Uncertainty Decomposition for Clarification Seeking in LLM Agents
Pith reviewed 2026-06-26 20:42 UTC · model grok-4.3
The pith
A prompt-based split of uncertainty into action confidence and request uncertainty lets LLM agents ask for clarification on ambiguous tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
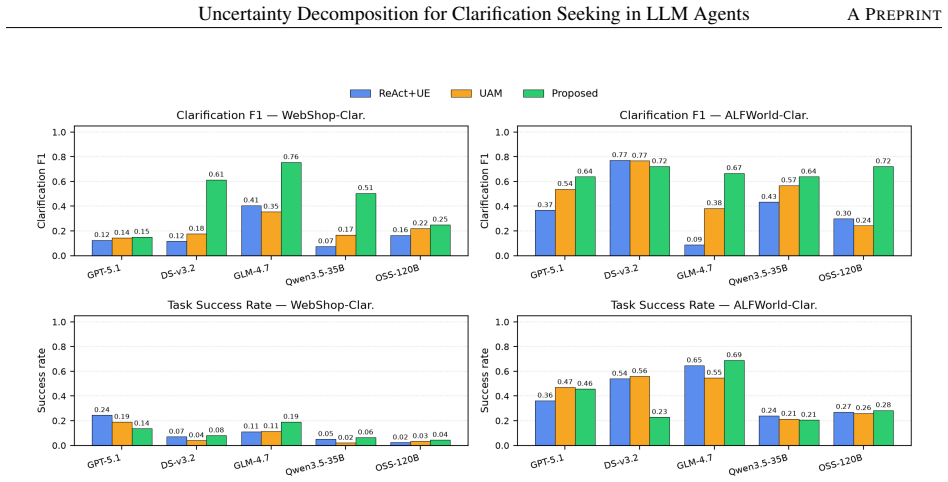
The central claim is that a prompt-based decomposition separating action confidence from request uncertainty (u) enables an agent to detect ambiguous task specifications and issue clarification requests, producing higher clarification F1 than ReAct+UE and UAM on the new WebShop-Clarification and ALFWorld-Clarification benchmarks while preserving performance on standard WebShop, ALFWorld, and REAL tasks across five backbones.
What carries the argument
prompt-based decomposition separating action confidence from request uncertainty (u)
If this is right
- Agents using the decomposition can issue clarification requests precisely when the task specification is ambiguous.
- Clarification F1 rises 73 percent over ReAct+UE and 36 percent over UAM on ALFWorld-Clarification averaged across backbones.
- The method leads clarification F1 on every backbone for WebShop-Clarification and on four of five backbones for ALFWorld-Clarification.
- Performance holds on standard non-clarification benchmarks, showing the decomposition does not degrade ordinary task execution.
- The gains appear under black-box API constraints without log-probabilities, multi-sampling, or training.
Where Pith is reading between the lines
- The same split could be used to maintain a running estimate of shared understanding across multi-turn conversations.
- Combining the request-uncertainty signal with external memory or tool-use traces might further reduce repeated clarification loops.
- The decomposition may generalize to other interactive settings such as code generation or data analysis where missing constraints are common.
Load-bearing premise
The uncertainty signals from the deliberately underspecified tasks in the two benchmarks match the distribution of underspecification that occurs in real user interactions with agents.
What would settle it
Measuring whether the same clarification F1 gains appear when the method is run on tasks that real users have underspecified rather than on the synthetic 50-percent underspecification in the benchmarks.
Figures





read the original abstract
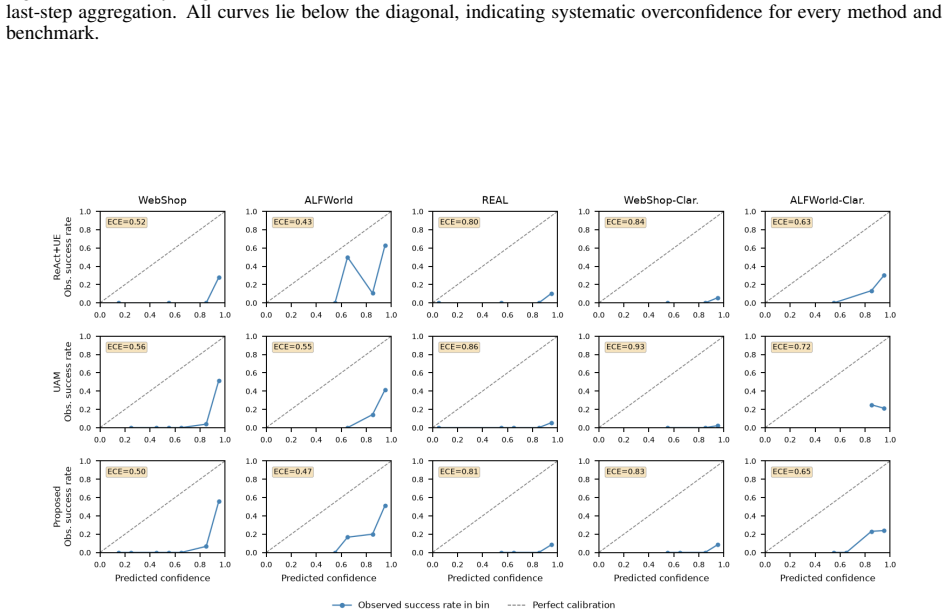
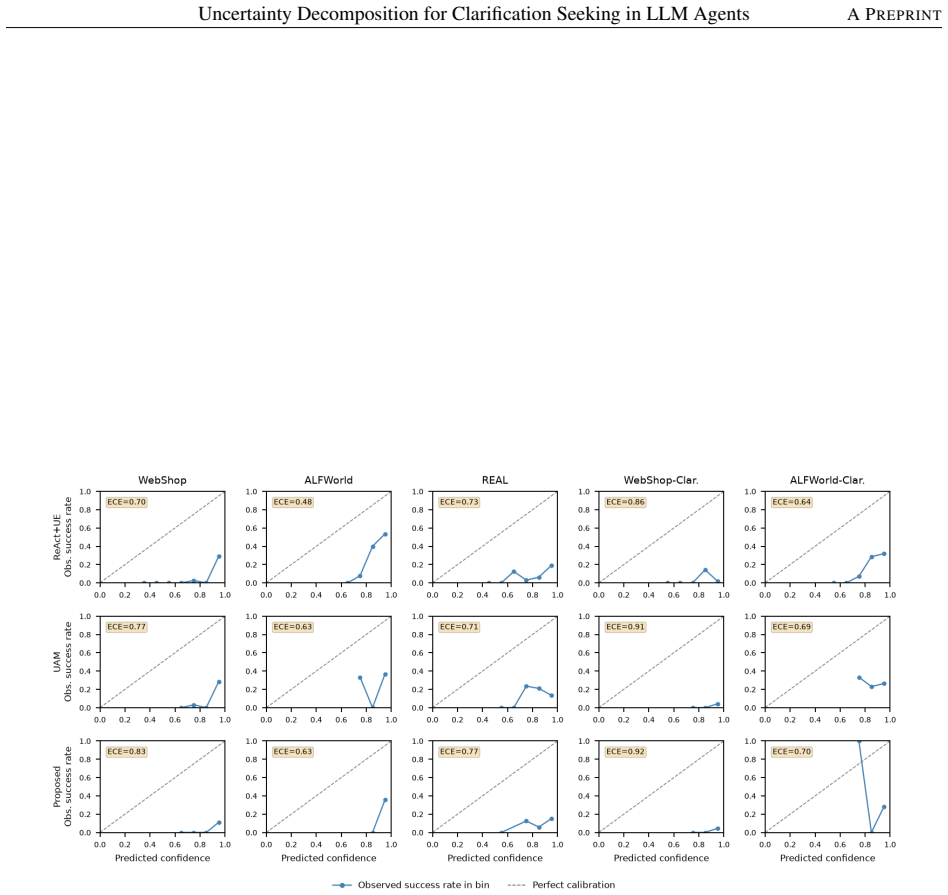
Recent position papers argue that the classical aleatoric/epistemic uncertainty framework is insufficient for interactive large language model (LLM) agents and call for underspecification-aware, decomposed, and communicable uncertainty representations that can unlock new agent capabilities such as proactive clarification seeking and shared mental-model building. Practical deployment constraints -- black-box APIs, interactive latency budgets, and the absence of labeled trajectories -- rule out logprob-based, multi-sampling, and training-based methods, leaving prompt-based estimation as the most viable family for surfacing such signals at deployment time. We answer this call with a simple prompt-based decomposition that separates action confidence from request uncertainty (u), enabling the agent to ask for clarification when the task specification is ambiguous. To evaluate it, we introduce two clarification-augmented benchmarks (WebShop-Clarification and ALFWorld-Clarification) in which 50% of tasks are deliberately underspecified, and systematically compare the proposed decomposition against ReAct+UE and Uncertainty-Aware Memory (UAM) across five LLM backbones (GPT-5.1, DeepSeek-v3.2-exp, GLM-4.7, Qwen3.5-35B, GPT-OSS-120B) on these variants together with the standard WebShop, ALFWorld, and REAL benchmarks for fault detection. Averaged across the five backbones, the proposed decomposition improves clarification F1 on ALFWorld-Clarification by 73% over ReAct+UE and by 36% over UAM, and leads clarification F1 on every backbone on WebShop-Clarification and on four of five backbones on ALFWorld-Clarification, indicating that the gains generalize beyond a single LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a prompt-based uncertainty decomposition for LLM agents that separates action confidence from a request uncertainty signal (u) to support proactive clarification seeking in underspecified tasks. It introduces two new benchmarks (WebShop-Clarification and ALFWorld-Clarification) containing 50% deliberately underspecified tasks and reports that, averaged over five LLM backbones, the decomposition yields 73% higher clarification F1 than ReAct+UE and 36% higher than UAM on ALFWorld-Clarification while leading on WebShop-Clarification and four of five backbones on ALFWorld-Clarification; the same method is also evaluated for fault detection on the original WebShop, ALFWorld, and REAL benchmarks.
Significance. If the empirical gains hold under scrutiny, the work supplies a lightweight, black-box-compatible method for surfacing communicable uncertainty that directly enables a new agent behavior (clarification). The multi-backbone evaluation across GPT-5.1, DeepSeek-v3.2-exp, GLM-4.7, Qwen3.5-35B and GPT-OSS-120B is a positive feature that supports claims of generality beyond a single model family.
major comments (3)
- [Benchmark construction] Benchmark construction (WebShop-Clarification and ALFWorld-Clarification): the central empirical claim rests on tasks in which 50% are deliberately underspecified, yet the manuscript supplies no analysis, user-study comparison, or distributional test showing that the injected ambiguities match the subtlety, frequency, or type of underspecification arising in real user–agent interactions; without this, the reported F1 gains risk being benchmark-specific.
- [Results] Results reporting (clarification F1 tables): averaged improvements of 73% and 36% are stated without per-backbone raw scores, standard deviations or error bars, exact prompt templates, or the decision threshold used to trigger clarification; these omissions make it impossible to verify robustness or reproduce the numbers from the abstract alone.
- [Methods] Methods section on the decomposition: the prompt-based estimator for action confidence versus request uncertainty u is described at a high level but lacks the precise wording of the prompt, the output parsing rule, and any ablation on prompt sensitivity; because the method is entirely prompt-driven, these details are load-bearing for the reproducibility of the claimed gains.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence statement of the exact decision rule that converts the decomposed uncertainty into a clarification action.
- [Tables/Figures] Figure or table captions should explicitly state the number of runs or seeds underlying the averaged F1 scores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (WebShop-Clarification and ALFWorld-Clarification): the central empirical claim rests on tasks in which 50% are deliberately underspecified, yet the manuscript supplies no analysis, user-study comparison, or distributional test showing that the injected ambiguities match the subtlety, frequency, or type of underspecification arising in real user–agent interactions; without this, the reported F1 gains risk being benchmark-specific.
Authors: We agree that explicit validation against real-world distributions strengthens the work. The underspecified tasks were created by targeted removal of attributes (e.g., product specifications in WebShop, goal details in ALFWorld). We will add a dedicated subsection describing the construction procedure and a qualitative distributional comparison to ambiguity patterns in existing agent interaction logs. A controlled user study remains outside current scope. revision: partial
-
Referee: [Results] Results reporting (clarification F1 tables): averaged improvements of 73% and 36% are stated without per-backbone raw scores, standard deviations or error bars, exact prompt templates, or the decision threshold used to trigger clarification; these omissions make it impossible to verify robustness or reproduce the numbers from the abstract alone.
Authors: Per-backbone scores, standard deviations, and the clarification threshold (u > 0.5) appear in the appendix tables and Section 4.1; prompt templates are in Appendix C. We will move the per-backbone breakdown and threshold into the main results section and add an explicit cross-reference in the abstract. revision: yes
-
Referee: [Methods] Methods section on the decomposition: the prompt-based estimator for action confidence versus request uncertainty u is described at a high level but lacks the precise wording of the prompt, the output parsing rule, and any ablation on prompt sensitivity; because the method is entirely prompt-driven, these details are load-bearing for the reproducibility of the claimed gains.
Authors: The exact prompt, parsing rule, and output format are provided in Appendix A. We will insert a prompt-sensitivity ablation (alternative phrasings and resulting F1 variance) into the revised methods section. revision: yes
- Direct user-study comparison of injected ambiguities to real user–agent underspecification distributions
Circularity Check
No circularity: empirical method evaluation on new benchmarks
full rationale
The paper proposes a prompt-based decomposition of uncertainty into action confidence and request uncertainty u, then reports empirical F1 improvements on two author-introduced clarification benchmarks (WebShop-Clarification and ALFWorld-Clarification) against named baselines across five LLM backbones. No equations, fitted parameters, or derivations are present; the central claims are direct performance comparisons on held-out task variants. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The evaluation is therefore self-contained against external benchmark metrics and does not reduce to any input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prompt-based estimation is the most viable family for surfacing underspecification-aware uncertainty at deployment time
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryderet al., “Language models are few-shot learners,” inProc. NeurIPS, 2020, pp. 1877–1901
2020
-
[2]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jianget al., “Training language models to follow instructions with human feedback,” in Proc. NeurIPS, 2022, pp. 27 730–27 744
2022
-
[3]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inProc. NeurIPS, 2022, pp. 24 824–24 837
2022
-
[4]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighanet al., “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[5]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProc. ICLR, 2023
2023
-
[6]
Understanding the planning of LLM agents: A survey,
X. Huang, W. Liu, X. Chen, X. Wang, J. Wang, and H. Dong, “Understanding the planning of LLM agents: A survey,”arXiv preprint arXiv:2402.02716, 2024
Pith/arXiv arXiv 2024
-
[7]
The rise and potential of large language model based agents: A survey,
Z. Xi, W. Chen, X. Guoet al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023
Pith/arXiv arXiv 2023
-
[8]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProc. UIST, 2023, pp. 1–22
2023
-
[9]
Uncertainty propagation on LLM agent,
Q. Zhao, Y . Liu, Z. Gao, E. Chen, and L. Meng, “Uncertainty propagation on LLM agent,” inProc. ACL, 2025, pp. 6064–6073
2025
-
[10]
UProp: Investigating the uncertainty propagation of LLMs in multi-step decision- making,
J. Duan, Y . Sun, L. Maoet al., “UProp: Investigating the uncertainty propagation of LLMs in multi-step decision- making,” inProc. NeurIPS, 2025
2025
-
[11]
Uncertainty in natural language generation: From theory to applications,
J. Baan, W. Aziz, B. Plank, and R. Fernandez, “Uncertainty in natural language generation: From theory to applications,”arXiv preprint arXiv:2307.15703, 2023
arXiv 2023
-
[12]
A survey of uncertainty estimation methods on large language models,
Z. Xia, J. Xu, Y . Zhang, and H. Liu, “A survey of uncertainty estimation methods on large language models,” in Findings of ACL, 2025, pp. 21 381–21 396
2025
-
[13]
Position: Uncertainty quantification needs reassessment for large language model agents,
M. Kirchhof, G. Kasneci, and E. Kasneci, “Position: Uncertainty quantification needs reassessment for large language model agents,” inProc. ICML (Position Paper Track), 2025
2025
-
[14]
Because we have LLMs, we can and should pursue agentic interpretability,
B. Kim, J. Hewitt, N. Nanda, N. Fiedel, and O. Tafjord, “Because we have LLMs, we can and should pursue agentic interpretability,”arXiv preprint arXiv:2506.12152, 2025
arXiv 2025
-
[15]
LM-Polygraph: Uncertainty estimation for language models,
E. Fadeeva, A. Vashurin, A. Tsvigunet al., “LM-Polygraph: Uncertainty estimation for language models,” in Proc. EMNLP: System Demonstrations, 2023, pp. 446–461
2023
-
[16]
Uncertainty quantification in LLM agents: Foundations, emerging challenges, and opportunities,
C. Oh, S. Lim, T. Baeet al., “Uncertainty quantification in LLM agents: Foundations, emerging challenges, and opportunities,”arXiv preprint arXiv:2602.05073, 2026
Pith/arXiv arXiv 2026
-
[17]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” inProc. ICLR, 2023
2023
-
[18]
Uncertainty calibration for tool-using language agents,
H. Liu, Z.-Y . Dou, Y . Wang, N. Peng, and Y . Yue, “Uncertainty calibration for tool-using language agents,” in Findings of EMNLP, 2024, pp. 16 781–16 805
2024
-
[19]
MICE for CATs: Model-internal confidence estimation for calibrating agents with tools,
N. Subramani, J. Eisner, J. Svegliato, B. Van Durme, Y . Su, and S. Thomson, “MICE for CATs: Model-internal confidence estimation for calibrating agents with tools,” inProc. NAACL, 2025, pp. 12 362–12 375
2025
-
[20]
Enhancing uncertainty estimation in LLMs with expectation of aggregated internal belief,
Z. Xiao, D. Dou, B. Xiong, Y . Chen, and G. Chen, “Enhancing uncertainty estimation in LLMs with expectation of aggregated internal belief,”arXiv preprint arXiv:2509.01564, 2025
arXiv 2025
-
[21]
Agentic uncertainty quantification,
J. Zhang, P. K. Choubey, K.-H. Huang, C. Xiong, and C.-S. Wu, “Agentic uncertainty quantification,”arXiv preprint arXiv:2601.15703, 2026
arXiv 2026
-
[22]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” inProc. ICLR, 2023
2023
-
[23]
Detecting hallucinations in large language models using semantic entropy,
S. Farquhar, J. Kossen, L. Kuhn, and Y . Gal, “Detecting hallucinations in large language models using semantic entropy,”Nature, vol. 630, no. 8017, pp. 625–630, 2024
2024
-
[24]
Kernel language entropy: Fine-grained uncertainty quantifi- cation for LLMs from semantic similarities,
A. V . Nikitin, J. Kossen, Y . Gal, and P. Marttinen, “Kernel language entropy: Fine-grained uncertainty quantifi- cation for LLMs from semantic similarities,” inProc. NeurIPS, 2024. 25 Uncertainty Decomposition for Clarification Seeking in LLM AgentsA PREPRINT
2024
-
[25]
Improving uncertainty quantification in large language models via semantic embeddings,
Y . S. Grewal, E. V . Bonilla, and T. D. Bui, “Improving uncertainty quantification in large language models via semantic embeddings,”arXiv preprint arXiv:2410.22685, 2024
arXiv 2024
-
[26]
Generating with confidence: Uncertainty quantification for black-box large language models,
Z. Lin, S. Trivedi, and J. Sun, “Generating with confidence: Uncertainty quantification for black-box large language models,”Trans. Mach. Learn. Res., 2024
2024
-
[27]
Tools in the loop: Quantifying uncertainty of LLM question answering systems that use tools,
P. Lymperopoulos and V . Sarathy, “Tools in the loop: Quantifying uncertainty of LLM question answering systems that use tools,” inProc. AAMAS, 2025, pp. 2645–2647
2025
-
[28]
Decomposing uncertainty for large language models through input clarification ensembling,
B. Hou, Y . Liu, K. Qian, J. Andreas, S. Chang, and Y . Zhang, “Decomposing uncertainty for large language models through input clarification ensembling,” inProc. ICML, vol. 235, 2024, pp. 19 023–19 042
2024
-
[29]
Unsupervised quality estimation for neural machine translation,
M. Fomicheva, S. Sun, L. Yankovskayaet al., “Unsupervised quality estimation for neural machine translation,” Trans. Assoc. Comput. Linguistics, vol. 8, pp. 539–555, 2020
2020
-
[30]
Uncertainty estimation in autoregressive structured prediction,
A. Malinin and M. Gales, “Uncertainty estimation in autoregressive structured prediction,” inProc. ICLR, 2021
2021
-
[31]
Shifting attention to relevance: Towards the predictive uncertainty quantifi- cation of free-form large language models,
J. Duan, H. Cheng, S. Wanget al., “Shifting attention to relevance: Towards the predictive uncertainty quantifi- cation of free-form large language models,” inProc. ACL, 2024, pp. 5050–5063
2024
-
[32]
Towards uncertainty-aware language agent,
J. Han, W. Buntine, and E. Shareghi, “Towards uncertainty-aware language agent,” inFindings of ACL, 2024, pp. 6662–6685
2024
-
[33]
Confidence calibration and rationalization for LLMs via multi-agent deliberation,
R. Yang, D. Rajagopal, S. A. Hayati, B. Hu, and D. Kang, “Confidence calibration and rationalization for LLMs via multi-agent deliberation,” inICLR Workshop on Reliable and Responsible Foundation Models, 2024
2024
-
[34]
BrowseConf: Confidence-guided test-time scaling for web agents,
L. Ou, K. Li, F. Linet al., “BrowseConf: Confidence-guided test-time scaling for web agents,”arXiv preprint arXiv:2510.23458, 2025
arXiv 2025
-
[35]
Rethinking aleatoric and epistemic uncertainty,
F. B. Smith, J. Kossen, E. Trollope, M. van der Wilk, A. Foster, and T. Rainforth, “Rethinking aleatoric and epistemic uncertainty,” inProc. ICML, 2025
2025
-
[36]
Understanding the sources of uncertainty for large language and multimodal models,
Z. Yang, S. Hao, H. Sun, L. Jiang, Q. Gao, Y . Ma, and Z. Hu, “Understanding the sources of uncertainty for large language and multimodal models,” inICLR Workshop, 2025
2025
-
[37]
Structured uncertainty guided clarification for LLM agents,
M. Suri, P. Mathur, N. Lipka, F. Dernoncourt, R. A. Rossi, and D. Manocha, “Structured uncertainty guided clarification for LLM agents,”arXiv preprint arXiv:2511.08798, 2025
Pith/arXiv arXiv 2025
-
[38]
C. Hao, S. Wang, and K. Zhou, “Uncertainty-aware GUI agent: Adaptive perception through component recom- mendation and human-in-the-loop refinement,”arXiv preprint arXiv:2508.04025, 2025
arXiv 2025
-
[39]
DeLLMa: Decision making under uncertainty with large language models,
O. Liu, D. Fu, D. Yogatama, and W. Neiswanger, “DeLLMa: Decision making under uncertainty with large language models,” inProc. ICLR, 2025
2025
-
[40]
PlanU: Large language model reasoning through planning under uncertainty,
Z. Deng, C. Ma, Q. Chenet al., “PlanU: Large language model reasoning through planning under uncertainty,” inProc. NeurIPS, 2025
2025
-
[41]
Agentic uncertainty reveals agentic overconfidence,
J. Kaddour, S. Patel, G. Dovonon, L. Richter, P. Minervini, and M. J. Kusner, “Agentic uncertainty reveals agentic overconfidence,”arXiv preprint arXiv:2602.06948, 2026
arXiv 2026
-
[42]
Enhancing GUI agent with uncertainty-aware self- trained evaluator,
G. Chen, L. Jie, L. Zou, W. Guan, M. Zhang, and L. Nie, “Enhancing GUI agent with uncertainty-aware self- trained evaluator,” inProc. NeurIPS, 2025
2025
-
[43]
WebShop: Towards scalable real-world web interaction with grounded language agents,
S. Yao, H. Chen, J. Yang, and K. Narasimhan, “WebShop: Towards scalable real-world web interaction with grounded language agents,” inProc. NeurIPS, 2022
2022
-
[44]
ALFWorld: Aligning text and embodied environments for interactive learning,
M. Shridhar, X. Yuan, M.-A. Cote, Y . Bisk, A. Trischler, and M. Hausknecht, “ALFWorld: Aligning text and embodied environments for interactive learning,” inProc. ICLR, 2021
2021
-
[45]
REAL: Benchmarking LLM agents on deterministic simulations of real websites,
J. Baek, H.-Y . Ha, J. Haet al., “REAL: Benchmarking LLM agents on deterministic simulations of real websites,” arXiv preprint arXiv:2504.11543, 2025
arXiv 2025
-
[46]
Evaluation and benchmarking of LLM agents: A survey,
M. Mohammadi, Y . Li, J. Lo, and W. Yip, “Evaluation and benchmarking of LLM agents: A survey,” inProc. KDD, 2025, pp. 6129–6139
2025
-
[47]
Addressing pitfalls in the evaluation of uncer- tainty estimation methods for natural language generation,
M. Ielanskyi, K. Schweighofer, L. Aichberger, and S. Hochreiter, “Addressing pitfalls in the evaluation of uncer- tainty estimation methods for natural language generation,” inICLR Workshop, 2025. 26
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.