Pose-Agnostic Robotic Functional Grasping via Observation-Action Canonicalization
Pith reviewed 2026-06-26 14:24 UTC · model grok-4.3
The pith
Transforming both depth views and robot actions into a shared mug-centered frame lets one learned policy grasp handles regardless of upright or inverted placement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
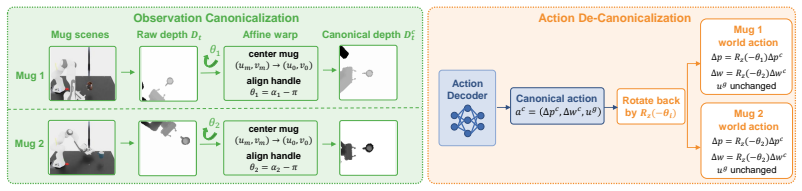
AnyMug introduces observation-action canonicalization that converts the depth observation and the predicted end-effector action into a shared object-centric frame so the policy receives a consistent mug-centered view and emits actions in a canonical direction independent of the mug's placement; combined with a handle-aware reward, pose curriculum, and domain randomization, the same closed-loop policy trained entirely in simulation reaches over 93 percent success on unseen upright and inverted mugs in simulation and 80 percent success zero-shot on five held-out physical mugs.
What carries the argument
Observation-action canonicalization, which maps both the depth image and the action vector into one fixed object-centric coordinate frame before the policy processes them.
If this is right
- A single set of policy weights suffices for both upright and inverted placements instead of requiring separate policies or explicit pose estimation.
- Grasp pose detection is replaced by closed-loop visuomotor control that continuously corrects for perception error on thin handles.
- Domain randomization and a pose curriculum together suffice for zero-shot sim-to-real transfer on this task without additional real-world fine-tuning.
- The same canonicalization step can be applied to other functional grasping tasks whose contact geometry is defined relative to an object feature rather than the world frame.
Where Pith is reading between the lines
- If the object-centric frame can be maintained across a wider class of objects, the method may reduce the need for instance-specific training data in other contact-rich manipulation tasks.
- The approach implicitly assumes that the gripper can always reach the canonical action direction without kinematic collision; testing on robots with different arm geometries would reveal whether that assumption holds.
- Extending the canonical frame to include velocity or force information could allow the same policy to handle compliant or slippery handles without changing the observation-action mapping.
Load-bearing premise
A reliable object-centric frame can be extracted from depth observations alone even when the mug is inverted or partially occluded.
What would settle it
Deploy the policy on a real mug whose handle lies in a plane that prevents reliable extraction of the object-centric frame from a single depth image and measure whether success rate collapses below the reported 80 percent.
Figures


read the original abstract
Functional robotic grasping requires a policy that generalizes across diverse object geometries and poses while maintaining task-specific contact precision. We study this challenge through mug-handle grasping, where thin handles, instance variation, and upright or inverted placements make both perception and control sensitive to object configuration. Grasp pose detection methods operate open-loop and are sensitive to estimation errors on thin handle structures. Learned visuomotor policies must implicitly learn to handle the coupled variation in visual appearance and action direction induced by different object placements, limiting generalization. We propose AnyMug, a canonicalized visuomotor reinforcement learning framework for functional grasping that trains a single closed-loop policy entirely in simulation and deploys it zero-shot on a real robot. AnyMug introduces observation-action canonicalization, which transforms both the depth observation and the predicted end-effector action into a shared object-centric frame. The policy therefore sees a consistent mug-centered view and emits actions in a canonical direction regardless of mug placement, allowing the same grasping behavior to be reused across configurations. A handle-aware reward further encourages precise approach, gripper alignment, and opposing-finger placement, while a pose curriculum and domain randomization improve training stability and sim-to-real transfer. In simulation, AnyMug achieves over 93% success rate on both unseen upright and inverted mugs and transfers zero-shot to a real Franka Panda, reaching 80% success rate on 5 held-out physical mugs across both pose categories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AnyMug, a visuomotor reinforcement learning framework for functional grasping of mugs that introduces observation-action canonicalization: depth observations and predicted end-effector actions are transformed into a shared object-centric frame so that a single policy sees a consistent mug-centered view and produces canonical actions independent of mug pose. The policy is trained entirely in simulation with a handle-aware reward, pose curriculum, and domain randomization, then deployed zero-shot on a real Franka Panda, reporting >93% success on unseen upright/inverted mugs in simulation and 80% success on five held-out physical mugs across both pose categories.
Significance. If the canonicalization mechanism is robust to real depth noise, the approach provides a concrete way to factor out object pose variation from the learned policy, which could reduce the data requirements for generalizing functional grasping across instance and placement diversity. The reported zero-shot sim-to-real numbers on a challenging thin-handle task would be a useful data point for the community if supported by the necessary ablation and error analysis.
major comments (2)
- [Abstract] Abstract and implied methods: the central claim attributes the 80% real-world success to observation-action canonicalization, yet the manuscript provides no quantitative measurement of 6-DoF pose estimation error from real depth images on thin handles or inverted placements, nor any sensitivity study showing how such errors affect the canonicalized policy input. Without these, it is impossible to confirm that the reported performance stems from the claimed mechanism rather than from the reward or randomization alone.
- [Abstract / Methods] The weakest assumption listed in the stress-test note is load-bearing: the framework presupposes that a reliable object-centric frame can be recovered from depth alone in both sim and reality. If this step fails on real sensor data for the handle geometry, the canonicalization benefit is nullified and the zero-shot transfer result cannot be interpreted as evidence for the method.
minor comments (2)
- [Abstract] Abstract: success rates are stated as 'over 93%' and '80%' without trial counts, standard deviations, or number of evaluation episodes, making it difficult to judge reproducibility or statistical reliability.
- [Methods] The description of the handle-aware reward and pose curriculum is high-level; explicit equations or pseudocode for the reward terms and curriculum schedule would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger validation of the canonicalization mechanism. We respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract and implied methods: the central claim attributes the 80% real-world success to observation-action canonicalization, yet the manuscript provides no quantitative measurement of 6-DoF pose estimation error from real depth images on thin handles or inverted placements, nor any sensitivity study showing how such errors affect the canonicalized policy input. Without these, it is impossible to confirm that the reported performance stems from the claimed mechanism rather than from the reward or randomization alone.
Authors: We agree that the manuscript lacks a direct quantitative measurement of 6-DoF pose estimation error on real depth images (particularly for thin handles and inverted placements) and a corresponding sensitivity study. While the paper includes ablation studies isolating the contribution of canonicalization versus reward and randomization, these do not substitute for explicit error analysis. In the revised manuscript we will add (i) measured 6-DoF pose estimation accuracy on the five held-out physical mugs in both upright and inverted configurations and (ii) a sensitivity study that perturbs the estimated object frame and reports resulting policy success rates. revision: yes
-
Referee: [Abstract / Methods] The weakest assumption listed in the stress-test note is load-bearing: the framework presupposes that a reliable object-centric frame can be recovered from depth alone in both sim and reality. If this step fails on real sensor data for the handle geometry, the canonicalization benefit is nullified and the zero-shot transfer result cannot be interpreted as evidence for the method.
Authors: Recovering a reliable object-centric frame from depth is indeed a central assumption. In simulation ground-truth poses are used; on the real robot we rely on depth-based estimation whose accuracy is not separately quantified in the current manuscript. The 80% zero-shot success rate provides indirect support that frame recovery is adequate for the evaluated mugs and poses, but we accept that this does not fully substantiate the assumption. The revision will therefore include an explicit description of the real-world pose estimation procedure together with its observed accuracy and any failure modes on thin-handle geometry. revision: yes
Circularity Check
No significant circularity; method is a standard RL design with empirical validation
full rationale
The paper describes a visuomotor RL framework that applies observation-action canonicalization to an object-centric frame using object pose (available as ground truth in simulation), combined with domain randomization, a pose curriculum, and a handle-aware reward. Reported performance metrics are direct empirical results from training and zero-shot deployment rather than any derivation that reduces by construction to fitted parameters or self-citations. No load-bearing equations, uniqueness theorems, or ansatzes are presented that collapse the central claim into its inputs. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bicchi and V
A. Bicchi and V . Kumar. Robotic grasping and contact: A review. InProceedings 2000 ICRA. Millennium conference. IEEE international conference on robotics and automation. Symposia proceedings (Cat. No. 00CH37065), volume 1, pages 348–353. IEEE, 2000
2000
-
[2]
J. Bohg, A. Morales, T. Asfour, and D. Kragic. Data-driven grasp synthesis—a survey.IEEE Transactions on robotics, 30(2):289–309, 2013
2013
-
[3]
J. Sun, A. Curtis, Y . You, Y . Xu, M. Koehle, Q. Chen, S. Huang, L. Guibas, S. Chitta, M. Schwager, et al. Arch: Hierarchical hybrid learning for long-horizon contact-rich robotic assembly.CoRL, 2025
2025
-
[4]
X. Chen, Z. Ye, J. Sun, Y . Fan, F. Hu, C. Wang, and C. Lu. Transferable active grasping and real embodied dataset. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 3611–3618. IEEE, 2020
2020
-
[5]
Q. Chen, H. Zheng, J. Yu, S. Huang, J. Sun, K. Goldberg, C. Wen, P. Abbeel, Y . Shentu, P. Wu, et al. Sarm2: Multi-task stage aware reward modeling for self improving robotic manipulation. arXiv preprint arXiv:2606.10305, 2026
Pith/arXiv arXiv 2026
-
[6]
S. Huang, J. Shao, K. Wang, Q. Chen, J. Sun, Y . Guo, M. Schwager, and J. Bohg. Breaking lock-in: Preserving steerability under low-data vla post-training.arXiv preprint arXiv:2604.23121, 2026
Pith/arXiv arXiv 2026
- [7]
-
[8]
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. Mimicplay: Long-horizon imitation learning by watching human play.CoRL, 2023
2023
-
[9]
Huang, Q
S. Huang, Q. Chen, X. Zhang, J. Sun, and M. Schwager. Particleformer: A 3d point cloud world model for multi-object, multi-material robotic manipulation.CoRL, 2025
2025
-
[10]
J. Mahler, J. Liang, S. Niyaz, M. Laskey, R. Doan, X. Liu, J. A. Ojea, and K. Goldberg. Dex- net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics.arXiv preprint arXiv:1703.09312, 2017
Pith/arXiv arXiv 2017
-
[11]
Mousavian, C
A. Mousavian, C. Eppner, and D. Fox. 6-dof graspnet: Variational grasp generation for object manipulation. InProceedings of the IEEE/CVF international conference on computer vision, pages 2901–2910, 2019
2019
-
[12]
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu. Anygrasp: Robust and efficient grasp perception in spatial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023
2023
-
[13]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[14]
Y . You, W. He, J. Liu, H. Xiong, W. Wang, and C. Lu. Cppf++: Uncertainty-aware sim2real ob- ject pose estimation by vote aggregation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9239–9254, 2024
2024
-
[15]
Levine, P
S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection.The International journal of robotics research, 37(4-5):421–436, 2018
2018
-
[16]
Dmitry, I
K. Dmitry, I. Alex, P. Peter, I. Julian, H. Alexander, J. Eric, Q. Deirdre, H. Ethan, K. Mri- nal, V . Vincent, et al. Qt-opt. scalable deep reinforcement learning for vision-based robotic manipulation.arXiv preprint, 2018. 9
2018
-
[17]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[18]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[19]
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[20]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[21]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt. Equivariant diffusion policy. InConference on Robot Learning (CoRL), 2024
2024
-
[22]
Yang, Z.-a
J. Yang, Z.-a. Cao, C. Deng, R. Antonova, S. Song, and J. Bohg. EquiBot: SIM(3)-equivariant diffusion policy for generalizable and data-efficient learning. InConference on Robot Learning (CoRL), 2024
2024
-
[23]
A. T. Miller and P. K. Allen. Graspit! a versatile simulator for robotic grasping.IEEE Robotics & Automation Magazine, 11(4):110–122, 2004
2004
-
[24]
Redmon and A
J. Redmon and A. Angelova. Real-time grasp detection using convolutional neural networks. In2015 IEEE international conference on robotics and automation (ICRA), pages 1316–1322. IEEE, 2015
2015
-
[25]
Pinto and A
L. Pinto and A. Gupta. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In2016 IEEE international conference on robotics and automation (ICRA), pages 3406–3413. IEEE, 2016
2016
-
[26]
Mahler, F
J. Mahler, F. T. Pokorny, B. Hou, M. Roderick, M. Laskey, M. Aubry, K. Kohlhoff, T. Kr¨oger, J. Kuffner, and K. Goldberg. Dex-net 1.0: A cloud-based network of 3d objects for robust grasp planning using a multi-armed bandit model with correlated rewards. In2016 IEEE international conference on robotics and automation (ICRA), pages 1957–1964. IEEE, 2016
1957
-
[27]
Mahler, M
J. Mahler, M. Matl, V . Satish, M. Danielczuk, B. DeRose, S. McKinley, and K. Goldberg. Learning ambidextrous robot grasping policies.Science robotics, 4(26):eaau4984, 2019
2019
-
[28]
Ten Pas, M
A. Ten Pas, M. Gualtieri, K. Saenko, and R. Platt. Grasp pose detection in point clouds.The International Journal of Robotics Research, 36(13-14):1455–1473, 2017
2017
-
[29]
X. Yan, J. Hsu, M. Khansari, Y . Bai, A. Pathak, A. Gupta, J. Davidson, and H. Lee. Learning 6-dof grasping interaction via deep geometry-aware 3d representations. In2018 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 3766–3773. IEEE, 2018
2018
-
[30]
Viereck, A
U. Viereck, A. Pas, K. Saenko, and R. Platt. Learning a visuomotor controller for real world robotic grasping using simulated depth images. InConference on robot learning, pages 291–
-
[31]
A. Zeng, S. Song, S. Welker, J. Lee, A. Rodriguez, and T. Funkhouser. Learning synergies between pushing and grasping with self-supervised deep reinforcement learning. In2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4238–
-
[32]
C.-C. Hsu, B. Wen, J. Xu, Y . Narang, X. Wang, Y . Zhu, J. Biswas, and S. Birchfield. Spot: Se (3) pose trajectory diffusion for object-centric manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4853–4860. IEEE, 2025
2025
-
[33]
H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2642–2651, 2019
2019
-
[34]
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, et al. Transporter networks: Rearranging the visual world for robotic manipulation. InConference on Robot Learning, pages 726–747. PMLR, 2021
2021
- [35]
-
[36]
X. Zhu, D. Wang, G. Su, O. Biza, R. Walters, and R. Platt. On robot grasp learning using equivariant models.Autonomous Robots, 47(8):1175–1193, 2023
2023
-
[37]
D. Wang, R. Walters, and R. Platt. SO(2)-equivariant reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[38]
D. Wang, M. Jia, X. Zhu, R. Walters, and R. Platt. On-robot learning with equivariant models. InConference on Robot Learning (CoRL), 2022. 11 Appendix A Related Work A.1 Grasp Pose Detection A popular paradigm in robotic grasping is to predict a target grasp pose from visual input. Classical methods [1, 23, 2] use analytical grasp metrics or geometric heu...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.