Skill Coverage: A Test Adequacy Metric for Agent Skills
Pith reviewed 2026-06-27 13:31 UTC · model grok-4.3
The pith
Skill coverage shows existing agent benchmarks exercise only 39.90 to 43.98 percent of documented skill behavior constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
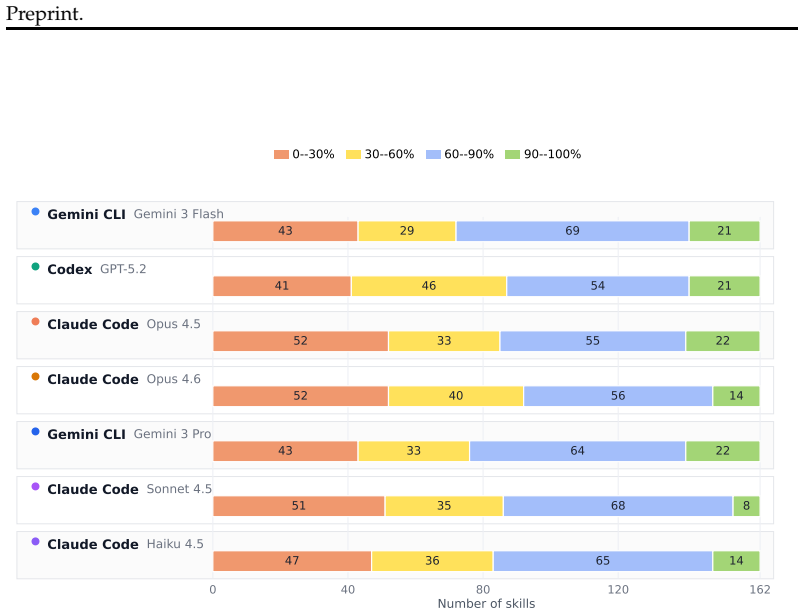
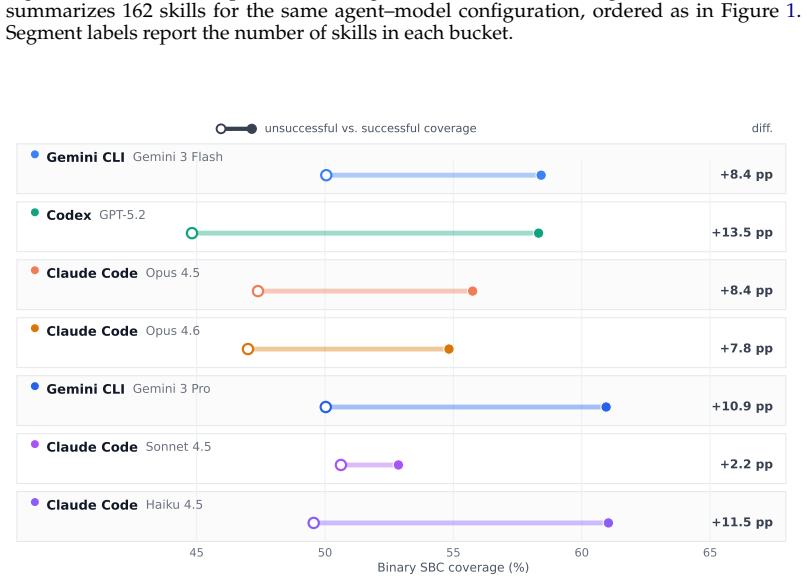
Skill coverage treats the skill artifact as the object under test. The method extracts observable skill behavior constraints from skill documents and measures whether an agent trajectory provides sufficient evidence to exercise and evaluate each constraint through a binary cover or not cover judgment that does not assign an additional outcome label. Application to SkillsBench shows that existing benchmark executions cover only 39.90 to 43.98 percent of skill behavior constraints, which demonstrates that successful task completion does not imply adequate testing of the skill artifact.
What carries the argument
Skill coverage metric, which extracts observable skill behavior constraints from skill documents and applies binary evidence-based coverage judgments to trajectories.
If this is right
- Successful task completion does not guarantee that all documented skill behavior constraints have been exercised.
- Current benchmark tasks leave over half of documented skill guidance untested.
- Test adequacy for agent skills requires explicit measurement of constraint coverage beyond task-level outcomes.
- Benchmark evaluations should report skill coverage in addition to task success rates.
Where Pith is reading between the lines
- New benchmark tasks could be designed specifically to target the uncovered constraints identified by the metric.
- The same extraction-and-judgment approach might be applied to evaluate coverage in other forms of procedural documentation used by agents.
- Skill documents themselves could be improved to make more constraints explicitly observable for testing purposes.
Load-bearing premise
Observable skill behavior constraints can be reliably extracted from skill documents and a binary judgment on whether a trajectory supplies sufficient evidence for each constraint can be made consistently without outcome labels.
What would settle it
Independent extraction of constraints from the same skill documents followed by re-judgment of the same trajectories that produces coverage rates outside the 39.90 to 43.98 percent range would falsify the reported coverage levels.
Figures

read the original abstract
Agent skills encode reusable procedural knowledge that guides large language model agents across tasks and execution contexts. Existing evaluations primarily assess skills through task level outcomes, yet task success alone does not reveal which parts of a skill have been exercised or which remain untested. We introduce skill coverage, a test adequacy metric that treats the skill artifact as the object under test. Our approach extracts observable skill behavior constraints from skill documents and measures whether an agent trajectory provides sufficient evidence to exercise and evaluate each constraint. Skill coverage uses a binary cover or not cover judgment, which reports whether a documented behavior has been exercised with sufficient observable evidence, without assigning an additional outcome label to the behavior. Applying skill coverage to SkillsBench reveals that existing benchmark executions cover only 39.90 to 43.98% of skill behavior constraints, suggesting that current benchmark tasks leave large portions of documented skill guidance untested. These findings show that successful task completion does not imply adequate testing of the skill artifact, highlighting skill coverage as a measure of how thoroughly agent skills are tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes skill coverage, a test adequacy metric for agent skills that extracts observable behavior constraints from skill documents and uses binary judgments to determine whether an agent trajectory supplies sufficient evidence for each constraint (without outcome labels). Applying the metric to SkillsBench shows existing benchmark executions cover only 39.90–43.98% of constraints, leading to the claim that task success does not imply adequate testing of the skill artifact.
Significance. If the extraction and judgment procedures prove reliable, the metric offers a useful complement to outcome-only evaluations by quantifying how thoroughly documented skill guidance is exercised. The paper correctly distinguishes task-level success from coverage of the skill document itself and applies the metric to an external benchmark, which is a constructive step toward more granular agent evaluation.
major comments (2)
- [Section 3] Section 3 and the evaluation protocol: the central empirical result (39.90–43.98% coverage) depends on two unvalidated steps—extraction of observable skill behavior constraints from documents and binary “sufficient evidence” judgments on trajectories—yet no inter-annotator agreement statistics or blinded validation against ground-truth covered trajectories are reported.
- [Evaluation protocol] Evaluation protocol: the binary judgments are presented as deterministic once constraints are fixed, but the protocol withholds outcome labels; without a comparison to human experts who have access to task success/failure or to known covered/uncovered trajectories, the reported coverage interval cannot be treated as a stable property of the benchmark executions.
Simulated Author's Rebuttal
Thank you for the referee's thoughtful comments. We address each major comment below and commit to revisions where the manuscript lacks supporting validation.
read point-by-point responses
-
Referee: [Section 3] Section 3 and the evaluation protocol: the central empirical result (39.90–43.98% coverage) depends on two unvalidated steps—extraction of observable skill behavior constraints from documents and binary “sufficient evidence” judgments on trajectories—yet no inter-annotator agreement statistics or blinded validation against ground-truth covered trajectories are reported.
Authors: We agree that the manuscript does not report inter-annotator agreement or blinded validation for constraint extraction and binary judgments. While the extraction targets observable behaviors described in skill documents and the judgments assess presence of sufficient evidence without outcome labels, these steps would benefit from explicit reliability metrics. In the revised manuscript we will add a validation subsection that reports IAA on a sampled subset of constraints and judgments together with a blinded comparison against a set of ground-truth covered/uncovered trajectories. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol: the binary judgments are presented as deterministic once constraints are fixed, but the protocol withholds outcome labels; without a comparison to human experts who have access to task success/failure or to known covered/uncovered trajectories, the reported coverage interval cannot be treated as a stable property of the benchmark executions.
Authors: The metric is intentionally outcome-agnostic because task success does not guarantee that every documented constraint has been exercised; the binary judgment therefore relies solely on observable evidence matching each constraint. Nevertheless, we accept that external validation against expert judgments (with and without outcome information) is needed to establish stability of the 39.90–43.98 % figures. The revision will include such a comparison on a held-out sample of trajectories. revision: yes
Circularity Check
No circularity: metric defined independently and applied to external benchmark
full rationale
The paper introduces skill coverage by defining extraction of observable constraints from skill documents and binary coverage judgments on trajectories. This definition stands alone and does not reference or depend on the SkillsBench coverage percentages. The reported 39.90–43.98% figures are the result of applying the metric, not inputs that construct it. No equations, fitted parameters, or self-citation chains reduce any claim to its own outputs. The derivation is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Skill documents contain extractable observable behavior constraints that admit consistent binary coverage judgments from trajectories.
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-05-19. Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, J. Q. Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health.ArXiv, abs/2505.08775,
Pith/arXiv arXiv 2026
-
[2]
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B
doi: 10.1109/TSE.2014.2372785. Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length- controlled alpacaeval: A simple way to debias automatic evaluators,
-
[3]
URL https://arxiv.org/abs/2404.04475. John B. Goodenough and Susan L. Gerhart. Toward a theory of test data selection.IEEE Transactions on Software Engineering, SE-1(2):156–173,
-
[4]
doi: 10.1109/TSE.1975.6312836. Orlena C. Z. Gotel and Anthony C. W. Finkelstein. An analysis of the requirements traceabil- ity problem. InProceedings of the IEEE International Conference on Requirements Engineering, pp. 94–101,
-
[5]
Xu Huang, Junwu Chen, Yuxing Fei, Zhuohan Li, P . Schwaller, and Gerbrand Ceder. Cascade: Cumulative agentic skill creation through autonomous development and evolution.ArXiv, abs/2512.23880,
-
[6]
ISO/IEC/IEEE 29148:2018: Systems and software engineering—life cycle processes—requirements engineering,
ISO/IEC/IEEE. ISO/IEC/IEEE 29148:2018: Systems and software engineering—life cycle processes—requirements engineering,
2018
-
[7]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jay Shin, yejin cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, S Shin, Ryan, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.),International Conference on Learning Representa- tions, vol...
2024
- [8]
-
[9]
doi: 10.1177/ 001316447003000308. 12 Preprint. Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, B. You, Haotian Shen, Jiankai Sun, Shuyi Wang, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yi Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang L...
-
[10]
URL https://api.semanticscholar.org/CorpusID:285606595. G. Ling, Shan Zhong, and R. Huang. Agent skills: A data-driven analysis of claude skills for extending large language model functionality.ArXiv, abs/2602.08004,
-
[11]
G-eval: Nlg evaluation using gpt-4 with better human alignment.ArXiv, abs/2303.16634,
Yang Liu, Dan Iter, Yichong Xu, Shuo Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment.ArXiv, abs/2303.16634,
-
[12]
Jaakkola, Yang Zhang, and Shiyu Chang
Yujian Liu, Jiabao Ji, Li An, T. Jaakkola, Yang Zhang, and Shiyu Chang. How well do agentic skills work in the wild: Benchmarking llm skill usage in realistic settings.ArXiv, abs/2604.04323,
-
[13]
PaperBench: Evaluating AI's Ability to Replicate AI Research
doi: 10.1109/ICST.2011.32. Giulio Starace, Oliver Jaffe, Dane Sherburn, J. Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, E. Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research.ArXiv, abs/2504.01848,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icst.2011.32 2011
-
[14]
doi: 10.1109/TSE.1986.6313008. Elaine J. Weyuker. The evaluation of program-based software test data adequacy criteria. Communications of the ACM, 31(6):668–675,
-
[15]
Whalen, Ajitha Rajan, Mats P
Michael W. Whalen, Ajitha Rajan, Mats P . E. Heimdahl, and Steven P . Miller. Coverage metrics for requirements-based testing. InProceedings of the 2006 International Symposium on Software Testing and Analysis, pp. 25–36,
2006
-
[16]
doi: 10.1145/1146238.1146242. Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. Flask: Fine-grained language model evaluation based on alignment skill sets.ArXiv, abs/2307.10928,
-
[17]
Openskilleval: Automatically auditing the open skill ecosystem for llm agents.ArXiv, abs/2605.23657,
Jiahao Ying, Bo Ai, Wei Tang, Siyuan Liu, and Yixin Cao. Openskilleval: Automatically auditing the open skill ecosystem for llm agents.ArXiv, abs/2605.23657,
-
[18]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, E. Xing, Haotong Zhang, Joseph E. Gonza- lez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena.ArXiv, abs/2306.05685,
-
[19]
Shan Zhong, Yiming Lu, Jingjie Ning, Yibing Wan, Lihang Feng, Yuyi Ao, Leonardo F. R. Ribeiro, Markus Dreyer, Sean Ammirati, and Chenyan Xiong. Skilllearnbench: Bench- marking continual learning methods for agent skill generation on real-world tasks.ArXiv, abs/2604.20087,
-
[20]
URLhttps://api.semanticscholar.org/CorpusID:287669099. 13 Preprint. Yingli Zhou, Wang Shu, Yaodong Su, Wenchuan Du, Yixiang Fang, and Xuemin Lin. A comprehensive survey on agent skills: Taxonomy, techniques, and applications.ArXiv, abs/2605.07358,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.