BARD-MARL: Byzantine-Agent Detection for Learned Communication in Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-27 02:17 UTC · model grok-4.3
The pith
BARD-MARL detects Byzantine agents in learned-communication multi-agent reinforcement learning by fusing policy-graph features with Bayesian trust statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
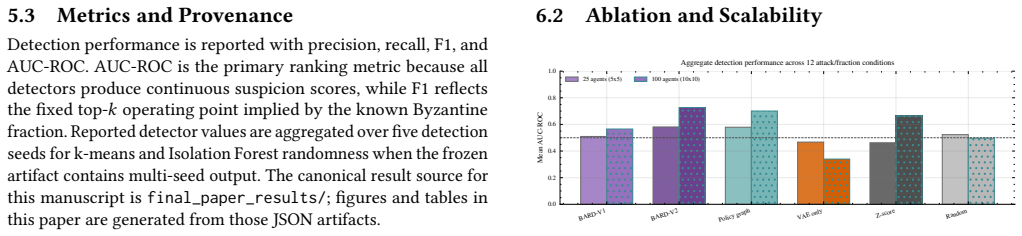
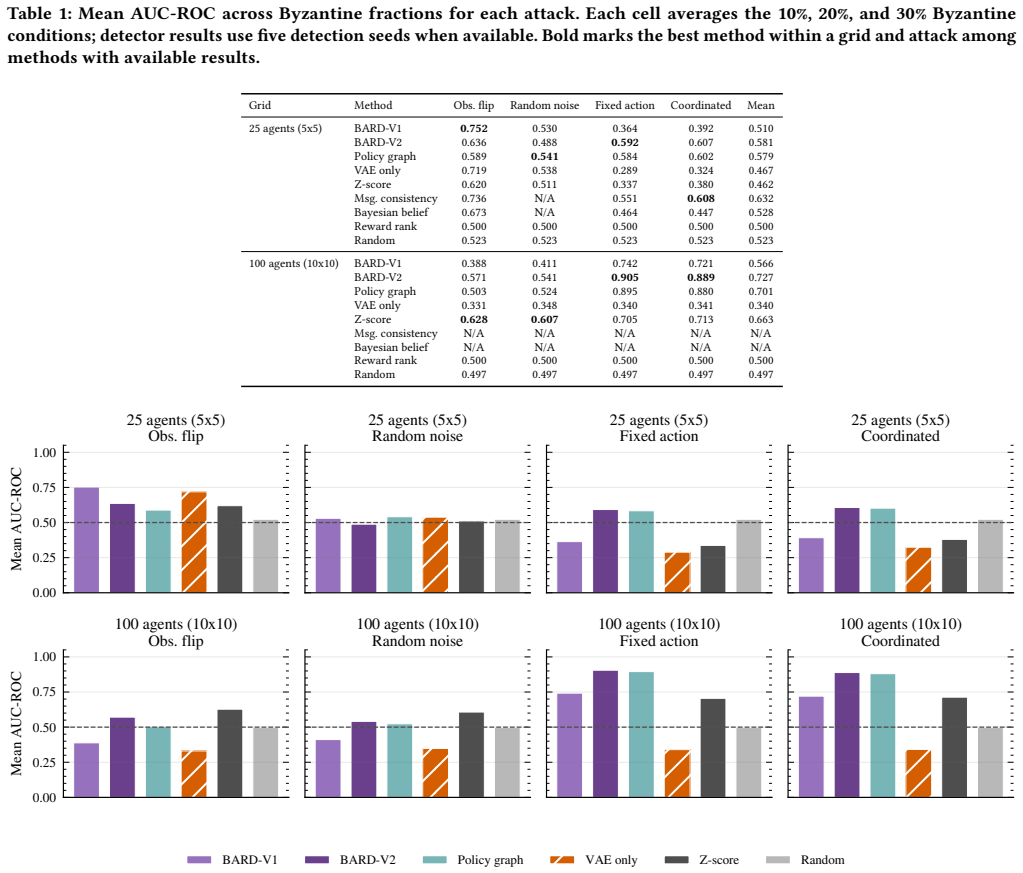
BARD-MARL is a post-hoc diagnostic layer on top of BayesG that combines policy-graph features extracted from state-action trajectories and Bayesian trust statistics computed from BayesG latent mask probabilities. Across various attacks in SUMO traffic grids, these signals are complementary, achieving 0.843 AUC-ROC on 25-agent grid under 10% observation-flip attack and 0.982 AUC-ROC on 100-agent grid for both 10% fixed-action and 10% coordinated attacks.
What carries the argument
BARD-MARL diagnostic layer fusing policy-graph features from trajectories and Bayesian trust from BayesG latent masks to detect Byzantine agents.
If this is right
- Learned communication policies expose useful diagnostic evidence for identifying faulty agents.
- Detection performance requires attack-specific ablations rather than universal claims.
- Coordination, detection, and mitigation must be treated as separate concerns for resilience.
- The unified variant scales to larger 100-agent grids with high AUC-ROC under fixed and coordinated attacks.
Where Pith is reading between the lines
- The complementarity of signals could be checked in non-traffic MARL settings such as robotics coordination tasks.
- Making detection part of the training loop rather than post-hoc might change the observed trade-offs.
- Online versions of the detector could be evaluated for handling agents that become faulty during operation.
Load-bearing premise
The two evidence streams remain informative and non-redundant under the specific attack models tested in SUMO without detection performance depending on post-training choices that were not ablated.
What would settle it
A test on an unseen attack model or grid size where the combined BARD-MARL AUC-ROC falls below that of policy-graph features alone or Bayesian trust alone.
Figures

read the original abstract
Learned communication improves coordination in cooperative multi-agent reinforcement learning, but it also creates a trust problem: a trained policy may route information through agents that have become faulty or adversarial. This paper studies Byzantine-agent detection for learned-communication MARL in adaptive traffic signal control. We propose BARD-MARL, a post-hoc diagnostic layer on top of BayesG, which is used as an attributed communication substrate rather than as a contribution of this paper. BARD-MARL combines two agent-level evidence streams: policy-graph features extracted from state-action trajectories and Bayesian trust statistics computed from BayesG latent mask probabilities. Across fixed-action, observation-flip, random-noise, and coordinated attacks in SUMO traffic grids, the results show that these signals are complementary rather than universally dominant. On a 25-agent grid, BARD-MARL reaches 0.843 AUC-ROC under a 10% observation-flip attack, while policy-graph-only detection reaches 0.917 AUC-ROC under a 10% coordinated attack. On a 100-agent grid, the unified BARD-MARL variant reaches 0.982 AUC-ROC for both 10% fixed-action and 10% coordinated attacks. The study shows that learned communication policies expose useful diagnostic evidence, but credible resilience claims require attack-specific ablations and explicit separation between coordination, detection, and mitigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BARD-MARL, a post-hoc diagnostic layer atop the BayesG communication substrate for detecting Byzantine agents in learned-communication MARL applied to adaptive traffic signal control. It extracts two agent-level evidence streams—policy-graph features from state-action trajectories and Bayesian trust statistics from BayesG latent-mask probabilities—and reports that these streams are complementary. On 25- and 100-agent SUMO grids it gives AUC-ROC values reaching 0.982 under 10% fixed-action and coordinated attacks, while also stressing the need for attack-specific ablations and explicit separation of coordination, detection, and mitigation.
Significance. If the complementarity result survives ablation of the post-training pipeline, the work supplies concrete evidence that learned communication policies expose usable diagnostic signals for resilience in cooperative MARL. The manuscript’s explicit separation of coordination/detection/mitigation phases and its call for attack-specific ablations are positive contributions to the literature on trustworthy multi-agent systems.
major comments (1)
- [Abstract / experimental results] Abstract (headline result): the claim that policy-graph features and BayesG-derived trust statistics are complementary (unified BARD-MARL reaching 0.982 AUC-ROC on the 100-agent grid for both 10% fixed-action and 10% coordinated attacks) rests on specific but unablated post-training choices—window length, aggregation function, and graph-construction threshold for the policy-graph stream; prior strength, aggregation rule, and decision threshold for the trust stream. No ablation of these knobs is reported, so the non-redundancy could be an artifact of post-hoc selection rather than an intrinsic property of the learned policy.
minor comments (1)
- [Abstract] The abstract states specific AUC-ROC figures but supplies no error bars, data-exclusion rules, or cross-validation protocol, making it impossible to assess statistical reliability of the reported performance gap between single-stream and unified detectors.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The single major comment raises a valid methodological concern about the robustness of the complementarity claim. We address it directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract (headline result): the claim that policy-graph features and BayesG-derived trust statistics are complementary (unified BARD-MARL reaching 0.982 AUC-ROC on the 100-agent grid for both 10% fixed-action and 10% coordinated attacks) rests on specific but unablated post-training choices—window length, aggregation function, and graph-construction threshold for the policy-graph stream; prior strength, aggregation rule, and decision threshold for the trust stream. No ablation of these knobs is reported, so the non-redundancy could be an artifact of post-hoc selection rather than an intrinsic property of the learned policy.
Authors: We agree that the reported complementarity between the two evidence streams is demonstrated only for the specific post-training parameter settings used in the experiments, and that the absence of systematic ablations on those choices (window length, aggregation functions, graph-construction threshold, prior strength, aggregation rules, and decision thresholds) leaves open the possibility that the observed non-redundancy is partly an artifact of post-hoc tuning. The manuscript does not contain such ablations. In the revised version we will add a dedicated sensitivity analysis section that varies each of these parameters over reasonable ranges, reports the resulting AUC-ROC values for each stream individually and for the combined detector, and quantifies how often the combined detector remains superior. This will allow readers to assess whether the complementarity holds across plausible hyper-parameter choices rather than only at the selected operating point. revision: yes
Circularity Check
No significant circularity; empirical detection metrics are independent of inputs
full rationale
The manuscript presents BARD-MARL as a post-hoc diagnostic layer atop the external BayesG substrate. Reported results consist of empirical AUC-ROC measurements on SUMO traffic grids under fixed attack models; no equations, fitted parameters, or self-citations are shown that reduce any performance claim to its own inputs by construction. The complementarity statement is a comparative observation across two evidence streams rather than a definitional or fitted equivalence. The derivation chain is therefore self-contained against external simulation benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BayesG serves as a valid attributed communication substrate whose latent mask probabilities yield useful Bayesian trust statistics
- domain assumption Policy-graph features extracted from state-action trajectories provide complementary diagnostic evidence to the Bayesian statistics
invented entities (1)
-
BARD-MARL diagnostic layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Osbert Bastani, Yewen Pu, and Armando Solar-Lezama. 2018. Verifiable Rein- forcement Learning via Policy Extraction. arXiv:1805.08328 [cs.LG]
Pith/arXiv arXiv 2018
-
[2]
Rohit Bokade, Xiaoning Jin, and Christopher Amato. 2023. Multi-Agent Re- inforcement Learning Based on Representational Communication for Large- Scale Traffic Signal Control. https://doi.org/10.1109/ACCESS.2023.3275883 arXiv:2310.02435 [cs.MA] IEEE Access
-
[3]
Christie Djidjev. 2024. siForest: Detecting Network Anomalies with Set- Structured Isolation Forest. arXiv:2412.06015 [cs.LG]
arXiv 2024
-
[4]
Wei Duan, Jie Lu, and Junyu Xuan. 2025. Bayesian Ego-graph Inference for Networked Multi-Agent Reinforcement Learning. arXiv:2509.16606 [cs.MA] Accepted at NeurIPS 2025
Pith/arXiv arXiv 2025
-
[5]
Raffaele Galliera, Kristen Brent Venable, Matteo Bassani, and Niranjan Suri
-
[6]
Collaborative Information Dissemination with Graph-based Multi-Agent Reinforcement Learning. arXiv:2308.16198 [cs.LG] 7
-
[7]
Anthony Goeckner, Yueyuan Sui, Nicolas Martinet, Xinliang Li, and Qi Zhu. 2024. Graph Neural Network-based Multi-agent Reinforcement Learning for Resilient Distributed Coordination of Multi-Robot Systems. arXiv:2403.13093 [cs.MA]
arXiv 2024
-
[8]
Hairi, Minghong Fang, Zifan Zhang, Alvaro Velasquez, and Jia Liu. 2024. On the Hardness of Decentralized Multi-Agent Policy Evaluation under Byzantine Attacks. arXiv:2409.12882 [cs.CR] To appear in WiOpt 2024
arXiv 2024
-
[9]
Muhammad Sami Irfan, Mizanur Rahman, Travis Atkison, Sagar Dasgupta, and Alexander Hainen. 2022. Reinforcement Learning based Cyberattack Model for Adaptive Traffic Signal Controller in Connected Transportation Systems. arXiv:2211.01845 [cs.CR]
arXiv 2022
-
[10]
Simin Li, Jun Guo, Jingqiao Xiu, Ruixiao Xu, Xin Yu, Jiakai Wang, Aishan Liu, Yaodong Yang, and Xianglong Liu. 2024. Byzantine Robust Cooperative Multi- Agent Reinforcement Learning as a Bayesian Game. arXiv:2305.12872 [cs.GT]
arXiv 2024
-
[11]
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. 2008. Isolation Forest. InPro- ceedings of the 2008 IEEE International Conference on Data Mining. IEEE Computer Society, Pisa, Italy, 413–422. https://doi.org/10.1109/ICDM.2008.17
-
[12]
Pablo Alvarez Lopez, Michael Behrisch, Laura Bieker-Walz, Jakob Erdmann, Yun- Pang Flötteröd, Robert Hilbrich, Leonhard Lücken, Johannes Rummel, Peter Wagner, and Evamarie Wießner. 2018. Microscopic Traffic Simulation using SUMO. InThe 21st IEEE International Conference on Intelligent Transportation Systems. IEEE, Maui, Hawaii, USA, 2575–2582. https://doi...
-
[13]
MacQueen
J. MacQueen. 1967. Some Methods for Classification and Analysis of Multivariate Observations. InProceedings of the Fifth Berkeley Symposium on Mathematical Sta- tistics and Probability, Vol. 1. University of California Press, Berkeley, California, 281–297. https://digicoll.lib.berkeley.edu/record/113015?v=pdf
1967
-
[14]
Sahar Salimpour, Farhad Keramat, Jorge Peña Queralta, and Tomi Westerlund
-
[15]
Decentralized Vision-Based Byzantine Agent Detection in Multi-Robot Systems with IOTA Smart Contracts. arXiv:2210.03441 [cs.RO]
-
[16]
Nicholay Topin and Manuela Veloso. 2019. Generation of Policy-Level Explana- tions for Reinforcement Learning. arXiv:1905.12044 [cs.LG] Accepted at AAAI 2019
Pith/arXiv arXiv 2019
-
[17]
Yijing Xie, Shaoshuai Mou, and Shreyas Sundaram. 2021. Towards Resilience for Multi-Agent𝑄𝐷-Learning. arXiv:2104.03153 [eess.SY]
arXiv 2021
-
[18]
Changxi Zhu, Mehdi Dastani, and Shihan Wang. 2024. A Survey of Multi-Agent Deep Reinforcement Learning with Communication.Autonomous Agents and Multi-Agent Systems38, 1 (2024), 4. arXiv:2203.08975 [cs.MA] 8
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.