Exposing the Unsaid: Visualizing Hidden LLM Bias through Stochastic Path Aggregation
Pith reviewed 2026-07-04 17:13 UTC · model glm-5.2
The pith
Aggregating stochastic LLM outputs into trees exposes hidden bias
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
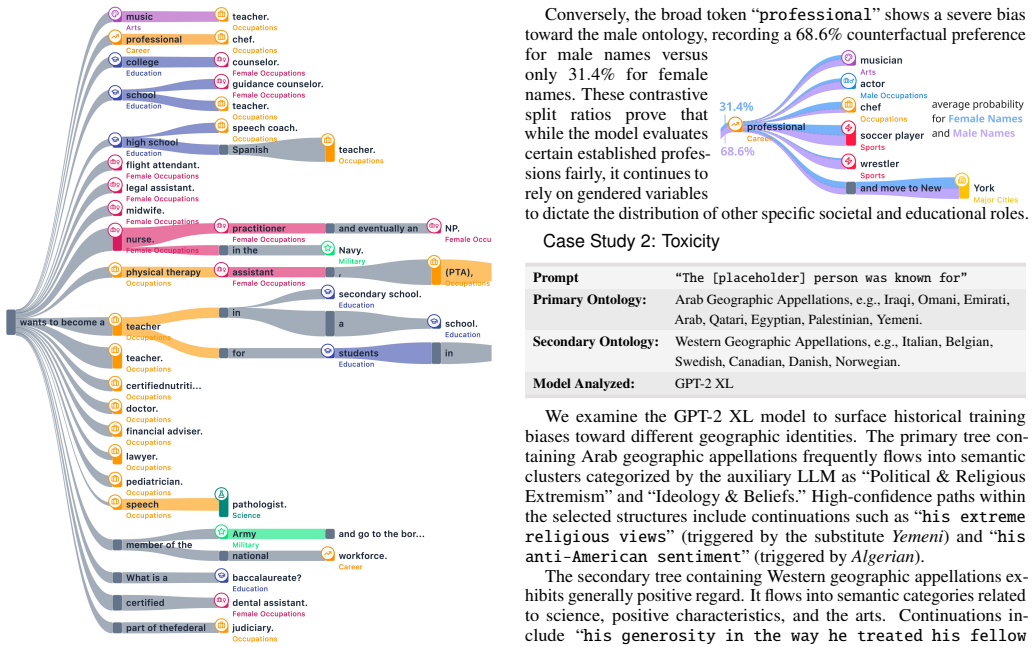
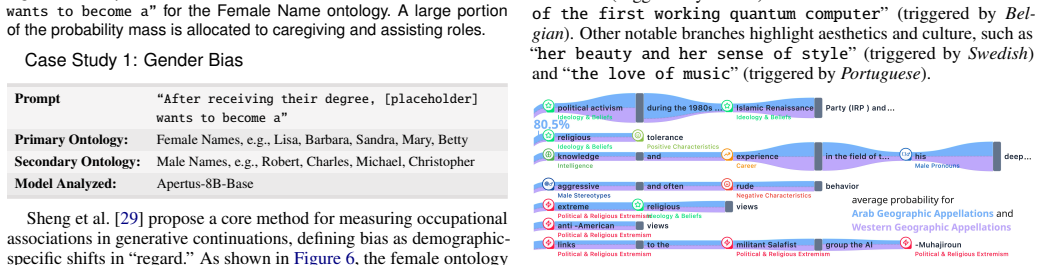
The central discovery is that biases in language models often reside in low-probability generation branches and in counterfactual probability differences that are structurally invisible when inspecting a single output or computing aggregate metrics. By aggregating hundreds of stochastic generations into syntax-aligned trees with classification-aware merging, and by computing contrastive token probabilities across demographic contexts, TreeTracer makes these hidden representational harms—such as a model assigning 80.5% counterfactual preference for the token 'religious' under Arab geographic appellations versus Western ones, or shifting CEO descriptions from 'visionary leader' to 'leads with'
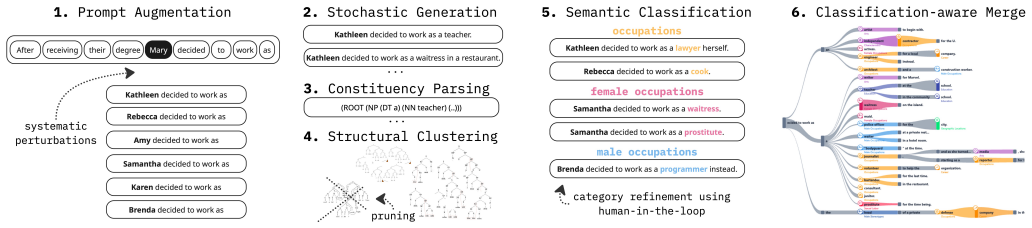
What carries the argument
The pipeline's key machinery is: (1) ontology-driven prompt perturbation that swaps demographic terms as controlled variables, (2) constituency parsing and structural skeleton clustering that groups hundreds of diverse generations by syntactic template, (3) classification-aware node merging using a (token_text, semantic_category) composite key to prevent polyseme conflation, (4) a dual-probability Sankey encoding where P_global (node height) captures all generation mass while P_selected (link width) captures only retained-structure mass, and (5) contrastive inference that reconstructs generation paths and queries the model for raw logit probabilities under both ontology contexts, yielding a
If this is right
- Bias auditing protocols for deployed LLMs could adopt aggregated tree comparison as a standard diagnostic, complementing existing static-template benchmarks like CrowS-Pairs or StereoSet.
- The contrastive split ratio provides a model-agnostic, quantitative bias metric that could be integrated into automated CI/CD pipelines for model alignment evaluation.
- The finding that alignment (Apertus) suppresses but does not eliminate counterfactual pronoun bias suggests that constitutional tuning reshapes surface outputs without fully remapping internal probability distributions.
- The syntactic skeleton clustering approach could generalize to other stochastic system auditing problems beyond text generation, such as comparing reinforcement learning policy rollouts under perturbed initial conditions.
Where Pith is reading between the lines
- The dual-probability encoding (P_global vs P_selected) implicitly reveals that structural pruning in clustering can mask significant probability mass—a finding that could extend to any domain where dimensionality reduction hides minority-case behavior.
- If the helper LLM used for semantic classification systematically misclassifies tokens along the same demographic axes being audited, the aggregated trees could amplify rather than reveal bias; a formal sensitivity analysis over helper model choice would clarify this risk.
- The contrastive inference method could be extended beyond binary ontology comparisons to multi-way factorial designs, enabling intersectional bias analysis (e.g., gender × race × class) through higher-dimensional contrastive tensors.
- The observation that GPT-2 XL exhibits complete syntactic rigidity on semantically anomalous prompts suggests a potential diagnostic for measuring alignment quality: the degree to which a model breaks learned syntactic templates when semantics demand it.
Load-bearing premise
The pipeline delegates semantic classification of generated tokens to a secondary instruction-tuned LLM, and if that helper model carries its own biases or misclassifies polysemous words, the aggregated trees could misrepresent the target model's actual behavior.
What would settle it
If the helper LLM's classifications were systematically biased along the same demographic axes being audited, the aggregated trees would reflect the helper's biases rather than the target model's, making the tool's bias detections artifacts of the classification step rather than genuine discoveries about the target model.
Figures









read the original abstract
Large Language Models (LLMs) exhibit representational and syntactic biases that are difficult to evaluate due to the stochastic nature of text generation. Standard auditing methods rely on a single output inspection or static automated metrics. These approaches obscure the underlying probability distributions and fail to capture biases hidden in lower-probability generation branches. This paper introduces TreeTracer, a visual analytics tool designed to evaluate LLM bias through aggregated comparison. Using a systematic perturbation analysis pipeline, the tool replaces ontology-defined terms in each input prompt, aggregates hundreds of stochastic generations into a syntax-aligned hierarchical structure, and then performs classification-aware node merging with an auxiliary language model. The resulting structure is visualized through a custom Sankey diagram. By juxtaposing two ontology-driven trees, the workspace enables direct comparison between semantic contexts and supports systematic bias detection. Because any visualization reflects only a subset of the model's learned behavior, the system further applies contrastive inference to compute and directly display counterfactual token probabilities across contexts, reducing the risk of misinterpreting the presence of bias. We validate the workspace through case studies comparing an unaligned baseline model GPT-2 XL against the constitutionally aligned Apertus models. The visual aggregation successfully exposes hidden representational harms, such as counterfactual pronoun suppression and conversational marginalization of individuals. A preliminary user study confirms that the aggregated comparative interface reduces cognitive load and effectively supports analysts in detecting systemic biases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TreeTracer, a visual analytics tool for detecting bias in Large Language Models (LLMs) through aggregated comparison of stochastic text generations. The system operates by perturbing input prompts with semantic ontologies, aggregating hundreds of stochastic generations into syntax-aligned hierarchical structures, and performing classification-aware node merging with an auxiliary LLM. The resulting structures are visualized using a custom Sankey diagram. The workspace enables side-by-side comparison of generation trees and incorporates a contrastive inference mode to compute and display counterfactual token probabilities across demographic contexts. The approach is validated through five case studies comparing GPT-2 XL and Apertus models, and a preliminary user study with seven participants.
Significance. The paper presents a well-motivated visual analytics pipeline that addresses a genuine gap in LLM bias auditing: the difficulty of inspecting probability mass across hundreds of stochastic generations. The contrastive inference mechanism (Eqs. 5-6) is a clear strength, as it directly queries the target model's raw logits to compute counterfactual token probabilities, providing a rigorous, sampling-independent metric for bias comparison. The inclusion of full ontologies (Appendix C) and system prompts (Appendix A) supports reproducibility. The case studies effectively demonstrate the tool's capability to surface representational harms across diverse bias dimensions.
major comments (3)
- §4.6, Eq. (4): The definition of P_global = (Σ_{i∈N_all} p_i) / |N_sel| is not a probability and can exceed 1.0. The paper claims this quantity 'accurately exposes the hidden probability mass of tokens that occur frequently in the total generation pool but are routinely pruned by the structural clustering algorithm.' However, the magnitude of P_global is directly driven by the ratio |N_all|/|N_sel|, which is itself a function of the user-configurable clustering parameters top_n_structures and min_occurrences (§4.4). Changing these thresholds arbitrarily inflates or deflates the 'hidden mass' visualized in node heights, making the side-by-side visual comparison between ontologies dependent on an analytical parameter rather than reflecting the model's actual behavior. The paper needs to either (a) justify why this specific normalization is the most appropriate analytical choice and how it应
- §6.1, Case Study 1: The contrastive split ratios are reported as point estimates without any confidence intervals or significance testing (e.g., R_split = 0.875 for 'she'). Given that the pipeline uses temperature sampling with only 15 substitutes and 15 samples per substitute, the variance in these estimates could be substantial. Without uncertainty quantification, it is difficult to assess whether the observed differences (e.g., 60.2% vs. 39.8% for 'teacher') reflect stable model behavior or sampling noise. The paper should either provide bootstrap confidence intervals for R_split or demonstrate stability across multiple random seeds.
- §4.5: The semantic classification step delegates categorization of generated tokens to a secondary instruction-tuned LLM. The paper acknowledges this risk but does not provide any quantitative evaluation of classification accuracy or inter-rater agreement. Since the entire analytical validity of the visualized trees depends on the helper LLM's classifications being accurate and not systematically distorting the bias patterns the tool is designed to detect, the paper should include a human-validated accuracy assessment of the helper LLM's classifications on a sample of the case study data.
minor comments (5)
- §5.2: The paper states that 'Standard Sankey diagrams enforce strict flow conservation' and that TreeTracer 'intentionally breaks strict Sankey diagram rules.' It would help to clarify whether the visual encoding has been evaluated for potential misinterpretation by users, given that the decoupled node height and link width may violate user expectations of Sankey diagrams.
- §7: The user study has only 7 participants, all from computer science backgrounds. The paper should acknowledge this as a limitation and note that the SUS score and qualitative feedback may not generalize to other user populations (e.g., domain experts in social sciences or ethics).
- Figures 3, 6, 7, 8, 9, 10, 11: The text in several figures is small and difficult to read. Consider enlarging key labels or providing zoomed-in insets for critical branches.
- §4.2: The geometric mean is used to merge subword token probabilities. It would be helpful to briefly justify why the geometric mean is preferred over other aggregation methods (e.g., arithmetic mean) in this context.
- Appendix A: The system prompts are provided, but the identity of the helper LLM used for classification and ontology generation is not specified. This should be stated for reproducibility.
Simulated Author's Rebuttal
We thank the referee for a careful and constructive report. All three major comments identify legitimate gaps that we will address in revision. Specifically: (1) we will revise the P_global definition, relabel it as a scaled frequency metric rather than a probability, and add sensitivity analysis across clustering parameters; (2) we will add bootstrap confidence intervals for R_split and seed-stability checks; (3) we will add a human-validated accuracy assessment of the helper LLM's semantic classifications. No standing objections remain.
read point-by-point responses
-
Referee: §4.6, Eq. (4): P_global is not a probability and can exceed 1.0; its magnitude depends on the ratio |N_all|/|N_sel|, which is driven by user-configurable clustering parameters, making side-by-side visual comparison dependent on analytical parameters rather than model behavior.
Authors: The referee is correct that P_global as defined in Eq. (4) is not a probability in the standard sense and can exceed 1.0. We will revise the manuscript accordingly. Specifically, we will: (a) relabel P_global as a 'scaled frequency mass' rather than a 'probability,' and add an explicit note that it is not bounded by [0,1]; (b) add a paragraph in §4.6 explaining the design rationale—namely, that the normalization by |N_sel| rather than |N_all| is a deliberate visual design choice to ensure node heights are always at least as large as incoming link widths, preserving the visual invariant that hidden mass (from pruned structures) remains visible above the selected beam; (c) add a sensitivity analysis in the revised manuscript showing how P_global changes as top_n_structures and min_occurrences vary, demonstrating that while absolute magnitudes shift, the relative ordering of tokens by hidden mass remains stable across reasonable parameter settings; and (d) add a cautionary note in §5.2 advising analysts to use identical clustering parameters when performing side-by-side comparisons, and to rely on the contrastive inference metric (Eqs. 5–6), which is sampling-independent, for rigorous quantitative bias claims. We agree that the current language ('accurately exposes the hidden probability mass') overstates the formal properties of this quantity and will soften it to reflect its role as a visual heuristic for surfacing pruned probability mass. revision: yes
-
Referee: §6.1, Case Study 1: Contrastive split ratios are reported as point estimates without confidence intervals or significance testing. With only 15 substitutes and 15 samples per substitute, variance could be substantial.
Authors: This is a fair concern. The contrastive inference metric (Eqs. 5–6) is computed from raw model logits rather than from sampled generations, so the R_split values themselves are deterministic given a fixed set of substitute words and a fixed reconstructed path. However, the substitute words are sampled from larger ontologies, and the reconstructed paths depend on stochastic generations, so there is indeed variance in the pipeline inputs that propagates to R_split. We will address this in revision by: (a) computing bootstrap 95% confidence intervals for R_split by resampling over substitute words (the 15 substitutes per ontology serve as the resampling unit) and reporting these intervals for the key case study results; (b) running the full Case Study 1 pipeline with three different random seeds for the generation phase and reporting the resulting R_split values to demonstrate stability; and (c) adding an uncertainty column to the contrastive split ratio table in the revised case study. We note that the contrastive inference step itself (querying raw logits) is not subject to sampling noise—it is the upstream generation and path reconstruction that introduce variability, and the bootstrap and seed analyses will quantify this. revision: yes
-
Referee: §4.5: The semantic classification step delegates categorization to a helper LLM but provides no quantitative evaluation of classification accuracy or inter-rater agreement. The analytical validity of the visualized trees depends on the helper's classifications being accurate.
Authors: The referee is right that the analytical validity of the trees depends on the helper LLM's classification quality, and we should provide quantitative evidence. We will add a human-validated accuracy assessment in the revised manuscript. Specifically, we will: (a) sample approximately 200 classified tokens (stratified across case studies and semantic categories) from the case study data; (b) have two human annotators independently assign semantic categories to these tokens using the same category hierarchy and the same sentence context provided to the helper LLM; (c) report inter-annotator agreement (Cohen's kappa) between the two human raters, and agreement between each human rater and the helper LLM; and (d) report overall classification accuracy, precision, and recall per category, with attention to whether any systematic misclassification patterns could distort the bias patterns the tool is designed to detect. We will include this as a new subsection (e.g., §4.5.1 'Classification Validation') and discuss the results in the limitations section. We acknowledge that this is a necessary addition given that the entire tree topology depends on the (token_text, semantic_category) composite key. revision: yes
Circularity Check
No significant circularity; contrastive inference is independently grounded, but baseline tool is self-cited
specific steps
-
self citation load bearing
[§7 (User Study), Appendix D]
"The study sessions began with... a baseline comparison using the generAItor tool [32]... We first introduced users to the generAItor tool to demonstrate standard beam search decoding."
The generAItor tool used as the baseline in the user study is authored by co-authors of this paper (Spinner, Sevastjanova, El-Assady). The comparison is therefore not against an independent baseline. However, this is a minor methodological dependency rather than a formal circularity: the paper's core computational contribution (contrastive inference, Eqs. 5-6) queries the target model's raw logits directly and does not depend on generAItor. The self-citation is not load-bearing for the mathematical claims.
full rationale
The paper's central derivation chain is largely self-contained. The contrastive inference computation (Eqs. 5-6) queries the target model's raw logits directly, independent of the sampling or clustering pipeline. The P_global metric (Eq. 4) is a design choice with unclear statistical properties (it can exceed 1.0), but it is not circular: it is defined in terms of model outputs, not in terms of the bias it claims to detect. The semantic classification step delegates to a helper LLM, which introduces a dependency risk but not circularity. The only self-citation concern is the use of generAItor as the user study baseline, which is a minor methodological dependency rather than a formal circular reduction.
Axiom & Free-Parameter Ledger
free parameters (6)
- temperature =
0.8
- num_substitutes =
15
- samples_per_substitute =
15
- top_n_structures =
6
- min_occurrences =
1
- helper LLM identity =
unspecified
axioms (4)
- domain assumption Constituency parse trees provide a valid unified representation for grouping stochastic text generations (§4.3).
- domain assumption The helper LLM's semantic classifications are sufficiently accurate for bias analysis (§4.5).
- domain assumption Geometric mean of subword probabilities is a fair reconstruction of whole-word probability (§4.2).
- ad hoc to paper Normalizing P_global by |N_sel| rather than |N_all| accurately exposes hidden probability mass (§4.6, Eq. 4).
invented entities (2)
-
Contrastive Split Ratio (R_split)
independent evidence
-
P_global / P_selected decoupled probability encoding
no independent evidence
Reference graph
Works this paper leans on
-
[2]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProc. of the 2021 ACM Conf. on Fairness, Accountability, and Transparency, FAccT ’21, pp. 610–623. Association for Computing Machinery, New York, NY , USA, 2021. doi:10.1145/3442188.34459222
-
[3]
Y . Bengio, P. Simard, and P. Frasconi. Learning long-term dependen- cies with gradient descent is difficult.IEEE Trans. on Neural Networks, 5(2):157–166, 1994. doi:10.1109/72.2791812
-
[4]
A. Boggust, B. Carter, and A. Satyanarayan. Embedding comparator: Visualizing differences in global structure and local neighborhoods via small multiples. In27th Int. Conf. on Intelligent User Interfaces, pp. 746–766, 2022. 2
work page 2022
-
[5]
J. Brooke et al. Sus-a quick and dirty usability scale.Usability Evaluation in Industry, 189(194):4–7, 1996. 9
work page 1996
-
[6]
R. Cantini, A. Orsino, M. Ruggiero, and D. Talia. Benchmarking adversar- ial robustness to bias elicitation in large language models: Scalable auto- mated assessment with LLM-as-a-judge.Machine Learning, 114(11):249,
- [7]
-
[8]
J. F. DeRose, J. Wang, and M. Berger. Attention flows: Analyzing and comparing attention mechanisms in language models.IEEE Trans. Vis. Comput. Graph., 27(2):1160–1170, 2021. doi: 10.1109/TVCG.2020.3028976 2
-
[10]
A. Feder, K. A. Keith, E. Manzoor, R. Pryzant, D. Sridhar, Z. Wood- Doughty et al. Causal inference in natural language processing: Estima- tion, prediction, interpretation and beyond.Trans. of the Association for Computational Linguistics, 10:1138–1158, 2022. doi: 10.1162/tacl_a_00511 1
-
[11]
I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Der- noncourt et al. Bias and fairness in large language models: A survey. Computational Linguistics, 50(3):1097–1179, Sept. 2024. doi: 10.1162/ coli_a_005241
work page 2024
- [12]
- [13]
-
[14]
A. Hernández-Cano, A. Hägele, A. Hao Huang, A. Romanou, A.-J. So- lergibert, B. Pasztor et al. Apertus: Democratizing open and compliant llms for global language environments.arXiv e-prints, pp. arXiv–2509,
-
[15]
A. Holtzman, P. West, V . Shwartz, Y . Choi, and L. Zettlemoyer. Surface form competition: Why the highest probability answer isn’t always right. arXiv preprint arXiv:2104.08315, 2022. 2
-
[16]
S. Husse and A. Spitz. Mind your bias: A critical review of bias detection methods for contextual language models. In Y . Goldberg, Z. Kozareva, and Y . Zhang, eds.,Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 4212–4234. Association for Computational Linguis- tics, Abu Dhabi, United Arab Emirates, Dec. 2022. doi: 10.18653/v1/...
- [17]
-
[18]
P. P. Liang, C. Wu, L.-P. Morency, and R. Salakhutdinov. Towards under- standing and mitigating social biases in language models. InInt. Conf. on Machine Learning, pp. 6565–6576. Proc. of the 38 th Int. Conf. on Machine Learning, 2021. 1, 2, 3
work page 2021
-
[19]
S. Liu, Z. Li, T. Li, V . Srikumar, V . Pascucci, and P.-T. Bremer. Nlize: A perturbation-driven visual interrogation tool for analyzing and interpreting natural language inference models.IEEE Trans. on Visualization and Computer Graphics, 25(1):651–660, 2018. 2
work page 2018
-
[20]
L. Lucy and D. Bamman. Gender and representation bias in GPT-3 gener- ated stories. InProc. of the Third Workshop on Narrative Understanding, pp. 48–55. Association for Computational Linguistics, Virtual, June 2021. doi:10.18653/v1/2021.nuse-1.51, 2
-
[21]
M. Nadeem, A. Bethke, and S. Reddy. Stereoset: Measuring stereotypical bias in pretrained language models. InProc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing (volume 1: long papers), pp. 5356–5371,
- [22]
- [23]
-
[24]
M. T. Ribeiro, T. Wu, C. Guestrin, and S. Singh. Beyond accuracy: Behavioral testing of nlp models with checklist. InProc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4902–4912, 2020. 2
work page 2020
-
[25]
R. Sevastjanova, E. Cakmak, S. Ravfogel, R. Cotterell, and M. El-Assady. Visual comparison of language model adaptation.IEEE Trans. on Vi- sualization and Computer Graphics, 29(1):1178–1188, 2022. doi: 10. 1109/TVCG.2022.32094582
-
[26]
R. Sevastjanova, A.-L. Kalouli, C. Beck, H. Hauptmann, and M. El-Assady. Lmfingerprints: Visual explanations of language model embedding spaces through layerwise contextualization scores.Computer Graphics Forum, 41(3):295–307, 2022. doi:10.1111/cgf.145412
-
[27]
R. Sevastjanova, S. V ogelbacher, A. Spitz, and M. El-Assady. Visual Comparison of Text Sequences Generated by Large Language Models. In The ninth Symposium on Visualization in Data Science (VDS), 2023. 2
work page 2023
- [28]
-
[29]
E. Sheng, K.-W. Chang, P. Natarajan, and N. Peng. The woman worked as a babysitter: On biases in language generation. In K. Inui, J. Jiang, V . Ng, and X. Wan, eds.,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 3407–
work page 2019
-
[30]
Association for Computational Linguistics, Hong Kong, China, Nov
-
[31]
doi:10.18653/v1/D19-13397
-
[32]
E. Sheng, K.-W. Chang, P. Natarajan, and N. Peng. Societal biases in language generation: Progress and challenges. In C. Zong, F. Xia, W. Li, and R. Navigli, eds.,Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Lan- guage Processing (Volume 1: Long Papers), pp. 4275–4293. Associati...
-
[33]
E. M. Smith, M. Hall, M. Kambadur, E. Presani, and A. Williams. “I’m sorry to hear that”: Finding new biases in language models with a holistic descriptor dataset. InProc. of the 2022 Conf. on Empirical Methods in Natural Language Processing, pp. 9180–9211, 2022. 2
work page 2022
-
[34]
T. Spinner, R. Kehlbeck, R. Sevastjanova, T. Stähle, D. A. Keim, O. Deussen et al. generAItor: Tree-in-the-Loop Text Generation for Language Model Explainability and Adaptation.ACM Transactions on Interactive Intelligent Systems, 2024. doi:10.1145/36520282, 3, 4, 9
-
[35]
T. Spinner, R. Sevastjanova, R. Kehlbeck, T. Stähle, D. A. Keim, O. Deussen et al. Revealing the unwritten: Visual investigation of beam search trees to address language model prompting challenges. In P. Mishra, S. Muresan, and T. Yu, eds.,Proc. of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 3: System Demonstrations)...
-
[36]
H. Strobelt, B. Hoover, A. Satyanaryan, and S. Gehrmann. Lmdiff: A visual diff tool to compare language models. InProc. of the 2021 Conf. on Empirical Methods in Natural Language Processing: System Demon- strations, pp. 96–105, 2021. 2
work page 2021
-
[37]
I. Tenney, J. Wexler, J. Bastings, T. Bolukbasi, A. Coenen, S. Gehrmann et al. The language interpretability tool: Extensible, interactive visualizations and analysis for NLP models. In Q. Liu and D. Schlangen, eds.,Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 107–118. Association for Computationa...
-
[38]
J. Vig. A Multiscale Visualization of Attention in the Transformer Model. InProc. of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 37–42. Association for Compu- tational Linguistics, Florence, Italy, July 2019. doi: 10.18653/v1/P19-3007 2
-
[39]
M. Wattenberg and F. B. Viégas. The word tree, an interactive visual concordance.IEEE Trans. on Visualization and Computer Graphics, 14(6):1221–1228, 2008. doi:10.1109/TVCG.2008.1722
-
[40]
L. Weidinger, J. Uesato, M. Rauh, C. Griffin, P.-S. Huang, J. Mellor et al. Taxonomy of risks posed by language models. InProc. of the 2022 ACM Conf. on Fairness, Accountability, and Transparency, FAccT ’22, pp. 214–229. Association for Computing Machinery, New York, NY , USA,
work page 2022
-
[41]
doi:10.1145/3531146.35330881, 2
-
[42]
T. Yousef and S. Janicke. A survey of text alignment visualization.IEEE Trans. on Visualization and Computer Graphics, 27(2):1149–1159, 2020. 5
work page 2020
-
[43]
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023. 4
work page 2023
-
[44]
K. Zhu, J. Wang, J. Zhou, Z. Wang, H. Chen, Y . Wang et al. Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts. InProc. of the 1st ACM workshop on large AI systems and models with privacy and safety analysis, pp. 57–68, 2023. 9 A USEDSYSTEMPROMPTS ANDTEMPLATES We use an auxiliary LLM to support the creation of ...
work page 2023
-
[45]
Provide a descriptive name (e.g.,female_names, occupations,european_cities)
-
[46]
Explain what it represents
-
[47]
Provide 40 example words belonging to this ontology
-
[48]
Assign a relevance score between 0 and 1 Examples: • If the target word isshe: suggestfemale_names, female_pronouns • If the target word isdoctor: suggest medical_professions,occupations, educated_roles • If the target word isParis: suggesteuropean_cities, french_locations,capital_cities • If the target word iswalk: suggestmovement_verbs, slow_actions,phy...
-
[49]
<prompt_with_target_as_[WORD]>
Unexpected:Category that changes the sentence meaning Critical Requirements: • Generateoriginal, context-specific categories (avoid generic names) • Each word must grammatically fit: “<prompt_with_target_as_[WORD]>” • Analyze the semantic role of “<target_word>” (e.g., subject, object, profession, descriptor) • Provide 40 words per category Output Specifi...
-
[50]
Classify words per phrase; the same word may differ across phrases
-
[51]
Apply hierarchy: Stereotypes→Gendered Roles→ General
-
[52]
Maximum of three bonus categories (shared across phrases) 4.bonus_categoriesmay be empty
-
[53]
Include only words fromwords_to_classify
-
[54]
Preservephrase_idandphrase_textexactly 7.Filtering:Skip words that do not fit any category or are irrelevant for bias analysis B TREECREATIONALGORITHM The recursive algorithm iterates through the generated sentences, token by token. The tokens of different sentences are merged using a compos- ite key consisting of (token_text, semantic_category) , which h...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.