Gaussian Process Prior Variational Autoencoder for Endoscopic Videos
Pith reviewed 2026-06-26 18:00 UTC · model grok-4.3
The pith
A temporal Gaussian process prior in a variational autoencoder improves restoration of corrupted endoscopic videos by modeling frame continuity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
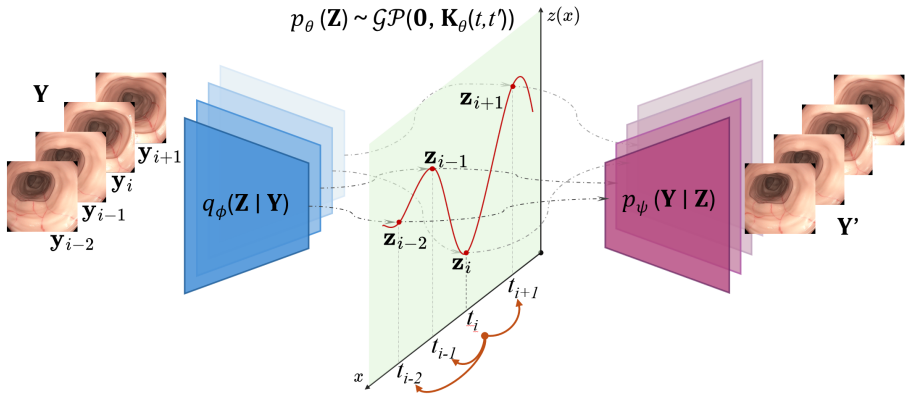
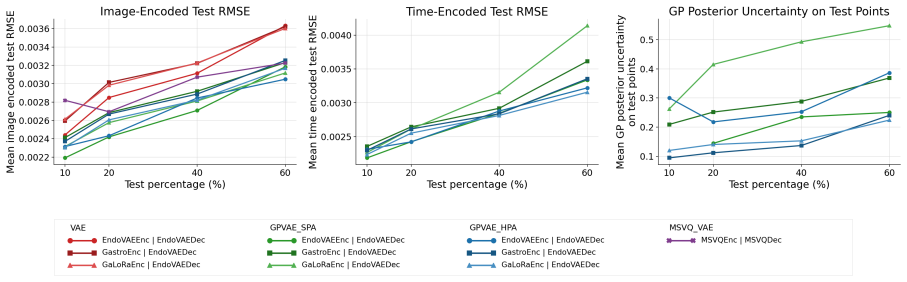
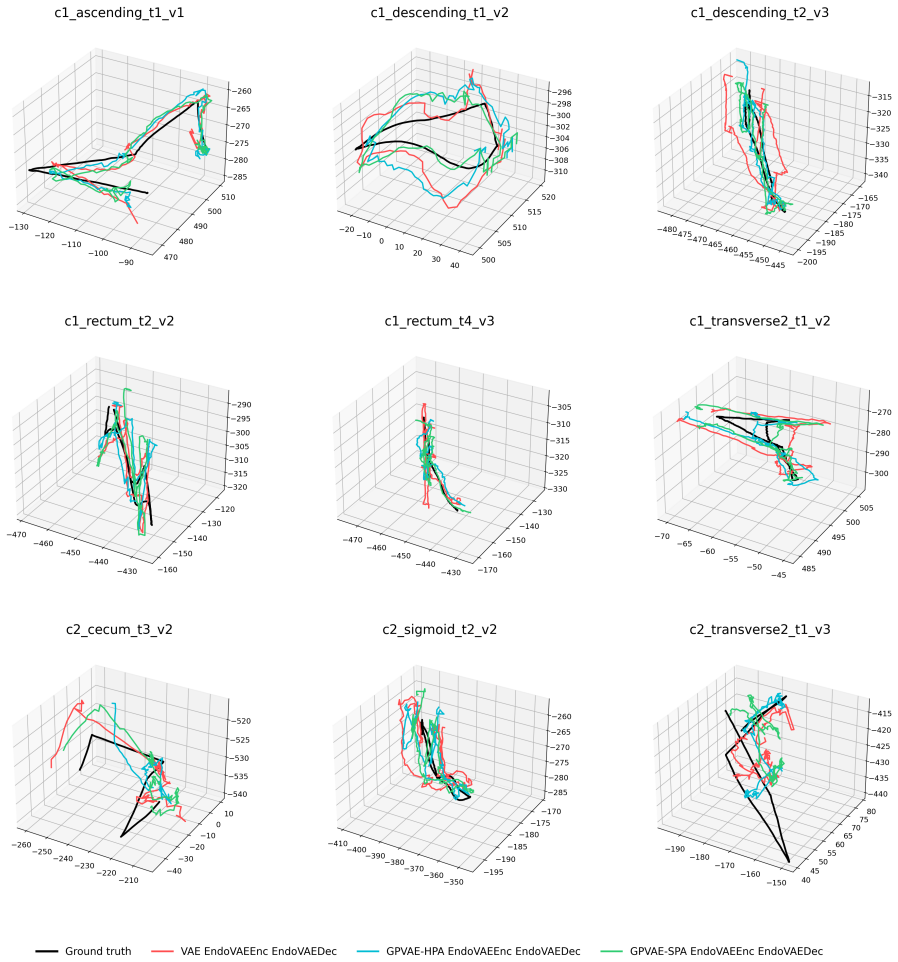
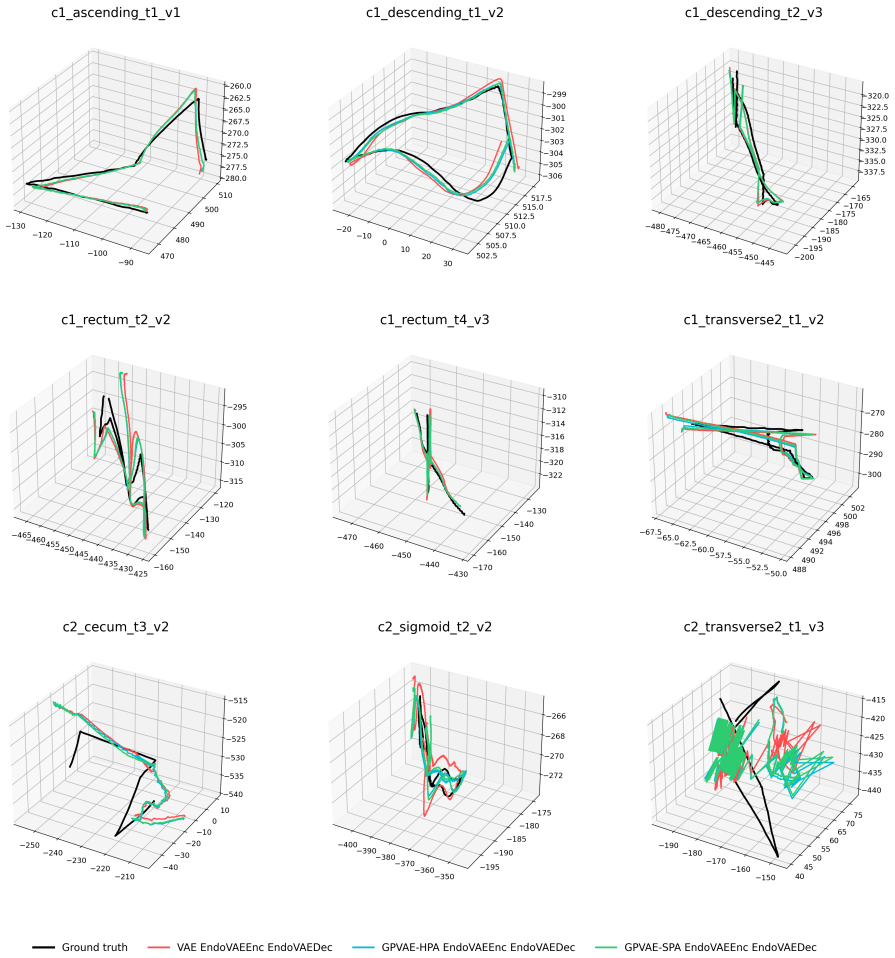
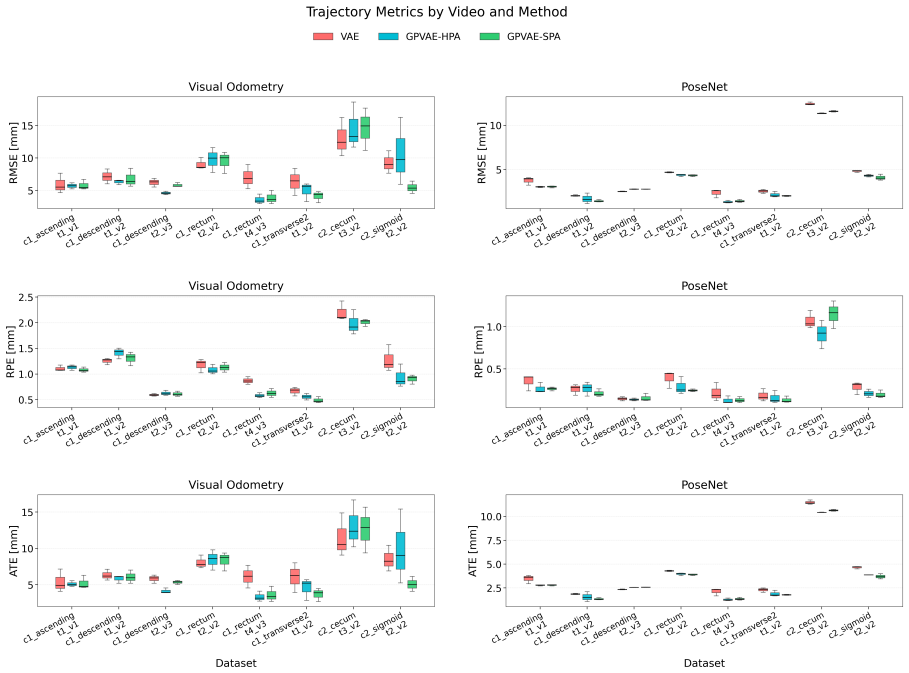
The GPVAE framework replaces the standard factorized latent prior with a temporal Gaussian process prior, enabling interpolation of missing frames with uncertainty-aware reconstruction in endoscopic videos. Endoscopy-specific encoders are paired with Hierarchical Prior Approximation or Sparse Precision Approximation for scalability, and DUCKNet masking excludes specular reflections from the loss. On the C3VDv2 dataset the best variants reduce image reconstruction RMSE by 21.9 percent on average and up to 26.1 percent relative to matched VAE baselines, while lowering downstream trajectory RMSE by 12.7 percent on average.
What carries the argument
The temporal Gaussian process prior placed on the latent variables of the variational autoencoder, which enforces continuity across time and is made tractable by Hierarchical Prior Approximation or Sparse Precision Approximation.
If this is right
- Missing frames can be interpolated using information from neighboring frames rather than treated independently.
- Each restored frame receives an uncertainty value that tracks how much temporal support is available.
- Downstream tasks such as visual odometry and pose estimation show lower trajectory error when fed the restored videos.
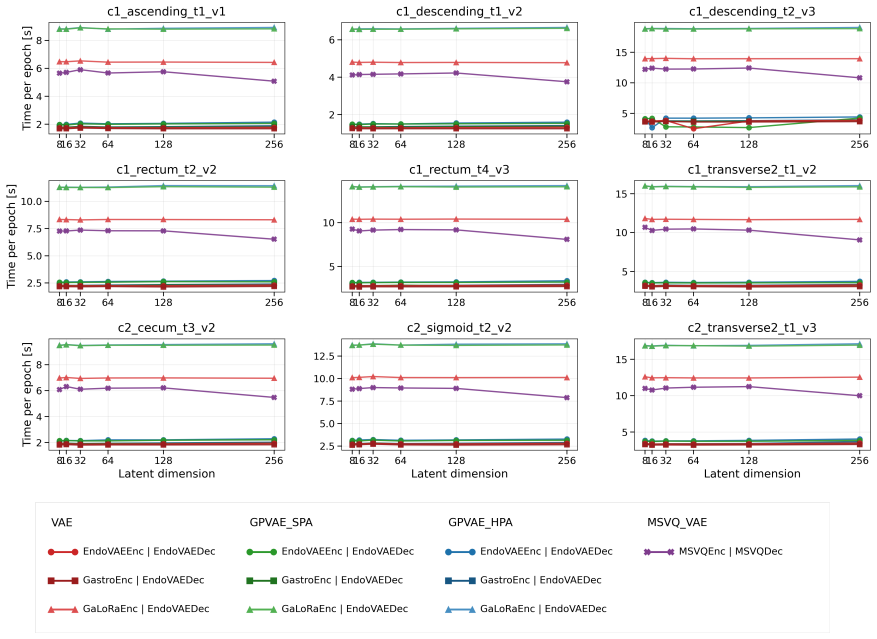
- Training requires roughly 27 percent more time per epoch because of the added Gaussian process computations.
Where Pith is reading between the lines
- The same temporal prior structure could be tested on other sequential medical imaging data such as ultrasound or fluoroscopy sequences.
- The per-frame uncertainty values might serve as a filter to flag low-confidence restorations for extra clinician review.
- Extending the model to jointly handle multiple artifact types without separate masking stages would be a direct next measurement.
Load-bearing premise
Endoscopic video dynamics are well captured by a temporal Gaussian process prior that can be approximated scalably while the masking step correctly removes corrupted pixels from the reconstruction objective.
What would settle it
If standard VAEs using the same encoders and masking achieve equal or lower RMSE on the C3VDv2 dataset than the GPVAE variants, the claimed benefit of the temporal Gaussian process prior would be falsified.
Figures

read the original abstract
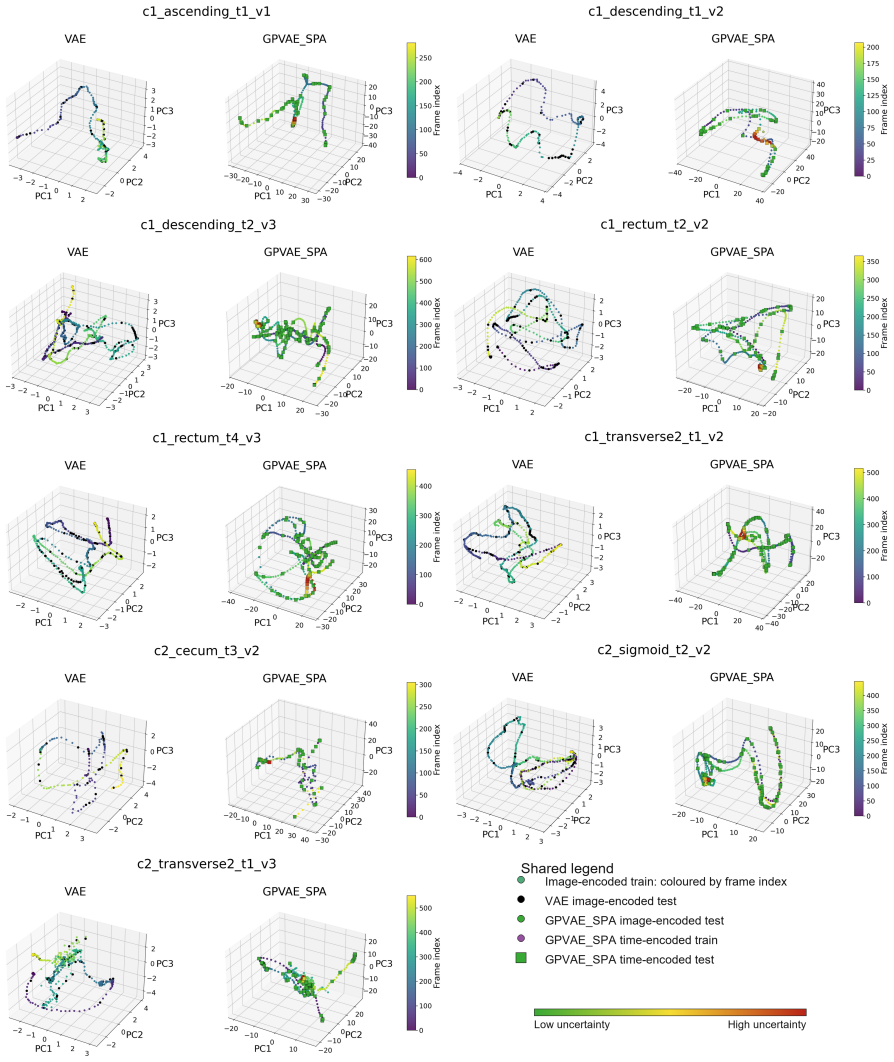
Endoscopic video analysis is essential for gastrointestinal diagnosis and computer-assisted interventions, but video sequences are routinely degraded by specular reflections, motion artifacts, and missing frames. These transient corruptions can distract clinicians, reduce image interpretability, and disrupt downstream tasks such as 3D reconstruction and navigation. Effective restoration therefore requires methods that exploit temporal continuity rather than treating frames in isolation. We introduce a Gaussian Process Prior Variational Autoencoder (GPVAE) framework for endoscopic video restoration that replaces the standard factorized latent prior with a temporal Gaussian process prior, enabling interpolation of missing frames with uncertainty-aware reconstruction. The framework combines endoscopy-specific encoders, including a convolutional EndoVAE backbone and pretrained Vision Transformer encoders from GastroNet-5M, with two scalable GP approximations: Hierarchical Prior Approximation (HPA) and Sparse Precision Approximation (SPA). Specular reflections are handled using a DUCKNet-based masking pipeline that excludes corrupted pixels from the reconstruction objective. On the C3VDv2 colonoscopy dataset, the best GPVAE variants reduced image reconstruction RMSE by 21.9\% on average, and by up to 26.1\%, relative to matched VAE baselines. Downstream trajectory RMSE was reduced by 12.7\% on average across classical visual odometry and a pretrained PoseNet, at an average increase of 27.3\% in training time per epoch. Finally, the GP posterior provides per-frame uncertainty estimates that reflect temporal support and offer a confidence signal for restored frames.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a Gaussian Process Prior Variational Autoencoder (GPVAE) for endoscopic video restoration. It replaces the factorized latent prior of standard VAEs with a temporal Gaussian process prior, using Hierarchical Prior Approximation (HPA) and Sparse Precision Approximation (SPA) for scalability, combined with DUCKNet-based masking to exclude specular reflections from the reconstruction loss. Experiments on the C3VDv2 colonoscopy dataset report that the best GPVAE variants achieve an average 21.9% (up to 26.1%) reduction in image reconstruction RMSE relative to matched VAE baselines, plus a 12.7% average reduction in downstream trajectory RMSE across visual odometry and PoseNet, at a 27.3% increase in per-epoch training time. The GP posterior is also shown to yield per-frame uncertainty estimates reflecting temporal support.
Significance. If the reported RMSE reductions are robust, the work demonstrates a practical way to incorporate temporal continuity and uncertainty quantification into VAE-based restoration for degraded endoscopic videos, which could improve reliability in downstream tasks like 3D reconstruction and navigation. The explicit use of scalable GP approximations and endoscopy-specific encoders (EndoVAE, GastroNet-5M) is a strength for applicability; the downstream evaluation further strengthens the case for utility beyond pixel-level metrics.
major comments (2)
- [§4.2] §4.2 (Scalable GP Approximations), around Eq. (8)–(11): The central claim attributes the 21.9% RMSE reduction to the temporal GP prior structure, yet no ablation or small-scale comparison to an exact GP implementation is provided to confirm that HPA and SPA preserve the intended covariance and uncertainty propagation without introducing artifacts that could explain the gains versus the factorized VAE baselines.
- [Table 2] Table 2 (Quantitative results on C3VDv2): The headline 21.9% average and 26.1% peak RMSE reductions, as well as the 12.7% trajectory improvement, are reported without error bars, standard deviations across runs, or statistical significance tests; this weakens confidence that the improvements are reliably attributable to the GP prior rather than dataset variability or baseline configuration details.
minor comments (2)
- [§3.4] The description of the DUCKNet masking pipeline in §3.4 would benefit from an explicit statement of how masked pixels affect the ELBO gradient computation.
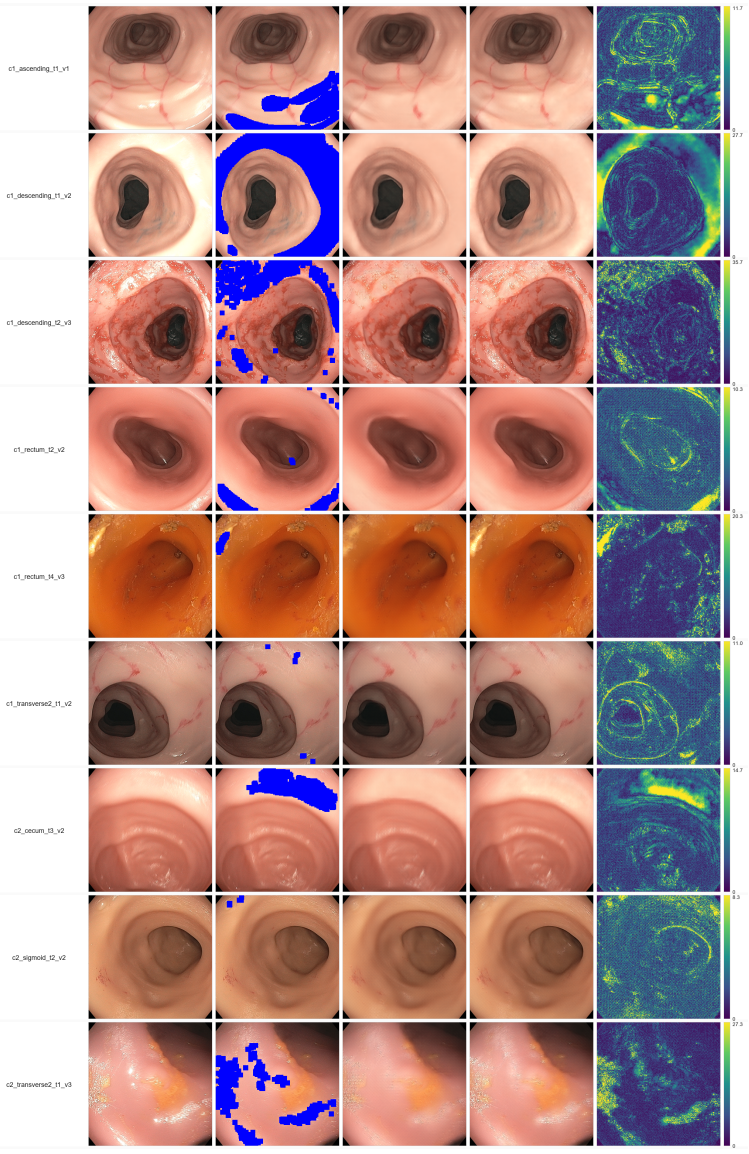
- [Figure 3] Figure 3 (uncertainty visualization) lacks a quantitative correlation between the reported per-frame uncertainty and actual reconstruction error on held-out frames.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the GP approximations and result reporting. We address each major comment below.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Scalable GP Approximations), around Eq. (8)–(11): The central claim attributes the 21.9% RMSE reduction to the temporal GP prior structure, yet no ablation or small-scale comparison to an exact GP implementation is provided to confirm that HPA and SPA preserve the intended covariance and uncertainty propagation without introducing artifacts that could explain the gains versus the factorized VAE baselines.
Authors: We agree that a direct comparison to exact GP inference would strengthen the validation. However, exact GP methods incur O(N^3) complexity, rendering them computationally infeasible for the long video sequences in C3VDv2. HPA and SPA are established scalable approximations from the GP literature that are designed to preserve the key covariance properties and uncertainty propagation of the exact GP; their theoretical fidelity is documented in the cited works. The performance gains over factorized VAE baselines, together with the per-frame uncertainty estimates that reflect temporal support, indicate that the improvements arise from the temporal GP structure rather than approximation artifacts. In revision we will expand the discussion in §4.2 to elaborate on these theoretical properties and prior empirical validations of HPA/SPA. revision: partial
-
Referee: [Table 2] Table 2 (Quantitative results on C3VDv2): The headline 21.9% average and 26.1% peak RMSE reductions, as well as the 12.7% trajectory improvement, are reported without error bars, standard deviations across runs, or statistical significance tests; this weakens confidence that the improvements are reliably attributable to the GP prior rather than dataset variability or baseline configuration details.
Authors: This is a valid point regarding statistical robustness. The reported figures come from single training runs owing to the substantial computational cost of the full experimental suite. We will perform additional runs with different random seeds to compute standard deviations, add error bars to Table 2, and include statistical significance tests in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical gains are direct comparisons to matched baselines
full rationale
The paper's central claim is an empirical performance improvement on the C3VDv2 dataset when a temporal GP prior (approximated via HPA/SPA) replaces the standard factorized VAE prior, with DUCKNet masking. No equations, self-citations, or uniqueness theorems are presented that reduce the reported RMSE reductions (21.9% average, 26.1% max) or trajectory improvements to quantities defined by the fitted parameters themselves or to prior self-authored results. The derivation chain consists of standard VAE ELBO maximization with an added GP structure whose effect is measured against explicitly matched VAE controls; the approximations are presented as implementation choices whose fidelity is not claimed to be exact but whose net effect is evaluated externally. This is self-contained against the dataset benchmarks and does not exhibit self-definitional, fitted-input-renamed-as-prediction, or load-bearing self-citation patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Endoscopic video sequences exhibit sufficient temporal continuity to be modeled by a Gaussian process prior despite specular reflections and motion artifacts.
Reference graph
Works this paper leans on
-
[1]
2000 , booktitle =
Rasmussen, Carl and Ghahramani, Zoubin , editor =. 2000 , booktitle =
2000
-
[2]
2021 , booktitle =
Jazbec, Metod and Ashman, Matt and Fortuin, Vincent and Pearce, Michael and Mandt, Stephan and R. 2021 , booktitle =
2021
-
[3]
Kou, Wenjun and Carlson, Dustin A. and Baumann, Alexandra J. and Donnan, Erica and Luo, Yuan and Pandolfino, John E. and Etemadi, Mozziyar , volume =. 2021 , journal =. doi:10.1016/j.artmed.2020.102006 , issn =
-
[4]
Vedaei, Seyed Shahim and Wahid, Khan A. , number =. 2021 , journal =. doi:10.1038/s41598-021-90523-w , issn =
-
[5]
Xu, Y. and Chen, R. and Zhang, P. and Chen, L. and Luo, B. and Li, Y. and Xiao, X. and Dong, W. , number =. 2022 , booktitle =. doi:10.5194/isprs-archives-XLVI-3-W1-2022-219-2022 , issn =
work page doi:10.5194/isprs-archives-xlvi-3-w1-2022-219-2022 2022
-
[6]
Han, Kai and Wang, Yunhe and Chen, Hanting and Chen, Xinghao and Guo, Jianyuan and Liu, Zhenhua and Tang, Yehui and Xiao, An and Xu, Chunjing and Xu, Yixing and Yang, Zhaohui and Zhang, Yiman and Tao, Dacheng , number =. 2023 , journal =. doi:10.1109/TPAMI.2022.3152247 , issn =
-
[7]
Ferreira, Vanessa M. and Piechnik, Stefan K. , number =. 2020 , booktitle =. doi:10.4070/KCJ.2020.0157 , issn =
-
[8]
and Aichinger, Philipp , number =
Dadras, Armin A. and Aichinger, Philipp , number =. 2024 , journal =. doi:10.3390/bioengineering11050443 , issn =
-
[9]
Bajhaiya, Deepak and Unni, Sujatha Narayanan and Koushik, A. K. , number =. 2023 , journal =. doi:10.1016/j.igie.2023.08.002 , issn =
-
[10]
Deep Residual Learning for Image Recognition
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , volume =. 2016 , booktitle =. doi:10.1109/CVPR.2016.90 , issn =
-
[11]
2025 , journal =
Kanaan, Muzaffer and Suveren, Memduh , doi =. 2025 , journal =
2025
-
[12]
2024 , author =. doi:10.1007/978-3-031-72089-5
-
[13]
Yu, Zhangyuan and Du, Chenlin and Liang, Hongrui and Zheng, Xiuqi and Ma, Zeyao and Wu, Mingjun and Ao, Mingwu and Lao, Qicheng , volume =. 2026 , booktitle =. doi:10.1007/978-3-032-05127-1
-
[14]
Atasoy, Selen and Mateus, Diana and Meining, Alexander and Yang, Guang Zhong and Navab, Nassir , number =. 2012 , journal =. doi:10.1109/TMI.2011.2174252 , issn =
-
[15]
and Gatoula, Panagiota and Iakovidis, Dimitris K
Diamantis, Dimitrios E. and Gatoula, Panagiota and Iakovidis, Dimitris K. , doi =. 2022 , booktitle =
2022
-
[16]
Bati. 2024 , journal =. doi:10.1007/s11548-024-03091-5 , issn =
-
[17]
Wang, Zhao and Liu, Chang and Zhang, Shaoting and Dou, Qi , volume =. 2023 , booktitle =. doi:10.1007/978-3-031-43996-4
-
[18]
Boers, Tim G W and Fockens, Kiki N and van der Putten, Joost A and Jaspers, Tim J M and Kusters, Carolus H J and Jukema, Jelmer B and Jong, Martijn R and Struyvenberg, Maarten R and de Groof, Jeroen and Bergman, Jacques J and de With, Peter H N and van der Sommen, Fons , pages =. 2024 , journal =. doi:https://doi.org/10.1016/j.media.2024.103298 , issn =
-
[19]
Zhang, Yi and Mao, Yiji and Lu, Xuanyu and Zou, Xingyu and Huang, Hao and Li, Xinyang and Li, Jiayue and Zhang, Haixian , number =. 2024 , journal =. doi:10.1007/s10462-024-10762-x , issn =
-
[20]
Jong, Martijn R. and Boers, Tim G.W. and Fockens, Kiki N. and Jukema, Jelmer B. and Kusters, Carolus H.J. and Jaspers, Tim J.M. and van Eijck van Heslinga, Rixta A.H. and Slooter, Floor C. and Struyvenberg, Maarten R. and Bisschops, Raf and van der Putten, Joost A. and de With, Peter H.N. and van der Sommen, Fons and de Groof, Albert J. and Bergman, Jacqu...
-
[21]
and Saglietti, Luca and Listgarten, Jennifer and Fusi, Nicolo , volume =
Casale, Francesco Paolo and Dalca, Adrian V. and Saglietti, Luca and Listgarten, Jennifer and Fusi, Nicolo , volume =. 2018 , booktitle =
2018
-
[22]
2006 , booktitle =
Rasmussen, Carl Edward and Williams, C K I , number =. 2006 , booktitle =
2006
-
[23]
Fujii, Kenko and Gras, Gauthier and Salerno, Antonino and Yang, Guang Zhong , volume =. 2018 , journal =. doi:10.1016/j.media.2017.11.011 , issn =
-
[24]
Wang, Zhao and Liu, Chang and Zhu, Lingting and Wang, Tongtong and Zhang, Shaoting and Dou, Qi , number =. 2025 , journal =. doi:10.1109/JBHI.2025.3532311 , issn =
-
[25]
and Ishii, Masaru and Taylor, Russell H
Li, David Z. and Ishii, Masaru and Taylor, Russell H. and Hager, Gregory D. and Sinha, Ayushi , volume =. 2020 , booktitle =. doi:10.1007/978-3-030-60946-7
-
[26]
Umeyama, Shinji , number =. 1991 , journal =. doi:10.1109/34.88573 , issn =
-
[27]
Masked Autoencoders in Computer Vision: A Comprehensive Survey,
Zhou, Zexian and Liu, Xiaojing , volume =. 2023 , journal =. doi:10.1109/ACCESS.2023.3323383 , issn =
-
[28]
Assran, Mahmoud and Caron, Mathilde and Misra, Ishan and Bojanowski, Piotr and Bordes, Florian and Vincent, Pascal and Joulin, Armand and Rabbat, Mike and Ballas, Nicolas , volume =. 2022 , booktitle =. doi:10.1007/978-3-031-19821-2
-
[29]
2025 , booktitle =
Shi, Xinxing and Jiang, Xiaoyu and. 2025 , booktitle =
2025
-
[30]
Ye, Menglong and Giannarou, Stamatia and Meining, Alexander and Yang, Guang Zhong , volume =. 2016 , journal =. doi:10.1016/j.media.2015.10.003 , issn =
-
[31]
Spitieris, Michail and Ruocco, Massimiliano and Murad, Abdulmajid and Nocente, Alessandro , number =. 2025 , journal =. doi:10.1007/s10489-025-06776-9 , issn =
-
[32]
Kendall, Alex and Grimes, Matthew and Cipolla, Roberto , pages =. 2015 , booktitle =. doi:10.1109/ICCV.2015.336 , keywords =
-
[33]
Ren, Xinzhen and Zhou, Wenju and Yuan, Naitong and Li, Fang and Ruan, Yetian and Zhou, Huiyu , volume =. 2025 , journal =. doi:10.1016/j.media.2025.103510 , issn =
-
[34]
Jaspers, Tim J.M. and de Jong, Ronald L.P.D. and Li, Yiping and Kusters, Carolus H.J. and Bakker, Franciscus H.A. and van Jaarsveld, Romy C. and Kuiper, Gino M. and van Hillegersberg, Richard and Ruurda, Jelle P. and Brinkman, Willem M. and Pluim, Josien P.W. and de With, Peter H.N. and Breeuwer, Marcel and Al Khalil, Yasmina and van der Sommen, Fons , vo...
-
[35]
Hirsch, Roy and Caron, Mathilde and Cohen, Regev and Livne, Amir and Shapiro, Ron and Golany, Tomer and Goldenberg, Roman and Freedman, Daniel and Rivlin, Ehud , volume =. 2023 , booktitle =. doi:10.1007/978-3-031-43904-9
-
[36]
Daher, Rema and Vasconcelos, Francisco and Stoyanov, Danail , number =. 2025 , journal =. doi:10.1007/s11548-025-03371-8 , issn =
-
[37]
2026 , journal =
Shen, Wenting and Wang, Yaonan and Liu, Min and Wang, Jiazheng and Ding, Renjie , doi =. 2026 , journal =
2026
-
[38]
URLhttps://doi.org/10.1109/ ISBI48211.2021.9434010
Mathew, Shawn and Nadeem, Saad and Kaufman, Arie , volume =. 2021 , booktitle =. doi:10.1109/ISBI48211.2021.9433982 , issn =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.