Think Again or Think Longer? Selective Verification for Budget-Aware Reasoning
Pith reviewed 2026-06-26 17:51 UTC · model grok-4.3
The pith
Selective verification matches or beats always-on verification accuracy while cutting tokens, though longer initial solves often win on total cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
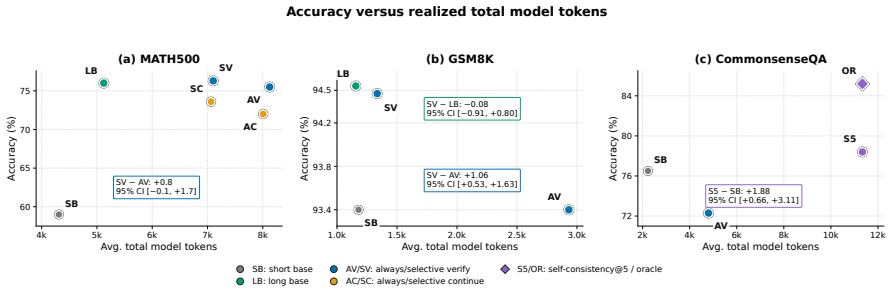
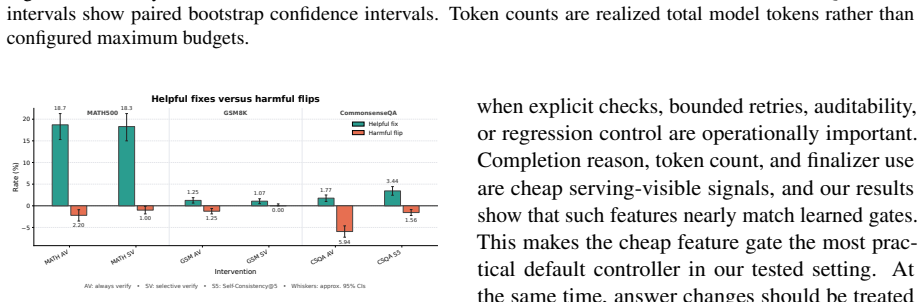
SEVRA is a serving-layer controller that trains recoverability-aware gates on serving-visible attempt state to decide whether to keep a frozen Qwen3-4B solver's initial answer or invoke verification. On MATH-500 this yields 76.3 percent accuracy versus 75.5 percent for always verifying, 26.8 percent fewer post-generation tokens, and harmful flips reduced from 2.2 percent to 1.0 percent. On GSM it verifies only 3.0 percent of examples to raise accuracy from 93.4 percent to 94.5 percent while cutting verification tokens by 91.2 percent. An 8192-token initial solve reaches 76.0 percent accuracy with 28 percent fewer total model tokens. On CommonsenseQA always-on verification hurts accuracy.
What carries the argument
Recoverability-aware gates trained from logged intervention outcomes on serving-visible attempt state of a frozen solver, deciding whether verification will improve the answer.
If this is right
- Selective verification reduces harmful answer changes from 2.2 percent to 1.0 percent on MATH-500.
- On GSM the selective policy verifies only 3.0 percent of examples while raising accuracy.
- Always-on verification reduces accuracy on CommonsenseQA.
- Self-Consistency at 5 improves accuracy but at roughly five times the realized token cost of selective verification.
- An 8192-token initial solve reaches similar accuracy to selective verification with 28 percent fewer total tokens.
Where Pith is reading between the lines
- Initial solve length and verification decisions should be optimized jointly rather than sequentially.
- Selective recovery is most useful in deployments that require explicit audit trails or bounded regression risk.
- If initial budgets can be tuned per example, selective verification may be triggered rarely.
- Verification can be net harmful on tasks where the solver is already reliable.
Load-bearing premise
Gates trained on recoverability outcomes from one frozen solver and set of logged examples will predict recovery success accurately on new problems without retraining.
What would settle it
On a new dataset the selective policy either verifies more than half the cases with no accuracy gain over always verifying, or a longer initial solve consistently uses more total tokens than the selective route.
Figures

read the original abstract
Test-time reasoning is increasingly used as a serving-time control knob, but extra reasoning is not uniformly valuable: it can repair failed attempts, waste compute on already-correct answers, or introduce harmful answer changes. We study this as a deployment allocation problem rather than a new-verifier problem. We introduce \sevra, Selective Verification for Reasoning Allocation, a serving-layer controller that decides whether to preserve a frozen solver's initial answer or invoke active verification. Using a frozen Qwen3-4B solver, we log intervention outcomes and train recoverability-aware gates from serving-visible attempt state. On \mathfive, selective verification reaches 76.3\% accuracy, compared with 75.5\% for always verifying, while reducing post-generation tokens by 26.8\% and harmful flips from 2.2\% to 1.0\%. However, an 8,192-token initial solve reaches 76.0\% accuracy with 28\% fewer total model tokens, showing that selective recovery is useful but not the best tested cost frontier. In frozen transfer to \gsm, the selective policy verifies only 3.0\% of examples, improves accuracy from 93.4\% to 94.5\%, and reduces verification tokens by 91.2\% relative to always verifying; again, a longer initial solve matches its accuracy with fewer realized tokens. On CommonsenseQA, always-on verification hurts, while Self-Consistency@5 improves accuracy at about five times the realized token cost. The resulting deployment rule is: tune the initial budget first, then use selective recovery when explicit checks, bounded retries, auditability, or regression-risk control matter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SEVRA, a serving-layer controller for budget-aware test-time reasoning. With a frozen Qwen3-4B solver, it logs intervention outcomes to train recoverability-aware gates that decide whether to preserve the initial answer or invoke verification. On MATH-500, selective verification achieves 76.3% accuracy (vs. 75.5% for always verifying) while cutting post-generation tokens by 26.8% and harmful flips from 2.2% to 1.0%. Frozen transfer to GSM verifies only 3% of examples, raising accuracy from 93.4% to 94.5% with 91.2% fewer verification tokens. On CommonsenseQA always-on verification hurts accuracy. The paper concludes that the initial solve budget should be tuned first, with selective recovery used when auditability or regression control is required. An 8192-token initial solve reaches 76.0% accuracy with 28% fewer total tokens than the selective policy.
Significance. If the recoverability gates generalize reliably, the work supplies a concrete deployment rule for allocating compute between longer initial generation and selective verification. The explicit comparisons to always-verify, longer initial solves, and Self-Consistency@5, together with the reported token and flip reductions, make the result actionable for practitioners. The emphasis on frozen solvers and serving-visible state is a practical strength.
major comments (2)
- [Abstract] Abstract and experimental results: the headline 0.8-point accuracy gain on MATH-500 (76.3% vs 75.5%) and the 26.8% token reduction are presented without error bars, number of runs, or dataset splits. Because the central claim is that selective verification is superior to always verifying, the absence of these statistics makes it impossible to judge whether the observed difference is statistically reliable or could be explained by sampling variation.
- [Transfer to GSM] Transfer experiments: the GSM transfer reports only 3% verification rate and a 1.1-point accuracy lift, but provides no gate-level metrics (precision, recall, or calibration of the recoverability predictor) on the held-out distribution. Without these, it is difficult to confirm that the gates avoid both missed recoveries and harmful flips on new tasks, which is load-bearing for the generalization claim.
minor comments (2)
- [Abstract] Notation: the manuscript uses \sevra and \mathfive without an explicit expansion on first use; a short parenthetical definition would improve readability.
- [MATH-500 results] The claim that 'an 8,192-token initial solve reaches 76.0% accuracy with 28% fewer total model tokens' would benefit from an explicit table comparing total tokens across all policies rather than scattered numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on statistical reporting and transfer evaluation. We address each major comment below and indicate the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: the headline 0.8-point accuracy gain on MATH-500 (76.3% vs 75.5%) and the 26.8% token reduction are presented without error bars, number of runs, or dataset splits. Because the central claim is that selective verification is superior to always verifying, the absence of these statistics makes it impossible to judge whether the observed difference is statistically reliable or could be explained by sampling variation.
Authors: We agree that the absence of run counts and variability measures weakens the ability to assess the reliability of the 0.8-point accuracy difference. The MATH-500 results were obtained from a single run owing to the computational cost of the Qwen3-4B model. In the revision we will (1) state explicitly that all reported figures are from a single run, (2) specify the standard MATH-500 test split, and (3) qualify the accuracy comparison while underscoring that the 26.8% post-generation token reduction is a deterministic outcome of the selective policy rather than a sampled quantity. revision: yes
-
Referee: [Transfer to GSM] Transfer experiments: the GSM transfer reports only 3% verification rate and a 1.1-point accuracy lift, but provides no gate-level metrics (precision, recall, or calibration of the recoverability predictor) on the held-out distribution. Without these, it is difficult to confirm that the gates avoid both missed recoveries and harmful flips on new tasks, which is load-bearing for the generalization claim.
Authors: We acknowledge that precision, recall, and calibration statistics on the GSM distribution would provide stronger evidence for the frozen gate's behavior. These per-gate metrics were not computed for the transfer experiments. In the revision we will expand the transfer section to highlight the observed 3% verification rate and 1.1-point accuracy gain as direct empirical outcomes, while explicitly noting the lack of gate-level diagnostics as a limitation of the current analysis. revision: partial
- Gate-level metrics (precision, recall, calibration) for the recoverability predictor on the GSM held-out distribution, which were not computed in the original experiments and cannot be supplied without additional analysis.
Circularity Check
No circularity; empirical training and evaluation are independent of claimed outcomes
full rationale
The paper logs intervention outcomes on a frozen Qwen3-4B solver, trains recoverability-aware gates from serving-visible state, and reports measured accuracy/token savings on MATH-500 (76.3% vs 75.5%), GSM transfer, and CommonsenseQA. No derivation step equates a result to its inputs by construction, renames a fit as a prediction, or relies on self-citation for a uniqueness theorem. The central deployment rule follows directly from the empirical comparisons rather than tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- recoverability gate parameters
axioms (1)
- domain assumption Serving-visible attempt state from the frozen solver provides sufficient signal to predict whether verification will improve the answer.
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Learning Representations, volume 2024, pages 39578–39601
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Qianli Ma, Haotian Zhou, Tingkai Liu, Jianbo Yuan, Pengfei Liu, Yang You, and Hongxia Yang. 2023. Let’s reward step by step: Step-level reward model as the navigators for reasoning.arXiv preprint arXiv:2310.10080. Aman Madaan, Niket Tandon, P...
arXiv 2024
-
[2]
arXiv preprint arXiv:2509.20368
Latts: Locally adaptive test-time scaling. arXiv preprint arXiv:2509.20368. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei ...
arXiv 2022
-
[3]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
-
[4]
Zhiyuan Zhai, Bingcong Li, Bingnan Xiao, Ming Li, and Xin Wang
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Zhiyuan Zhai, Bingcong Li, Bingnan Xiao, Ming Li, and Xin Wang. 2026. Adaptive test-time compute allocation for reasoning llms via constrained policy optimization.arXiv preprint arXiv:2604.14853. Andy Zhou, Kai Yan, Mi...
Pith/arXiv arXiv 2026
-
[5]
Verification or a longer initial budget often recovers it
Truncated derivation: the base request reaches its token limit before exposing a fi- nal answer. Verification or a longer initial budget often recovers it
-
[6]
Candidate-specific verifica- tion can repair it
Local arithmetic or algebra error: the base attempt completes but contains a checkable operation error. Candidate-specific verifica- tion can repair it
-
[7]
This produces a harmful flip
Incorrect reinterpretation: a post- generation call replaces a correct answer after inventing an error or changing the problem interpretation. This produces a harmful flip
-
[8]
Shared misconception: the base and verifica- tion calls agree on the same wrong derivation. Additional calls do not help because the fail- ure is correlated. Active verification is particularly useful for the first two categories. Selective routing reduces exposure to the third, but does not solve the fourth. K Negative Results and Design Decisions Contin...
-
[9]
Finalization Parseable base answer Finalizer overuse, finalizer changing a completed answer, answer-format mismatch
every evaluated policy selects at most one final answer per example; Stage Output Failure mode checked Base solve Base trace, answer, usage Solver truncation, missing final answer, unexpectedly empty output. Finalization Parseable base answer Finalizer overuse, finalizer changing a completed answer, answer-format mismatch. Intervention Action trace, answe...
-
[10]
accept policies never consume action tokens
-
[11]
selective policies consume action tokens only above threshold
-
[12]
These invariants keep accuracy, token, and flip com- parisons aligned
all paired comparisons use the same example set. These invariants keep accuracy, token, and flip com- parisons aligned. S Reproduction Commands and File Map The exact repository layout may differ in an anony- mous release, but the experiments are organized around four command families:
-
[13]
generate logged recovery rows for each action and shard
-
[14]
merge shards and remove incomplete example-action sets
-
[15]
train/export gate scores and thresholded poli- cies
-
[16]
think harder
summarize tables, figures, paired tests, and the replay dashboard. Minimal reproducibility recipe.A minimal in- dependent reproduction does not require retrain- ing every gate. It can start from released recovery JSONL files, verify row completeness, compute base/always/selective/long-base policies, and re- generate the paper tables. Full reproduction add...
2019
-
[17]
Log realized prompt and generation tokens, completion reason, finalizer calls, retries, la- tency, and answer changes
-
[18]
A larger limit may reduce realized cost by avoiding truncation
Tune the initial reasoning budget and compare multiple maximum limits. A larger limit may reduce realized cost by avoiding truncation
-
[19]
Do not assume continuation, critique, and verification are interchangeable
Screen candidate recovery actions on logged failures. Do not assume continuation, critique, and verification are interchangeable
-
[20]
Train or configure a gate only after establish- ing that the chosen action has useful fix-to-flip behavior
-
[21]
Compare the gate against cheap observable signals and matched-rate random or heuristic baselines. Diagnostic Question answered How to compute it Desired interpretation Truncation-only policy Is the gate merely a length-stop detector? Verify only examples with length-limit termination; compare to the full gate at the same example set. If full gate improves...
-
[22]
Report accuracy, helpful fixes, harmful flips, intervention rate, action cost, total cost, and attempt-state subgroups
-
[23]
Without it, post-generation selectiv- ity may appear more efficient than it is
Preserve a long-base baseline in the final com- parison. Without it, post-generation selectiv- ity may appear more efficient than it is. Z Extended Industry Implications Set the initial budget before adding a controller. On both math benchmarks, the long initial solve lies on the best tested cost–accuracy frontier. A practical deployment should therefore ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.