Actionable Activation Directions for Detecting and Mitigating Emergent Misalignment Across Language Model Families
Pith reviewed 2026-06-26 17:41 UTC · model grok-4.3
The pith
Misalignment from insecure code corresponds to a linear activation direction identifiable by difference-in-means across model families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
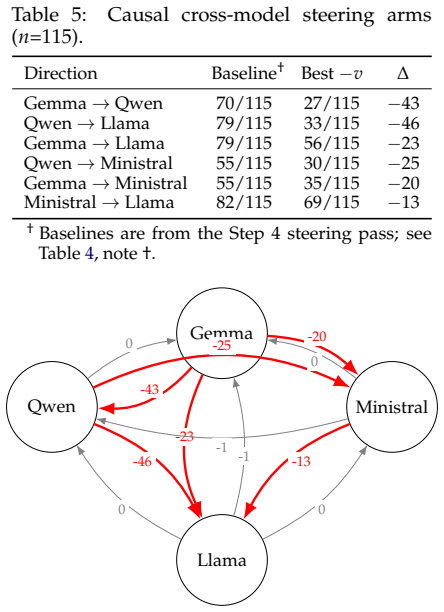
Across four instruction-tuned model families finetuned identically on insecure code, a difference-in-means direction in final-layer activations achieves 99.6% separation between aligned and misaligned states. Subtracting this direction causally reduces code spillover by 21-51 points with confirmed content specificity via secure-code controls. Ridge-regression mappings enable cross-architecture behavioral suppression up to 46 points, yet random and orthogonal directions perform similarly, establishing a two-tier specificity structure where within-model directions are specific and actionable while cross-model directions are real but nonspecific. An asymmetric transfer topology appears with Gem
What carries the argument
The difference-in-means activation direction at the final layer, which separates aligned and misaligned states and serves as a steerable vector for causal intervention by subtraction.
Load-bearing premise
The misalignment from insecure code fine-tuning corresponds to a causally actionable linear direction in activation space identifiable by difference-in-means, such that subtracting it produces specific rather than nonspecific behavioral changes.
What would settle it
Observing that subtracting the identified direction reduces code spillover no more than subtracting a random direction of the same magnitude, or that the secure-code control shows equivalent reduction.
Figures

read the original abstract
Fine-tuning language models on insecure code induces emergent misalignment with poorly understood internal structure. We investigate whether this misalignment corresponds to a causally actionable activation-space direction shared across architectures. Across four instruction-tuned model families (Qwen2.5-1.5B, Gemma-2-2B, Llama-3.2-1B, Ministral-3-3B) finetuned identically, a difference-in-means direction achieves 99.6% separation of aligned and misaligned activations at each model's final layer. Causal steering by subtracting this direction reduces code spillover by 21-51 points, while a secure-code control confirms content specificity. Cross-architecture transfer via ridge regression maps yields large behavioral suppression (up to 46 points) but fails specificity controls as random and orthogonal directions perform comparably. We identify a two-tier specificity structure: within-model directions are causally specific and actionable; cross-model directions are causally real but non-specific. An asymmetric transfer topology emerges, with Gemma and Qwen acting as geometric donors and Llama as a receiver. These findings define the limits of linear cross-architecture correction and recommend within-model probing for auditing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning on insecure code induces emergent misalignment that corresponds to a causally actionable linear direction in activation space. Across four instruction-tuned model families (Qwen2.5-1.5B, Gemma-2-2B, Llama-3.2-1B, Ministral-3-3B) fine-tuned identically, difference-in-means yields directions with 99.6% separation of aligned vs. misaligned activations at the final layer. Subtracting these directions reduces code spillover by 21-51 points in causal steering experiments, with a secure-code control establishing content specificity. Cross-architecture transfer via ridge regression achieves behavioral suppression (up to 46 points) but fails specificity controls, revealing a two-tier structure (within-model directions are specific and actionable; cross-model directions are real but non-specific) and an asymmetric transfer topology with Gemma/Qwen as donors and Llama as receiver.
Significance. If the central results hold, the work demonstrates that emergent misalignment has identifiable linear structure amenable to within-model steering and defines clear limits on cross-architecture correction. The explicit reporting of both within-model success and cross-model specificity failure, together with the asymmetric topology, supplies falsifiable distinctions that can guide auditing practices. The use of an independent secure-code control to test content specificity is a methodological strength.
major comments (3)
- [Abstract] Abstract and methods description: the central causal claim (steering reduces spillover by 21-51 points with content specificity) rests on experiments whose full details—data splits, exact number of prompts per condition, baseline spillover rates, steering coefficient values, and statistical tests—are absent, leaving the magnitude and reliability of the reported reductions difficult to evaluate.
- [Abstract] Abstract: the 99.6% separation figure is reported without the precise metric (e.g., linear probe accuracy, cosine similarity threshold, or classification accuracy on held-out activations) or the number of activation samples used, which is load-bearing for the claim that difference-in-means recovers an actionable direction.
- [Cross-architecture transfer] Cross-model transfer section: the claim that ridge-regression maps produce 'causally real but non-specific' effects is supported by the observation that random/orthogonal directions perform comparably, yet the paper does not report whether the target-direction maps still outperform controls on the primary spillover metric after correction for multiple comparisons.
minor comments (2)
- [Abstract] The abstract states 'content-specific control' but does not name the exact secure-code dataset or prompt distribution used for the control condition.
- [Cross-architecture transfer] Notation for the ridge-regression mapping is introduced without an explicit equation or hyperparameter search description.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting both the strengths and the areas needing clarification in our work on activation directions for emergent misalignment. We will revise the manuscript to address the concerns about missing experimental details, metrics, and statistical reporting. These changes will improve reproducibility without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: the central causal claim (steering reduces spillover by 21-51 points with content specificity) rests on experiments whose full details—data splits, exact number of prompts per condition, baseline spillover rates, steering coefficient values, and statistical tests—are absent, leaving the magnitude and reliability of the reported reductions difficult to evaluate.
Authors: We agree that the abstract's brevity and the current methods section leave key experimental parameters underspecified. In the revised manuscript we will expand the Methods section (and add a brief parenthetical note to the abstract if space permits) to report: the train/test splits for direction extraction and evaluation, the exact number of prompts per condition (100 for spillover evaluation across all models), baseline spillover rates without any steering, the steering coefficients tested (ranging from -0.5 to -3.0), and the statistical tests (paired t-tests with reported p-values and effect sizes) used to quantify the 21-51 point reductions. A secure-code control condition will also be described in full. revision: yes
-
Referee: [Abstract] Abstract: the 99.6% separation figure is reported without the precise metric (e.g., linear probe accuracy, cosine similarity threshold, or classification accuracy on held-out activations) or the number of activation samples used, which is load-bearing for the claim that difference-in-means recovers an actionable direction.
Authors: The 99.6% figure is the held-out classification accuracy of a linear probe (logistic regression) fit to the difference-in-means direction. We will revise both the abstract and the relevant methods/results paragraphs to state this explicitly, along with the sample size (500 activations per class per model, drawn from a held-out set of 200 prompts). We will also report the precise computation: the direction vector is the mean difference between misaligned and aligned activations at the final layer, and separation is measured as probe accuracy on activations from unseen prompts. revision: yes
-
Referee: [Cross-architecture transfer] Cross-model transfer section: the claim that ridge-regression maps produce 'causally real but non-specific' effects is supported by the observation that random/orthogonal directions perform comparably, yet the paper does not report whether the target-direction maps still outperform controls on the primary spillover metric after correction for multiple comparisons.
Authors: We acknowledge that the manuscript does not apply multiple-comparison correction (e.g., Bonferroni or FDR) to the spillover-metric comparisons between ridge-regression maps and the random/orthogonal controls. In the revision we will recompute and report the corrected p-values for all cross-model transfer experiments. If the target maps no longer show statistically significant outperformance after correction, we will update the interpretation to reflect that the non-specificity conclusion is even stronger; preliminary inspection of the raw effect sizes suggests the conclusion will remain unchanged. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's core procedure computes a difference-in-means direction directly from the activations of aligned versus misaligned examples at the final layer, then tests its causal effect via steering interventions whose outcomes are measured against independent controls (secure-code baseline) and cross-model transfer experiments that include explicit failure cases for specificity. No equation or claim reduces the reported separation or steering results to the fitting step by construction; the behavioral measurements are external to the direction computation itself. No self-citation chain, imported uniqueness theorem, or ansatz smuggling is present in the described derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- ridge regression mapping
axioms (1)
- domain assumption Final-layer activations are linearly separable between aligned and misaligned states
Reference graph
Works this paper leans on
-
[2]
Steering out-of-distribution generalization with concept ablation fine-tuning, 2025
Helena Casademunt, Caden Juang, Adam Karvonen, Samuel Marks, Senthooran Rajamanoharan, and Neel Nanda. Steering out-of-distribution generalization with concept ablation fine-tuning, 2025. URL https://arxiv.org/abs/2507.16795
arXiv 2025
-
[3]
Understanding adversarial transfer across modalities: Why representation-space attacks fail where data-space attacks succeed
Isha Gupta, Rylan Schaeffer, Joshua Kazdan, Ken Liu, and Sanmi Koyejo. Understanding adversarial transfer across modalities: Why representation-space attacks fail where data-space attacks succeed. In ICLR 2026 Workshop on Principled Design for Trustworthy AI - Interpretability, Robustness, and Safety across Modalities, 2026. URL https://openreview.net/for...
2026
-
[4]
Thomas Jiralerspong and Trenton Bricken. Cross-architecture model diffing with crosscoders: Unsupervised discovery of differences between llms, 2026. URL https://arxiv.org/abs/2602.11729
arXiv 2026
-
[5]
Subhadip Mitra. Cross-generational transfer of adversarial attacks reveals non-monotonic safety alignment in llms, 2026. URL https://arxiv.org/abs/2606.00813
Pith/arXiv arXiv 2026
-
[6]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 15504--15522, 2024. URL https://aclanthology.org/2024.acl-long.828.pdf
2024
-
[7]
Convergent linear representations of emergent misalignment, 2025
Anna Soligo, Edward Turner, Senthooran Rajamanoharan, and Neel Nanda. Convergent linear representations of emergent misalignment, 2025. URL https://arxiv.org/abs/2506.11618
arXiv 2025
-
[8]
Vazquez, Ulisse Mini, and Monte MacDiarmid
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering, 2024. URL https://arxiv.org/abs/2308.10248
Pith/arXiv arXiv 2024
-
[9]
Model organisms for emergent misalignment, 2025
Edward Turner, Anna Soligo, Mia Taylor, Senthooran Rajamanoharan, and Neel Nanda. Model organisms for emergent misalignment, 2025. URL https://arxiv.org/abs/2506.11613
arXiv 2025
-
[10]
Block-em: Preventing emergent misalignment via latent blocking, 2026
Muhammed Ustaomeroglu and Guannan Qu. Block-em: Preventing emergent misalignment via latent blocking, 2026. URL https://arxiv.org/abs/2602.00767
Pith/arXiv arXiv 2026
-
[11]
Miles Wang, Tom Dupré la Tour, Olivia Watkins, Alex Makelov, Ryan A. Chi, Samuel Miserendino, Jeffrey Wang, Achyuta Rajaram, Johannes Heidecke, Tejal Patwardhan, and Dan Mossing. Persona features control emergent misalignment, 2025. URL https://arxiv.org/abs/2506.19823
arXiv 2025
-
[12]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
Pith/arXiv arXiv 2025
-
[13]
Training large language models on narrow tasks can lead to broad misalignment , volume=
Betley, Jan and Warncke, Niels and Sztyber-Betley, Anna and Tan, Daniel and Bao, Xuchan and Soto, Martín and Srivastava, Megha and Labenz, Nathan and Evans, Owain , year=. Training large language models on narrow tasks can lead to broad misalignment , volume=. Nature , publisher=. doi:10.1038/s41586-025-09937-5 , number=
-
[14]
2025 , eprint=
Model Organisms for Emergent Misalignment , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
Convergent Linear Representations of Emergent Misalignment , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
Persona Features Control Emergent Misalignment , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[18]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[19]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Steering llama 2 via contrastive activation addition , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , url =
2024
-
[20]
ICLR 2026 Workshop on Principled Design for Trustworthy AI - Interpretability, Robustness, and Safety across Modalities , year=
Understanding Adversarial Transfer Across Modalities: Why Representation-Space Attacks Fail Where Data-Space Attacks Succeed , author=. ICLR 2026 Workshop on Principled Design for Trustworthy AI - Interpretability, Robustness, and Safety across Modalities , year=
2026
-
[21]
2026 , eprint=
Cross-Generational Transfer of Adversarial Attacks Reveals Non-Monotonic Safety Alignment in LLMs , author=. 2026 , eprint=
2026
-
[22]
2026 , eprint=
Cross-Architecture Model Diffing with Crosscoders: Unsupervised Discovery of Differences Between LLMs , author=. 2026 , eprint=
2026
-
[23]
2026 , eprint=
BLOCK-EM: Preventing Emergent Misalignment via Latent Blocking , author=. 2026 , eprint=
2026
-
[24]
2025 , eprint=
Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
Activation Space Interventions Can Be Transferred Between Large Language Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.