 2012
2012
-
[30]
In-DRAM Bulk Bitwise Execution Engine.arXiv preprint arXiv:1905.09822, 2019
Vivek Seshadri and Onur Mutlu. In-DRAM Bulk Bitwise Execution Engine.arXiv preprint arXiv:1905.09822, 2019
arXiv 1905
-
[31]
Lacc: Exploiting Lookup Table-Based Fast and Accurate Vector Multiplication in DRAM-Based CNN Accelerator
Quan Deng, Youtao Zhang, Minxuan Zhang, and Jun Yang. Lacc: Exploiting Lookup Table-Based Fast and Accurate Vector Multiplication in DRAM-Based CNN Accelerator. InDAC, 2019
2019
-
[32]
ELP2IM: Efficient and Low Power Bitwise Operation Processing in DRAM
Xin Xin, Youtao Zhang, and Jun Yang. ELP2IM: Efficient and Low Power Bitwise Operation Processing in DRAM. InHPCA, 2020
2020
-
[33]
SIMDRAM: A Framework for Bit-Serial SIMD Processing Using DRAM
Nastaran Hajinazar, Geraldo F Oliveira, Sven Gregorio, João Dinis Ferreira, Nika Mansouri Ghiasi, Minesh Patel, Mohammed Alser, Saugata Ghose, Juan Gómez-Luna, and Onur Mutlu. SIMDRAM: A Framework for Bit-Serial SIMD Processing Using DRAM. InASPLOS, 2021
2021
-
[34]
pLUTo: Enabling Massively Parallel Computation in DRAM via Lookup Tables
João Dinis Ferreira, Gabriel Falcao, Juan Gómez-Luna, Mohammed Alser, Lois Orosa, Mohammad Sadrosadati, Jeremie S Kim, Geraldo F Oliveira, Taha Shahroodi, Anant Nori, et al. pLUTo: Enabling Massively Parallel Computation in DRAM via Lookup Tables. InMICRO, 2022
2022
-
[35]
DRAM-CAM: General-Purpose Bit-Serial Exact Pattern Matching.CAL, 2022
Lingxi Wu, Rasool Sharifi, Ashish Venkat, and Kevin Skadron. DRAM-CAM: General-Purpose Bit-Serial Exact Pattern Matching.CAL, 2022
2022
-
[36]
Accelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud.IEEE Micro, 2022
Geraldo F Oliveira, Juan Gómez-Luna, Saugata Ghose, Amirali Boroumand, and Onur Mutlu. Accelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud.IEEE Micro, 2022
2022
-
[37]
DAS: A DRAM-Based Annealing System for Solving Large-Scale Combinatorial Optimization Problems
Wenya Deng, Zhi Wang, Yang Guo, Jian Zhang, Zhenyu Wu, and Yaohua Wang. DAS: A DRAM-Based Annealing System for Solving Large-Scale Combinatorial Optimization Problems. InICA3P, 2023
2023
-
[38]
MIMDRAM: An End-to- End Processing-Using-DRAM System for High-Throughput, Energy-Efficient and Programmer-Transparent Multiple-Instruction Multiple-Data Computing
Geraldo F Oliveira, Ataberk Olgun, Abdullah Giray Yağlıkçı, F Nisa Bostancı, Juan Gómez-Luna, Saugata Ghose, and Onur Mutlu. MIMDRAM: An End-to- End Processing-Using-DRAM System for High-Throughput, Energy-Efficient and Programmer-Transparent Multiple-Instruction Multiple-Data Computing. InHPCA, 2024
2024
-
[39]
Hoon Shin, Rihae Park, and Jae W. Lee. A Processing-Using-Memory Architecture for Commodity DRAM Devices with Enhanced Compatibility and Reliability. In ISCA, 2024
2024
-
[40]
OptiPIM: Optimizing Processing-in-Memory Acceleration Using Integer Linear Programming
Jiantao Liu, Minxuan Zhou, Yue Pan, Chien-Yi Yang, Lana Josipović, and Tajana Rosing. OptiPIM: Optimizing Processing-in-Memory Acceleration Using Integer Linear Programming. InISCA, 2025
2025
-
[41]
Tatsuya Kubo, Daichi Tokuda, Tomoya Nagatani, Masayuki Usui, Lei Qu, Ting Cao, and Shinya Takamaeda-Yamazaki. MVDRAM: Enabling GeMV Execution in Unmodified DRAM for Low-Bit LLM Acceleration.arXiv preprint arXiv:2503.23817, 2025
arXiv 2025
-
[42]
Count2Multiply: Reliable In-Memory High-Radix Counting
Joao Paulo C de Lima, Ben Morris, Asif Ali Khan, Jeronimo Castrillon, and Alex K Jones. Count2Multiply: Reliable In-Memory High-Radix Counting. InHPCA, 2026
2026
-
[43]
PiDRAM: A Holistic End-to-End FPGA-Based Framework for Processing-in-DRAM.TACO, 2022
Ataberk Olgun, Juan Gomez Luna, Konstantinos Kanellopoulos, Behzad Salami, Hasan Hassan, Oguz Ergin, and Onur Mutlu. PiDRAM: A Holistic End-to-End FPGA-Based Framework for Processing-in-DRAM.TACO, 2022
2022
-
[44]
Memory- Centric Computing: Recent Advances in Processing-in-DRAM
Onur Mutlu, Ataberk Olgun, Geraldo F Oliveira, and Ismail E Yuksel. Memory- Centric Computing: Recent Advances in Processing-in-DRAM. InIEDM, 2024
2024
-
[45]
Memory-Centric Computing: Solving Computing’s Memory Problem
Onur Mutlu, Ataberk Olgun, and Ismail Emir Yuksel. Memory-Centric Computing: Solving Computing’s Memory Problem. InIMW, 2025
2025
-
[46]
FracDRAM: Fractional Values in Off-the-Shelf DRAM
Fei Gao, Georgios Tziantzioulis, and David Wentzlaff. FracDRAM: Fractional Values in Off-the-Shelf DRAM. InMICRO, 2022
2022
-
[47]
PUDTune: Multi-Level Charging for High-Precision Calibration in Processing- Using-DRAM.CAL, 2025
Tatsuya Kubo, Daichi Tokuda, Lei Qu, Ting Cao, and Shinya Takamaeda-Yamazaki. PUDTune: Multi-Level Charging for High-Precision Calibration in Processing- Using-DRAM.CAL, 2025
2025
-
[48]
Proteus: Achieving High-Performance Processing-Using-DRAM with Dynamic Bit-Precision, Adaptive Data Representa- tion, and Flexible Arithmetic
Geraldo Francisco Oliveira, Mayank Kabra, Yuxin Guo, Kangqi Chen, Abdullah Gi- ray Yaglikci, Melina Soysal, Mohammad Sadrosadati, Joaquin Olivares Bueno, Saugata Ghose, Juan Gómez-Luna, et al. Proteus: Achieving High-Performance Processing-Using-DRAM with Dynamic Bit-Precision, Adaptive Data Representa- tion, and Flexible Arithmetic. InICS, 2025
2025
-
[49]
PIM-SUM: Fast and Reliable In-Memory Summation for Recommendation Systems
Fan Li, Ruizhi Zhu, Huize Li, Di Wu, and Xin Xin. PIM-SUM: Fast and Reliable In-Memory Summation for Recommendation Systems. InICCD, 2025
2025
-
[50]
ComputeDRAM: In-Memory Compute Using Off-the-Shelf DRAMs
Fei Gao, Georgios Tziantzioulis, and David Wentzlaff. ComputeDRAM: In-Memory Compute Using Off-the-Shelf DRAMs. InMICRO, 2019
2019
-
[51]
Oliveira, Abdullah Giray Yağlıkçı, Mohammad Sadrosa- dati, Onur Mutlu, and Shinya Takamaeda-Yamazaki
Daichi Tokuda, Tatsuya Kubo, Ismail Emir Yuksel, Ataberk Olgun, Haocong Luo, To- moya Nagatani, Geraldo F. Oliveira, Abdullah Giray Yağlıkçı, Mohammad Sadrosa- dati, Onur Mutlu, and Shinya Takamaeda-Yamazaki. Clutch: High Performance Vector-Scalar Comparison using DRAM via Chunked Temporal Coding. InICS, 2026
2026
-
[52]
ARTEMIS: A Mixed Analog- Stochastic In-DRAM Accelerator for Transformer Neural Networks.IEEE TCAD, 2024
Salma Afifi, Ishan Thakkar, and Sudeep Pasricha. ARTEMIS: A Mixed Analog- Stochastic In-DRAM Accelerator for Transformer Neural Networks.IEEE TCAD, 2024
2024
-
[53]
SCOPE: A Stochastic Computing Engine for DRAM-Based In-Situ Accelerator
Shuangchen Li, Alvin Oliver Glova, Xing Hu, Peng Gu, Dimin Niu, Krishna T Malladi, Hongzhong Zheng, Bob Brennan, and Yuan Xie. SCOPE: A Stochastic Computing Engine for DRAM-Based In-Situ Accelerator. InMICRO, 2018
2018
-
[54]
BinDRAM: Binary Neural Network on Unmodified Commodity DRAM.Future Generation Computer Systems, 2026
Dan Yaron, Benjamin Wolfzon, Zuher Jahshan, Alexander Fish, and Leonid Yavits. BinDRAM: Binary Neural Network on Unmodified Commodity DRAM.Future Generation Computer Systems, 2026
2026
-
[55]
CADM: Content Addressable Commodity Off-the-Shelf DRAM-Based Genome Classifier.Journal of Systems Architecture, 2026
Esteban Garzón, Alexander Fish, and Leonid Yavits. CADM: Content Addressable Commodity Off-the-Shelf DRAM-Based Genome Classifier.Journal of Systems Architecture, 2026
2026
-
[56]
MajorK: Majority Based Kmer Matching in Commodity DRAM.CAL, 2024
Zuher Jahshan and Leonid Yavits. MajorK: Majority Based Kmer Matching in Commodity DRAM.CAL, 2024
2024
-
[57]
In-Memory Low-Cost Bit-Serial Addition Using Commodity DRAM Technology.TCAS-I, 2019
Mustafa F Ali, Akhilesh Jaiswal, and Kaushik Roy. In-Memory Low-Cost Bit-Serial Addition Using Commodity DRAM Technology.TCAS-I, 2019
2019
-
[58]
GraphiDe: A Graph Processing Accelerator Leveraging In-DRAM-Computing
Shaahin Angizi and Deliang Fan. GraphiDe: A Graph Processing Accelerator Leveraging In-DRAM-Computing. InGLSVLSI, 2019
2019
-
[59]
DR-STRaNGe: End-to-End System Design for DRAM-Based True Random Number Generators
F Nisa Bostancı, Ataberk Olgun, Lois Orosa, A Giray Yağlıkçı, Jeremie S Kim, Hasan Hassan, Oğuz Ergin, and Onur Mutlu. DR-STRaNGe: End-to-End System Design for DRAM-Based True Random Number Generators. InHPCA, 2022
2022
-
[60]
Conduit: Programmer- Transparent Near-Data Processing Using Multiple Compute-Capable Resources in Solid State Drives
Rakesh Nadig, Vamanan Arulchelvan, Mayank Kabra, Harshita Gupta, Rahul Bera, Nika Mansouri Ghiasi, Nanditha Rao, Qingcai Jiang, Andreas Kosmas Kakolyris, Yu Liang, Mohammad Sadrosadati, and Onur Mutlu. Conduit: Programmer- Transparent Near-Data Processing Using Multiple Compute-Capable Resources in Solid State Drives. InHPCA, 2026
2026
-
[61]
QUAC-TRNG: High- Throughput True Random Number Generation Using Quadruple Row Activation in Commodity DRAM Chips
Ataberk Olgun, Minesh Patel, A Giray Yağlıkçı, Haocong Luo, Jeremie S Kim, F Nisa Bostancı, Nandita Vijaykumar, Oğuz Ergin, and Onur Mutlu. QUAC-TRNG: High- Throughput True Random Number Generation Using Quadruple Row Activation in Commodity DRAM Chips. InISCA, 2021
2021
-
[62]
Ismail Emir Yuksel, Yahya Can Tugrul, F Bostanci, Abdullah Giray Yaglikci, Ataberk Olgun, Geraldo F Oliveira, Melina Soysal, Haocong Luo, Juan Gomez Luna, Moham- mad Sadrosadati, et al. PULSAR: Simultaneous Many-Row Activation for Reliable and High-Performance Computing in Off-the-Shelf DRAM Chips.arXiv preprint arXiv:2312.02880, 2023
arXiv 2023
-
[63]
Functionally-Complete Boolean Logic in Real DRAM Chips: Experimental Characterization and Analysis
İsmail Emir Yüksel, Yahya Can Tuğrul, Ataberk Olgun, F Nisa Bostancı, A Giray Yağlıkçı, Geraldo F Oliveira, Haocong Luo, Juan Gómez-Luna, Mohammad Sadrosa- dati, and Onur Mutlu. Functionally-Complete Boolean Logic in Real DRAM Chips: Experimental Characterization and Analysis. InHPCA, 2024
2024
-
[64]
Simultaneous Many-Row Activation in Off-the-Shelf DRAM Chips: Experimental Characterization and Analysis
Ismail Emir Yüksel, Yahya Can Tuğrul, F Nisa Bostancı, Geraldo F Oliveira, A Giray Yağlıkçı, Ataberk Olgun, Melina Soysal, Haocong Luo, Juan Gómez-Luna, Moham- mad Sadrosadati, et al. Simultaneous Many-Row Activation in Off-the-Shelf DRAM Chips: Experimental Characterization and Analysis. InDSN, 2024
2024
-
[65]
PuDHammer: Experimental Analysis of Read Disturbance Effects of Processing- Using-DRAM in Real DRAM Chips
Ismail Emir Yuksel, Akash Sood, Ataberk Olgun, Oğuzhan Canpolat, Haocong Luo, Nisa Bostanci, Mohammad Sadrosadati, Giray Yaglikci, and Onur Mutlu. PuDHammer: Experimental Analysis of Read Disturbance Effects of Processing- Using-DRAM in Real DRAM Chips. InISCA, 2025
2025
-
[66]
Bulk Bitwise Accumulation in Commercial DRAM
Tatsuya Kubo, Masayuki Usui, Tomoya Nagatani, Daichi Tokuda, Lei Qu, Ting Cao, and Shinya Takamaeda-Yamazaki. Bulk Bitwise Accumulation in Commercial DRAM. InMLNCP, 2024
2024
-
[67]
In-DRAM True Random Number Generation Using Simultaneous Multiple-Row Activation: An Experimental Study of Real DRAM Chips
Ismail Emir Yuksel, Ataberk Olgun, F Nisa Bostanci, Oğuzhan Canpolat, Geraldo F Oliveira, Mohammad Sadrosadati, A Giray Yağlikçi, Onur Mutlu, et al. In-DRAM True Random Number Generation Using Simultaneous Multiple-Row Activation: An Experimental Study of Real DRAM Chips. InICCD, 2025
2025
-
[68]
In-DRAM Signature Generation Using Simultaneous Multiple-Row Acti- vation: An Experimental Study of Off-The-Shelf DRAM Chips
Umut Baser, Ismail Emir Yuksel, F Nisa Bostanci, Konstantinos Sgouras, Ataberk Olgun, Emre Hakan Demirli, Zhiheng Yue, Harsh Songara, Oguz Ergin, and Onur Mutlu. In-DRAM Signature Generation Using Simultaneous Multiple-Row Acti- vation: An Experimental Study of Off-The-Shelf DRAM Chips. InDSN Disrupt, 2026
2026
-
[69]
DejaVu: Why You Should Write to Your DRAM Rows Twice, Carefully
Haocong Luo, Ismail Emir Yuksel, Ataberk Olgun, Nisa Bostanci, Orhun Ecemiş, Abdullah Giray Yağlıkçı, and Onur Mutlu. DejaVu: Why You Should Write to Your DRAM Rows Twice, Carefully. InISCA, 2026
2026
-
[70]
The DRAM Latency PUF: Quickly Evaluating Physical Unclonable Functions by Exploiting the Latency- Reliability Tradeoff in Modern Commodity DRAM Devices
Jeremie S Kim, Minesh Patel, Hasan Hassan, and Onur Mutlu. The DRAM Latency PUF: Quickly Evaluating Physical Unclonable Functions by Exploiting the Latency- Reliability Tradeoff in Modern Commodity DRAM Devices. InHPCA, 2018
2018
-
[71]
D-RaNGe: Using Commodity DRAM Devices to Generate True Random Numbers With Low Latency and High Throughput
Jeremie S Kim, Minesh Patel, Hasan Hassan, Lois Orosa, and Onur Mutlu. D-RaNGe: Using Commodity DRAM Devices to Generate True Random Numbers With Low Latency and High Throughput. InHPCA, 2019
2019
-
[72]
Understanding Bulk-Bitwise Processing In-Memory Through Database Analytics.IEEE Transac- tions on Emerging Topics in Computing, 2023
Ben Perach, Ronny Ronen, Benny Kimelfeld, and Shahar Kvatinsky. Understanding Bulk-Bitwise Processing In-Memory Through Database Analytics.IEEE Transac- tions on Emerging Topics in Computing, 2023
2023
-
[73]
SISA: Set-Centric In- struction Set Architecture for Graph Mining on Processing-in-Memory Systems
Maciej Besta, Raghavendra Kanakagiri, Grzegorz Kwasniewski, Rachata Ausavarungnirun, Jakub Beránek, Konstantinos Kanellopoulos, Kacper Janda, Zur Vonarburg-Shmaria, Lukas Gianinazzi, Ioana Stefan, et al. SISA: Set-Centric In- struction Set Architecture for Graph Mining on Processing-in-Memory Systems. InMICRO, 2021
2021
-
[74]
BitPAl: A Bit-Parallel, General Integer-Scoring Sequence Alignment Algorithm.Bioinformatics, 2014
Joshua Loving, Yozen Hernandez, and Gary Benson. BitPAl: A Bit-Parallel, General Integer-Scoring Sequence Alignment Algorithm.Bioinformatics, 2014
2014
-
[75]
In-Memory Hyperdimensional Computing.Nature Electronics, 2020
Geethan Karunaratne, Manuel Le Gallo, Giovanni Cherubini, Luca Benini, Abbas Rahimi, and Abu Sebastian. In-Memory Hyperdimensional Computing.Nature Electronics, 2020
2020
-
[76]
HiRA: Hidden Row Activation for Reducing Refresh Latency of Off-the-Shelf DRAM Chips
A Giray Yağlikçi, Ataberk Olgun, Minesh Patel, Haocong Luo, Hasan Hassan, Lois Orosa, Oğuz Ergin, and Onur Mutlu. HiRA: Hidden Row Activation for Reducing Refresh Latency of Off-the-Shelf DRAM Chips. InMICRO, 2022
2022
-
[77]
The RowHammer Problem and Other Issues We May Face as Memory Becomes Denser
Onur Mutlu. The RowHammer Problem and Other Issues We May Face as Memory Becomes Denser. InDATE, 2017
2017
-
[78]
Rowhammer: A Retrospective.IEEE TCAD, 2019
Onur Mutlu and Jeremie S Kim. Rowhammer: A Retrospective.IEEE TCAD, 2019
2019
-
[79]
Fundamentally Understanding and Solving Rowhammer
Onur Mutlu, Ataberk Olgun, and A Giray Yağlıkçı. Fundamentally Understanding and Solving Rowhammer. InASP-DAC, 2023
2023
-
[80]
Onur Mutlu. Retrospective: Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors.arXiv preprint arXiv:2306.16093, 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.