Where to Place the Query? Unveiling and Mitigating Positional Bias in In-Context Learning for Diffusion LLMs via Decoding Dynamics
Pith reviewed 2026-07-01 09:05 UTC · model grok-4.3
The pith
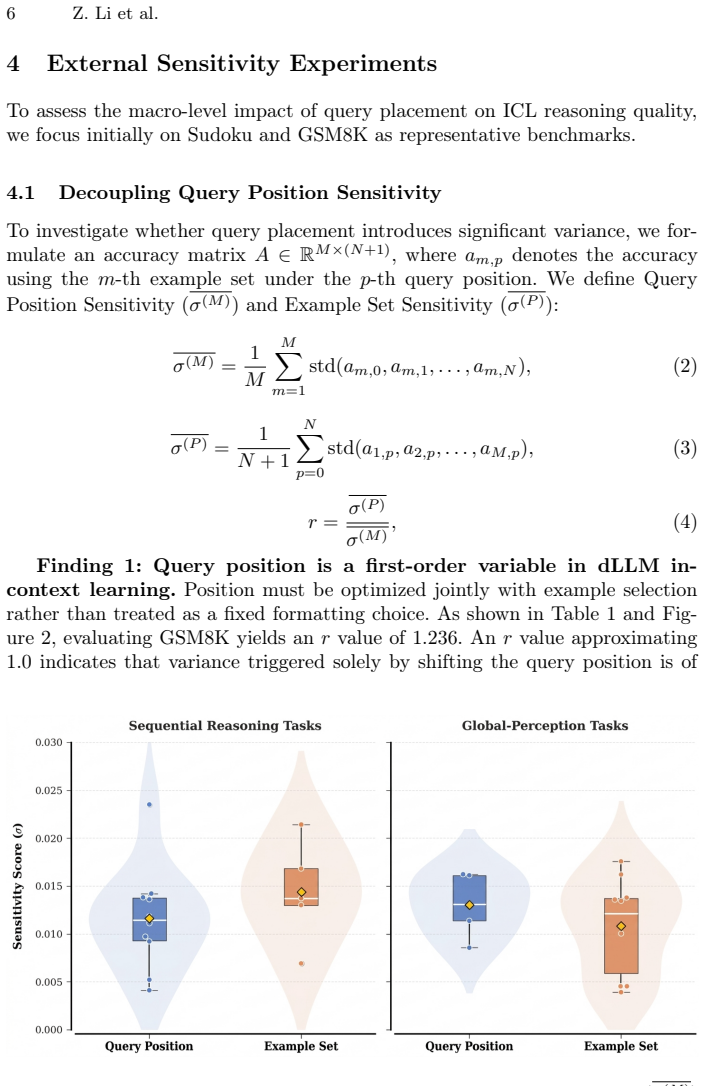
Query position is a first-order variable in diffusion LLMs that affects in-context learning quality on par with example semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
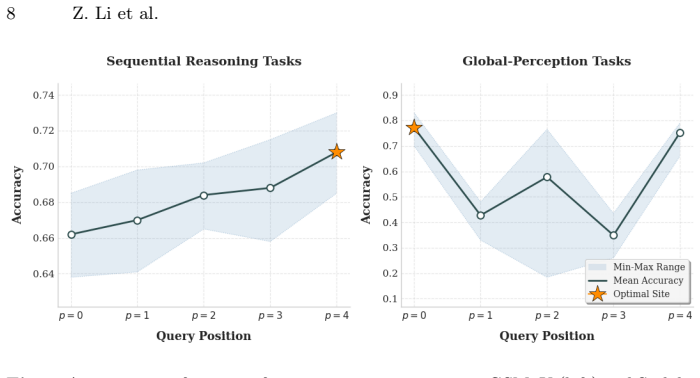
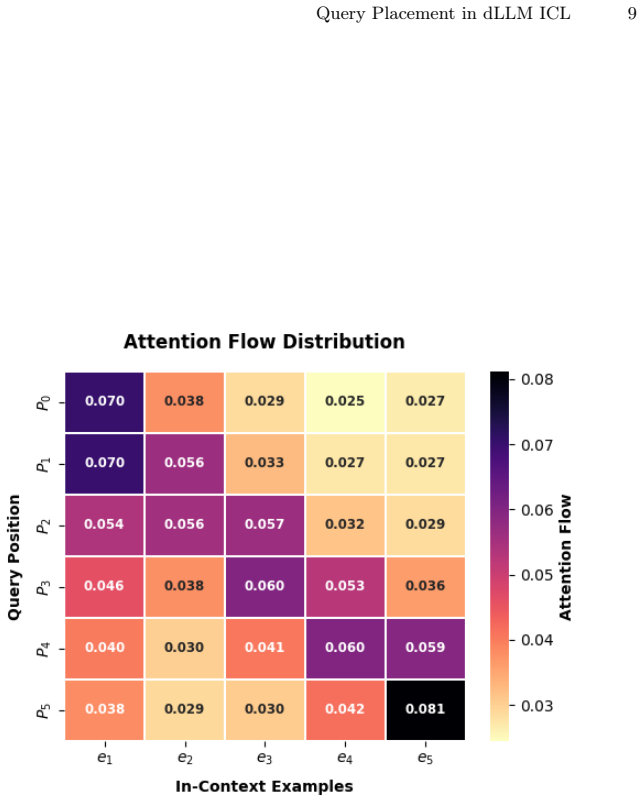
Query position is actually a first-order variable in dLLMs. Through empirical decoupling, positional variance impacts generation quality on par with example semantic quality. Internally, this positional sensitivity stems from a spatial Recency Effect in attention flow and task-dependent shifts in decoding trajectories. Traditional single-step confidence fails in dLLMs, while Average Confidence tracks the iterative decoding process. Auto-ICL is a training-free adaptive routing strategy that dynamically optimizes query placement and approaches oracle performance across heterogeneous tasks.
What carries the argument
Average Confidence, a metric that averages token-level confidence scores over the full iterative decoding trajectory to rank candidate query positions without ground-truth labels.
If this is right
- Dynamic query placement via Average Confidence can be applied at inference time to improve ICL without retraining.
- Spatial ICL baselines become necessary for fair evaluation of dLLMs because trailing-query templates inherited from AR models are suboptimal.
- Decoding-trajectory shifts explain why single-step metrics break and why multi-step averaging restores reliability.
- The same positional routing logic extends to any task where bidirectional attention is used for iterative refinement.
Where Pith is reading between the lines
- Prompt templates for dLLMs may need to be redesigned from the ground up rather than adapted from AR conventions.
- If recency in attention is the dominant driver, similar position effects could appear in other bidirectional or diffusion-style sequence models.
- Auto-ICL style routing could be tested as a lightweight way to improve few-shot performance on perception tasks where AR models already struggle.
Load-bearing premise
The observed positional effects are driven by a spatial recency bias in attention and that averaging confidence over decoding steps reliably indicates output quality.
What would settle it
A controlled experiment that holds example content fixed, varies only query position, and finds no measurable difference in final generation quality or in how well single-step confidence predicts correctness.
Figures






read the original abstract
While In-Context Learning (ICL) is extensively studied in Autoregressive (AR) LLMs, its mechanism within Diffusion Large Language Models (dLLMs) remains largely unexplored. Unlike AR models restricted by unidirectional causal masking, dLLMs intrinsically utilize bidirectional attention, offering extensive spatial flexibility for query placement. Unfortunately, current practices conventionally inherit AR-style trailing-query templates, often overlooking the structural paradigm shift. This paper presents a comprehensive analysis unveiling that query position is actually a first-order variable in dLLMs. Through empirical decoupling, we demonstrate that positional variance impacts generation quality on par with example semantic quality. Internally, this positional sensitivity stems from a spatial ``Recency Effect'' in attention flow and task-dependent shifts in decoding trajectories. To mitigate this instability without ground-truth labels, we reveal that traditional single-step confidence ($C_{decoded}$) fails in dLLMs. Instead, we propose Average Confidence ($\overline{C}$), a novel metric tracking the iterative decoding process. By establishing the foundational spatial ICL baselines, we introduce Auto-ICL, a training-free adaptive routing strategy that dynamically optimizes query placement, robustly approaching oracle performance across heterogeneous reasoning and perception tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that query position is a first-order variable in in-context learning for diffusion LLMs (dLLMs), with positional variance impacting generation quality on par with example semantic quality. It attributes this to a spatial Recency Effect in attention flow and task-dependent decoding trajectory shifts, shows that single-step confidence fails in dLLMs, introduces Average Confidence as a label-free metric tracking iterative decoding, and proposes the training-free Auto-ICL adaptive routing strategy that approaches oracle performance on reasoning and perception tasks.
Significance. If the empirical decoupling and causal mechanisms hold under rigorous controls, the work establishes foundational spatial ICL baselines for dLLMs that differ structurally from AR models due to bidirectional attention. The Average Confidence metric and Auto-ICL strategy address a practical instability without ground-truth labels and could influence prompt design for this emerging model class.
minor comments (2)
- The abstract introduces 'Average Confidence' and 'Auto-ICL' without defining their precise formulations or how they differ from standard confidence measures; this should be clarified in the methods section for reproducibility.
- The claim of 'empirical decoupling' between position and semantics would benefit from explicit reference to the specific tables or figures showing effect sizes and statistical tests.
Simulated Author's Rebuttal
We thank the referee for their review and positive assessment of the significance of our work on positional bias in in-context learning for diffusion LLMs. We appreciate the recognition that query position is a first-order variable and that Average Confidence and Auto-ICL offer practical value. No specific major comments were raised in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical analysis of positional bias in dLLMs via experiments on attention flow and decoding trajectories, proposing Average Confidence and Auto-ICL as practical mitigations. No derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations appear in the abstract or described structure. Claims rest on observed performance differences and metric comparisons rather than reductions to inputs by construction. This is the expected outcome for an empirical methods paper without mathematical self-reference.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Average Confidence metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceed- ings of the 58th annual meeting of the association for computational linguistics
Abnar, S., Zuidema, W.: Quantifying attention flow in transformers. In: Proceed- ings of the 58th annual meeting of the association for computational linguistics. pp. 4190–4197 (2020)
2020
-
[2]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Arriola, M., Gokaslan, A., Chiu, J.T., Yang, Z., Qi, Z., Han, J., Sahoo, S.S., Kuleshov, V.: Block diffusion: Interpolating between autoregressive and diffusion language models. arXiv preprint arXiv:2503.09573 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., Sutton, C.: Program synthesis with large language models (2021),https://arxiv.org/abs/2108.07732 18 Z. Li et al
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
arXiv preprint arXiv:2501.15030 (2025)
Bhope, R.A., Venkateswaran, P., Jayaram, K., Isahagian, V., Muthusamy, V., Venkatasubramanian, N.: Optiseq: Ordering examples on-the-fly for in-context learning. arXiv preprint arXiv:2501.15030 (2025)
-
[5]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Chang, T.Y., Jia, R.: Data curation alone can stabilize in-context learning. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8123–8144 (2023)
2023
-
[6]
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., Schulman, J.: Training verifiers to solve math word problems (2021),https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Cobbina, K.A., Zhou, T.: Where to show demos in your prompt: A positional bias of in-context learning. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 29548–29581 (2025)
2025
-
[8]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., et al.: A survey on in-context learning. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 1107–1128 (2024)
2024
-
[9]
In: International conference on machine learning
Ghorbani, A., Zou, J.: Data shapley: Equitable valuation of data for machine learn- ing. In: International conference on machine learning. pp. 2242–2251. PMLR (2019)
2019
-
[10]
In: Findings of the Association for Computational Linguistics: ACL 2024
Guo, Q., Wang, L., Wang, Y., Ye, W., Zhang, S.: What makes a good order of examples in in-context learning. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 14892–14904 (2024)
2024
-
[11]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring massive multitask language understanding (2021),https://arxiv. org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
arXiv preprint arXiv:2508.13021 (2025)
Huang, P., Liu, S., Liu, Z., Yan, Y., Wang, S., Chen, Z., Xiao, T.: Pc-sampler: Position-aware calibration of decoding bias in masked diffusion models. arXiv preprint arXiv:2508.13021 (2025)
-
[13]
In: Proceedings of the 56th annual meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Khandelwal, U., He, H., Qi, P., Jurafsky, D.: Sharp nearby, fuzzy far away: How neural language models use context. In: Proceedings of the 56th annual meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 284–294 (2018)
2018
- [14]
-
[15]
Diffusion Language Models Know the Answer Before Decoding
Li, P., Zhou, Y., Muhtar, D., Yin, L., Yan, S., Shen, L., Vosoughi, S., Liu, S.: Diffusion language models know the answer before decoding. arXiv preprint arXiv:2508.19982 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
arXiv preprint arXiv:2511.09700 (2025)
Li, W., Wang, Y., Wang, Z., Shang, J.: Order matters: Rethinking prompt con- struction in in-context learning. arXiv preprint arXiv:2511.09700 (2025)
-
[17]
arXiv preprint arXiv:2601.03199 (2026)
Li,Y.,Meng,H.,Wang,C.,Chen,H.:Dip:Dynamicin-contextplannerfordiffusion language models. arXiv preprint arXiv:2601.03199 (2026)
-
[18]
Liu, J., Shen, D., Zhang, Y., Dolan, W.B., Carin, L., Chen, W.: What makes good in-context examples for gpt-3? In: Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd workshop on knowledge extraction and integration for deep learning architectures. pp. 100–114 (2022)
2022
-
[19]
arXiv preprint arXiv:2402.10738 (2024)
Liu, Y., Liu, J., Shi, X., Cheng, Q., Huang, Y., Lu, W.: Let’s learn step by step: Enhancing in-context learning ability with curriculum learning. arXiv preprint arXiv:2402.10738 (2024)
-
[20]
arXiv preprint arXiv:2602.02159 (2026) Query Placement in dLLM ICL 19
Long, L., Huang, Y., Bai, S., Gong, R., Zhang, J., Zhou, A., Yang, J.: Focus-dllm: Accelerating long-context diffusion llm inference via confidence-guided context fo- cusing. arXiv preprint arXiv:2602.02159 (2026) Query Placement in dLLM ICL 19
-
[21]
In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Lu, Y., Bartolo, M., Moore, A., Riedel, S., Stenetorp, P.: Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 8086–8098 (2022)
2022
-
[22]
Min, S., Lewis, M., Hajishirzi, H., Zettlemoyer, L.: Rethinking the role of demon- strations: What makes in-context learning work? In: Proceedings of the 2022 Con- ference on Empirical Methods in Natural Language Processing. pp. 11048–11064 (2022)
2022
-
[23]
arXiv preprint arXiv:2302.11042 (2023)
Nguyen, T., Wong, E.: In-context example selection with influences. arXiv preprint arXiv:2302.11042 (2023)
-
[24]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y., Wen, J.R., Li, C.: Large language diffusion models. arXiv preprint arXiv:2502.09992 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In: Findings of the association for computational linguistics: ACL 2023
Tang, R., Kong, D., Huang, L., et al.: Large language models can be lazy learn- ers: Analyze shortcuts in in-context learning. In: Findings of the association for computational linguistics: ACL 2023. pp. 4645–4657 (2023)
2023
-
[26]
arXiv preprint arXiv:2508.09138 (2025)
Wang, W., Fang, B., Jing, C., Shen, Y., Shen, Y., Wang, Q., Ouyang, H., Chen, H., Shen, C.: Time is a feature: Exploiting temporal dynamics in diffusion language models. arXiv preprint arXiv:2508.09138 (2025)
-
[27]
arXiv preprint arXiv:2508.09192 (2025)
Wang, X., Xu, C., Jin, Y., Jin, J., Zhang, H., Deng, Z.: Diffusion llms can do faster- than-ar inference via discrete diffusion forcing. arXiv preprint arXiv:2508.09192 (2025)
-
[28]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Wu, C., Zhang, H., Xue, S., Liu, Z., Diao, S., Zhu, L., Luo, P., Han, S., Xie, E.: Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. arXiv preprint arXiv:2505.22618 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Wu, Z., Wang, Y., Ye, J., Kong, L.: Self-adaptive in-context learning: An infor- mation compression perspective for in-context example selection and ordering. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 1423–1436 (2023)
2023
-
[30]
arXiv preprint arXiv:2512.16229 (2025)
Xu, C., Jin, Y., Li, J., Tu, Y., Long, G., Tu, D., Song, M., Si, H., Hou, T., Yan, J., et al.: Lopa: Scaling dllm inference via lookahead parallel decoding. arXiv preprint arXiv:2512.16229 (2025)
- [31]
-
[32]
Dream 7B: Diffusion Large Language Models
Ye, J., Xie, Z., Zheng, L., Gao, J., Wu, Z., Jiang, X., Li, Z., Kong, L.: Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing
Yoo, K.M., Kim, J., Kim, H.J., Cho, H., Jo, H., Lee, S.W., Lee, S.g., Kim, T.: Ground-truth labels matter: A deeper look into input-label demonstrations. In: Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. pp. 2422–2437 (2022)
2022
-
[34]
Yu, R., Li, Q., Wang, X.: Discrete diffusion in large language and multimodal models: A survey. arXiv preprint arXiv:2506.13759 (2025)
-
[35]
Zhang, X., Quan, Y., Shen, C., Yuan, X., Yan, S., Xie, L., Wang, W., Gu, C., Tang, H., Ye, J.: From redundancy to relevance: Information flow in lvlms across reasoning tasks. In: Proceedings of the 2025 Conference of the Nations of the Amer- icas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)....
2025
-
[36]
In: International conference on machine learning
Zhao, Z., Wallace, E., Feng, S., Klein, D., Singh, S.: Calibrate before use: Improving few-shot performance of language models. In: International conference on machine learning. pp. 12697–12706. Pmlr (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.