The Bi-Channel Networking Paradigm for Database Systems in the Cloud
Pith reviewed 2026-06-26 15:23 UTC · model grok-4.3
The pith
Database systems in the cloud can co-design networking by splitting communication into a high-performance data path and a reliable control path.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
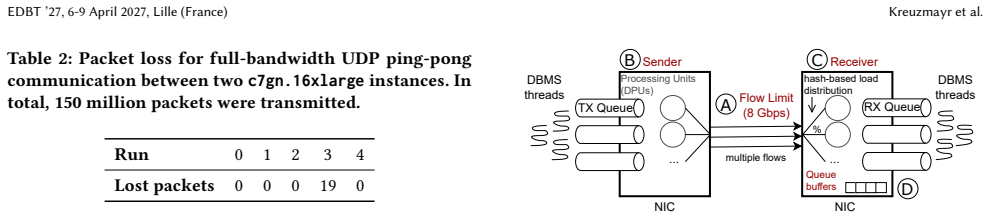
Database systems should no longer treat networking as a black box but co-design it with database operations through the bi-channel paradigm, which separates communication into a high-performance data path for latency- and bandwidth-sensitive operations and a reliable control path for coordination and recovery. The paradigm is implemented by combining user-space UDP and kernel-based TCP to exploit modern NIC capabilities while preserving TCP's reliability and ordering guarantees.
What carries the argument
The bi-channel paradigm, which separates communication into a high-performance data path using user-space UDP and a reliable control path using kernel TCP.
If this is right
- A distributed shuffle can saturate 200 Gbit/s network links using only three CPU cores.
- A replicated key-value store can process millions of messages per second while cutting kernel overhead.
- The approach preserves TCP reliability and ordering guarantees for coordination while using user-space UDP for performance-critical data movement.
- Other combinations of network stacks beyond UDP and TCP remain possible under the same separation.
Where Pith is reading between the lines
- The separation of data and control paths could extend to other distributed systems that face kernel networking bottlenecks in the cloud.
- Database implementers may need to expose NIC offload features directly to the data path layer.
- Larger-scale tests under varying network conditions would check whether the hybrid maintains its guarantees at cluster sizes beyond the reported examples.
- The split may allow independent scaling or fault handling of the control path without affecting data throughput.
Load-bearing premise
A hybrid of user-space UDP for the data path and kernel TCP for the control path can be combined in a way that exploits modern NIC capabilities while fully preserving TCP's reliability and ordering guarantees without introducing new failure modes or excessive implementation complexity.
What would settle it
An experiment showing that the UDP-TCP hybrid either loses reliability or ordering, introduces new failure modes, or fails to reduce CPU overhead compared with standard kernel TCP would falsify the claim.
Figures

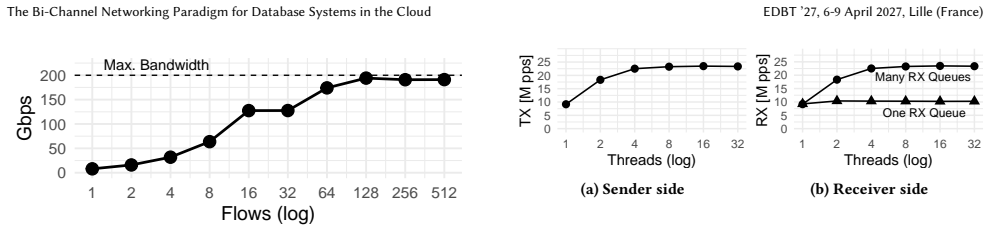



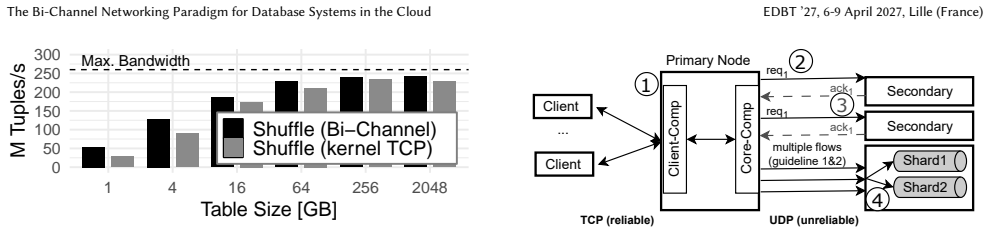
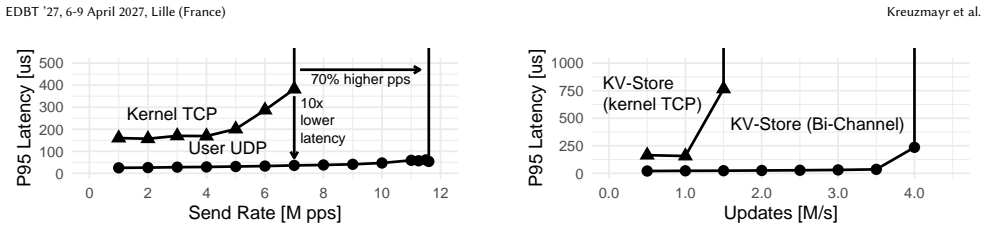

read the original abstract
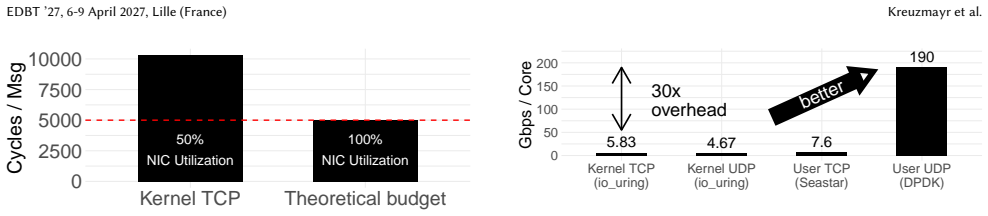
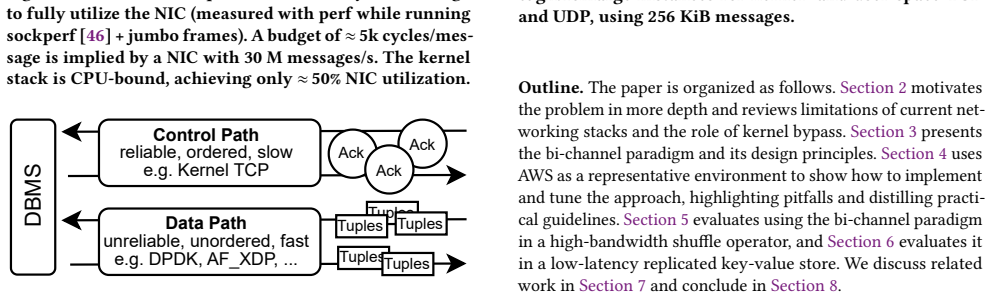
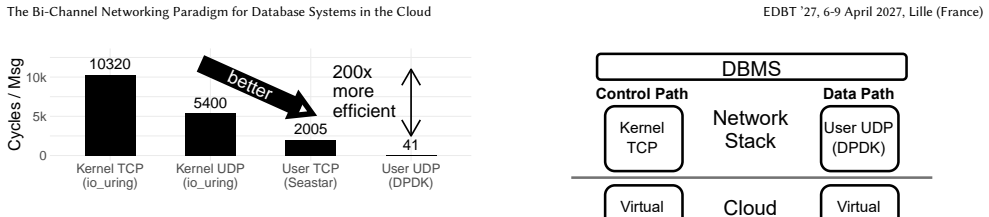
When network links were slow, cloud and distributed database systems could rely on generic kernel abstractions and treat network communication as a black box. With today's fast cloud networks, this approach breaks down: database performance becomes limited by the CPU overhead of the kernel TCP stack. Replacing TCP with user-space UDP can reduce this overhead, but it requires reimplementing essential guarantees, such as reliability and ordering. To solve this conundrum, database systems should no longer treat networking as a black box but co-design it with database operations. We propose the bi-channel paradigm for database systems, which separates communication into two channels: A high-performance data path for latency- and bandwidth-sensitive operations, and a reliable control path for coordination and recovery. We implement the paradigm by combining user-space UDP and kernel-based TCP, though other stack combinations are possible. This design exploits modern NIC capabilities while preserving TCP's reliability. We demonstrate the paradigm's efficiency and simplicity in two representative settings: a distributed shuffle saturating 200 Gbit/s with three CPU cores, and a replicated key-value store processing millions of messages per second.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the bi-channel networking paradigm for cloud database systems, which separates communication into a high-performance data path (user-space UDP for latency- and bandwidth-sensitive operations) and a reliable control path (kernel TCP for coordination and recovery). It claims this co-design with database operations exploits modern NIC capabilities while preserving TCP reliability and ordering, implemented via hybrid UDP/TCP stacks, and demonstrates efficiency in a distributed shuffle saturating 200 Gbit/s with three CPU cores and a replicated key-value store processing millions of messages per second.
Significance. If the central claim holds, the paradigm offers a practical middle ground between kernel TCP overhead and full user-space reimplementation of guarantees, potentially enabling higher performance in fast cloud networks without sacrificing reliability. The two concrete demonstration settings provide initial evidence of efficiency and simplicity, though the lack of detailed metrics limits assessment of broader impact.
major comments (2)
- [Abstract] Abstract: The performance demonstrations (distributed shuffle at 200 Gbit/s with three cores; replicated KV store at millions of messages/sec) are stated without detailed measurements, error bars, baselines, or exclusion criteria, which is load-bearing for assessing the efficiency claim of the bi-channel design.
- [Abstract] Abstract and implementation description: The claim that the hybrid user-space UDP + kernel TCP design 'preserves TCP's reliability' while exploiting NIC capabilities lacks any description of cross-channel coordination, loss recovery, ordering semantics across paths, or failure-mode analysis; this is load-bearing for the central claim that the split avoids new failure modes or excessive DB-layer complexity.
minor comments (1)
- [Abstract] The abstract and text use 'bi-channel paradigm' as a new term without a clear definition or comparison table to prior hybrid networking approaches in databases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance demonstrations (distributed shuffle at 200 Gbit/s with three cores; replicated KV store at millions of messages/sec) are stated without detailed measurements, error bars, baselines, or exclusion criteria, which is load-bearing for assessing the efficiency claim of the bi-channel design.
Authors: We agree that the abstract presents the performance results at a high level without supporting details. The full manuscript contains the requested measurements, baselines, error bars, and experimental methodology in the evaluation sections. To address the concern directly in the abstract, we will revise it to include key quantitative details and explicit references to the detailed results and baselines. revision: yes
-
Referee: [Abstract] Abstract and implementation description: The claim that the hybrid user-space UDP + kernel TCP design 'preserves TCP's reliability' while exploiting NIC capabilities lacks any description of cross-channel coordination, loss recovery, ordering semantics across paths, or failure-mode analysis; this is load-bearing for the central claim that the split avoids new failure modes or excessive DB-layer complexity.
Authors: The abstract summarizes the design at a high level and does not include the requested details on cross-channel coordination. The full manuscript explains that the TCP control path is responsible for coordination, recovery, and ordering guarantees while the UDP data path handles performance-critical transfers, with the database layer using the control path to manage any UDP losses. However, we acknowledge the referee's point that a concise description of these mechanisms, ordering semantics, and failure modes would strengthen the central claim. We will add a brief paragraph to the abstract and/or introduction clarifying these aspects. revision: yes
Circularity Check
No circularity: independent design proposal without derivations or self-referential reductions
full rationale
The paper presents a systems design proposal for a bi-channel networking paradigm that splits communication into a high-performance UDP data path and a reliable TCP control path. No equations, fitted parameters, predictions, or mathematical derivations appear in the abstract or described content. The central claim is an explicit design choice grounded in observed limitations of kernel TCP stacks on fast networks, with implementation and performance claims (e.g., 200 Gbit/s shuffle) presented as empirical demonstrations rather than reductions to prior inputs. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner. The derivation chain is therefore self-contained as an independent architectural suggestion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Kernel TCP stack incurs prohibitive CPU overhead on modern fast cloud networks for database workloads
- domain assumption User-space UDP combined with kernel TCP can preserve essential reliability and ordering guarantees while exploiting modern NIC capabilities
invented entities (1)
-
bi-channel paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services. 2023. Compute optimized instances. Amazon Elastic Compute Cloud Documentation. https://docs.aws.amazon.com/ec2/latest/ instancetypes/co.html Accessed: 2026-01-31
2023
-
[2]
Amazon Web Services. 2025. Amazon EC2 instance network band- width. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2- instance-network-bandwidth.html Accessed: 2026-01-31. EDBT ’27, 6-9 April 2027, Lille (France) Kreuzmayr et al
2025
-
[3]
Amazon Web Services. 2025. DPDK driver for Elastic Network Adapter (ENA). https://github.com/amzn/amzn-drivers/tree/master/userspace/dpdk Accessed: 2026-01-31
2025
-
[4]
Austin Appleby. 2011. SMHasher. https://github.com/aappleby/smhasher Accessed: 2026-01-31
2011
-
[5]
Shivnath Babu and Herodotos Herodotou. 2013. Massively Parallel Databases and MapReduce Systems.Found. Trends Databases5, 1 (2013), 1–104. doi:10. 1561/1900000036
2013
-
[6]
Wei Bai, Shanim Sainul Abdeen, Ankit Agrawal, Krishan Kumar Attre, Paramvir Bahl, Ameya Bhagat, Gowri Bhaskara, Tanya Brokhman, Lei Cao, Ahmad Cheema, Rebecca Chow, Jeff Cohen, Mahmoud Elhaddad, Vivek Ette, Igal Figlin, Daniel Firestone, Mathew George, Ilya German, Lakhmeet Ghai, Eric Green, Albert Greenberg, Manish Gupta, Randy Haagens, Matthew Hen- del,...
-
[7]
Empowering Azure Storage with RDMA. InNSDI. USENIX Association, 49–67. https://www.usenix.org/conference/nsdi23/presentation/bai
-
[8]
Adam Belay, George Prekas, Ana Klimovic, Samuel Grossman, Christos Kozyrakis, and Edouard Bugnion. 2014. IX: A Protected Dataplane Oper- ating System for High Throughput and Low Latency. InOSDI, Jason Flinn and Hank Levy (Eds.). USENIX Association, 49–65. https://www.usenix.org/ conference/osdi14/technical-sessions/presentation/belay
2014
-
[9]
Carsten Binnig, Andrew Crotty, Alex Galakatos, Tim Kraska, and Erfan Zama- nian. 2016. The End of Slow Networks: It’s Time for a Redesign.Proc. VLDB Endow.9, 7 (2016), 528–539. doi:10.14778/2904483.2904485
-
[10]
Freedman, Justin Pettit, Jianying Luo, Nick McK- eown, and Scott Shenker
Martín Casado, Michael J. Freedman, Justin Pettit, Jianying Luo, Nick McK- eown, and Scott Shenker. 2007. Ethane: taking control of the enterprise. In SIGCOMM, Jun Murai and Kenjiro Cho (Eds.). ACM, 1–12. doi:10.1145/1282380. 1282382
-
[11]
Mark A Cusack, John Adamson, Mark Brinicombe, Neil A Carson, Thomas Kejser, Jim Peterson, Arvind Vasudev, Kurt Westerfeld, and Robert Wipfel
-
[12]
Yellowbrick: An Elastic Data Warehouse on Kubernetes. InCIDR. https: //www.cidrdb.org/cidr2024/papers/p2-cusack.pdf
-
[13]
Benoît Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Un- terbrunner. 2016. The Snowflake Elastic Data Warehouse. InSIGMO...
-
[14]
DPDK Project, Linux Foundation. 2026. Data Plane Development Kit. https: //github.com/DPDK/dpdk/blob/main/drivers/net/mana/rx.c Accessed: 2026- 01-31
2026
-
[15]
Aleksandar Dragojevic, Dushyanth Narayanan, Miguel Castro, and Orion Hodson. 2014. FaRM: Fast Remote Memory. InNSDI, Ratul Mahajan and Ion Stoica (Eds.). USENIX Association, 401–414. https://www.usenix.org/ conference/nsdi14/technical-sessions/dragojevi%C4%87
2014
-
[16]
Nightingale, Matthew Renzelmann, Alex Shamis, Anirudh Badam, and Miguel Castro
Aleksandar Dragojevic, Dushyanth Narayanan, Edmund B. Nightingale, Matthew Renzelmann, Alex Shamis, Anirudh Badam, and Miguel Castro. 2015. No compromises: distributed transactions with consistency, availability, and performance. InSOSP, Ethan L. Miller and Steven Hand (Eds.). ACM, 54–70. doi:10.1145/2815400.2815425
-
[17]
Jingwen Du, Fang Wang, Dan Feng, Changchen Gan, Yuchao Cao, Xiaomin Zou, and Fan Li. 2023. Fast One-Sided RDMA-Based State Machine Replication for Disaggregated Memory.ACM Trans. Archit. Code Optim.20, 2 (mar 2023), 31:1–31:25. doi:10.1145/3587096
-
[18]
Peter Xiang Gao, Akshay Narayan, Gautam Kumar, Rachit Agarwal, Sylvia Ratnasamy, and Scott Shenker. 2015. pHost: distributed near-optimal datacen- ter transport over commodity network fabric. InCoNEXT, Felipe Huici and Giuseppe Bianchi (Eds.). ACM, 1:1–1:12. doi:10.1145/2716281.2836086
-
[19]
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. 2003. The Google file system. InSOSP, Michael L. Scott and Larry L. Peterson (Eds.). ACM, 29–43. doi:10.1145/945445.945450
-
[20]
Google Cloud. 2025. Network bandwidth. https://cloud.google.com/compute/ docs/network-bandwidth Accessed: 2026-01-31
2025
-
[21]
Google Cloud. 2026. View Google Cloud packet loss dashboard. https: //docs.cloud.google.com/network-intelligence-center/docs/performance- dashboard/how-to/view-google-cloud-packet-loss Accessed: 2026-01-31
2026
-
[22]
Google Cloud Platform. 2026. Linux kernel driver for Compute Engine Vir- tual Ethernet. https://github.com/GoogleCloudPlatform/compute-virtual- ethernet-linux Accessed: 2026-03-31
2026
-
[23]
Moore, Gianni Antichi, and Marcin Wójcik
Mark Handley, Costin Raiciu, Alexandru Agache, Andrei Voinescu, Andrew W. Moore, Gianni Antichi, and Marcin Wójcik. 2017. Re-architecting datacenter networks and stacks for low latency and high performance. InSIGCOMM. ACM, 29–42. doi:10.1145/3098822.3098825
-
[24]
Matthias Jasny, Muhammad El-Hindi, Tobias Ziegler, and Carsten Binnig. 2025. A Wake-Up Call for Kernel-Bypass on Modern Hardware. InDaMoN. ACM, 14:1–14:5
2025
-
[25]
Matthias Jasny, Muhammad El-Hindi, Tobias Ziegler, Viktor Leis, and Carsten Binnig. 2025. High-Performance DBMSs with io_uring: When and How to use it.CoRRabs/2512.04859 (2025). doi:10.48550/ARXIV.2512.04859 arXiv:2512.04859
-
[26]
Eunyoung Jeong, Shinae Woo, Muhammad Asim Jamshed, Haewon Jeong, Sunghwan Ihm, Dongsu Han, and KyoungSoo Park. 2014. mTCP: a Highly Scalable User-level TCP Stack for Multicore Systems. InNSDI, Ratul Mahajan and Ion Stoica (Eds.). USENIX Association, 489–502. https://www.usenix.org/ conference/nsdi14/technical-sessions/presentation/jeong
2014
-
[27]
Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2014. Using RDMA efficiently for key-value services. InSIGCOMM, Fabián E. Bustamante, Y. Char- lie Hu, Arvind Krishnamurthy, and Sylvia Ratnasamy (Eds.). ACM, 295–306. doi:10.1145/2619239.2626299
-
[28]
Andersen
Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2016. Design Guide- lines for High Performance RDMA Systems.login Usenix Mag.41, 3 (2016). https://www.usenix.org/publications/login/fall2016/kalia
2016
-
[29]
Andersen
Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2019. Datacenter RPCs can be General and Fast. InNSDI. USENIX Association, 1–16
2019
-
[30]
Sharma, Arvind Krishnamurthy, and Thomas E
Antoine Kaufmann, Tim Stamler, Simon Peter, Naveen Kr. Sharma, Arvind Krishnamurthy, and Thomas E. Anderson. 2019. TAS: TCP Acceleration as an OS Service. InEuroSys, George Candea, Robbert van Renesse, and Christof Fetzer (Eds.). ACM, 24:1–24:16. doi:10.1145/3302424.3303985
-
[31]
Michael Kerrisk. 2025. io_uring_prep_send_zc. https://man7.org/linux/man- pages/man3/io_uring_prep_send_zc.3.html Accessed: 2026-01-31
2025
-
[32]
Taehyun Kim, Deondre Martin Ng, Junzhi Gong, Youngjin Kwon, Minlan Yu, and KyoungSoo Park. 2023. Rearchitecting the TCP Stack for I/O-Offloaded Content Delivery. InNSDI, Mahesh Balakrishnan and Manya Ghobadi (Eds.). USENIX Association, 275–292. https://www.usenix.org/conference/nsdi23/ presentation/kim-taehyun
2023
-
[33]
Milojicic, and Gustavo Alonso
Dario Korolija, Dimitrios Koutsoukos, Kimberly Keeton, Konstantin Taranov, Dejan S. Milojicic, and Gustavo Alonso. 2022. Farview: Disaggregated Memory with Operator Off-loading for Database Engines. InCIDR. CIDR Foundation. https://www.cidrdb.org/cidr2022/papers/p11-korolija.pdf
2022
-
[34]
H. T. Kung and Robert Morris. 1995. Credit-based flow control for ATM networks.IEEE Netw.9, 2 (1995), 40–48
1995
-
[35]
Viktor Leis, Adnan Alhomssi, Tobias Ziegler, Yannick Loeck, and Christian Dietrich. 2023. Virtual-Memory Assisted Buffer Management.Proc. ACM Manag. Data1, 1 (2023), 7:1–7:25
2023
-
[36]
Boncz, Alfons Kemper, and Thomas Neumann
Viktor Leis, Peter A. Boncz, Alfons Kemper, and Thomas Neumann. 2014. Morsel-driven parallelism: a NUMA-aware query evaluation framework for the many-core age. InSIGMOD, Curtis E. Dyreson, Feifei Li, and M. Tamer Özsu (Eds.). ACM, 743–754. doi:10.1145/2588555.2610507
-
[37]
LF Projects, LLC. 2025. Data Plane Development Kit. https://www.dpdk.org/ Accessed: 2026-01-31
2025
-
[38]
Feng Li, Sudipto Das, Manoj Syamala, and Vivek R. Narasayya. 2016. Ac- celerating Relational Databases by Leveraging Remote Memory and RDMA. InSIGMOD, Fatma Özcan, Georgia Koutrika, and Sam Madden (Eds.). ACM, 355–370. doi:10.1145/2882903.2882949
-
[39]
Feilong Liu, Lingyan Yin, and Spyros Blanas. 2017. Design and Evaluation of an RDMA-aware Data Shuffling Operator for Parallel Database Systems. In EuroSys. ACM, 48–63. doi:10.1145/3064176.3064202
-
[40]
Jiuxing Liu, Jiesheng Wu, and Dhabaleswar K. Panda. 2004. High Performance RDMA-Based MPI Implementation over InfiniBand.Int. J. Parallel Program. 32, 3 (2004), 167–198. doi:10.1023/B:IJPP.0000029272.69895.C1
-
[41]
Zirui Liu, Xian Niu, Wei Zhou, Yisen Hong, Zhouran Shi, Tong Yang, Yuchao Zhang, Yuhan Wu, Yikai Zhao, Zhuochen Fan, and Bin Cui. 2025. Extendible RDMA-based Remote Memory KV Store with Dynamic Perfect Hashing Index. InICDE. IEEE, 1745–1758. doi:10.1109/ICDE65448.2025.00134
-
[42]
Hendrik Makait, Bonaventura Del Monte, and Tilmann Rabl. 2024. Ghost- writer: a Distributed Message Broker on RDMA and NVM. InADMS@VLDB. VLDB.org. https://vldb.org/workshops/2024/proceedings/ADMS/ADMS24_ 04.pdf
2024
-
[43]
Sergey Melnik, Andrey Gubarev, Jing Jing Long, Geoffrey Romer, Shiva Shiv- akumar, Matt Tolton, Theo Vassilakis, Hossein Ahmadi, Dan Delorey, Slava Min, Mosha Pasumansky, and Jeff Shute. 2020. Dremel: A Decade of Interac- tive SQL Analysis at Web Scale.Proc. VLDB Endow.13, 12 (2020), 3461–3472. doi:10.14778/3415478.3415568
-
[44]
Christopher Mitchell, Yifeng Geng, and Jinyang Li. 2013. Using One- Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store. In USENIX ATC, Andrew Birrell and Emin Gün Sirer (Eds.). USENIX Associ- ation, 103–114. https://www.usenix.org/conference/atc13/technical-sessions/ presentation/mitchell
2013
-
[45]
C. Mohan, Bruce G. Lindsay, and Ron Obermarck. 1986. Transaction Man- agement in the R* Distributed Database Management System.ACM Trans. Database Syst.11, 4 (1986), 378–396. doi:10.1145/7239.7266
-
[46]
Ousterhout
Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John K. Ousterhout
-
[47]
InSIGCOMM, Sergey Gorinsky and János Tapolcai (Eds.)
Homa: a receiver-driven low-latency transport protocol using network priorities. InSIGCOMM, Sergey Gorinsky and János Tapolcai (Eds.). ACM, 221–235. doi:10.1145/3230543.3230564
-
[48]
YoungGyoun Moon, SeungEon Lee, Muhammad Asim Jamshed, and Kyoung- Soo Park. 2020. AccelTCP: Accelerating Network Applications with Stateful TCP Offloading. InNSDI, Ranjita Bhagwan and George Porter (Eds.). USENIX Association, 77–92. https://www.usenix.org/conference/nsdi20/presentation/ moon The Bi-Channel Networking Paradigm for Database Systems in the C...
2020
-
[49]
NVIDIA Corporation. 2025. sockperf. https://github.com/Mellanox/sockperf Accessed: 2026-01-31
2025
-
[50]
John K. Ousterhout. 2022. It’s Time to Replace TCP in the Datacenter.CoRR abs/2210.00714 (2022). doi:10.48550/ARXIV.2210.00714 arXiv:2210.00714
-
[51]
Mosha Pasumansky and Benjamin Wagner. 2022. Assembling a Query Engine From Spare Parts. InCDMS@VLDB, Satyanarayana R. Valluri and Mohamed Zaït (Eds.). https://cdmsworkshop.github.io/2022/Proceedings/ShortPapers/ Paper1_MoshaPasumansky.pdf
2022
-
[52]
Simon Peter, Jialin Li, Irene Zhang, Dan R. K. Ports, Doug Woos, Arvind Krishnamurthy, Thomas E. Anderson, and Timothy Roscoe. 2014. Arrakis: The Operating System is the Control Plane. InOSDI, Jason Flinn and Hank Levy (Eds.). USENIX Association, 1–16. https://www.usenix.org/conference/ osdi14/technical-sessions/presentation/peter
2014
-
[53]
Wolf Rödiger, Tobias Mühlbauer, Alfons Kemper, and Thomas Neumann. 2015. High-Speed Query Processing over High-Speed Networks.Proc. VLDB Endow. 9, 4 (2015), 228–239. doi:10.14778/2856318.2856319
-
[54]
Alireza Sanaee, Vahab Jabrayilov, Ilias Marinos, Anuj Kalia, Divyanshu Saxena, Prateesh Goyal, Kostis Kaffes, and Gianni Antichi. 2025. Fast Userspace Networking for the Rest of Us. arXiv:2502.09281 [cs.NI] https://arxiv.org/abs/ 2502.09281
arXiv 2025
-
[55]
Michael Scharf and Sebastian Kiesel. 2006. Head-of-line Blocking in TCP and SCTP: Analysis and Measurements. InGLOBECOM. IEEE. doi:10.1109/ GLOCOM.2006.333
2006
-
[56]
ScyllaDB. 2019. Seastar. https://seastar.io/ Accessed: 2026-01-31
2019
-
[57]
ScyllaDB. 2025. ScyllaDB. https://www.scylladb.com/ Accessed: 2026-01-31
2025
-
[58]
Leah Shalev, Hani Ayoub, Nafea Bshara, and Erez Sabbag. 2020. A Cloud- Optimized Transport Protocol for Elastic and Scalable HPC.IEEE Micro40, 6 (2020), 67–73. doi:10.1109/MM.2020.3016891
-
[59]
Alex Shamis, Matthew Renzelmann, Stanko Novakovic, Georgios Chatzopou- los, Aleksandar Dragojevic, Dushyanth Narayanan, and Miguel Castro. 2019. Fast General Distributed Transactions with Opacity. InSIGMOD, Peter A. Boncz, Stefan Manegold, Anastasia Ailamaki, Amol Deshpande, and Tim Kraska (Eds.). ACM, 433–448. doi:10.1145/3299869.3300069
-
[60]
Rajath Shashidhara, Tim Stamler, Antoine Kaufmann, and Simon Peter. 2022. FlexTOE: Flexible TCP Offload with Fine-Grained Parallelism. InNSDI. USENIX Association, 87–102
2022
-
[61]
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, and Robert Chansler
-
[62]
The Hadoop Distributed File System. InMSST, Mohammed G. Khatib, Xubin He, and Michael Factor (Eds.). IEEE Computer Society, 1–10. doi:10. 1109/MSST.2010.5496972
arXiv 2010
-
[63]
Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armistead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie Germano, Anand Kanagala, Jeff Provost, Jason Simmons, Eiichi Tanda, Jim Wanderer, Urs Hölzle, Stephen Stuart, and Amin Vahdat. 2015. Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Netw...
2015
-
[64]
Maomeng Su, Mingxing Zhang, Kang Chen, Zhenyu Guo, and Yongwei Wu
-
[65]
InEuroSys, Gustavo Alonso, Ricardo Bianchini, and Marko Vukolic (Eds.)
RFP: When RPC is Faster than Server-Bypass with RDMA. InEuroSys, Gustavo Alonso, Ricardo Bianchini, and Marko Vukolic (Eds.). ACM, 1–15. doi:10.1145/3064176.3064189
-
[66]
Tencent Cloud. 2025. F-Stack. https://www.f-stack.org/ Accessed: 2026-01-31
2025
-
[67]
Lasse Thostrup, Jan Skrzypczak, Matthias Jasny, Tobias Ziegler, and Carsten Binnig. 2022. DFI: The Data Flow Interface for High-Speed Networks.SIGMOD Rec.51, 1 (2022), 15–22. doi:10.1145/3542700.3542705
-
[68]
Alexander van Renen, Dominik Horn, Pascal Pfeil, Kapil Vaidya, Wenjian Dong, Murali Narayanaswamy, Zhengchun Liu, Gaurav Saxena, Andreas Kipf, and Tim Kraska. 2024. Why TPC Is Not Enough: An Analysis of the Amazon Redshift Fleet.Proc. VLDB Endow.17, 11 (2024), 3694–3706. doi:10.14778/ 3681954.3682031
arXiv 2024
-
[69]
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. InSIGMOD, Semih Salihoglu, Wenchao Zhou, Rada Chirkova, Jun Yang, and Dan Suciu (Ed...
-
[70]
Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Mo- tivala, and Thierry Cruanes. 2020. Building An Elastic Query Engine on Disaggregated Storage. InNSDI, Ranjita Bhagwan and George Porter (Eds.). USENIX Association, 449–462. https://www.usenix.org/conference/nsdi20/ presentation/vuppalapati
2020
-
[71]
Qing Wang, Youyou Lu, and Jiwu Shu. 2022. Sherman: A Write-Optimized Distributed B+Tree Index on Disaggregated Memory. InSIGMOD. ACM, 1033–
2022
-
[72]
doi:10.1145/3514221.3517824
-
[73]
Ruihong Wang, Jianguo Wang, Stratos Idreos, M. Tamer Özsu, and Walid G. Aref. 2022. The Case for Distributed Shared-Memory Databases with RDMA- Enabled Memory Disaggregation.CoRRabs/2207.03027 (2022). doi:10.48550/ arXiv.2207.03027 arXiv:2207.03027
arXiv 2022
-
[74]
Tinggang Wang, Shuo Yang, Hideaki Kimura, Garret Swart, and Spyros Blanas
-
[75]
InADMS, Rajesh Bordawekar and Tirthankar Lahiri (Eds.)
Efficient Usage of One-Sided RDMA for Linear Probing. InADMS, Rajesh Bordawekar and Tirthankar Lahiri (Eds.). 1–13. http://www.adms- conf.org/2020-camera-ready/ADMS20_06.pdf
2020
-
[76]
Johannes Wehrstein, Roman Heinrich, Mihail Stoian, Skander Krid, Martin Stemmer, Andreas Kipf, Carsten Binnig, and Muhammad El-Hindi. 2025. Red- bench: Workload Synthesis From Cloud Traces.CoRRabs/2511.13059 (2025)
Pith/arXiv arXiv 2025
-
[77]
Weil, Scott A
Sage A. Weil, Scott A. Brandt, Ethan L. Miller, Darrell D. E. Long, and Carlos Maltzahn. 2006. Ceph: A Scalable, High-Performance Distributed File System. InOSDI, Brian N. Bershad and Jeffrey C. Mogul (Eds.). USENIX Association, 307–320. http://www.usenix.org/events/osdi06/tech/weil.html
2006
-
[78]
Mengbai Xiao, Hao Wang, Liang Geng, Rubao Lee, and Xiaodong Zhang
-
[79]
Catfish: Adaptive RDMA-enabled R-Tree for Low Latency and High Throughput. InICDCS. IEEE, 164–175. doi:10.1109/ICDCS.2019.00025
-
[80]
Channy Yun. 2025. New Amazon EC2 C8gn instances powered by AWS Graviton4 offering up to 600Gbps network bandwidth. AWS News Blog. https://aws.amazon.com/blogs/aws/new-amazon-ec2-c8gn-instances- powered-by-aws-graviton4-offering-up-to-600gbps-network-bandwidth/ Accessed: 2026-01-31
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.