Beyond Importance: Interchange-Sobol Sensitivity Reveals Task-Specific Content Channels in Transformer Components
Pith reviewed 2026-06-27 04:01 UTC · model grok-4.3
The pith
Interchange-Group Sobol Decomposition separates content transport from computational degradation in transformer components by comparing replacement and ablation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
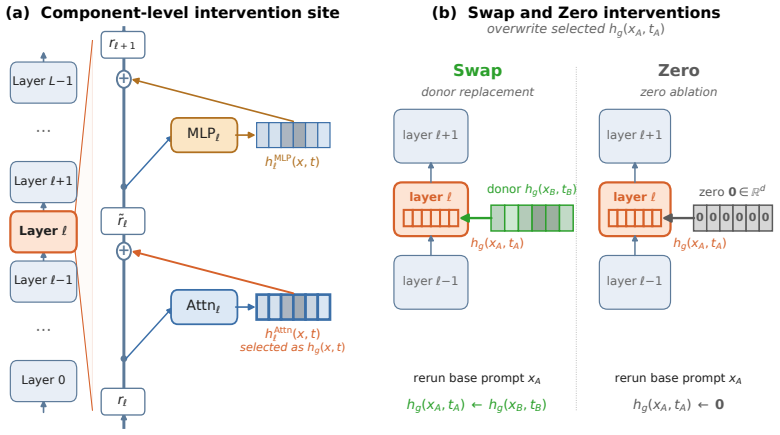
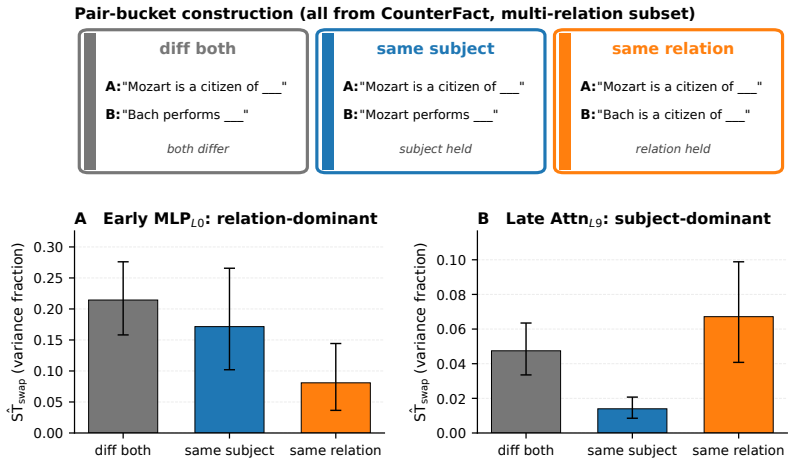
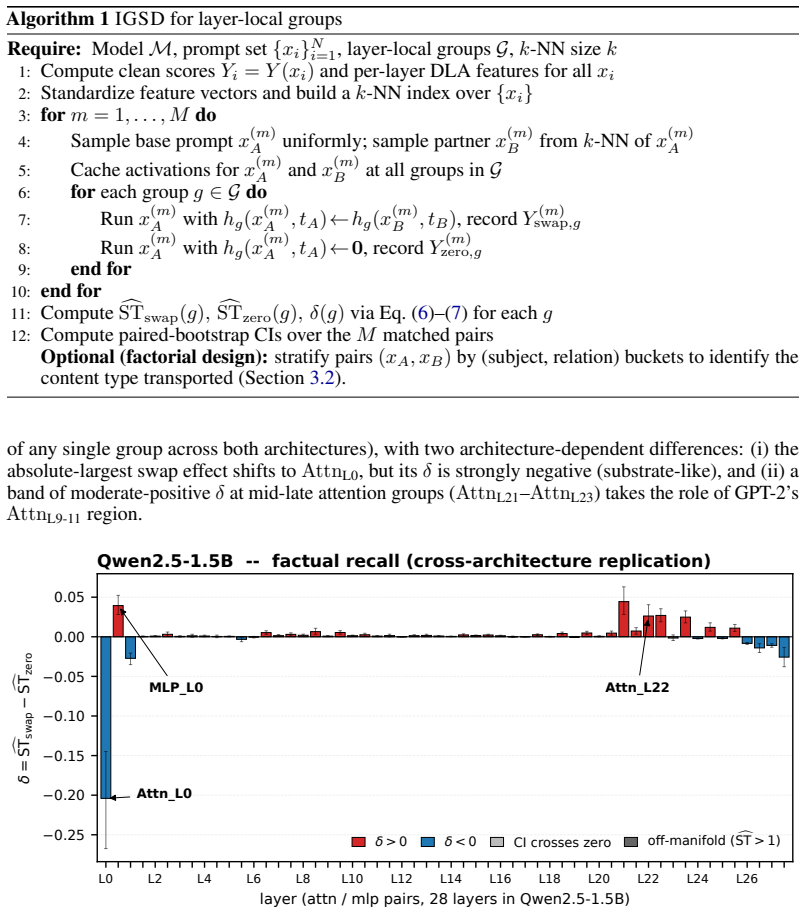
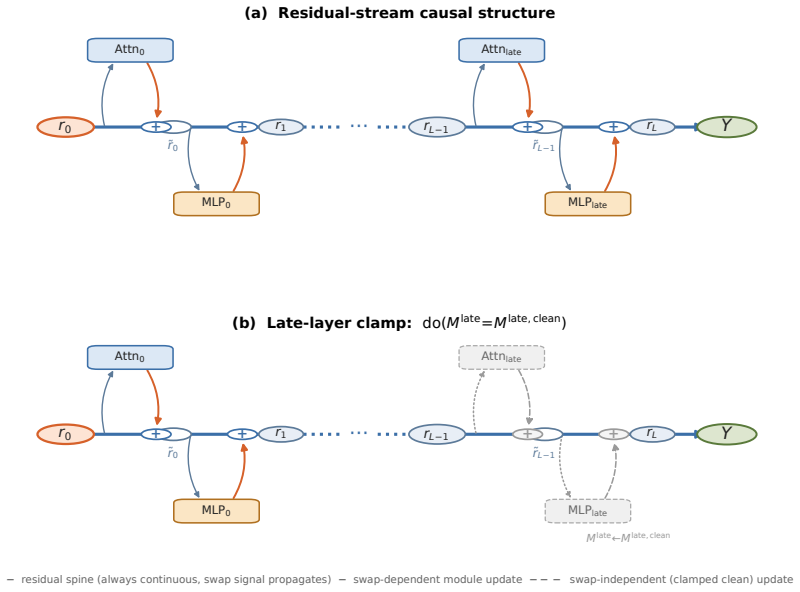
IGSD estimates two Sobol-style variance indices from paired replacement and ablation interventions on the same component, uses their signed difference to separate content-transport contributions from computational-degradation contributions, and monitors validity with the symmetric off-manifold diagnostic ĜST>1. In factual recall, it identifies an early-layer content channel that transports relation-frame content while late attention transports subject-retrieval content, refining at head level to Attn_L9H8, with the early signal expressed through later transformations rather than residual pass-through.
What carries the argument
Interchange-Group Sobol Decomposition (IGSD), a paired-intervention framework that compares matched activation replacement against zero ablation on the same component and separates their variance contributions via signed difference.
If this is right
- In factual recall, an early-layer channel carries relation content that standard importance methods underestimate.
- Late attention heads carry subject-retrieval content while the early channel carries relation-frame content.
- The early signal is expressed through downstream transformations rather than residual pass-through.
- Replacement and deletion interventions are not interchangeable and their divergence supplies a diagnostic for content transport.
- Head-granularity analysis isolates specific heads such as Attn_L9H8 as subject-retrieval carriers.
Where Pith is reading between the lines
- The divergence between replacement and ablation could serve as a general test for whether a component functions as a content carrier in other tasks.
- Importance rankings that ignore this distinction may systematically misattribute functional roles to components that mainly affect computation.
- The method suggests testing whether early content channels appear in non-recall tasks or in models of different scales.
Load-bearing premise
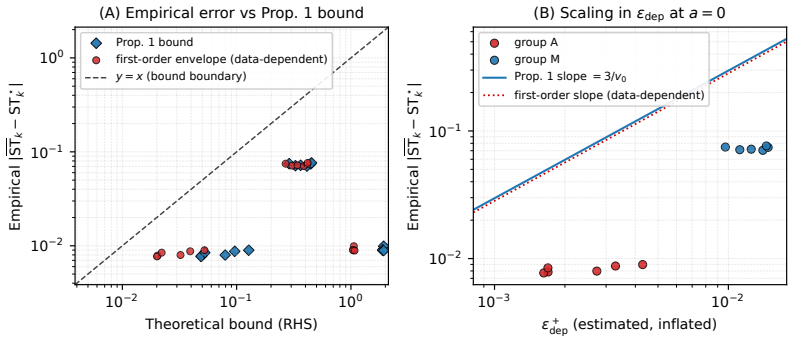
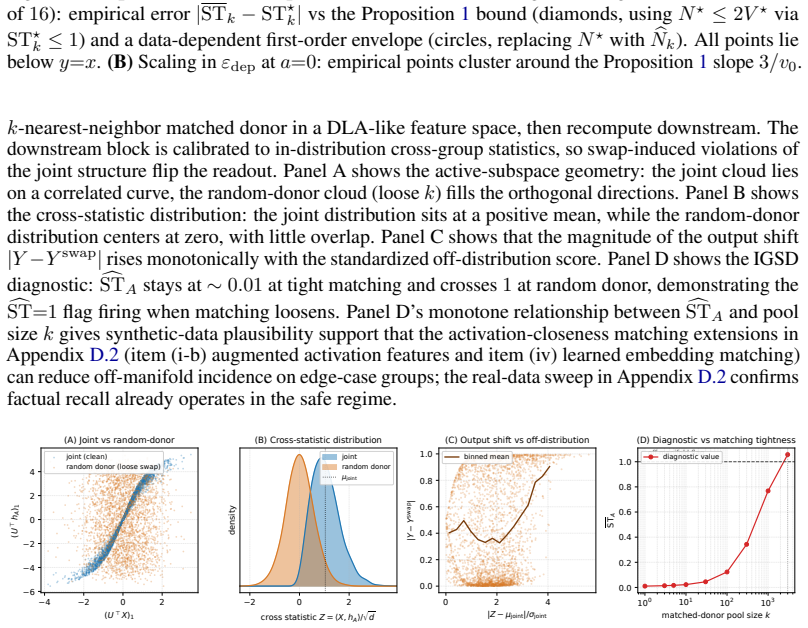
The symmetric off-manifold diagnostic reliably confirms intervention validity and the signed difference between the two variance indices cleanly isolates transport from degradation.
What would settle it
If the signed difference between replacement-based and ablation-based Sobol indices shows no systematic alignment with independent activation-patching measures of relation-frame content across layers, the separation between transport and degradation roles would be falsified.
Figures





read the original abstract
Mechanistic interpretability methods summarize a transformer component by a single importance score, conflating two distinct roles: a component may matter because it transports task-relevant content, or because the forward computation degrades when its contribution is removed. We introduce \emph{Interchange-Group Sobol Decomposition} (IGSD), a paired-intervention framework that compares matched activation replacement with zero ablation on the same component, estimates two Sobol-style variance indices, and uses their signed difference to separate the two roles, with intervention validity monitored by a symmetric off-manifold diagnostic $\widehat{\mathrm{ST}}>1$. In factual recall, IGSD identifies an early-layer content channel in both GPT-2 small and Qwen2.5-1.5B that standard importance methods underestimate. A controlled subject and relation donor design shows that the early channel transports relation-frame content while late attention transports subject-retrieval content, refining at head granularity to the known $\mathrm{Attn}_{L9H8}$ head. Late-layer clamping confirms that the early signal is expressed through downstream transformations rather than residual pass-through. These results show that replacement and deletion are not interchangeable controls and their divergence provides a practical statistical diagnostic for content transport in transformer components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Interchange-Group Sobol Decomposition (IGSD), a paired-intervention framework that estimates two Sobol-style variance indices from matched activation replacement versus zero ablation on the same transformer component. Their signed difference is used to separate content-transport roles from computational-degradation roles, with validity checked by a symmetric off-manifold diagnostic ĜST>1. Applied to factual-recall tasks, IGSD identifies an early-layer content channel in GPT-2 small and Qwen2.5-1.5B that standard importance scores underestimate; controlled donor experiments attribute relation-frame content to this channel and subject-retrieval content to late attention heads (refining to Attn_L9H8), with late-layer clamping confirming downstream expression rather than residual pass-through.
Significance. If the signed-difference attribution holds, the work supplies a concrete statistical diagnostic that refines mechanistic interpretability beyond scalar importance scores. The paired-intervention design and explicit off-manifold validity check are methodological strengths; the empirical separation of transport versus degradation roles in factual recall, together with head-level refinement, would be a useful addition to the interpretability toolkit.
major comments (2)
- [Abstract] Abstract and method description: the central claim that the signed difference of the two variance indices cleanly isolates content transport from degradation is load-bearing, yet the manuscript supplies no derivation showing that this difference is invariant to downstream residual-stream interactions or compensatory mechanisms. The skeptic's concern that replacement and ablation may induce partially overlapping distribution shifts therefore remains unaddressed.
- [§4] §4 (empirical results) and the description of ĜST>1: the symmetric off-manifold diagnostic is presented as validating the interventions, but no quantitative threshold justification, sensitivity analysis, or counter-example test is given to establish that ĜST>1 reliably rules out the confounding effects raised in the stress-test note.
minor comments (1)
- [Abstract] Notation: the symbol ĜST is introduced without an explicit equation reference in the abstract; a forward pointer to its definition would improve readability.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address the two major comments below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim that the signed difference of the two variance indices cleanly isolates content transport from degradation is load-bearing, yet the manuscript supplies no derivation showing that this difference is invariant to downstream residual-stream interactions or compensatory mechanisms. The skeptic's concern that replacement and ablation may induce partially overlapping distribution shifts therefore remains unaddressed.
Authors: The paired design of IGSD is intended to control for many of these effects by using matched interventions on the same component. However, we acknowledge the absence of an explicit derivation for invariance under residual-stream interactions. In the revision, we will add a theoretical section deriving the signed difference under a linear residual-stream model and discuss the conditions under which overlapping distribution shifts are minimized. We believe this addresses the core concern without altering the empirical findings. revision: yes
-
Referee: [§4] §4 (empirical results) and the description of ĜST>1: the symmetric off-manifold diagnostic is presented as validating the interventions, but no quantitative threshold justification, sensitivity analysis, or counter-example test is given to establish that ĜST>1 reliably rules out the confounding effects raised in the stress-test note.
Authors: We agree that additional validation for the ĜST>1 threshold would improve the paper. The threshold is chosen based on the point where the diagnostic indicates the intervention is off-manifold, but we will include a sensitivity analysis across different thresholds and a counter-example test using synthetic data in the revised §4. This will provide quantitative justification and demonstrate robustness against the noted confounding effects. revision: yes
Circularity Check
No circularity: IGSD framework is externally defined and applied without reduction to inputs or self-citations
full rationale
The paper introduces Interchange-Group Sobol Decomposition (IGSD) as a new paired-intervention method that computes two Sobol-style variance indices from matched replacement and zero-ablation interventions on the same component, then takes their signed difference to separate transport from degradation roles while using an off-manifold diagnostic for validity. This construction is defined from standard sensitivity-analysis primitives and the paper's own intervention design; it does not reduce by equation to fitted parameters, self-referential definitions, or prior author work. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or method description, and the empirical findings on early-layer channels in GPT-2 and Qwen2.5 are presented as applications rather than derivations that presuppose the target result. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The signed difference of Sobol indices from replacement versus ablation cleanly isolates content transport.
- domain assumption The off-manifold diagnostic ĜST>1 validates intervention quality.
Reference graph
Works this paper leans on
-
[1]
Mathematics and computers in simulation , volume=
Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates , author=. Mathematics and computers in simulation , volume=. 2001 , publisher=
2001
-
[2]
Design and estimator for the total sensitivity index , author=
Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index , author=. Computer physics communications , volume=. 2010 , publisher=
2010
-
[3]
Computer Physics Communications , volume=
Analysis of variance designs for model output , author=. Computer Physics Communications , volume=. 1999 , publisher=
1999
-
[4]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[5]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Advances in Neural Information Processing Systems , volume=
Towards automated circuit discovery for mechanistic interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Journal of Machine Learning Research , volume=
Causal abstraction: A theoretical foundation for mechanistic interpretability , author=. Journal of Machine Learning Research , volume=
-
[8]
Uncertainty in Artificial Intelligence , pages=
Approximate causal abstractions , author=. Uncertainty in Artificial Intelligence , pages=. 2020 , organization=
2020
-
[9]
Advances in Neural Information Processing Systems , volume=
Interpretability at scale: Identifying causal mechanisms in alpaca , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
The Non-Linear Representation Dilemma: Is Causal Abstraction Enough for Mechanistic Interpretability? , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[11]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , url=
2023
-
[12]
Advances in Neural Information Processing Systems , volume=
Investigating gender bias in language models using causal mediation analysis , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
How to use and interpret activation patching
How to use and interpret activation patching , author=. arXiv preprint arXiv:2404.15255 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
The Twelfth International Conference on Learning Representations , year=
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods , author=. The Twelfth International Conference on Learning Representations , year=
-
[15]
arXiv preprint arXiv:2403.00745 , year=
Atp*: An efficient and scalable method for localizing llm behaviour to components , author=. arXiv preprint arXiv:2403.00745 , year=
-
[16]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in. 2022 , url=
2022
-
[17]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Dissecting recall of factual associations in auto-regressive language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[18]
The Twelfth International Conference on Learning Representations , year=
Linearity of Relation Decoding in Transformer Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[19]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Interpretability of language models via task spaces , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
Transformer Circuits Thread , year =
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. Transformer Circuits Thread , year =
-
[21]
2024 , publisher=
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet , author=. 2024 , publisher=
2024
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Extracting interpretable task-specific circuits from large language models for faster inference , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[24]
2000 , publisher=
Asymptotic statistics , author=. 2000 , publisher=
2000
-
[25]
2022 , howpublished =
TransformerLens , author =. 2022 , howpublished =
2022
-
[26]
The Fourteenth International Conference on Learning Representations , year=
Circuit Insights: Towards Interpretability Beyond Activations , author=. The Fourteenth International Conference on Learning Representations , year=
-
[27]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[28]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2501.17520 , year=
Conditional Feature Importance revisited: Double Robustness, Efficiency and Inference , author=. arXiv preprint arXiv:2501.17520 , year=
-
[30]
Nature , volume=
Detecting hallucinations in large language models using semantic entropy , author=. Nature , volume=. 2024 , publisher=
2024
-
[31]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
Mechanistic Interpretability for
Leonard Bereska and Stratis Gavves , journal=. Mechanistic Interpretability for. 2024 , url=
2024
-
[33]
ACM Computing Surveys , volume=
Bridging the black box: A survey on mechanistic interpretability in ai , author=. ACM Computing Surveys , volume=. 2026 , publisher=
2026
-
[34]
Political Analysis , volume=
Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies , author=. Political Analysis , volume=. 2012 , publisher=
2012
-
[35]
Journal of the American Statistical Association , volume=
Optimal matching for observational studies , author=. Journal of the American Statistical Association , volume=. 1989 , publisher=
1989
-
[36]
Journal of the American Statistical Association , volume=
Using mixed integer programming for matching in an observational study of kidney failure after surgery , author=. Journal of the American Statistical Association , volume=. 2012 , publisher=
2012
-
[37]
, title=
Rosenbaum, Paul R. , title=. 2002 , address=
2002
-
[38]
2003 , publisher=
Partial identification of probability distributions , author=. 2003 , publisher=
2003
-
[39]
Econometrica , volume=
Confidence intervals for partially identified parameters , author=. Econometrica , volume=. 2004 , publisher=
2004
-
[40]
The Eleventh International Conference on Learning Representations , year=
Mass-Editing Memory in a Transformer , author=. The Eleventh International Conference on Learning Representations , year=
-
[41]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
International Conference on Learning Representations , volume=
A simple and effective pruning approach for large language models , author=. International Conference on Learning Representations , volume=
-
[44]
International conference on machine learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International conference on machine learning , pages=. 2023 , organization=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.