Answer Engineering: Local Trajectory Editing for Protocol-Constrained Decision Making in Large Language Models
Pith reviewed 2026-06-26 14:10 UTC · model grok-4.3
The pith
Local rule-guided edits to an LLM's visible reasoning trajectory raise balanced accuracy on a clinical protocol benchmark from 42% to 80.7%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Answer Engineering applies localized rule-guided interventions to the visible reasoning trajectory during standard autoregressive generation. On a controlled clinical benchmark for sudden sensorineural hearing loss, step-by-step reasoning shifted rather than eliminated errors, dropping SSNHL compliance from 54.5% to 25.1% while raising acceptance on the conductive contrast condition from 1.6% to 58.9%. The editing layer raised SSNHL compliance to 83.5% and conductive-case adherence to 77.9%, lifting balanced accuracy from 42.0% under reasoning-only generation to 80.7%.
What carries the argument
Answer Engineering, a deterministic runtime and authoring layer that applies localized rule-guided interventions to the visible reasoning trajectory during autoregressive generation.
If this is right
- Protocol adherence can be improved through auditable runtime control of reasoning trajectories rather than model retraining.
- Step-by-step reasoning can shift errors rather than eliminate them in protocol-constrained domains.
- Limitations in the approach stem from rule coverage, trigger reliability, and persistent diagnosis-first generation dynamics.
- The method leaves diagnosis-first biases intact while correcting downstream management steps.
Where Pith is reading between the lines
- The same local-editing pattern could be applied to other rule-heavy domains such as legal document drafting or financial compliance checks.
- Human-authored rule sets may prove more maintainable than fine-tuning when protocols change frequently.
- Persistent model tendencies like early diagnosis suggest that trajectory control may need to operate at multiple points along the generation path.
Load-bearing premise
Rule-guided local interventions can be authored and triggered reliably enough to cover the relevant protocol constraints without introducing new inconsistencies or missing cases.
What would settle it
Running the same editing rules on a fresh set of clinical protocols whose constraints overlap or require more context than the current authoring interface supports, then measuring whether net compliance falls below the no-editing baseline.
Figures

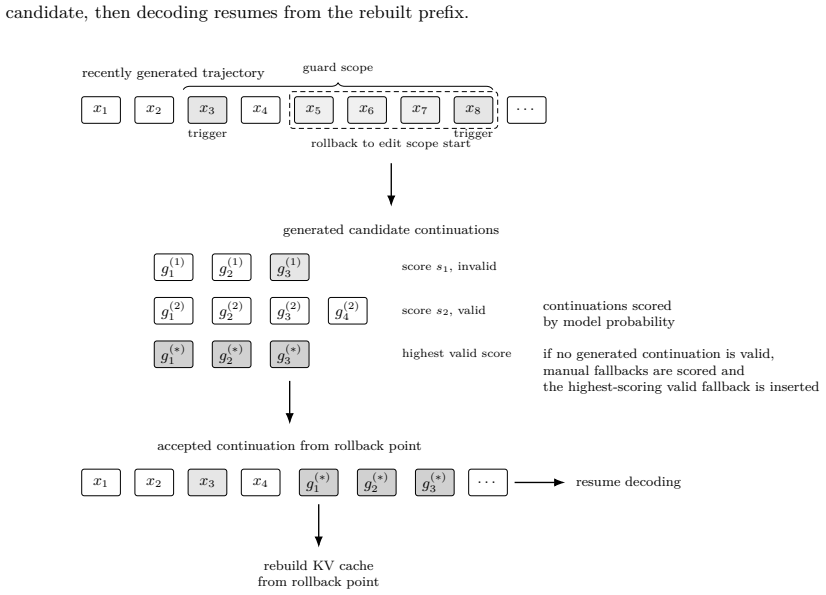
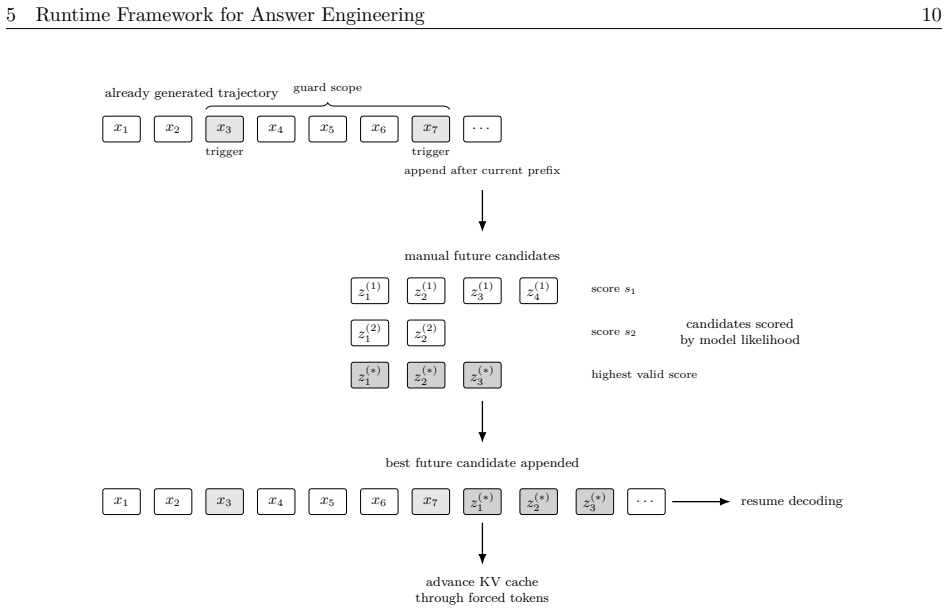



read the original abstract
Large language models can produce confident but protocol-invalid answers in domains where procedural compliance is critical. This paper presents Answer Engineering, a deterministic runtime and authoring layer that applies localized rule-guided interventions to the visible reasoning trajectory during standard autoregressive generation, without retraining, modifying model weights, or performing global search. The method is evaluated on a controlled clinical benchmark for sudden sensorineural hearing loss (SSNHL), where correct management depends on protocol-consistent interpretation of symptom timing, Weber/Rinne tuning-fork findings, and otoscopic findings. In the benchmark, step-by-step reasoning shifted rather than eliminated errors: compliant outcomes for SSNHL decreased from 54.5% under unguided generation to 25.1%, while acceptance on the conductive contrast condition increased from 1.6% to 58.9%. Local trajectory editing increased SSNHL compliance to 83.5% and conductive-case adherence to 77.9%, raising balanced accuracy from 42.0% under reasoning-only generation to 80.7%. The results support a systems-level view in which protocol adherence can be improved through auditable runtime control of reasoning trajectories, while also identifying limitations caused by rule coverage, trigger reliability, and persistent diagnosis-first generation dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Answer Engineering, a deterministic runtime layer for local rule-guided editing of LLM reasoning trajectories during autoregressive generation to enforce protocol compliance without retraining or global search. On a controlled clinical benchmark for sudden sensorineural hearing loss (SSNHL) involving symptom timing, Weber/Rinne findings, and otoscopic interpretation, it reports that reasoning-only generation reduces SSNHL compliance to 25.1% (from 54.5% unguided) while increasing conductive-case acceptance to 58.9%; local editing then raises SSNHL compliance to 83.5%, conductive adherence to 77.9%, and balanced accuracy from 42.0% to 80.7%. The work frames this as a systems-level approach to auditable protocol adherence while noting limitations in rule coverage, trigger reliability, and diagnosis-first dynamics.
Significance. If the results hold, the contribution lies in demonstrating a practical, weight-agnostic method for runtime trajectory control that yields substantial lifts on a domain-specific benchmark with clear baseline comparisons. The explicit identification of limitations and focus on deterministic, auditable interventions provide a concrete starting point for protocol-constrained applications in medicine and similar fields. The empirical numbers on a controlled task offer falsifiable predictions that can be stress-tested in follow-up work.
major comments (1)
- [Abstract] Abstract: The central empirical claims (SSNHL compliance rising to 83.5%, balanced accuracy to 80.7%) rest on the effectiveness of the authored rules covering protocol elements such as symptom timing, Weber/Rinne, and otoscopic findings without missing cases or introducing inconsistencies; however, no counts of rules, coverage analysis, trigger false-positive/negative rates, or ablation on rule completeness are supplied, leaving the gains vulnerable to the possibility that they reflect patching of a narrow error distribution rather than a general solution.
Simulated Author's Rebuttal
We thank the referee for the careful review and the recommendation for major revision. The concern about transparency in the rule set is well-taken and will be addressed by expanding the manuscript with the requested quantitative details on rule authoring and coverage.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (SSNHL compliance rising to 83.5%, balanced accuracy to 80.7%) rest on the effectiveness of the authored rules covering protocol elements such as symptom timing, Weber/Rinne, and otoscopic findings without missing cases or introducing inconsistencies; however, no counts of rules, coverage analysis, trigger false-positive/negative rates, or ablation on rule completeness are supplied, leaving the gains vulnerable to the possibility that they reflect patching of a narrow error distribution rather than a general solution.
Authors: We agree that the manuscript would benefit from explicit quantification of the rule set to support the reported gains. The current version emphasizes the local-editing mechanism and the controlled benchmark results while noting limitations in rule coverage and trigger reliability; it does not include rule counts, coverage tables, trigger error rates, or ablations. In the revision we will add: (i) the total number of authored rules and their breakdown by protocol element (symptom timing, Weber/Rinne, otoscopy), (ii) a coverage matrix indicating which protocol requirements are addressed and any identified gaps, (iii) observed trigger activation statistics including false-positive and false-negative rates measured on the benchmark traces, and (iv) a short discussion of rule completeness that stops short of a full ablation study. These additions will make clear that the interventions target the specific error modes documented in the reasoning-only baseline rather than constituting narrow, post-hoc patches. Because the rules are deterministic and human-authored, the requested statistics can be supplied without new experiments or changes to the core method. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with no definitional or fitted reductions.
full rationale
The paper reports measured compliance rates (e.g., 83.5% SSNHL, 80.7% balanced accuracy) from direct application of rule-guided edits on a fixed clinical benchmark. No equations, parameters fitted to the target metrics, self-citations used as load-bearing uniqueness theorems, or renamings of known results appear in the provided text. The derivation chain consists of an external benchmark comparison rather than any self-referential construction. Limitations on rule coverage are noted but do not create circularity in the reported outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2307.13702 , year =
Measuring Faithfulness in Chain-of-Thought Reasoning , author =. arXiv preprint arXiv:2307.13702 , year =
-
[2]
Faithful Chain-of-Thought Reasoning , author =. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages =. 2023 , organization =. doi:10.18653/v1/2023.ijcnlp-main.20 , url =
-
[3]
arXiv preprint arXiv:2503.08679 , year =
Chain-of-Thought Reasoning in the Wild Is Not Always Faithful , author =. arXiv preprint arXiv:2503.08679 , year =
-
[4]
LLM s cannot find reasoning errors, but can correct them given the error location
Tyen, Gladys and Mansoor, Hassan and C. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , organization =. doi:10.18653/v1/2024.findings-acl.826 , url =
-
[5]
arXiv preprint arXiv:2311.09101 , year =
Towards a Unified View of Answer Calibration for Multi-Step Reasoning , author =. arXiv preprint arXiv:2311.09101 , year =
-
[6]
Advances in Neural Information Processing Systems , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , year =
-
[7]
Constitutional
Bai, Yuntao and Kadavath, Saurav and Kundu, Sandipan and Askell, Amanda and Kernion, Jackson and Jones, Andy and Chen, Anna and Goldie, Anna and Mirhoseini, Azalia and McKinnon, Cameron , journal =. Constitutional. 2022 , note =
2022
-
[8]
2024 , note =
Srivatsa, Vikranth and He, Zijian and Abhyankar, Reyna and Zhang, Hao and Zhang, Yiying , journal =. 2024 , note =
2024
-
[9]
arXiv preprint arXiv:2305.14739 , year =
Trusting Your Evidence: Hallucinate Less with Context-Aware Decoding , author =. arXiv preprint arXiv:2305.14739 , year =
-
[10]
2021 , organization =
Yang, Kevin and Klein, Dan , booktitle =. 2021 , organization =
2021
-
[11]
arXiv preprint arXiv:2305.10601 , year =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. arXiv preprint arXiv:2305.10601 , year =
-
[12]
2023 , note =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , note =
2023
-
[13]
Wang, Peifeng and Wang, Zhengyang and Li, Zheng and Gao, Yifan and Yin, Bing and Ren, Xiang , booktitle =. 2023 , organization =. doi:10.18653/v1/2023.acl-long.304 , url =
-
[14]
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Trustworthy LLMs: A Survey and Guideline for Evaluating Large Language Models' Alignment , author =. arXiv preprint arXiv:2308.05374 , year =. doi:10.48550/arXiv.2308.05374 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.05374
-
[15]
From Implicit Exploration to Structured Reasoning: Guideline and Refinement for
Chen, Jiaxiang and Wang, Zhuo and Zou, Mingxi and Li, Zhucong and Zhou, Zhijian and Wang, Song and Xu, Zenglin , booktitle =. From Implicit Exploration to Structured Reasoning: Guideline and Refinement for. 2025 , isbn =. doi:10.18653/v1/2025.findings-emnlp.196 , url =
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[17]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
The Lancet , volume =
Sudden Sensorineural Hearing Loss , author =. The Lancet , volume =. 2009 , doi =
2009
-
[19]
ACM Computing Surveys , year=
A Survey of Reasoning with Large Language Models , author=. ACM Computing Surveys , year=
-
[20]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , year =
The Impact of Format Restrictions on Performance of Large Language Models , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track , year =
2024
-
[21]
Proceedings of the Conference on Language Modeling (COLM) , year =
Automata-based Constraints for Language Model Decoding , author =. Proceedings of the Conference on Language Modeling (COLM) , year =
-
[22]
arXiv preprint arXiv:2408.12599 , year =
Controllable Text Generation for Large Language Models: A Survey , author =. arXiv preprint arXiv:2408.12599 , year =
-
[23]
Advances in Neural Information Processing Systems , year =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , year =
-
[24]
A Survey on Large Language Model Acceleration based on
Li, Haoyang and Li, Yiming and Tian, Anxin and Tang, Tianhao and Xu, Zhanchao and Chen, Xuejia and Hu, Nicole and Dong, Wei and Li, Qing and Chen, Lei , journal =. A Survey on Large Language Model Acceleration based on. 2025 , url =
2025
-
[25]
and Salakhutdinov, Ruslan , booktitle =
Dai, Zihang and Yang, Zhilin and Yang, Yiming and Carbonell, Jaime and Le, Quoc V. and Salakhutdinov, Ruslan , booktitle =. Transformer-. 2019 , pages =
2019
-
[26]
arXiv preprint arXiv:2207.06881 , year =
Recurrent Memory Transformer , author =. arXiv preprint arXiv:2207.06881 , year =
-
[27]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , journal =. 2023 , url =
2023
-
[28]
arXiv preprint arXiv:2405.17935 , year =
Tool Learning with Large Language Models: A Survey , author =. arXiv preprint arXiv:2405.17935 , year =
-
[29]
arXiv preprint arXiv:2305.04388 , year =
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author =. arXiv preprint arXiv:2305.04388 , year =
-
[30]
2025 , howpublished =
Reasoning Models Don't Always Say What They Think , author =. 2025 , howpublished =
2025
-
[31]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
Measuring Chain of Thought Faithfulness by Unlearning Reasoning Steps , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[32]
International Conference on Learning Representations (ICLR) , year =
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing , author =. International Conference on Learning Representations (ICLR) , year =
-
[33]
International Conference on Learning Representations (ICLR) , year =
SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning , author =. International Conference on Learning Representations (ICLR) , year =
-
[34]
Expert Systems with Applications , volume =
Measuring the Complexity of Rule-Based Expert Systems , author =. Expert Systems with Applications , volume =. 1994 , doi =
1994
-
[35]
Decision Support Systems , volume =
An Approach to Improving the Maintainability of Existing Rule Bases , author =. Decision Support Systems , volume =. 1996 , doi =
1996
-
[36]
Proceedings of the 2022 ACM Southeast Conference , year =
From Past to Present: A Comprehensive Technical Review of Rule-Based Expert Systems from 1980--2021 , author =. Proceedings of the 2022 ACM Southeast Conference , year =. doi:10.1145/3476883.3520211 , url =
-
[37]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , year =
Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search , author =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics , year =
-
[38]
arXiv preprint arXiv:2309.15071 , year =
A Survey of Constrained Text Generation for Large Language Models , author =. arXiv preprint arXiv:2309.15071 , year =
-
[39]
Otolaryngology--Head and Neck Surgery , volume =
Clinical Practice Guideline: Sudden Hearing Loss (Update) , author =. Otolaryngology--Head and Neck Surgery , volume =. 2019 , month = aug, doi =
2019
-
[40]
Nature , volume =
Large Language Models Encode Clinical Knowledge , author =. Nature , volume =. 2023 , month = aug, doi =
2023
-
[41]
Applied Sciences , volume =
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author =. Applied Sciences , volume =. 2021 , month = jul, doi =
2021
-
[42]
arXiv preprint arXiv:2303.17651 , year =
Self-Refine: Iterative Refinement with Self-Feedback , author =. arXiv preprint arXiv:2303.17651 , year =
-
[43]
arXiv preprint arXiv:2212.08073 , year =
Constitutional AI: Harmlessness from AI Feedback , author =. arXiv preprint arXiv:2212.08073 , year =
-
[44]
arXiv preprint arXiv:2308.11462 , year =
LegalBench: A Collaboratively Built Benchmark for Legal Reasoning , author =. arXiv preprint arXiv:2308.11462 , year =
-
[45]
arXiv preprint arXiv:2302.04761 , year =
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. arXiv preprint arXiv:2302.04761 , year =
-
[46]
2025 , howpublished =
Answer Engineering Architecture Overview , author =. 2025 , howpublished =
2025
-
[47]
2025 , howpublished =
Answer Engineering Language Developer Specification v0.1 , author =. 2025 , howpublished =
2025
-
[48]
2025 , howpublished =
Answer Engineering Extension Points , author =. 2025 , howpublished =
2025
-
[49]
Training Verifiers to Solve Math Word Problems , author =. 2021 , journal =. 2110.14168 , archivePrefix=
Pith/arXiv arXiv 2021
-
[50]
2021 , eprint =
Scratchpads for Intermediate Computation with Language Models , author =. 2021 , eprint =
2021
-
[51]
2012 , institution =
International Standards on Combating Money Laundering and the Financing of Terrorism & Proliferation , author =. 2012 , institution =
2012
-
[52]
2016 , institution =
Recommended Practices for Safety and Health Programs , author =. 2016 , institution =
2016
-
[53]
OpenMeditron/Meditron3-8B , year =
-
[54]
Stachler, Robert J. and Chandrasekhar, Sujana S. and Archer, Sharon M. and Rosenfeld, Richard M. and Schwartz, Seth R. and Barrs, David M. and Brown, Stephen R. and Fife, Terry D. and Ford, Paula and Ganiats, Theodore G. and Hollingsworth, David B. and Lewandowski, Cary A. and Montano, Joseph J. and Saunders, Joseph E. and Tucci, Debara L. and Valente, Mi...
-
[55]
Nature Medicine , volume =
Evaluation and Mitigation of the Limitations of Large Language Models in Clinical Decision-Making , author =. Nature Medicine , volume =. 2024 , doi =
2024
-
[56]
npj Digital Medicine , volume =
Autonomous Medical Evaluation for Guideline Adherence of Large Language Models , author =. npj Digital Medicine , volume =. 2024 , doi =
2024
-
[57]
JMIRx Med , volume =
Assessing the Limitations of Large Language Models in Clinical Practice Guideline-Concordant Treatment Decision-Making on Real-World Data: Retrospective Study , author =. JMIRx Med , volume =. 2025 , month = nov, doi =
2025
-
[58]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
Improving Large Language Models Function Calling and Interpretability via Guided-Structured Templates , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.1242 , url =
-
[59]
OpenReview , year =
Curse of Instructions: Large Language Models Cannot Follow Multiple Instructions at Once , author =. OpenReview , year =
-
[60]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year =
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , year =
2024
-
[61]
Findings of the Association for Computational Linguistics: EMNLP 2025 , year =
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , year =
2025
-
[62]
2023 , eprint =
Let’s Verify Step by Step , author =. 2023 , eprint =
2023
-
[63]
2019 , url =
Sudden Hearing Loss Guideline Issue , organization =. 2019 , url =
2019
-
[64]
and Flaherty, Alexander and Zhang, Jason A
Leung, Michael A. and Flaherty, Alexander and Zhang, Jason A. and Hara, Joseph , title =. Canadian Family Physician , volume =. 2016 , url =
2016
-
[65]
Hearing Loss in Adults: Quality Standard 2 -- Sudden Onset of Hearing Loss , year =
-
[66]
Hearing Loss in Adults: Assessment and Management , year =
-
[67]
Plausibility: On the (Un)Reliability of Explanations from Large Language Models , author =
Faithfulness vs. Plausibility: On the (Un)Reliability of Explanations from Large Language Models , author =. arXiv preprint arXiv:2402.04614 , year =
-
[68]
STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning , author =. arXiv preprint , year =. 2203.14465 , eprinttype =
-
[69]
Proceedings of the ACM Symposium on Operating Systems Principles , year =
Efficient Memory Management for Large Language Model Serving with PagedAttention , author =. Proceedings of the ACM Symposium on Operating Systems Principles , year =
-
[70]
arXiv preprint arXiv:2312.07104 , year =
SGLang: Efficient Execution of Structured Language Model Programs , author =. arXiv preprint arXiv:2312.07104 , year =
-
[71]
arXiv preprint arXiv:2307.11760 , year =
Guidance: A Language for Controlling Large Language Models , author =. arXiv preprint arXiv:2307.11760 , year =
-
[72]
arXiv preprint arXiv:2308.12372 , year =
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications , author =. arXiv preprint arXiv:2308.12372 , year =
-
[73]
Proceedings of the ACM on Programming Languages , year =
LMQL: A Programming Language for Large Language Models , author =. Proceedings of the ACM on Programming Languages , year =
-
[74]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[75]
International Conference on Learning Representations (ICLR) , year=
Improving Instruction-Following in Language Models through Activation Steering , author=. International Conference on Learning Representations (ICLR) , year=
-
[76]
arXiv preprint arXiv:2410.12877 , year=
Improving Instruction-Following in Language Models through Activation Steering , author=. arXiv preprint arXiv:2410.12877 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.