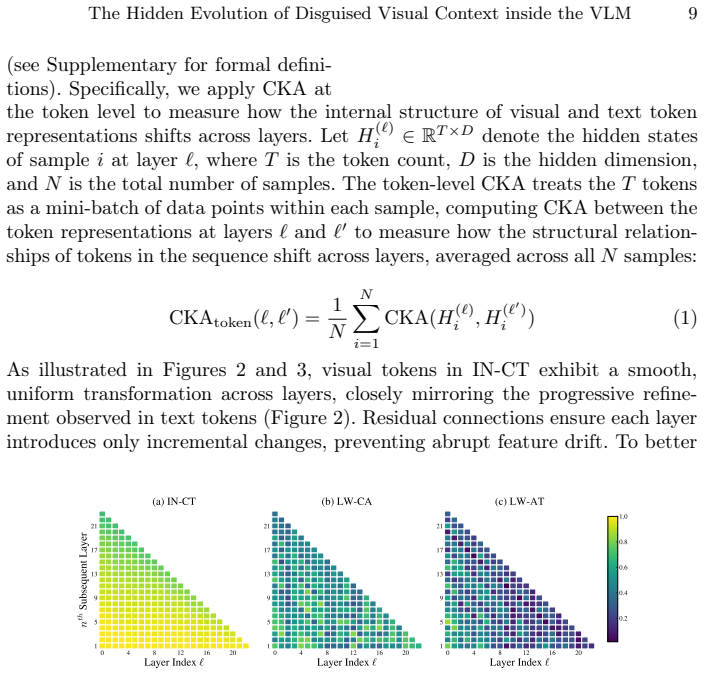
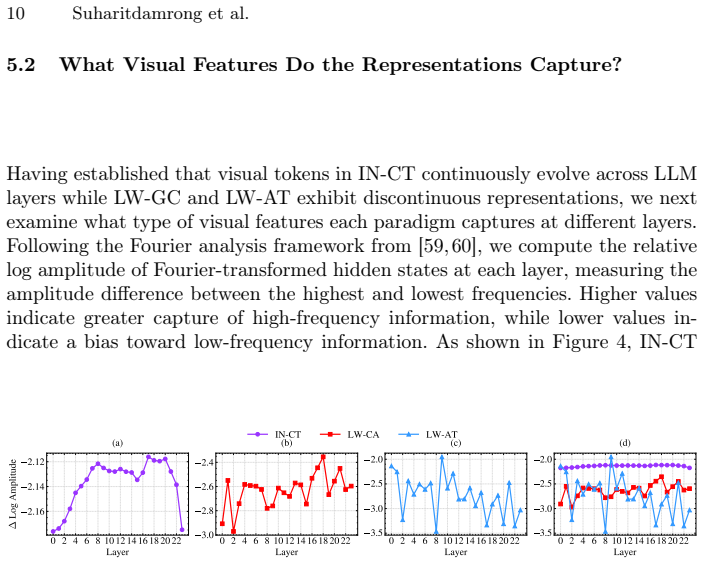
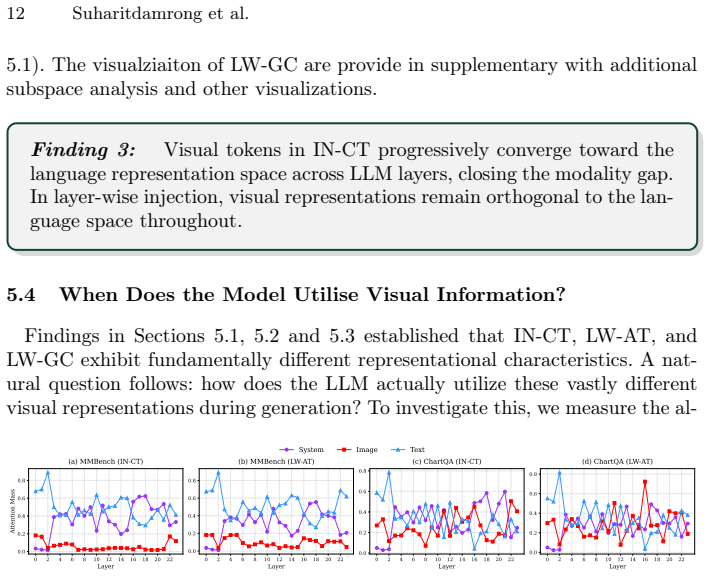
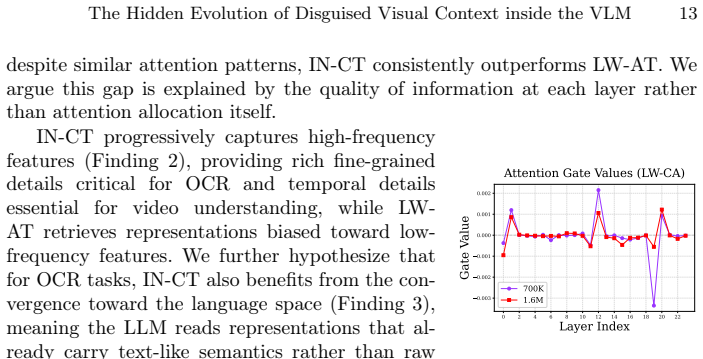
The Hidden Evolution of Disguised Visual Context inside the VLM
Pith reviewed 2026-06-26 18:06 UTC · model grok-4.3
The pith
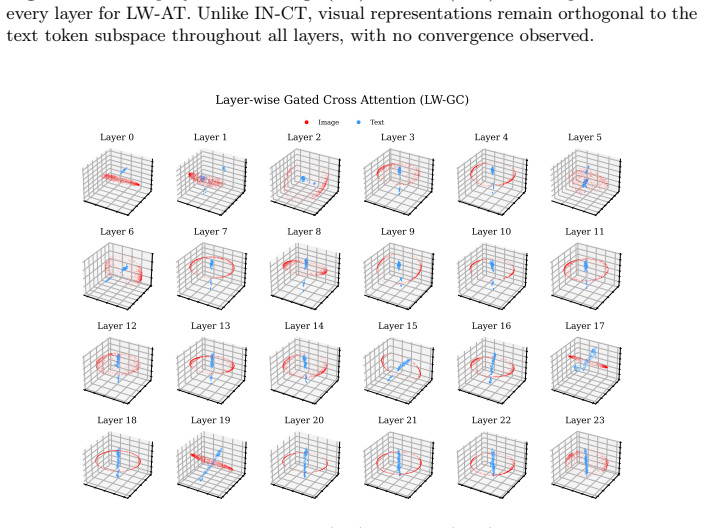
Visual tokens enter LLMs as raw signals and are progressively reshaped by integration paradigm, each capturing different frequency characteristics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Visual tokens enter the LLM as disguised visual context, raw representations lacking linguistic structure, but are progressively reshaped depending on the integration paradigm, each capturing fundamentally different frequency characteristics of the visual signal. This evolution inside the LLM determines what visual features the VLM can utilize effectively, how visual representations align with the language space, and ultimately how each paradigm performs across different tasks. Attention allocation alone is insufficient, and performance is driven by the quality of visual representations at each layer.
What carries the argument
The progressive reshaping of disguised visual context inside the LLM, where raw visual tokens acquire different frequency profiles according to whether they are added as in-context prompts or injected at intermediate layers.
If this is right
- In-context and layer-wise injection each produce visual representations tuned to different frequency characteristics of the input signal.
- The internal evolution of visual tokens controls alignment with the language space and determines task performance.
- Performance gaps between paradigms arise from differences in representation quality at each layer rather than attention allocation alone.
- The same training regime reveals that each paradigm has distinct strengths on single-image, multi-image, and video benchmarks.
Where Pith is reading between the lines
- Choosing the injection layer could be tuned to match the frequency demands of a target task.
- The same layer-wise reshaping process may appear when other modalities such as audio are integrated into LLMs.
- Architecture search could target specific representation qualities at particular depths rather than overall attention patterns.
Load-bearing premise
The two integration paradigms can be compared fairly when trained under identical conditions across single-image, multi-image, and video benchmarks.
What would settle it
Finding that the frequency characteristics of visual representations at corresponding layers remain identical between the two paradigms, or that performance differences disappear once representation quality is controlled for.
Figures




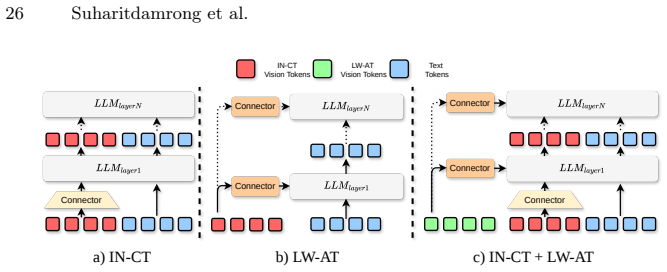
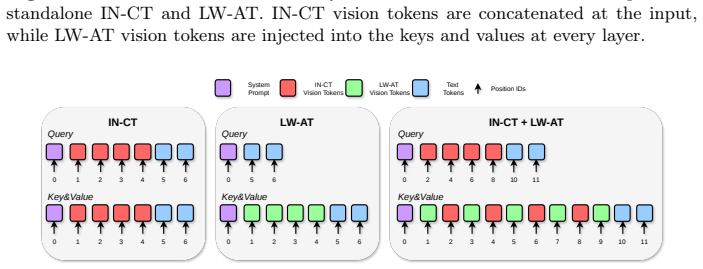

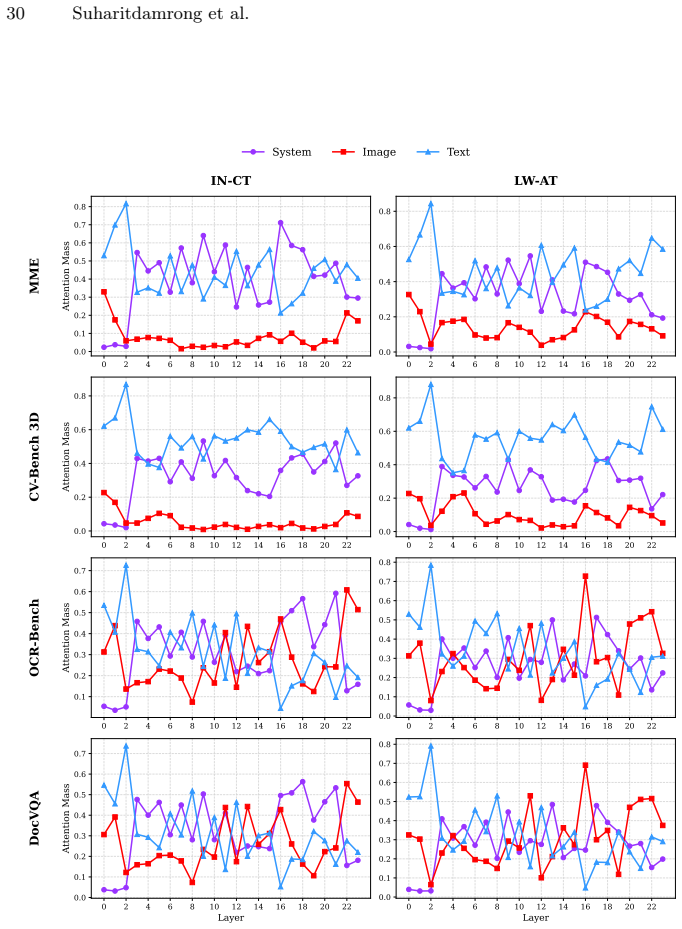

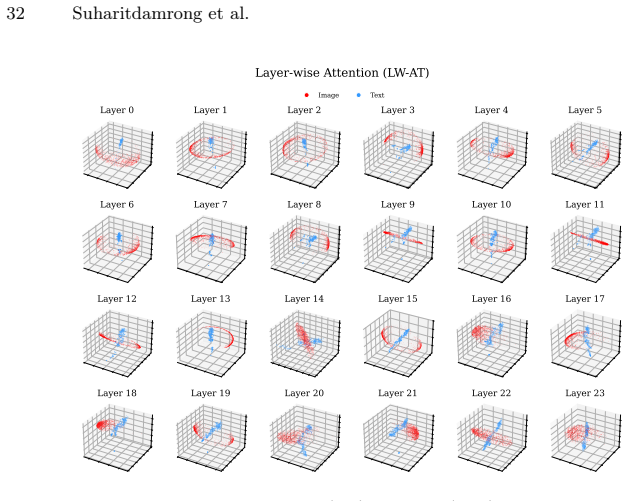
read the original abstract
Visual tokens enter Large Language Models (LLMs) as raw, foreign signals. How they are transformed into meaningful representations and interact with the language space depends entirely on the integration architecture. Whether by treating visual tokens as in-context prompts within the input sequence or injecting them directly into the LLM's intermediate layers. A controlled comparison and understanding of how these architectural choices affect visual information and its internal transformation to integrate with the LLM remains underexplored. We provide a fair comparison by evaluating in-context and layer-wise injection VLM integration paradigms under identical training conditions across single image, multi-image, and video benchmarks. In doing so, we uncover a hidden evolution where visual tokens enter the LLM as disguised visual context, raw representations lacking linguistic structure, but are progressively reshaped depending on the integration paradigm, each capturing fundamentally different frequency characteristics of the visual signal. We show that this evolution inside the LLM determines what visual features the VLM can utilize effectively, how visual representations align with the language space, and ultimately how each paradigm performs across different tasks. We further demonstrate that attention allocation alone is insufficient, and that performance is driven by the quality of visual representations at each layer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares two VLM integration paradigms—in-context prompting of visual tokens versus layer-wise injection—under identical training conditions on single-image, multi-image, and video benchmarks. It claims that visual tokens enter the LLM as raw 'disguised visual context' lacking linguistic structure and undergo paradigm-dependent progressive reshaping that captures fundamentally different frequency characteristics of the visual signal; this internal evolution determines usable visual features, alignment with language space, and task performance. The work further asserts that attention allocation alone is insufficient and that performance is driven by the quality of visual representations at each layer.
Significance. If the results hold after verification of identical training conditions, the work would provide a useful empirical dissection of how architectural choices shape internal visual representations in VLMs. The multi-benchmark controlled comparison and the emphasis on layer-wise representation quality (rather than attention alone) could inform future VLM design. The absence of equations, fitted parameters, or statistical controls noted in the abstract, however, limits immediate assessment of the frequency-characteristic claims.
major comments (1)
- [Abstract] Abstract (and experimental setup section): The central claim that paradigm-dependent reshaping and frequency differences drive performance gaps requires that the only systematic difference between in-context and layer-wise setups is the integration architecture. The manuscript states the paradigms were evaluated 'under identical training conditions,' yet supplies no explicit verification (optimizer, learning-rate schedule, batch construction, number of steps, or visual-encoder update policy). This assumption is load-bearing; any mismatch would allow training artifacts to explain the reported evolution and benchmark differences.
minor comments (2)
- [Abstract] Abstract: The term 'disguised visual context' is introduced without definition or citation, which reduces clarity for readers.
- [Abstract] Abstract: No dataset names, sizes, or error-bar reporting are mentioned, making it difficult to gauge the scale and statistical reliability of the frequency-characteristic observations.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback emphasizing the need for transparent verification of our controlled experimental setup. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and experimental setup section): The central claim that paradigm-dependent reshaping and frequency differences drive performance gaps requires that the only systematic difference between in-context and layer-wise setups is the integration architecture. The manuscript states the paradigms were evaluated 'under identical training conditions,' yet supplies no explicit verification (optimizer, learning-rate schedule, batch construction, number of steps, or visual-encoder update policy). This assumption is load-bearing; any mismatch would allow training artifacts to explain the reported evolution and benchmark differences.
Authors: We agree that explicit verification is essential to substantiate the claim that architectural integration is the sole systematic difference. The original manuscript asserted identical training conditions but did not enumerate the specific hyperparameters. In revision we will add a dedicated paragraph (or table) in the experimental setup section specifying the optimizer, learning-rate schedule, batch construction, total steps, and visual-encoder update policy for both paradigms, thereby confirming the controlled comparison and removing any ambiguity about training artifacts. revision: yes
Circularity Check
No circularity: empirical observations from controlled experiments
full rationale
The paper presents an empirical comparison of two VLM integration paradigms evaluated under identical training conditions, with the reported 'hidden evolution' and frequency characteristics framed as direct observations from internal representation analysis rather than quantities derived from fitted parameters, self-definitions, or self-citation chains. No equations, ansatzes, or predictions appear in the provided text that reduce claims to inputs by construction; the central assertions rest on experimental isolation of architectural differences, which is self-contained against external benchmarks and does not invoke load-bearing self-citations or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
- [3]
-
[4]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Zhu, D., et al.: Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv preprint arXiv:2509.23661 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Awadalla, A., Gao, I., Gardner, J., Hessel, J., Hanafy, Y., Zhu, W., Marathe, K., Bitton, Y., Gadre, S., Sagawa, S., et al.: Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Advances in Neural Information Processing Systems37, 7400–7426 (2024)
Basu, S., Grayson, M., Morrison, C., Nushi, B., Feizi, S., Massiceti, D.: Under- standing information storage and transfer in multi-modal large language models. Advances in Neural Information Processing Systems37, 7400–7426 (2024)
2024
-
[8]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024)
2024
-
[9]
Advances in neural information processing systems36, 49250–49267 (2023)
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023)
2023
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Deitke, M., Clark, C., Lee, S., Tripathi, R., Yang, Y., Park, J.S., Salehi, M., Muen- nighoff, N., Lo, K., Soldaini, L., et al.: Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 91–104 (2025)
2025
-
[11]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Diao, H., Li, X., Cui, Y., Wang, Y., Deng, H., Pan, T., Wang, W., Lu, H., Wang, X.: Evev2: Improved baselines for encoder-free vision-language models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21014–21025 (2025)
2025
-
[12]
In: Findings of the association for computational linguistics: EMNLP 2022
Eichenberg, C., Black, S., Weinbach, S., Parcalabescu, L., Frank, A.: Magma– multimodal augmentation of generative models through adapter-based finetuning. In: Findings of the association for computational linguistics: EMNLP 2022. pp. 2416–2428 (2022)
2022
-
[13]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
2025
-
[15]
arXiv preprint arXiv:2506.08008 (2025)
Fu, S., Bonnen, T., Guillory, D., Darrell, T.: Hidden in plain sight: Vlms overlook their visual representations. arXiv preprint arXiv:2506.08008 (2025)
-
[16]
arXiv preprint arXiv:2503.03983 (2025)
Ghosh, S., Kong, Z., Kumar, S., Sakshi, S., Kim, J., Ping, W., Valle, R., Manocha, D., Catanzaro, B.: Audio flamingo 2: An audio-language model with long-audio un- derstanding and expert reasoning abilities. arXiv preprint arXiv:2503.03983 (2025)
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Han, J., Gong, K., Zhang, Y., Wang, J., Zhang, K., Lin, D., Qiao, Y., Gao, P., Yue, X.: Onellm: One framework to align all modalities with language. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26584–26595 (2024)
2024
-
[18]
In: Proceedings The Hidden Evolution of Disguised Visual Context inside the VLM 17 of the IEEE/CVF conference on computer vision and pattern recognition
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., et al.: Cogagent: A visual language model for gui agents. In: Proceedings The Hidden Evolution of Disguised Visual Context inside the VLM 17 of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14281–14290 (2024)
2024
-
[19]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
2019
-
[20]
In: International conference on machine learning
Jaegle, A., Gimeno, F., Brock, A., Vinyals, O., Zisserman, A., Carreira, J.: Per- ceiver: General perception with iterative attention. In: International conference on machine learning. pp. 4651–4664. PMLR (2021)
2021
-
[21]
arXiv preprint arXiv:2410.02762 (2024)
Jiang, N., Kachinthaya, A., Petryk, S., Gandelsman, Y.: Interpreting and edit- ing vision-language representations to mitigate hallucinations. arXiv preprint arXiv:2410.02762 (2024)
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jiang, Z., Chen, J., Zhu, B., Luo, T., Shen, Y., Yang, X.: Devils in middle lay- ers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25004–25014 (2025)
2025
-
[23]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kaduri, O., Bagon, S., Dekel, T.: What’s in the image? a deep-dive into the vision of vision language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14549–14558 (2025)
2025
-
[24]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Kafle,K.,Price,B.,Cohen,S.,Kanan,C.:Dvqa:Understandingdatavisualizations via question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5648–5656 (2018)
2018
-
[25]
arXiv preprint arXiv:2503.03321 (2025)
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. arXiv preprint arXiv:2503.03321 (2025)
-
[26]
In: European conference on computer vision
Kembhavi, A., Salvato, M., Kolve, E., Seo, M., Hajishirzi, H., Farhadi, A.: A di- agram is worth a dozen images. In: European conference on computer vision. pp. 235–251. Springer (2016)
2016
-
[27]
In: European Conference on Computer Vision
Kim, G., Hong, T., Yim, M., Nam, J., Park, J., Yim, J., Hwang, W., Yun, S., Han, D., Park, S.: Ocr-free document understanding transformer. In: European Conference on Computer Vision. pp. 498–517. Springer (2022)
2022
-
[28]
In: International conference on machine learning
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.: Similarity of neural network rep- resentations revisited. In: International conference on machine learning. pp. 3519–
-
[29]
Advances in Neural Information Processing Systems36, 71683–71702 (2023)
Laurençon, H., Saulnier, L., Tronchon, L., Bekman, S., Singh, A., Lozhkov, A., Wang, T., Karamcheti, S., Rush, A., Kiela, D., et al.: Obelics: An open web- scale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems36, 71683–71702 (2023)
2023
-
[30]
Laurençon, H., Tronchon, L., Cord, M., Sanh, V.: What matters when building vision-language models? Advances in Neural Information Processing Systems37, 87874–87907 (2024)
2024
-
[31]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Li, B., Zhang, Y., Chen, L., Wang, J., Pu, F., Cahyono, J.A., Yang, J., Li, C., Liu, Z.: Otter: A multi-modal model with in-context instruction tuning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[32]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Li, B., Wang, R., Wang, G., Ge, Y., Ge, Y., Shan, Y.: Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) 18 Suharitdamrong et al
2023
-
[35]
Li, Y., Wang, C., Jia, J.: Llama-vid: An image is worth 2 tokens in large lan- guagemodels.In:EuropeanConferenceonComputerVision.pp.323–340.Springer (2024)
2024
-
[36]
Ad- vances in Neural Information Processing Systems35, 17612–17625 (2022)
Liang, V.W., Zhang, Y., Kwon, Y., Yeung, S., Zou, J.Y.: Mind the gap: Under- standing the modality gap in multi-modal contrastive representation learning. Ad- vances in Neural Information Processing Systems35, 17612–17625 (2022)
2022
-
[37]
IEEE Transactions on Multimedia (2026)
Lin, B., Tang, Z., Ye, Y., Huang, J., Zhang, J., Pang, Y., Jin, P., Ning, M., Luo, J., Yuan, L.: Moe-llava: Mixture of experts for large vision-language models. IEEE Transactions on Multimedia (2026)
2026
-
[38]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971– 5984 (2024)
2024
-
[39]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lin, J., Chen, H., Fan, Y., Fan, Y., Jin, X., Su, H., Fu, J., Shen, X.: Multi-layer visual feature fusion in multimodal llms: Methods, analysis, and best practices. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4156–4166 (2025)
2025
-
[40]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[41]
Lin, Z., Liu, C., Zhang, R., Gao, P., Qiu, L., Xiao, H., Qiu, H., Lin, C., Shao, W., Chen, K., et al.: Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[43]
io/blog/2024-01-30-llava-next/
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/
2024
-
[44]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[45]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024)
2024
-
[46]
Science China Information Sciences67(12), 220102 (2024)
Liu, Y., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.C., Liu, C.L., Jin, L., Bai, X.: Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences67(12), 220102 (2024)
2024
-
[47]
Advances in neural information processing systems35, 2507– 2521 (2022)
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.W., Zhu, S.C., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in neural information processing systems35, 2507– 2521 (2022)
2022
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Luo, G., Yang, X., Dou, W., Wang, Z., Liu, J., Dai, J., Qiao, Y., Zhu, X.: Mono- internvl: Pushing the boundaries of monolithic multimodal large language models with endogenous visual pre-training. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24960–24971 (2025)
2025
-
[49]
arXiv preprint arXiv:2408.11795 (2024)
Ma, F., Zhou, Y., Zhang, Z., Yan, S., Li, H., He, Z., Wu, S., Rao, F., Zhang, Y., Sun, X.: Ee-mllm:A data-efficient and compute-efficient multimodal largelanguage model. arXiv preprint arXiv:2408.11795 (2024)
-
[50]
In: Proceedings of the 17th Conference of the Eu- ropean Chapter of the Association for Computational Linguistics
Mañas, O., Lopez, P.R., Ahmadi, S., Nematzadeh, A., Goyal, Y., Agrawal, A.: Mapl: Parameter-efficient adaptation of unimodal pre-trained models for vision- The Hidden Evolution of Disguised Visual Context inside the VLM 19 language few-shot prompting. In: Proceedings of the 17th Conference of the Eu- ropean Chapter of the Association for Computational Lin...
2023
-
[51]
Advances in Neural Information Processing Systems36, 46212–46244 (2023)
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems36, 46212–46244 (2023)
2023
-
[52]
In: Findings of the association for computational linguistics: ACL 2022
Masry, A., Do, X.L., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of the association for computational linguistics: ACL 2022. pp. 2263–2279 (2022)
2022
-
[53]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Mathew, M., Karatzas, D., Jawahar, C.: Docvqa: A dataset for vqa on document images. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2200–2209 (2021)
2021
-
[54]
In: Proceedings of the Cray User Group, pp
McIntosh-Smith, S., Alam, S., Woods, C.: Isambard-ai: a leadership-class super- computer optimised specifically for artificial intelligence. In: Proceedings of the Cray User Group, pp. 44–54 (2024)
2024
-
[55]
Ad- vances in Neural Information Processing Systems37, 23464–23487 (2024)
Meng, L., Yang, J., Tian, R., Dai, X., Wu, Z., Gao, J., Jiang, Y.G.: Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms. Ad- vances in Neural Information Processing Systems37, 23464–23487 (2024)
2024
-
[56]
arXiv preprint arXiv:2209.15162 (2022)
Merullo, J., Castricato, L., Eickhoff, C., Pavlick, E.: Linearly mapping from image to text space. arXiv preprint arXiv:2209.15162 (2022)
-
[57]
In: 2019 international conference on document analysis and recognition (ICDAR)
Mishra, A., Shekhar, S., Singh, A.K., Chakraborty, A.: Ocr-vqa: Visual question answering by reading text in images. In: 2019 international conference on document analysis and recognition (ICDAR). pp. 947–952. IEEE (2019)
2019
-
[58]
arXiv preprint arXiv:2410.07149 (2024)
Neo, C., Ong, L., Torr, P., Geva, M., Krueger, D., Barez, F.: Towards inter- preting visual information processing in vision-language models. arXiv preprint arXiv:2410.07149 (2024)
- [59]
- [60]
-
[61]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., et al.: Longvu: Spatiotemporal adaptive compression for long video-language understanding. arXiv preprint arXiv:2410.17434 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Advances in Neural Information Processing Sys- tems37, 130848–130886 (2024)
Shukor, M., Cord, M.: Implicit multimodal alignment: On the generalization of frozen llms to multimodal inputs. Advances in Neural Information Processing Sys- tems37, 130848–130886 (2024)
2024
-
[63]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8317–8326 (2019)
2019
-
[64]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Advances in Neural Information Processing Systems 37, 87310–87356 (2024)
Tong, P., Brown, E., Wu, P., Woo, S., Iyer, A.J.V., Akula, S.C., Yang, S., Yang, J., Middepogu, M., Wang, Z., et al.: Cambrian-1: A fully open, vision-centric ex- ploration of multimodal llms. Advances in Neural Information Processing Systems 37, 87310–87356 (2024)
2024
-
[66]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025) 20 Suharitdamrong et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Advances in Neural Infor- mation Processing Systems34, 200–212 (2021)
Tsimpoukelli, M., Menick, J.L., Cabi, S., Eslami, S., Vinyals, O., Hill, F.: Multi- modal few-shot learning with frozen language models. Advances in Neural Infor- mation Processing Systems34, 200–212 (2021)
2021
-
[68]
arXiv preprint arXiv:2503.20680 (2025)
Wang, H., Ye, Y., Li, B., Nie, Y., Lu, J., Tang, J., Wang, Y., Huang, C.: Vision as lora. arXiv preprint arXiv:2503.20680 (2025)
-
[69]
Advances in Neural Information Processing Systems37, 121475–121499 (2024)
Wang, W., Lv, Q., Yu, W., Hong, W., Qi, J., Wang, Y., Ji, J., Yang, Z., Zhao, L., XiXuan, S., et al.: Cogvlm: Visual expert for pretrained language models. Advances in Neural Information Processing Systems37, 121475–121499 (2024)
2024
-
[70]
Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024)
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024)
2024
-
[71]
xAI: Grok-1.5 vision preview.https://x.ai/news/grok-1.5v(April 2024), ac- cessed: 2026-03-08
2024
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiao,J.,Shang,X.,Yao,A.,Chua,T.S.:Next-qa:Nextphaseofquestion-answering to explaining temporal actions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9777–9786 (2021)
2021
-
[73]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Ye, J., Xu, H., Liu, H., Hu, A., Yan, M., Qian, Q., Zhang, J., Huang, F., Zhou, J.: mplug-owl3: Towards long image-sequence understanding in multi-modal large language models. arXiv preprint arXiv:2408.04840 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
arXiv preprint arXiv:2508.20279 (2025)
Yu, Z., Lee, Y.J.: How multimodal llms solve image tasks: A lens on visual ground- ing, task reasoning, and answer decoding. arXiv preprint arXiv:2508.20279 (2025)
-
[76]
arXiv preprint arXiv:2506.16691 (2025)
Yue, T., Guo, L., Tang, Y., Zhao, Z., Zhu, X., Huang, H., Liu, J.: Lavi: Effi- cient large vision-language models via internal feature modulation. arXiv preprint arXiv:2506.16691 (2025)
-
[77]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9556–9567 (2024)
2024
-
[78]
Zellers,R.,Holtzman,A.,Bisk,Y.,Farhadi,A.,Choi,Y.:Hellaswag:Canamachine really finish your sentence? In: Proceedings of the 57th annual meeting of the association for computational linguistics. pp. 4791–4800 (2019)
2019
-
[79]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, K., Shen, Y., Li, B., Liu, Z.: Large multi-modal models can interpret fea- tures in large multi-modal models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3650–3661 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.