PhysDrift: Bridging the Embodiment Gap in Humanoid Co-Speech Motion Generation
Pith reviewed 2026-06-26 17:29 UTC · model grok-4.3
The pith
Generating co-speech motions directly in humanoid joint space bridges the embodiment gap from human retargeting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Embodiment-aware robot-native generation maintains consistency throughout training and inference by directly predicting humanoid joint trajectories from speech, without intermediate human-body representations, and incorporates physical regularization to stabilize dynamics.
What carries the argument
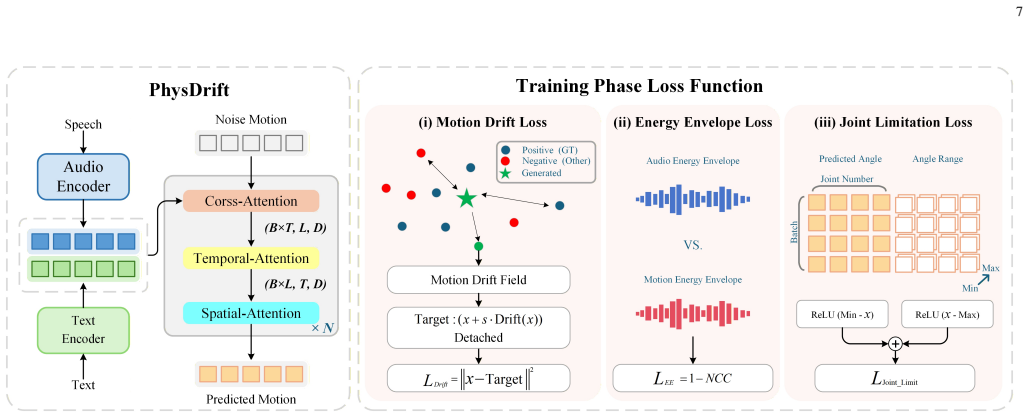
PhysDrift, the framework that directly maps speech to executable humanoid joint trajectories while enforcing embodiment consistency and physical regularization.
Load-bearing premise
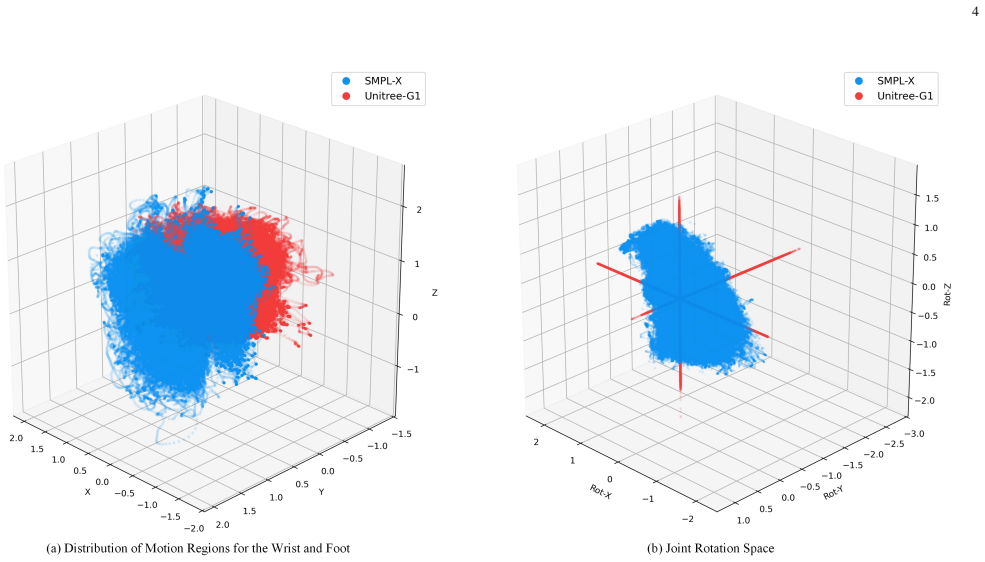
The main cause of poor humanoid co-speech performance is the mismatch between human motion manifolds and robot constraints during retargeting.
What would settle it
An experiment on a physical humanoid where a retargeted human-centric baseline matches or exceeds PhysDrift on speech-motion alignment, physical plausibility, and smoothness metrics would falsify the central claim.
Figures

read the original abstract
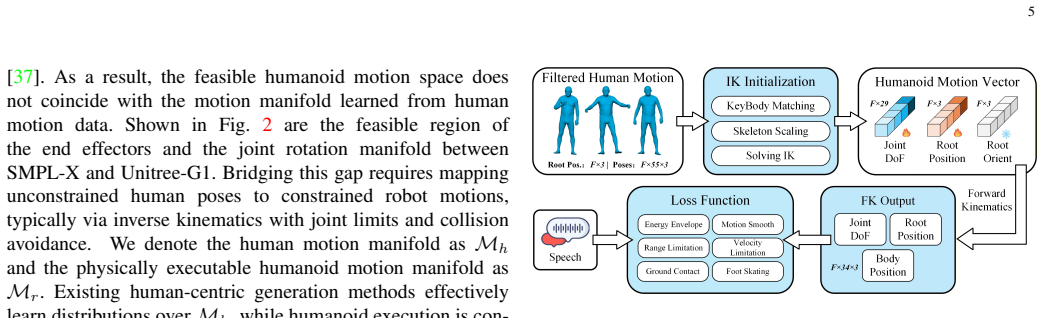
Humanoid robots require co-speech motions that are not only expressive and speech-aligned, but also physically executable under embodiment constraints. Existing co-speech generation pipelines are predominantly human-centric: motions are first generated in human-body representations such as SMPL-X and subsequently retargeted to humanoid robots. In this work, we identify a fundamental embodiment gap in this paradigm, where the mismatch between human motion manifolds and humanoid embodiment constraints disrupts embodiment consistency during motion transfer and physical execution. Through extensive analysis, we show that although retargeting can preserve coarse motion semantics, it significantly compresses motion diversity and weakens prosody-motion synchronization, limiting expressive humanoid behaviors. To address this problem, we first propose IK-EER, a prosody-preserving humanoid motion curation framework that jointly optimizes kinematic feasibility and speech-motion temporal alignment during retargeting. Building upon the curated robot-native motion dataset, we further introduce PhysDrift, an embodiment-aware co-speech motion generation framework that directly predicts executable humanoid joint trajectories from speech without relying on intermediate human-body representations. Unlike conventional human-centric pipelines, PhysDrift maintains embodiment consistency throughout both training and inference while incorporating physical regularization to stabilize robot motion dynamics. Extensive experiments and real-world humanoid deployment demonstrate that embodiment-aware robot-native generation substantially improves speech-motion alignment, physical plausibility, motion smoothness, inference efficiency, and real-time interaction capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that human-centric co-speech motion pipelines for humanoids suffer from an embodiment gap: retargeting from SMPL-X compresses motion diversity and weakens prosody synchronization. It introduces IK-EER, a curation method that jointly optimizes kinematic feasibility and speech-motion alignment to produce a robot-native dataset, and PhysDrift, a direct speech-to-robot-joint generator that incorporates physical regularization to maintain embodiment consistency. The abstract states that extensive experiments plus real-world humanoid deployment show substantial gains in speech-motion alignment, physical plausibility, smoothness, inference efficiency, and real-time capability.
Significance. If the empirical isolation of the robot-native component holds, the result would be significant for humanoid robotics: it offers a concrete alternative to the dominant retargeting paradigm and demonstrates deployable real-time performance. The explicit real-world deployment is a positive strength that grounds the claims beyond simulation.
major comments (1)
- [Abstract] Abstract: the central claim that 'embodiment-aware robot-native generation substantially improves...' requires that the gains arise from bypassing the human manifold rather than from IK-EER curation or the added physical regularization. No ablation is described that holds speech features, model capacity, and the IK-EER step fixed while varying only the human-intermediate versus direct robot-native path; without this comparison the embodiment-gap diagnosis is not isolated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the source of performance gains. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'embodiment-aware robot-native generation substantially improves...' requires that the gains arise from bypassing the human manifold rather than from IK-EER curation or the added physical regularization. No ablation is described that holds speech features, model capacity, and the IK-EER step fixed while varying only the human-intermediate versus direct robot-native path; without this comparison the embodiment-gap diagnosis is not isolated.
Authors: We appreciate the referee's emphasis on rigorous isolation. Section 3 provides an independent analysis showing that standard retargeting from SMPL-X compresses motion diversity and weakens prosody synchronization even before any generative model is applied; this establishes the embodiment gap in the human-centric paradigm. Our experiments then compare full pipelines: human-centric baselines (SMPL-X generation + conventional retargeting) versus PhysDrift (direct prediction on the IK-EER-curated robot-native dataset with physical regularization). The regularization is an integral component of maintaining embodiment consistency during direct training and inference, not an orthogonal add-on. An ablation that applies IK-EER to human-generated motions to create a matched 'human-intermediate' dataset would deviate from the dominant retargeting practice we critique and is therefore not performed. We will add a clarifying paragraph in the revised experiments section and adjust the abstract wording to more precisely attribute gains to the combination of robot-native data and direct embodiment-aware modeling. revision: partial
Circularity Check
No significant circularity; derivation self-contained with no fitted inputs or self-citation reductions
full rationale
The provided abstract and manuscript description introduce IK-EER curation and PhysDrift generation as new frameworks without any equations, fitted parameters, or predictions that reduce to inputs by construction. No self-citations appear as load-bearing for uniqueness theorems, ansatzes, or renamings. The central claims rest on proposed methods and external experiments rather than self-referential definitions, satisfying the criteria for a self-contained derivation against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Edurobot: Intelligent humanoid robot with natural interaction for ed- ucation and entertainment,
W. Budiharto, A. D. Cahyani, P. C. Rumondor, and D. Suhartono, “Edurobot: Intelligent humanoid robot with natural interaction for ed- ucation and entertainment,”Procedia Computer Science, vol. 116, pp. 564–570, 2017. 1
2017
-
[2]
The dual role of humanoid robots in education: As didactic tools and social actors,
S. Ekstr ¨om and L. Pareto, “The dual role of humanoid robots in education: As didactic tools and social actors,”Educ. Inf. Technol., vol. 27, no. 9, pp. 12 609–12 644, 2022. 1
2022
-
[3]
Humanoid robot–assisted support for health care in older adults: Systematic scoping review,
L. Cui, Y . Li, X. Yang, X. Liu, L. Zhang, and L. Hou, “Humanoid robot–assisted support for health care in older adults: Systematic scoping review,”JMIR Aging, vol. 9, p. e83849, 2026. 1
2026
-
[4]
Advancing remote healthcare using humanoid and affective systems,
U. Tripathi, R. S. J, V . Chamola, A. Jolfaei, and A. Chintanpalli, “Advancing remote healthcare using humanoid and affective systems,” IEEE Sens. J., vol. 22, no. 18, pp. 17 606–17 614, 2022. 1
2022
-
[5]
Joint recon- figuration after failure for performing emblematic gestures in humanoid receptionist robot,
W. Jutharee, B. Kaewkamnerdpong, and T. Maneewarn, “Joint recon- figuration after failure for performing emblematic gestures in humanoid receptionist robot,”Sensors, vol. 23, no. 22, p. 9277, 2023. 1
2023
-
[6]
Livegesture: Streamable co-speech gesture generation model,
M. U. Saleem, M. J. Patel, E. Pinyoanuntapong, Z. Qin, L. Yang, H. Xue, A. Helmy, C. Chen, and P. Wang, “Livegesture: Streamable co-speech gesture generation model,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., (CVPR), Denver, Colorado, USA, Jun, 2026, pp. 2264–2273. 1
2026
-
[7]
Coordspeaker: Exploiting gesture captioning for coordinated caption-empowered co-speech gesture gen- eration,
F. Fang, S. Yang, and W. Yang, “Coordspeaker: Exploiting gesture captioning for coordinated caption-empowered co-speech gesture gen- eration,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., (CVPR), Denver, Colorado, USA, Jun, 2026, pp. 30 761–30 771. 1
2026
-
[8]
Unitracker: Learning universal whole-body motion tracker for humanoid robots,
K. Yin, W. Zeng, K. Fan, M. Dai, Z. Wang, Q. Zhang, Z. Tian, J. Wang, J. Pang, and W. Zhang, “Unitracker: Learning universal whole-body motion tracker for humanoid robots,”IEEE Rob. Autom. Lett., vol. 11, no. 7, pp. 8124–8131, 2026. 1
2026
-
[9]
Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li, “Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,” inProc. Adv. neural inf. proces. syst., (NeurIPS), San Diego, CA, USA, 2025, pp. 62 406–62 433. 1, 9
2025
-
[10]
Expressive body capture: 3d hands, face, and body from a single image,
G. Pavlakos, V . Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3d hands, face, and body from a single image,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., (CVPR), Long Beach, CA, USA, Jun, 2019, pp. 10 975–10 985. 1
2019
-
[11]
ECHO: edge-cloud humanoid orchestration for language-to- motion control,
H. Jia, J. Song, Y . Zhang, H. Jin, Y . Fan, W. Chen, W. Zhang, and Y . Yue, “ECHO: edge-cloud humanoid orchestration for language-to- motion control,”arXiv preprint arXiv:2603.16188, 2026. 1
arXiv 2026
-
[12]
Gesturelsm: Latent short- cut based co-speech gesture generation with spatial-temporal modeling,
P. Liu, L. Song, J. Huang, H. Liu, and C. Xu, “Gesturelsm: Latent short- cut based co-speech gesture generation with spatial-temporal modeling,” inProc. IEEE Int. Conf. Comput. Vis., (ICCV). Honolulu, HI, USA: IEEE, Oct, 2025, pp. 10 929–10 939. 1, 8, 9, 11
2025
-
[13]
BEAT: A large-scale semantic and emotional multi- modal dataset for conversational gestures synthesis,
H. Liu, Z. Zhu, N. Iwamoto, Y . Peng, Z. Li, Y . Zhou, E. Bozkurt, and B. Zheng, “BEAT: A large-scale semantic and emotional multi- modal dataset for conversational gestures synthesis,” inProc. Eur . Conf. Comput. Vis., (ECCV), Tel Aviv, Israel, Oct. 2022, pp. 612–630. 3
2022
-
[14]
EMAGE: towards unified holistic co-speech gesture generation via expressive masked audio ges- ture modeling,
H. Liu, Z. Zhu, G. Becherini, Y . Peng, M. Su, Y . Zhou, X. Zhe, N. Iwamoto, B. Zheng, and M. J. Black, “EMAGE: towards unified holistic co-speech gesture generation via expressive masked audio ges- ture modeling,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., (CVPR), Seattle, W A, USA, Jun. 2024, pp. 1144–1154. 3, 4, 8, 9
2024
-
[15]
Zeroeggs: Zero-shot example-based gesture generation from speech,
S. Ghorbani, Y . Ferstl, D. Holden, N. F. Troje, and M. Carbonneau, “Zeroeggs: Zero-shot example-based gesture generation from speech,” Comput. Graph. F orum, vol. 42, no. 1, pp. 206–216, 2023. 3
2023
-
[16]
Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation,
A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, “Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation,”ACM Trans. Graph., vol. 37, no. 4, p. 112, 2018. 3
2018
-
[17]
Speech gesture generation from the trimodal context of text, audio, and speaker identity,
Y . Yoon, B. Cha, J. Lee, M. Jang, J. Lee, J. Kim, and G. Lee, “Speech gesture generation from the trimodal context of text, audio, and speaker identity,”ACM Trans. Graph., vol. 39, no. 6, pp. 222:1–222:16, 2020. 3
2020
-
[18]
HOP: heterogeneous topology-based multimodal entanglement for co-speech gesture gener- ation,
H. Cheng, T. Wang, G. Shi, Z. Zhao, and Y . Fu, “HOP: heterogeneous topology-based multimodal entanglement for co-speech gesture gener- ation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., (CVPR), Nashville, TN, USA, Jun, 2025, pp. 906–916. 3
2025
-
[19]
Semges: Semantics- aware co-speech gesture generation using semantic coherence and relevance learning,
L. Liu, E. Ghaleb, A. Ozyurek, and Z. Yumak, “Semges: Semantics- aware co-speech gesture generation using semantic coherence and relevance learning,” inProc. IEEE Int. Conf. Comput. Vis., (ICCV), Honolulu, Hawaii, USA, Oct, 2025, pp. 13 963–13 973. 3
2025
-
[20]
Didiffges: Decou- pled semi-implicit diffusion models for real-time gesture generation from speech,
Y . Cheng, S. Huang, X. Chen, J. Ning, and M. Gong, “Didiffges: Decou- pled semi-implicit diffusion models for real-time gesture generation from speech,” inProc. AAAI Conf. Artif. Intell., (AAAI), T. Walsh, J. Shah, and Z. Kolter, Eds., Philadelphia, PA, USA, Mar, 2025, pp. 2464–2472. 3
2025
-
[21]
Mo- tioncraft: Crafting whole-body motion with plug-and-play multimodal controls,
Y . Bian, A. Zeng, X. Ju, X. Liu, Z. Zhang, W. Liu, and Q. Xu, “Mo- tioncraft: Crafting whole-body motion with plug-and-play multimodal controls,” inProc. AAAI Conf. Artif. Intell., (AAAI), T. Walsh, J. Shah, and Z. Kolter, Eds., Philadelphia, PA, USA, Mar, 2025, pp. 1880–1888. 3
2025
-
[22]
Biped walking pattern generation by using preview control of zero-moment point,
S. Kajita, F. Kanehiro, K. Kaneko, K. Fujiwara, K. Harada, K. Yokoi, and H. Hirukawa, “Biped walking pattern generation by using preview control of zero-moment point,” inProc. IEEE Int. Conf. Robot. Autom., (ICRA), Taipei, Taiwan, China, Sep, 2003, pp. 1620–1626. 3
2003
-
[23]
Optimization based full body control for the atlas robot,
S. Feng, E. C. Whitman, X. Xinjilefu, and C. G. Atkeson, “Optimization based full body control for the atlas robot,” inIEEE-RAS Int. Conf. Humanoid Rob., Madrid, Spain, Nov, 2014, pp. 120–127. 3
2014
-
[24]
Time parameterization of humanoid-robot paths,
W. Suleiman, F. Kanehiro, E. Yoshida, J. Laumond, and A. Monin, “Time parameterization of humanoid-robot paths,”IEEE Trans. Robot., vol. 26, no. 3, pp. 458–468, 2010. 3
2010
-
[25]
Optimal whole- body motion planning of humanoids in cluttered environments,
H. T. Kalidindi, A. Balachandran, and S. V . Shah, “Optimal whole- body motion planning of humanoids in cluttered environments,”Robotics Auton. Syst., vol. 118, pp. 263–277, 2019. 3
2019
-
[26]
Task-relevant roadmaps: A framework for humanoid motion planning,
M. F. Stollenga, L. Pape, M. Frank, J. Leitner, A. F ¨orster, and J. Schmid- huber, “Task-relevant roadmaps: A framework for humanoid motion planning,” in2013 IEEE/RSJ Int. Conf. Intell. Robots Syst., (IROS), Tokyo, Japan, Nov, 2013, pp. 5772–5778. 3
2013
-
[27]
Core: A hybrid approach of contact-aware optimization and learning for humanoid robot motions,
T. Jeong, Y . Chai, S. Choi, J. Bak, C. Kim, J. Yoon, Y . Lee, J. Lee, K. Lee, J. Kim, and S. Choi, “Core: A hybrid approach of contact-aware optimization and learning for humanoid robot motions,” inIEEE-RAS Int. Conf. Humanoid Rob., Seoul, Republic of Korea, Sep, 2025, pp. 293–300. 3
2025
-
[28]
Expressive whole-body control for humanoid robots,
X. Cheng, Y . Ji, J. Chen, R. Yang, G. Yang, and X. Wang, “Expressive whole-body control for humanoid robots,” inRobotics: Science and Systems XX, Delft, The Netherlands, Jul, 2024. 3, 4
2024
-
[29]
Mobile-television: Predictive motion priors for humanoid whole-body control,
C. Lu, X. Cheng, J. Li, S. Yang, M. Ji, C. Yuan, G. Yang, S. Yi, and X. Wang, “Mobile-television: Predictive motion priors for humanoid whole-body control,” inProc. IEEE Int. Conf. Robot. Autom., (ICRA), Atlanta, GA, USA, May, 2025, pp. 5364–5371. 3
2025
-
[30]
Universal humanoid robot pose learning from internet human videos,
J. Mao, S. Zhao, S. Song, C. Hong, T. Shi, J. Ye, M. Zhang, H. Geng, J. Malik, V . Guizilini, and Y . Wang, “Universal humanoid robot pose learning from internet human videos,” inIEEE-RAS Int. Conf. Humanoid Rob., Seoul, Republic of Korea, Sep, 2025, pp. 1–8. 3
2025
-
[31]
Harmon: Whole-body motion generation of humanoid robots from language descriptions,
Z. Jiang, Y . Xie, J. Li, Y . Yuan, Y . Zhu, and Y . Zhu, “Harmon: Whole-body motion generation of humanoid robots from language descriptions,” inProc. Conf. Robot Learning, (CoRL), Munich, Germany, Nov, 2024, pp. 3015–3026. 3, 4, 5
2024
-
[32]
Z. Xu, M. Hu, K. Xiao, Q. Fang, C. Liu, and Q. Chen, “Realizing text-driven motion generation on NAO robot: A reinforcement learning- optimized control pipeline,”arXiv preprint arXiv:2506.05117, 2025. 3
arXiv 2025
-
[33]
Hierarchical intention-aware expressive motion generation for humanoid robots,
L. Bao, Y . Pan, T. Peng, D. Kanoulas, and C. Zhou, “Hierarchical intention-aware expressive motion generation for humanoid robots,” arXiv preprint arXiv:2506.01563, 2025. 3
arXiv 2025
-
[34]
Generalizable humanoid manipulation with 3d diffusion policies,
Y . Ze, Z. Chen, W. Wang, T. Chen, X. He, Y . Yuan, X. B. Peng, and J. Wu, “Generalizable humanoid manipulation with 3d diffusion policies,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst.,(IROS), Hangzhou, China, Oct, 2025, pp. 2873–2880. 3
2025
-
[35]
HOVER: versatile neural whole-body controller for humanoid robots,
T. He, W. Xiao, T. Lin, Z. Luo, Z. Xu, Z. Jiang, J. Kautz, C. Liu, G. Shi, X. Wang, L. J. Fan, and Y . Zhu, “HOVER: versatile neural whole-body controller for humanoid robots,” inProc. IEEE Int. Conf. Robot. Autom., (ICRA), Atlanta, GA, USA, May, 2025, pp. 9989–9996. 3 13
2025
-
[36]
Manidp: Manipulability-aware diffusion policy for posture- dependent bimanual manipulation,
Z. Li, J. Liu, D. Li, T. Teng, M. Li, S. Calinon, D. G. Caldwell, and F. Chen, “Manidp: Manipulability-aware diffusion policy for posture- dependent bimanual manipulation,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst.,(IROS), Hangzhou, China, Oct, 2025, pp. 9956–9962. 3
2025
-
[37]
Humanmimic: Learning natural locomotion and transitions for humanoid robot via wasserstein adversarial imitation,
A. Tang, T. Hiraoka, N. Hiraoka, F. Shi, K. Kawaharazuka, K. Kojima, K. Okada, and M. Inaba, “Humanmimic: Learning natural locomotion and transitions for humanoid robot via wasserstein adversarial imitation,” inProc. IEEE Int. Conf. Robot. Autom., (ICRA), Yokohama, Japan, May, 2024, pp. 13 107–13 114. 4
2024
-
[38]
Emotiongesture: Audio-driven diverse emotional co-speech 3d gesture generation,
X. Qi, C. Liu, L. Li, J. Hou, H. Xin, and X. Yu, “Emotiongesture: Audio-driven diverse emotional co-speech 3d gesture generation,”IEEE Trans. Multimedia, vol. 26, pp. 10 420–10 430, 2024. 5
2024
-
[39]
Mambagesture2: Co-speech gesture generation via hierarchical fusion and spatiotemporal aggregation,
C. Fu, Y . Wang, H. He, S. Wang, C. Wang, Y . Tai, Y . Liu, and J. Zhang, “Mambagesture2: Co-speech gesture generation via hierarchical fusion and spatiotemporal aggregation,”IEEE Trans. Multimedia, vol. Early Access, pp. 1–9, 2026. 5
2026
-
[40]
Retargeting matters: General motion retargeting for humanoid motion tracking,
J. P. Ara ´ujo, Y . Ze, P. Xu, J. Wu, and C. K. Liu, “Retargeting matters: General motion retargeting for humanoid motion tracking,” arXiv preprint arXiv:2510.02252, 2025. 5, 10, 11
arXiv 2025
-
[41]
K. Zakka. (2026, Feb.) Mink: Python inverse kinematics based on MuJoCo. [Online]. Available: https://github.com/kevinzakka/mink 5, 10
2026
-
[42]
Perpetual humanoid control for real-time simulated avatars,
Z. Luo, J. Cao, A. Winkler, K. Kitani, and W. Xu, “Perpetual humanoid control for real-time simulated avatars,” inProc. IEEE Int. Conf. Comput. Vis., (ICCV), Paris, France,, Oct, 2023, pp. 10 861–10 870. 5, 10
2023
-
[43]
Adaptive convolutional network pruning through pixel-level cross-correlation and channel independence for enhanced model compression,
G. Li, H. Shao, X. Deng, and Y . Jiang, “Adaptive convolutional network pruning through pixel-level cross-correlation and channel independence for enhanced model compression,”Eng. Appl. Artif. Intell., vol. 154, p. 110920, 2025. 6
2025
-
[44]
PHUMA: physically-grounded humanoid locomotion dataset,
K. Lee, S. Kim, M. Park, H. Kim, D. Hwang, H. Lee, and J. Choo, “PHUMA: physically-grounded humanoid locomotion dataset,”arXiv preprint arXiv:2510.26236, 2025. 6
Pith/arXiv arXiv 2025
-
[45]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., (CVPR), Long Beach, CA, USA, Jun, 2019, pp. 5745–5753. 6
2019
-
[46]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inProc. Int. Conf. Learn. Represent.,(ICLR), Kigali, Rwanda, May, 2023. 7
2023
-
[47]
Neural discrete rep- resentation learning,
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete rep- resentation learning,” inProc. Adv. neural inf. proces. syst., (NeurIPS), Long Beach, CA, USA, 2017, pp. 6309–6318. 7
2017
-
[48]
Generative modeling via drifting,
M. Deng, H. Li, T. Li, Y . Du, and K. He, “Generative modeling via drifting,”arXiv preprint arXiv:2602.04770, 2026. 8
Pith/arXiv arXiv 2026
-
[49]
Enabling synergistic full-body control in prompt-based co-speech motion generation,
B. Chen, Y . Li, Y .-X. Ding, T. Shao, and K. Zhou, “Enabling synergistic full-body control in prompt-based co-speech motion generation,” in Proceedings of the 32nd ACM International Conference on Multimedia. New York, NY , USA: ACM, 2024, p. 10. 8, 9, 11
2024
-
[50]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inProc. Adv. neural inf. proces. syst., (NeurIPS), Long Beach, California, USA, Dec, 2017, pp. 6629–6640. 9
2017
-
[51]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi, “Omniretarget: Interaction-preserving data generation for humanoid whole-body loco-manipulation and scene interaction,”arXiv preprint arXiv:2509.26633, 2025. 9
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.