Token Factory: Efficiently Integrating Diverse Signals into Large Recommendation Models
Pith reviewed 2026-06-26 18:47 UTC · model grok-4.3
The pith
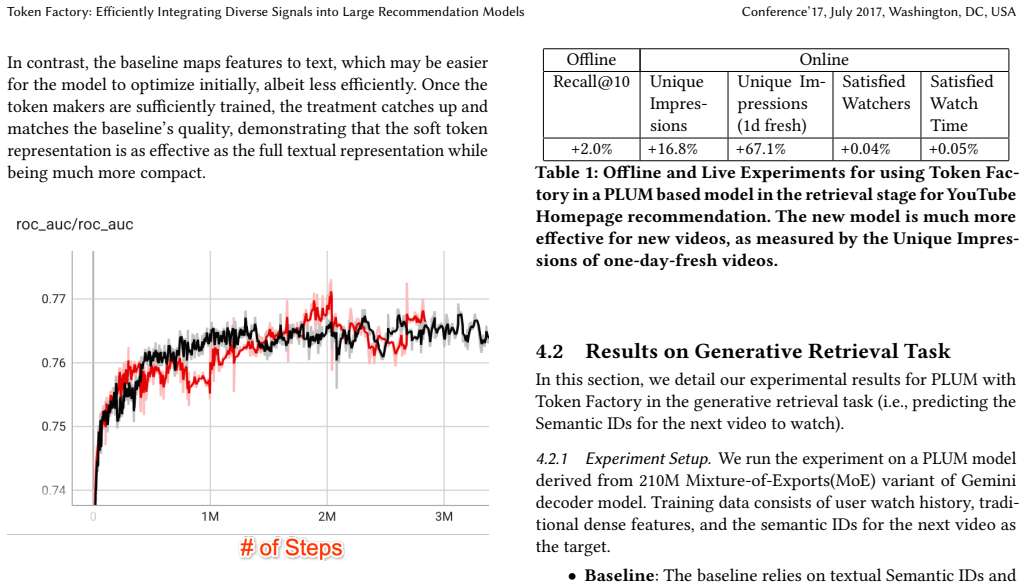
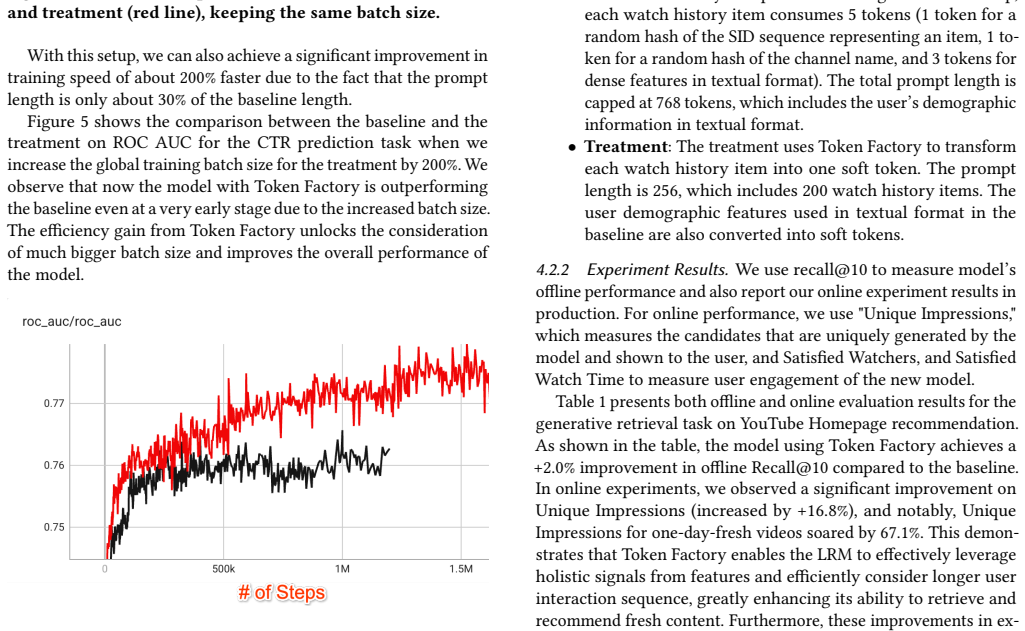
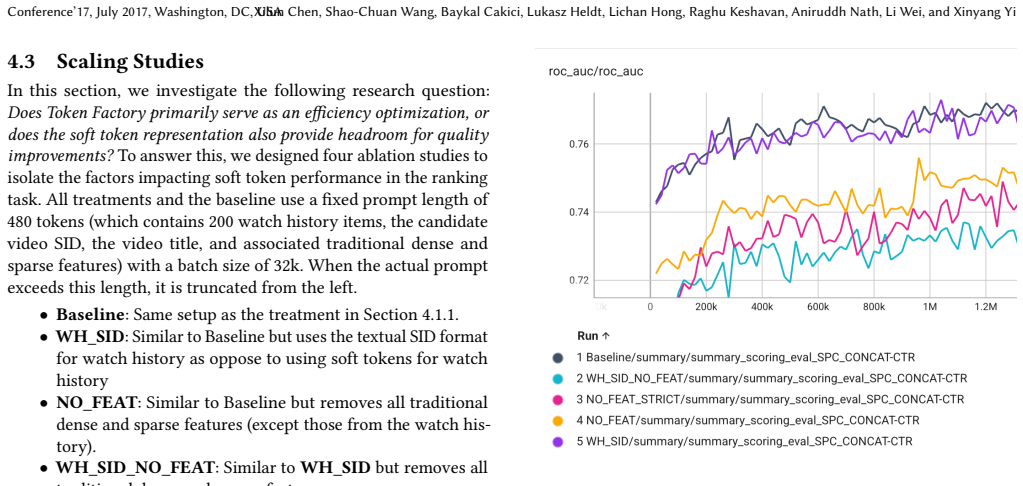
Token Factory converts traditional recommendation signals into soft tokens that large models process directly without long prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Token Factory is a framework that transforms traditional signals into soft tokens that Large Recommendation Models can consume directly, enabling efficient integration and compression of heterogeneous input features while avoiding prompt length explosion.
What carries the argument
Token Factory, the module that generates soft tokens from heterogeneous signals for direct insertion into the LRM input stream.
If this is right
- Memory footprint and compute per inference drop because prompt length stays bounded.
- More varied input signals can be added without forcing the model context window to grow.
- End-to-end training becomes feasible for signals that previously required separate feature stores.
- Production deployment cost decreases while recommendation metrics improve.
Where Pith is reading between the lines
- The same soft-token conversion could be applied to non-recommendation transformers that currently ingest external structured data as text.
- If the soft tokens are learned end-to-end, the method might reduce the need for manual feature engineering pipelines.
- Scaling the number of input signal types becomes mainly a question of how many soft-token slots the model can afford rather than prompt length limits.
Load-bearing premise
Converting signals into soft tokens keeps enough of the original information for the model to use it without meaningful loss.
What would settle it
A side-by-side production run where models trained with Token Factory soft tokens show no accuracy gain or higher error than the same models using direct textualization of the same signals.
Figures





read the original abstract
Large Recommendation Models (LRMs) have demonstrated promising capabilities in industry-scale recommendation tasks. However, holistically integrating traditional signals into these transformer-based architectures effectively and efficiently remains a major challenge. Conventional approaches that "textualize" these signals directly or create discrete item representations often lead to excessively long prompts, substantial memory footprints, and high computational overhead. To overcome these limitations, we propose "Token Factory", a framework designed to transform traditional signals into "soft tokens" that can be directly processed by LRMs. This approach enables efficient integration and compression of heterogeneous input features, preventing prompt length explosion while enhancing model performance. We detail the architecture of Token Factory and present experimental results validating its effectiveness in a production-scale recommendation environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Token Factory, a framework that transforms traditional recommendation signals into soft tokens for direct processing by Large Recommendation Models (LRMs). It claims this enables efficient integration and compression of heterogeneous features, prevents prompt length explosion, and enhances performance, with validation from experimental results in a production-scale environment.
Significance. If the soft-token compression demonstrably preserves signal information and the production experiments isolate gains from faithful integration rather than added capacity, the approach could provide a scalable method for incorporating diverse traditional signals into transformer-based LRMs without prohibitive prompt growth.
major comments (2)
- [Abstract] Abstract: The claim that 'experimental results validating its effectiveness in a production-scale recommendation environment' is presented without any description of methods, baselines, metrics, datasets, or ablation studies. This is load-bearing for the central claim, as the asserted performance enhancement and information-preserving compression cannot be assessed from the given text.
- [Abstract] Abstract: No mechanism, reconstruction loss, mutual-information estimate, or control experiment (e.g., comparison to random embeddings of equal dimensionality) is described to verify that soft tokens retain sufficient information from the original heterogeneous signals rather than the observed gains arising from additional trainable parameters inside the factory.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract's claims require additional context to be fully assessable and will revise it accordingly while preserving conciseness. The full manuscript contains the detailed experimental sections referenced in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'experimental results validating its effectiveness in a production-scale recommendation environment' is presented without any description of methods, baselines, metrics, datasets, or ablation studies. This is load-bearing for the central claim, as the asserted performance enhancement and information-preserving compression cannot be assessed from the given text.
Authors: We acknowledge the abstract is brief and does not enumerate experimental details. The full manuscript includes dedicated experimental sections describing the production-scale setup, baselines, metrics, datasets, and ablations. We will revise the abstract to add a concise high-level summary of these elements (e.g., key metrics and scale) so the central claim can be evaluated from the abstract alone. revision: yes
-
Referee: [Abstract] Abstract: No mechanism, reconstruction loss, mutual-information estimate, or control experiment (e.g., comparison to random embeddings of equal dimensionality) is described to verify that soft tokens retain sufficient information from the original heterogeneous signals rather than the observed gains arising from additional trainable parameters inside the factory.
Authors: The abstract does not describe verification mechanisms. The manuscript's architecture section explains how Token Factory produces soft tokens via learned transformations of heterogeneous signals, with performance gains demonstrated through controlled experiments in the results section. We will add a brief clause to the abstract referencing the training objective and comparative controls used to isolate the contribution of the soft-token compression from added capacity. revision: yes
Circularity Check
No circularity; engineering proposal with external experimental validation.
full rationale
The paper proposes Token Factory as a framework to convert signals into soft tokens for LRMs, supported by production-scale experiments. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. The central claim rests on empirical results rather than any self-referential reduction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
soft tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2018.JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018.JAX: composable transformations of Python+NumPy programs. http://github.com/google/jax
2018
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al . 2025. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 247–256
2025
- [3]
-
[4]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al
- [5]
-
[6]
Peiyu Hu, Wayne Lu, and Jia Wang. 2026. From ids to semantics: A generative framework for cross-domain recommendation with adaptive semantic tokeniza- tion. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 14874–14882
2026
- [7]
- [8]
-
[9]
Haohao Qu, Wenqi Fan, Zihuai Zhao, and Qing Li. 2025. Tokenrec: Learning to tokenize id for llm-based generative recommendations.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[10]
Zihua Si, Zhongxiang Sun, Jiale Chen, Guozhang Chen, Xiaoxue Zang, Kai Zheng, Yang Song, Xiao Zhang, Jun Xu, and Kun Gai. 2024. Generative retrieval with semantic tree-structured identifiers and contrastive learning. InProceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific...
2024
-
[11]
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, Ed Chi, and Xinyang Yi. 2024. Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24). Association fo...
2024
-
[12]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. In International Conference on Machine Learning (ICML)
2024
-
[13]
Qiang Zhang, Hanchao Yu, Ivan Ji, Chen Yuan, Yi Zhang, Chihuang Liu, Xiaolong Wang, Christopher E Lambert, Ren Chen, Chen Kovacs, et al . 2025. Efficient Sequential Recommendation for Long Term User Interest Via Personalization. In 2025 IEEE International Conference on Data Mining (ICDM). IEEE, 913–922
2025
-
[14]
Da-Wei Zhou, Hai-Long Sun, Jingyi Ning, Han-Jia Ye, and De-Chuan Zhan
- [15]
- [16]
- [17]
-
[18]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
2025
-
[19]
Yanyan Zou, Junbo Qi, Lunsong Huang, Yu Li, Kewei Xu, Jiabao Gao, Binglei Zhao, Xuanhua Yang, Sulong Xu, and Shengjie Li. 2026. GenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation. InSIRIG. A Soft Tokens Attention Visualization To better understand the behavioral differences between models uti- lizing soft tokens and those us...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.