AutoACSL: Synthesizing ACSL Specifications by Integrating LLMs with CPG-Based Static Analysis
Pith reviewed 2026-06-26 16:51 UTC · model grok-4.3
The pith
Extracting semantic features from code property graphs lets LLMs generate ACSL specifications that Frama-C can prove at much higher rates than code-only prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoACSL encodes arithmetic operations, loop and recursion structures, and return-value propagation extracted from code property graphs into structured prompts; an iterative loop then feeds candidate ACSL specifications to Frama-C/WP for verification and refinement until the program is proved or the process terminates.
What carries the argument
The feedback-driven synthesis loop that augments LLM prompts with CPG-derived semantic features and verifies each candidate contract against Frama-C/WP.
If this is right
- The same CPG features allow the LLM to add input constraints that prevent runtime errors in addition to normal behavioral specifications.
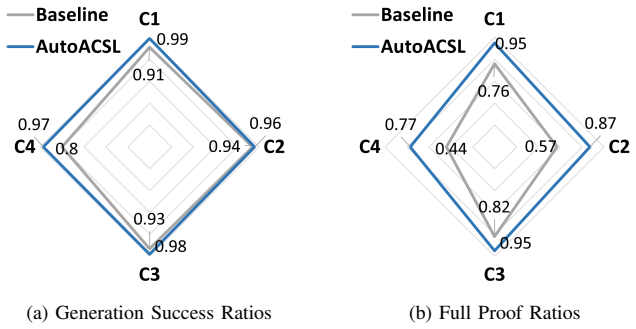
- Full proof success improves consistently across GPT-o4 Mini, GPT-5.2, Grok-4.1, and Gemini-3.
- The iterative verification loop terminates with a provable contract for 96 percent of programs when paired with Gemini-3.
Where Pith is reading between the lines
- The approach could be tested on programs containing pointer aliasing or concurrency to see whether additional CPG analyses are required.
- If the extracted features prove portable, the same prompting structure might be applied to other contract languages such as JML for Java.
- A natural next measurement is how many refinement iterations are typically needed before proof succeeds.
Load-bearing premise
The semantic features pulled from code property graphs are enough for the language model to write contracts that capture all relevant behaviors and avoid unprovable constraints.
What would settle it
Running the same 604 programs through the four LLMs with prompts that omit all CPG features and measuring whether the full-proof ratio falls back to the code-only baseline levels.
Figures



read the original abstract
Generating formal specifications for C programs remains a challenge in formal verification due to the manual effort, expertise, and semantic precision required. While recent advancements in large language models (LLMs) offer promise in automating specification synthesis, current approaches often lack semantic depth and produce unverifiable or incomplete contracts. To address these limitations, we introduce AutoACSL, a novel framework that integrates LLM prompting with semantic features extracted from Code Property Graphs (CPGs). AutoACSL performs static analyses to extract key semantic elements, including arithmetic operations, loop and recursion structures, and return value propagation, which are encoded into structured prompts. These prompts enable the LLM not only to generate normal behavioral specifications but also to include constraints that prevent inputs leading to runtime errors. AutoACSL employs a feedback-driven synthesis loop, where candidate specifications are verified using Frama-C/WP and refined iteratively until verification succeeds or a termination condition is met. Evaluated on 604 programs drawn from diverse datasets, AutoACSL achieves a 98% specification generation success ratio and a 96% full proof ratio when paired with Gemini-3. Compared to a code-only baseline, AutoACSL improves the full proof ratio by 24.7% to 51.7% across four LLMs (GPT-o4 Mini, GPT-5.2, Grok-4.1, and Gemini-3), demonstrating that integrating large language models with CPG-based static analysis substantially enhances both generation robustness and verification effectiveness for automated ACSL specification synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoACSL, a framework integrating LLMs with Code Property Graphs (CPGs) to extract semantic features (arithmetic operations, loop/recursion structures, return-value propagation) from C programs. These features are encoded into prompts for generating ACSL specifications, including error-preventing constraints. A feedback-driven loop iteratively refines candidates using Frama-C/WP verification until success or termination. On 604 programs from diverse datasets, AutoACSL reports 98% specification generation success and 96% full proof ratio with Gemini-3, improving full proof ratio by 24.7%–51.7% over a code-only baseline across four LLMs (GPT-o4 Mini, GPT-5.2, Grok-4.1, Gemini-3).
Significance. If the measured gains are attributable to the CPG semantic features rather than the refinement loop, the work would meaningfully advance automated ACSL synthesis by demonstrating how static-analysis-derived structure can improve LLM output quality for formal verification. The scale of the evaluation (604 programs) and the hybrid LLM+static-analysis design provide a concrete empirical baseline for future hybrid approaches.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the code-only baseline is described only as 'code-only' with no indication that it employs the identical feedback-driven synthesis loop (iterative refinement via WP counter-examples until success or termination) used by AutoACSL. Because the method section explicitly relies on this multi-turn procedure, the reported 24.7%–51.7% full-proof-ratio gains cannot be isolated to the CPG features; the loop itself may be the dominant factor. This directly undermines the central claim that CPG integration is responsible for the improvement.
- [Evaluation] Evaluation section: no information is supplied on dataset composition (source, selection criteria, distribution of loop/recursion depth, arithmetic complexity), baseline implementation details, statistical significance of the deltas, or failure-mode analysis. Without these, post-hoc selection or implementation differences cannot be ruled out, weakening confidence in the 96% full-proof claim.
minor comments (1)
- [Abstract] The abstract states quantitative results without referencing the specific tables or figures that contain the per-LLM breakdowns; cross-references would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the isolation of CPG contributions and strengthen the evaluation. We address each major comment below and will revise the manuscript to resolve the identified issues.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the code-only baseline is described only as 'code-only' with no indication that it employs the identical feedback-driven synthesis loop (iterative refinement via WP counter-examples until success or termination) used by AutoACSL. Because the method section explicitly relies on this multi-turn procedure, the reported 24.7%–51.7% full-proof-ratio gains cannot be isolated to the CPG features; the loop itself may be the dominant factor. This directly undermines the central claim that CPG integration is responsible for the improvement.
Authors: We agree that the baseline description was insufficient to isolate the effect of CPG features. The feedback-driven loop is integral to the synthesis process described in the method, and to attribute gains specifically to CPG integration the baseline must employ the identical loop. In the revised manuscript we will explicitly state that the code-only baseline uses the same multi-turn refinement procedure (candidate generation followed by Frama-C/WP verification and iterative counter-example feedback until success or termination), differing from AutoACSL only in the absence of CPG-derived semantic features from the prompts. This clarification ensures the reported deltas reflect the contribution of the CPG component. We have updated the relevant sections accordingly. revision: yes
-
Referee: [Evaluation] Evaluation section: no information is supplied on dataset composition (source, selection criteria, distribution of loop/recursion depth, arithmetic complexity), baseline implementation details, statistical significance of the deltas, or failure-mode analysis. Without these, post-hoc selection or implementation differences cannot be ruled out, weakening confidence in the 96% full-proof claim.
Authors: We acknowledge the need for greater transparency. In the revised Evaluation section we will add: (1) full details on dataset sources, selection criteria, and distributions of program features including loop/recursion depth and arithmetic complexity; (2) explicit implementation details for the code-only baseline; (3) statistical significance testing of the observed deltas (e.g., paired tests with p-values); and (4) a failure-mode analysis categorizing cases where full proof was not achieved. These additions will be supported by the existing experimental data and will be presented in tables or appendices as appropriate. revision: yes
Circularity Check
Empirical framework with no derivation chain
full rationale
The paper describes an empirical method that combines LLM prompting with CPG-extracted semantic features and evaluates it via a feedback-driven verification loop on 604 programs. It reports measured success ratios (98% generation, 96% full proof) and relative improvements over a code-only baseline. No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-referential definitions appear. The enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) do not apply; the central claims rest on experimental outcomes rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
F.-C. D. Team,FramaC, CEA LIST, 2025. [Online]. Available: https://frama-c.com/html/publications.html# general
2025
-
[2]
Seeking specifications: The case for neuro-symbolic specification synthesis,
G. Granberry, W. Ahrendt, and M. Johansson, “Seeking specifications: The case for neuro-symbolic specification synthesis,” 2025. [Online]. Available: https://arxiv.org/ abs/2504.21061
arXiv 2025
-
[3]
Specify what? Enhancing neural specification synthesis by symbolic methods,
——, “Specify what? Enhancing neural specification synthesis by symbolic methods,” inIntegrated Formal Methods, N. Kosmatov and L. Kov ´acs, Eds. Cham: Springer Nature Switzerland, 2025, pp. 307–325
2025
-
[4]
Can ChatGPT support software verification?
C. Janßen, C. Richter, and H. Wehrheim, “Can ChatGPT support software verification?” 2023. [Online]. Available: https://arxiv.org/abs/2311.02433
arXiv 2023
-
[5]
En- hancing automated loop invariant generation for complex programs with large language models,
R. Liu, G. Li, M. Chen, L.-I. Wu, and J. Ke, “En- hancing automated loop invariant generation for complex programs with large language models,”arXiv preprint arXiv:2412.10483, 2024
arXiv 2024
-
[6]
Mod- eling and discovering vulnerabilities with code property graphs,
F. Yamaguchi, N. Golde, D. Arp, and K. Rieck, “Mod- eling and discovering vulnerabilities with code property graphs,” in2014 IEEE symposium on security and pri- vacy. IEEE, 2014, pp. 590–604
2014
-
[7]
The daikon system for dynamic detection of likely invariants,
M. D. Ernst, J. H. Perkins, P. J. Guo, S. McCamant, C. Pacheco, M. S. Tschantz, and C. Xiao, “The daikon system for dynamic detection of likely invariants,” Sci. Comput. Program., vol. 69, no. 1–3, p. 35–45, Dec. 2007. [Online]. Available: https://doi.org/10.1016/ j.scico.2007.01.015
2007
-
[8]
Syminfer: inferring numerical invariants using symbolic states,
T. Nguyen, K. Nguyen, and H. Duong, “Syminfer: inferring numerical invariants using symbolic states,” in Proceedings of the ACM/IEEE 44th International Confer- ence on Software Engineering: Companion Proceedings, ser. ICSE ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 197–201. [Online]. Available: https://doi.org/10.1145/3510454.3516833
-
[9]
Dysy: dynamic symbolic execution for invariant inference,
C. Csallner, N. Tillmann, and Y . Smaragdakis, “Dysy: dynamic symbolic execution for invariant inference,” inProceedings of the 30th International Conference on Software Engineering, ser. ICSE ’08. New York, NY , USA: Association for Computing Machinery, 2008, p. 281–290. [Online]. Available: https://doi.org/10.1145/ 1368088.1368127
arXiv 2008
-
[10]
Speedy: An eclipse-based ide for invariant inference,
D. R. Cok and S. C. Johnson, “Speedy: An eclipse-based ide for invariant inference,”Electronic Proceedings in Theoretical Computer Science, vol. 149, p. 44–57, Apr. 2014. [Online]. Available: http://dx.doi.org/10. 4204/EPTCS.149.5
2014
-
[11]
Efficient mining of iterative patterns for software specification discovery,
D. Lo, S.-C. Khoo, and C. Liu, “Efficient mining of iterative patterns for software specification discovery,” inProceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining, 2007, pp. 460–469
2007
-
[12]
Abstract contract synthesis and verification in the symbolic k framework,
M. Alpuente, D. Pardo, and A. Villanueva, “Abstract contract synthesis and verification in the symbolic k framework,”Fundamenta Informaticae, vol. 177, no. 3-4, pp. 235–273, 2020
2020
-
[13]
Automated synthesis of software contracts with kindspec,
M. Alpuente and A. Villanueva, “Automated synthesis of software contracts with kindspec,” inAnalysis, Verifica- tion and Transformation for Declarative Programming and Intelligent Systems: Essays Dedicated to Manuel Hermenegildo on the Occasion of His 60th Birthday. Springer, 2023, pp. 51–71
2023
-
[14]
F. Dordowsky, “An experimental study using ACSL and Frama-C to formulate and verify low-level requirements from a DO-178C compliant avionics project,”arXiv preprint arXiv:1508.03894, 2015
Pith/arXiv arXiv 2015
-
[15]
Autodeduct: A tool for automated deductive verification of c code,
J. Amilon, D. Gurov, C. Lidstr ¨om, M. Nyberg, G. Ung, and O. Wingbrant, “Autodeduct: A tool for automated deductive verification of c code,” 2025. [Online]. Available: https://arxiv.org/abs/2501.10889
arXiv 2025
-
[16]
Automated inference of ACSL function con- tracts using tricera,
J. Amilon, “Automated inference of ACSL function con- tracts using tricera,” 2021
2021
-
[17]
F.-C. D. Team,FramaC Eva Plug-in Manual, CEA LIST, 2025. [Online]. Available: https://frama-c.com/ html/publications.html#eva
2025
-
[18]
[Online]
——,FramaC Pathcrawler Plug-in Manual, CEA LIST, 2025. [Online]. Available: https://frama-c.com/ html/publications.html#pathcrawler
2025
-
[19]
Enchanting program specification synthesis by large language models using static analysis and program verification,
C. Wen, J. Cao, J. Su, Z. Xu, S. Qin, M. He, H. Li, S.-C. Cheung, and C. Tian, “Enchanting program specification synthesis by large language models using static analysis and program verification,” inComputer Aided Verifica- tion, A. Gurfinkel and V . Ganesh, Eds. Cham: Springer Nature Switzerland, 2024, pp. 302–328
2024
-
[20]
Veco- gen: Automating generation of formally verified c code with large language models,
M. Sevenhuijsen, K. Etemadi, and M. Nyberg, “Veco- gen: Automating generation of formally verified c code with large language models,” in2025 IEEE/ACM 13th International Conference on Formal Methods in Software Engineering (FormaliSE). IEEE, 2025, pp. 101–112
2025
-
[21]
LLM meets bounded model checking: Neuro-symbolic loop invariant inference,
G. Wu, W. Cao, Y . Yao, H. Wei, T. Chen, and X. Ma, “LLM meets bounded model checking: Neuro-symbolic loop invariant inference,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, ser. ASE ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 406–417. [Online]. Available: https://doi.org/10.1145...
arXiv 2024
-
[22]
Next steps in LLM-Supported Java verification,
S. Teuber and B. Beckert, “Next steps in LLM-Supported Java verification,” in2025 IEEE/ACM 1st International Workshop on Neuro-Symbolic Software Engineering (NSE). IEEE, May 2025, p. 1–4. [Online]. Available: http://dx.doi.org/10.1109/NSE66660.2025.00007
-
[23]
Automated generation of code contracts: Generative ai to the rescue?
S. Greiner, N. B ¨uhlmann, M. Ohrndorf, C. Tsigkanos, O. Nierstrasz, and T. Kehrer, “Automated generation of code contracts: Generative ai to the rescue?” in Proceedings of the 23rd ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences, 2024, pp. 1–14
2024
-
[24]
L. Ma, S. Liu, Y . Li, X. Xie, and L. Bu, “ SpecGen: Automated Generation of Formal Program Specifications via Large Language Models ,” in 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). Los Alamitos, CA, USA: IEEE Computer Society, May 2025, pp. 16–28. [Online]. Available: https://doi.ieeecomputersociety.org/ 10.1109/ICSE55347...
-
[25]
A tale of 1001 loc: Potential runtime error-guided specification synthesis for verifying large-scale programs,
Z. Wang, T. Lin, M. Chen, H. Li, M. Yang, X. Yi, S. Qin, Y . Luo, X. Li, B. Gu, L. Lu, and J. Yin, “A tale of 1001 loc: Potential runtime error-guided specification synthesis for verifying large-scale programs,”Proceedings of the ACM on Programming Languages, vol. 10, no. OOP- SLA1, 2026
2026
-
[26]
Automated proof generation for rust code via self-evolution,
T. Chen, S. Lu, S. Lu, Y . Gong, C. Yang, X. Li, M. R. H. Misu, H. Yu, N. Duan, P. Chenget al., “Automated proof generation for rust code via self-evolution,”arXiv preprint arXiv:2410.15756, 2024
arXiv 2024
-
[27]
Classinvgen: Class invariant synthesis using large language models,
C. Sun, V . Agashe, S. Chakraborty, J. Taneja, C. Barrett, D. Dill, X. Qiu, and S. K. Lahiri, “Classinvgen: Class invariant synthesis using large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2502.18917
Pith/arXiv arXiv 2025
-
[28]
Propertygpt: Llm-driven formal verification of smart contracts through retrieval-augmented property generation,
Y . Liu, Y . Xue, D. Wu, Y . Sun, Y . Li, M. Shi, and Y . Liu, “Propertygpt: Llm-driven formal verification of smart contracts through retrieval-augmented property generation,” inProceedings 2025 Network and Distributed System Security Symposium, ser. NDSS
2025
-
[29]
Internet Society, 2025. [Online]. Available: http://dx.doi.org/10.14722/ndss.2025.241357
-
[30]
Loop verification with invariants and contracts,
G. Ernst, “Loop verification with invariants and contracts,” inVerification, Model Checking, and Abstract Interpretation: 23rd International Conference, VMCAI 2022, Philadelphia, PA, USA, January 16–18, 2022, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2022, p. 69–92. [Online]. Available: https://doi.org/10.1007/ 978-3-030-94583-1 4
2022
-
[31]
F.-C. D. Team,FramaC WP Plug-in Manual, CEA LIST, 2025. [Online]. Available: https://frama-c.com/ html/publications.html#wp
2025
-
[32]
Casp: an evaluation dataset for formal verification of c code,
N. Hertzberg, M. Sevenhuijsen, L. K ˚areborn, and A. Lokrantz, “Casp: an evaluation dataset for formal verification of c code,” inInternational Conference on Bridging the Gap between AI and Reality. Springer, 2025, pp. 63–82. APPENDIX A.1 Analysis of Memory Access The memory access analysis serves two purposes: (1) guid- ing the generation of memory safet...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.