Playful Agentic Robot Learning
Pith reviewed 2026-06-26 20:52 UTC · model grok-4.3
The pith
Robot agents build reusable code skills through self-directed play before facing specific tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
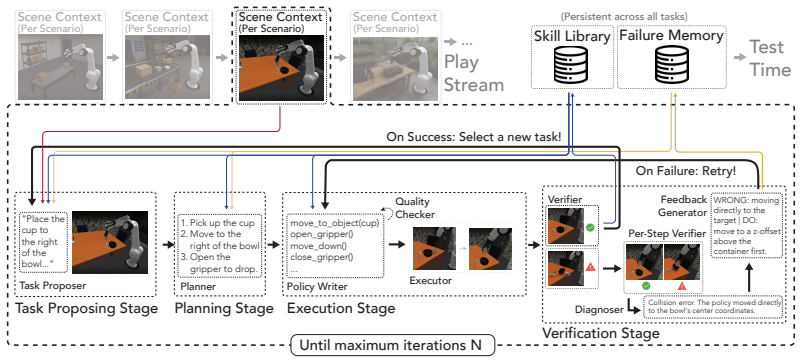
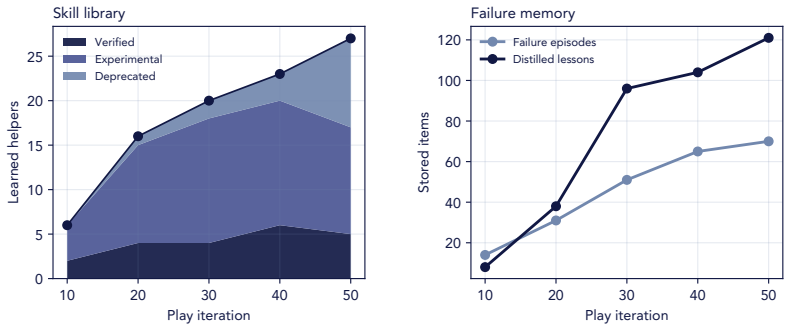
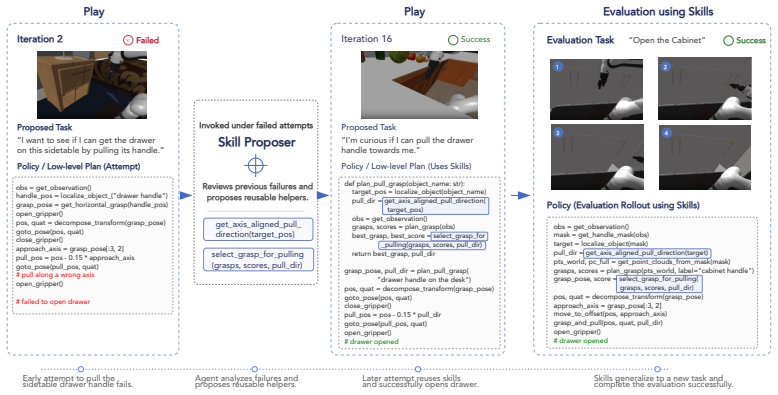
Robotics Agent Teams perform self-directed play by proposing novel yet learnable exploratory tasks, planning and executing robot-code policies, verifying intermediate progress with step-level feedback, diagnosing failures, retrying, and distilling successful executions into a frozen code skill library that is later retrieved to solve new tasks.
What carries the argument
RATs (Robotics Agent Teams) that generate exploratory tasks during play, execute code policies, verify outcomes, and compile successes into a reusable code skill library for later retrieval.
Load-bearing premise
The agents can reliably propose novel yet learnable exploratory tasks, verify intermediate progress, diagnose failures, and distill successful executions into a persistent reusable code skill library without external supervision or post-hoc human curation.
What would settle it
An experiment in which skills retrieved from the play-built library produce no improvement or lower success rates on held-out downstream tasks compared to no-play or random-play baselines would falsify the central claim.
Figures








read the original abstract
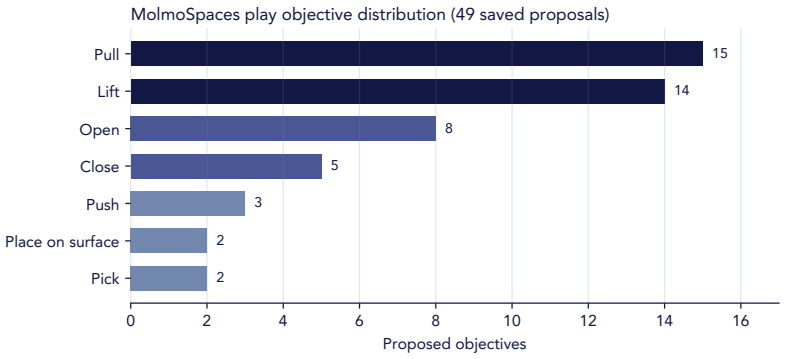
Current agentic robot systems can write executable Code-as-Policy programs, observe feedback, and revise behavior across multiple attempts, but they remain largely task-driven: reusable skills are acquired only after explicit instructions. We study Playful Agentic Robot Learning, where an embodied coding agent uses self-directed play as a continual skill-learning stage before downstream tasks arrive. We introduce RATs, Robotics Agent Teams designed for play-time skill acquisition. During play, RATs proposes novel yet learnable exploratory tasks, plans and executes robot-code policies, verifies intermediate progress, diagnoses failures, retries with dense, step-level feedback, and distills successful executions into a persistent code skill library. At test time, the agent reuses relevant skills from this frozen library to help solve new tasks. Experiments in LIBERO-PRO and MolmoSpaces show that play-learned skills improve held-out downstream tasks over no-play and random-play baselines, with 20.6 and 17.0 percentage-point gains over CaP-Agent0 on LIBERO-PRO and MolmoSpaces, respectively. Moreover, the learned skills can be plugged into other inference-time Code-as-Policy agents by simply retrieving them into the context, improving RoboSuite and real-world transfer by 8.9 and 8.8 points, respectively, without finetuning the underlying model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Playful Agentic Robot Learning, in which Robotics Agent Teams (RATs) perform self-directed play to autonomously propose exploratory tasks, execute Code-as-Policy programs, verify progress, diagnose failures with dense feedback, and distill successes into a reusable frozen code skill library. These skills are then retrieved at test time to improve held-out downstream task performance, yielding 20.6 and 17.0 percentage-point gains over CaP-Agent0 on LIBERO-PRO and MolmoSpaces, respectively, plus 8.9 and 8.8 point improvements when plugged into other agents on RoboSuite and real-world transfer without finetuning the base model.
Significance. If the unsupervised play pipeline functions as described, the work offers a concrete path toward modular, reusable skill libraries in embodied agents that can be composed at inference time. The reported benchmark gains on named suites and the zero-finetune transfer results provide a clear, falsifiable basis for evaluating the approach. The absence of free parameters in the core claim and the emphasis on persistent code skills are strengths that distinguish it from purely task-driven baselines.
major comments (2)
- [abstract and §3] Play phase description (abstract and §3): The central empirical gains rest on the claim that RATs autonomously propose novel yet learnable tasks, verify intermediate progress, diagnose failures, and distill skills without external supervision or post-hoc curation. No concrete mechanisms, success criteria, or failure modes for autonomous verification and diagnosis are provided; if these steps rely on implicit human filtering or oracle signals, the no-play and random-play baselines become incomparable and the 20.6 pp / 17.0 pp improvements do not follow from the stated method.
- [results section and tables] Experimental controls (results section and tables reporting LIBERO-PRO / MolmoSpaces): The abstract and results report percentage-point gains but supply no information on number of runs, statistical significance tests, data exclusion rules, or error bars. Without these, it is impossible to assess whether the observed differences are robust or whether the play-learned library genuinely drives the improvement versus variance in the underlying Code-as-Policy agent.
minor comments (2)
- [abstract] Abstract: the phrase 'without finetuning the underlying model' should be accompanied by a brief statement of what model is used and whether any prompt engineering or retrieval hyperparameters are tuned.
- Notation: 'RATs' is introduced as an acronym but the expansion 'Robotics Agent Teams' appears only once; consistent use of the acronym after first definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen clarity and reporting where needed.
read point-by-point responses
-
Referee: [abstract and §3] Play phase description (abstract and §3): The central empirical gains rest on the claim that RATs autonomously propose novel yet learnable tasks, verify intermediate progress, diagnose failures, and distill skills without external supervision or post-hoc curation. No concrete mechanisms, success criteria, or failure modes for autonomous verification and diagnosis are provided; if these steps rely on implicit human filtering or oracle signals, the no-play and random-play baselines become incomparable and the 20.6 pp / 17.0 pp improvements do not follow from the stated method.
Authors: Section 3 specifies that verification and diagnosis occur via the agent's internal code execution traces and self-generated dense feedback prompts, with no external oracle or human curation applied to the play phase. The no-play and random-play baselines use identical execution and retrieval pipelines, isolating the effect of the distilled library. To address the request for greater concreteness, we will add explicit pseudocode for the verification loop, success criteria (e.g., task-completion predicates), and representative failure-mode traces in the revised §3. revision: yes
-
Referee: [results section and tables] Experimental controls (results section and tables reporting LIBERO-PRO / MolmoSpaces): The abstract and results report percentage-point gains but supply no information on number of runs, statistical significance tests, data exclusion rules, or error bars. Without these, it is impossible to assess whether the observed differences are robust or whether the play-learned library genuinely drives the improvement versus variance in the underlying Code-as-Policy agent.
Authors: The referee correctly notes the absence of run counts, error bars, and significance tests. In the revision we will report results over 5 independent seeds per condition, include standard-error bars on all tables, state the data-exclusion rule (failed environment resets only), and add paired t-tests between conditions to quantify robustness. revision: yes
Circularity Check
No circularity: empirical gains rest on experimental comparisons, not derivations
full rationale
The paper reports empirical performance improvements from play-learned skills on held-out downstream tasks (LIBERO-PRO, MolmoSpaces, RoboSuite, real-world) versus no-play and random-play baselines. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims are direct experimental outcomes rather than any reduction of a result to its own inputs by construction. The evaluation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
RATs (Robotics Agent Teams)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500. IEEE, 2023
2023
-
[2]
Singh, V
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. ProgPrompt: Generating situated robot task plans using large language models. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 11523– 11530. IEEE, 2023
2023
-
[3]
Vemprala, R
S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor. ChatGPT for robotics: Design principles and model abilities.IEEE Access, 12:55682–55696, 2024
2024
-
[4]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[5]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, 9 K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilin- sky.π 0: A vision-language-action flow model for general robot control. InProcee...
2025
-
[6]
Black, N
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tan...
2025
-
[7]
M. Fu, J. Yu, K. El-Refai, E. Kou, H. Xue, H. Huang, W. Xiao, G. Wang, F.-F. Li, G. Shi, J. Wu, S. Sastry, Y . Zhu, K. Goldberg, and L. Fan. CaP-X: A framework for benchmarking and improving coding agents for robot manipulation.arXiv preprint arXiv:2603.22435, 2026
arXiv 2026
-
[8]
Piaget.The Origins of Intelligence in Children
J. Piaget.The Origins of Intelligence in Children. International Universities Press, New York, 1952
1952
-
[9]
A. Gopnik. Childhood as a solution to explore-exploit tensions.Philosophical Transactions of the Royal Society B: Biological Sciences, 375(1803):20190502, 2020. doi:10.1098/rstb.2019. 0502
-
[10]
L. B. Smith and M. Gasser. The development of embodied cognition: Six lessons from babies. Artificial Life, 11(1-2):13–29, 2005. doi:10.1162/1064546053278973
-
[11]
Schmidhuber
J. Schmidhuber. Curious model-building control systems. InProceedings of the International Joint Conference on Neural Networks (IJCNN), volume 2, pages 1458–1463, Singapore, 1991. IEEE
1991
-
[12]
P.-Y . Oudeyer, F. Kaplan, and V . V . Hafner. Intrinsic motivation systems for autonomous mental development.IEEE Transactions on Evolutionary Computation, 11(2):265–286, 2007. doi:10.1109/TEVC.2006.890271
-
[13]
Baranes and P.-Y
A. Baranes and P.-Y . Oudeyer. Active learning of inverse models with intrinsically motivated goal exploration in robots.Robotics and Autonomous Systems, 61(1):49–73, 2013
2013
-
[14]
Forestier and P.-Y
S. Forestier and P.-Y . Oudeyer. Modular active curiosity-driven discovery of tool use. In2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3965– 3972, Daejeon, Korea, 2016. IEEE
2016
-
[15]
Pathak, P
D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell. Curiosity-driven exploration by self- supervised prediction. InProceedings of the 34th International Conference on Machine Learn- ing (ICML), volume 70 ofProceedings of Machine Learning Research, pages 2778–2787, 2017
2017
-
[16]
Houthooft, X
R. Houthooft, X. Chen, Y . Duan, J. Schulman, F. De Turck, and P. Abbeel. VIME: Variational information maximizing exploration. InAdvances in Neural Information Processing Systems 29 (NeurIPS), 2016
2016
-
[17]
L. S. Vygotsky.Mind in Society: The Development of Higher Psychological Processes. Har- vard University Press, Cambridge, MA, 1978. Edited by Michael Cole, Vera John-Steiner, Sylvia Scribner, and Ellen Souberman
1978
-
[18]
A. D. Pellegrini.The Role of Play in Human Development. Oxford University Press, Oxford, UK, 2009. ISBN 9780195367324
2009
-
[19]
Schmidhuber
J. Schmidhuber. Formal theory of creativity, fun, and intrinsic motivation (1990–2010).IEEE Transactions on Autonomous Mental Development, 2(3):230–247, 2010. 10
1990
-
[20]
F. Kaplan and P.-Y . Oudeyer. In search of the neural circuits of intrinsic motivation.Frontiers in Neuroscience, 1(1):225–236, 2007. doi:10.3389/neuro.01.1.1.017.2007
-
[21]
C. Kidd, S. T. Piantadosi, and R. N. Aslin. The goldilocks effect: Human infants allocate attention to visual sequences that are neither too simple nor too complex.PLOS ONE, 7(5): e36399, 2012. doi:10.1371/journal.pone.0036399
-
[22]
M. Rolf, J. J. Steil, and M. Gienger. Goal babbling permits direct learning of inverse kine- matics.IEEE Transactions on Autonomous Mental Development, 2(3):216–229, 2010. doi: 10.1109/TAMD.2010.2062511
-
[23]
Forestier, R
S. Forestier, R. Portelas, Y . Mollard, and P.-Y . Oudeyer. Intrinsically motivated goal explo- ration processes with automatic curriculum learning.Journal of Machine Learning Research, 23(152):1–41, 2022
2022
-
[24]
Lynch, M
C. Lynch, M. Khansari, T. Xiao, V . Kumar, J. Tompson, S. Levine, and P. Sermanet. Learning latent plans from play. In L. P. Kaelbling, D. Kragic, and K. Sugiura, editors,Proceedings of the Conference on Robot Learning, volume 100 ofProceedings of Machine Learning Research, pages 1113–1132. PMLR, 30 Oct–01 Nov 2020. URLhttps://proceedings.mlr.press/ v100/...
2020
-
[25]
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. Mimic- play: Long-horizon imitation learning by watching human play. In J. Tan, M. Toussaint, and K. Darvish, editors,Proceedings of The 7th Conference on Robot Learning, volume 229 of Proceedings of Machine Learning Research, pages 201–221. PMLR, 06–09 Nov 2023. URL https:/...
2023
-
[26]
Colas, T
C. Colas, T. Karch, N. Lair, J.-M. Dussoux, C. Moulin-Frier, P. F. Dominey, and P.-Y . Oudeyer. Language as a cognitive tool to imagine goals in curiosity-driven exploration. InAdvances in Neural Information Processing Systems 33 (NeurIPS), 2020
2020
-
[27]
Thrun and T
S. Thrun and T. M. Mitchell. Lifelong robot learning.Robotics and Autonomous Systems, 15 (1–2):25–46, 1995
1995
-
[28]
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019. doi:10.1016/j.neunet.2019. 01.012
-
[29]
Lesort, V
T. Lesort, V . Lomonaco, A. Stoian, D. Maltoni, D. Filliat, and N. Díaz-Rodríguez. Continual learning for robotics: Definition, framework, learning strategies, opportunities and challenges. Information Fusion, 58:52–68, 2020
2020
-
[30]
R. S. Sutton, D. Precup, and S. Singh. Between MDPs and semi-MDPs: A framework for tem- poral abstraction in reinforcement learning.Artificial Intelligence, 112(1–2):181–211, 1999
1999
-
[31]
Konidaris, S
G. Konidaris, S. Kuindersma, R. Grupen, and A. Barto. Robot learning from demonstration by constructing skill trees.The International Journal of Robotics Research, 31(3):360–375, 2012
2012
-
[32]
Kroemer, S
O. Kroemer, S. Niekum, and G. Konidaris. A review of robot learning for manipulation: Challenges, representations, and algorithms.Journal of Machine Learning Research, 22(30): 1–82, 2021
2021
-
[33]
Pertsch, Y
K. Pertsch, Y . Lee, and J. J. Lim. Accelerating reinforcement learning with learned skill priors. InProceedings of the 4th Conference on Robot Learning (CoRL), volume 155 ofProceedings of Machine Learning Research, pages 188–204, 2020
2020
-
[34]
C. Lynch and P. Sermanet. Language conditioned imitation learning over unstructured data. InProceedings of Robotics: Science and Systems (RSS), 2021. doi:10.15607/RSS.2021.XVII. 047. 11
-
[35]
W. Wan, Y . Zhu, R. Shah, and Y . Zhu. Lotus: Continual imitation learning for robot manip- ulation through unsupervised skill discovery, 2024. URLhttps://arxiv.org/abs/2311. 02058
2024
-
[36]
Y . J. Ma, W. Liang, H.-J. Wang, S. Wang, Y . Zhu, L. Fan, O. Bastani, and D. Jayaraman. DrEureka: Language model guided sim-to-real transfer. InRobotics: Science and Systems (RSS), 2024. URLhttps://arxiv.org/abs/2406.01967
arXiv 2024
-
[37]
Bengio, J
Y . Bengio, J. Louradour, R. Collobert, and J. Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning (ICML), pages 41–48. ACM, 2009
2009
-
[38]
Narvekar, B
S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P. Stone. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research, 21(181):1–50, 2020
2020
-
[39]
Florensa, D
C. Florensa, D. Held, X. Geng, and P. Abbeel. Automatic goal generation for reinforcement learning agents. InProceedings of the 35th International Conference on Machine Learning (ICML), volume 80 ofProceedings of Machine Learning Research, pages 1515–1528, 2018
2018
-
[40]
A. Nair, V . Pong, M. Dalal, S. Bahl, S. Lin, and S. Levine. Visual reinforcement learning with imagined goals. InAdvances in Neural Information Processing Systems 31 (NeurIPS), 2018
2018
-
[41]
V . H. Pong, M. Dalal, S. Lin, A. Nair, S. Bahl, and S. Levine. Skew-Fit: State-covering self- supervised reinforcement learning. InProceedings of the 37th International Conference on Machine Learning (ICML), volume 119 ofProceedings of Machine Learning Research, pages 7783–7792, 2020
2020
-
[42]
Seita, D
D. Seita, D. Chan, R. Rao, C. Tang, M. Zhao, and J. Canny. ZPD teaching strategies for deep reinforcement learning from demonstrations. InDeep Reinforcement Learning Workshop at NeurIPS, 2019
2019
-
[43]
Y . Mu, J. Chen, Q. Zhang, S. Chen, Q. Yu, C. Ge, R. Chen, Z. Liang, M. Hu, C. Tao, P. Sun, H. Yu, C. Yang, W. Shao, W. Wang, J. Dai, Y . Qiao, M. Ding, and P. Luo. Robocodex: Multimodal code generation for robotic behavior synthesis, 2024. URLhttps://arxiv. org/abs/2402.16117
arXiv 2024
-
[44]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Bal- akrishna, N. Batchelor, A. Bewley, J. Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342, 2025
Pith/arXiv arXiv 2025
-
[45]
J. Shi, R. Yang, K. Chao, B. S. Wan, Y . S. Shao, J. Lei, J. Qian, L. Le, P. Chaudhari, K. Dani- ilidis, et al. Maestro: Orchestrating robotics modules with vision-language models for zero- shot generalist robots. InNeurIPS 2025 Workshop on Space in Vision, Language, and Embod- ied AI, 2025
2025
-
[46]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. Ruano, K. Jeffrey, S. Jesmonth, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Rettingh...
2022
-
[47]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, 12 K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An embodied multimodal language model. InProceedings of the 40th International Conf...
2023
-
[48]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxPoser: Composable 3D value maps for robotic manipulation with language models. InProceedings of the 7th Conference on Robot Learning (CoRL), volume 229 ofProceedings of Machine Learning Research, 2023
2023
-
[49]
A. Zeng, M. Attarian, B. Ichter, K. Choromanski, A. Wong, S. Welker, F. Tombari, A. Purohit, M. Ryoo, V . Sindhwani, J. Lee, V . Vanhoucke, and P. Florence. Socratic models: Composing zero-shot multimodal reasoning with language. InThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[50]
Y . Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y . Qiao, and P. Luo. EmbodiedGPT: Vision-language pre-training via embodied chain of thought. InAdvances in Neural Information Processing Systems 36 (NeurIPS), pages 25081–25094, 2023
2023
-
[51]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Represen- tations, 2023. URLhttps://openreview.net/forum?id=WE_vluYUL-X
2023
-
[52]
Shinn, F
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Lan- guage agents with verbal reinforcement learning. InAdvances in Neural Information Process- ing Systems 36 (NeurIPS), 2023
2023
-
[53]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prab- humoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Informa- tion Processing Systems 36 (NeurIPS), 2023
2023
-
[54]
X. Chen, M. Lin, N. Schärli, and D. Zhou. Teaching large language models to self-debug. In The Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[55]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar. V oy- ager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research (TMLR), 2024
2024
-
[56]
K. Lin, C. Snell, Y . Wang, C. Packer, S. Wooders, I. Stoica, and J. E. Gonzalez. Sleep-time compute: Beyond inference scaling at test-time.arXiv preprint arXiv:2504.13171, 2025
arXiv 2025
-
[57]
Y . Zhu, J. Wong, A. Mandlekar, R. Martín-Martín, A. Joshi, K. Lin, S. Nasiriany, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learning. InarXiv preprint arXiv:2009.12293, 2020
Pith/arXiv arXiv 2009
-
[58]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[59]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: To- wards robust and fair evaluation of vision-language-action models beyond memorization.arXiv preprint arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[60]
Y . Kim, W. Pumacay, O. Rayyan, M. Argus, W. Han, E. VanderBilt, J. Salvador, A. Deshpande, R. Hendrix, S. Jauhri, et al. Molmospaces: A large-scale open ecosystem for robot navigation and manipulation.arXiv preprint arXiv:2602.11337, 2026
arXiv 2026
-
[61]
I’m curious if I can lift the brown tissue box straight up into the air
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, 2024. 13 Appendix Table of Contents A Implementation Details about RATS15 A.1 Details of Play-Time Task Proposal . . . . . . . . . . . . . ....
2024
-
[62]
Review the task history — what worked, what failed, and WHY?
-
[63]
If recent tasks failed, consider whether to try a simpler variant or a 41completely different approach
-
[64]
If recent tasks succeeded, consider building on those skills with 43something slightly harder — but still single-step and child-feasible
-
[65]
45The target object (arg1 of an ‘On‘/‘In‘ goal) MUST come from the RELIABLE 46list in the Pick-Primitive Reliability block
Pick objects and fixtures that make the task interesting but achievable. 45The target object (arg1 of an ‘On‘/‘In‘ goal) MUST come from the RELIABLE 46list in the Pick-Primitive Reliability block
-
[66]
Ensure the goal uses valid predicates from the catalog
-
[67]
Do NOT use the "Stack" predicate (currently unsupported in the 49simulator)
-
[68]
For kitchen scenes use LIBERO_Kitchen_Tabletop_Manipulation, for table 51scenes use LIBERO_Tabletop_Manipulation
-
[69]
no broken 56combos apply
**Inspect against the KNOWN ENV LIMITATIONS list above.** If your 53intended (predicate, container) combo is on it, pick a different 54container OR a different predicate. State in ‘reasoning‘ that you 55checked the list and explain the substitution, or note "no broken 56combos apply" if the list is empty for your candidate. 57 58Respond in JSON with keys:...
-
[70]
The problem class name MUST be one of the listed scene types (e.g., 64LIBERO_Kitchen_Tabletop_Manipulation). 37
-
[71]
Every object and fixture in (:init) must have a placement region defined 66in (:regions)
-
[72]
68Keep ranges small (0.02 wide)
Region ranges are (x_min y_min x_max y_max) relative to the workspace. 68Keep ranges small (0.02 wide). Stay within [-0.45, 0.45] for x and [-0.35, 690.35] for y
-
[73]
Fixtures that go on the workspace also need an init region and an (On 71fixture workspace_region) in (:init)
-
[74]
Fixture sub-regions (like top_region for cabinet, cook_region for stove, 73heating_region for microwave) use (:target fixture_instance) with NO 74(:ranges) — they are predefined by the fixture
-
[75]
Objects of interest ((:obj_of_interest)) should include the 76objects/regions that appear in the goal
-
[76]
Use And to combine multiple goal predicates
-
[77]
Object instances are numbered: butter_1, akita_black_bowl_1, 79akita_black_bowl_2, etc
-
[78]
{workspace}_
CRITICAL: In (:regions), region names must NOT include the workspace 81prefix. LIBERO auto-prepends "{workspace}_" to region names. So define 82"butter_init_region" (NOT "kitchen_table_butter_init_region"). In (:init) 83and (:goal), use the FULL prefixed name: "kitchen_table_butter_init_region"
-
[79]
In (:goal), fixture sub-regions are prefixed: {fixture_instance}_{sub} 85(e.g., wooden_cabinet_1_top_region)
-
[80]
table",
CRITICAL: In (:fixtures), the workspace type is the LOWERCASE workspace 87type from the catalog (e.g., "table", "kitchen_table"), NOT the problem 88class name. Example: "main_table - table" or "kitchen_table - 89kitchen_table"
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.