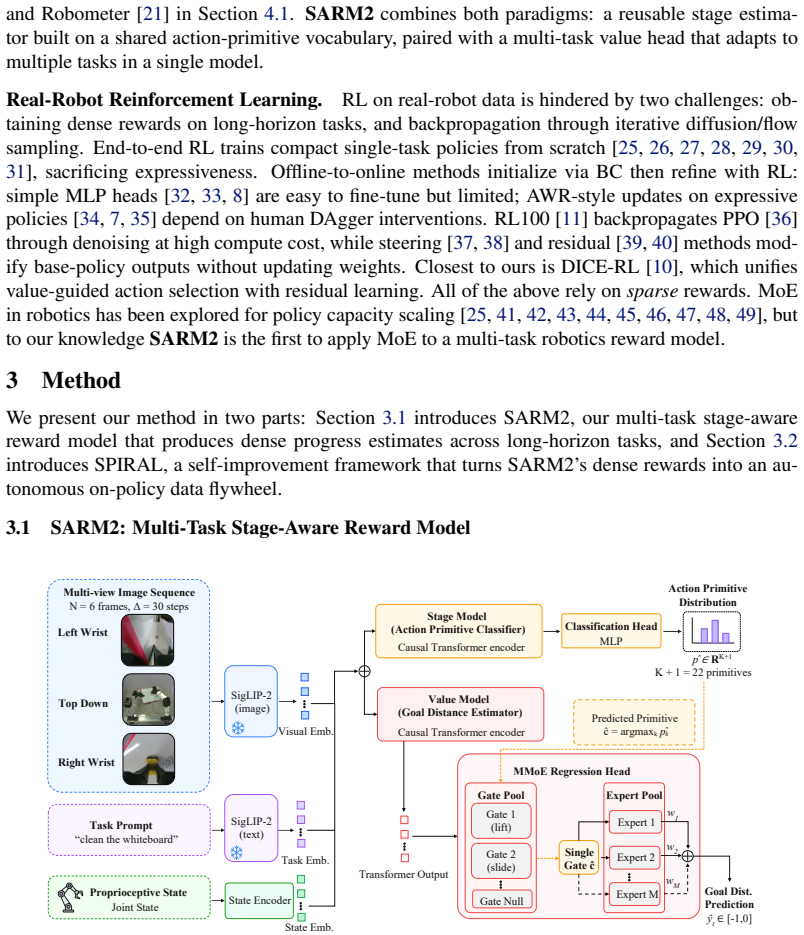
SARM2: Multi-Task Stage Aware Reward Modeling for Self Improving Robotic Manipulation
Pith reviewed 2026-06-27 13:21 UTC · model grok-4.3
The pith
A multi-task stage-aware reward model enables near-perfect success on long-horizon robotic manipulation tasks through self-improvement from autonomous rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
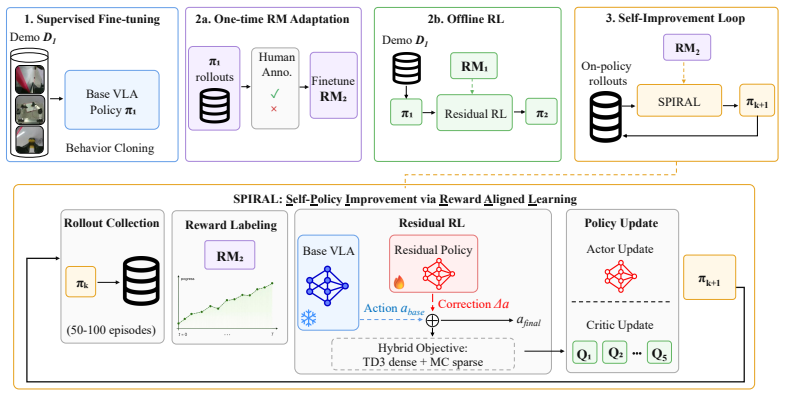
RM combines an action-primitive-based stage estimator with a multi-gate Mixture-of-Experts value head to produce dense per-step rewards that generalize across manipulation tasks. Integrated into SPIRAL, this yields on-policy reward-guided learning that improves VLA policies from autonomous rollouts, cutting value-estimation MSE by 80 percent and raising success from around 50 percent to near-perfect levels on tasks such as Folding Shorts and Cleaning Whiteboard.
What carries the argument
RM, the multi-task stage-aware reward model built from an action-primitive-based stage estimator and a multi-gate Mixture-of-Experts value head that outputs dense rewards.
If this is right
- RM reduces value-estimation MSE by 80 percent over strongest baselines on a 10-task benchmark.
- When used in SPIRAL, task success on Folding Shorts rises from 58 percent to 100 percent.
- When used in SPIRAL, task success on Cleaning Whiteboard rises from 50 percent to 90 percent.
- The combination supports a stable robot data flywheel by enabling policy improvement from cheap autonomous rollouts.
Where Pith is reading between the lines
- The same stage-estimation idea might apply to other sequential robot tasks that lack manual progress labels.
- If the estimator generalizes, it could reduce the amount of human demonstration data needed for VLA fine-tuning.
- A direct test would measure whether RM maintains low MSE when evaluated on manipulation tasks absent from its training set.
Load-bearing premise
The action-primitive-based stage estimator can reliably identify task progress across multiple manipulation tasks without per-task annotations.
What would settle it
If the stage estimator mislabels progress on held-out tasks, value-estimation MSE stays high and SPIRAL produces no measurable rise in policy success rates.
Figures












read the original abstract
Fine-tuning vision-language-action (VLA) policies for long-horizon manipulation still relies heavily on behavior cloning, which requires costly high-quality demonstrations and keeps policies near the demonstration distribution. Reward models can reduce this dependence by reweighting demonstrations and providing dense supervision for on-robot reinforcement learning (RL), but they must be dense, accurate, and general. Existing methods fall short: task-specific stage-aware models are accurate but require per-task annotations, while general vision-language-model (VLM) reward models are broadly applicable but too coarse for fine-grained long-horizon progress. We introduce RM, a multi-task stage-aware reward model that combines an action-primitive-based stage estimator with a multi-gate Mixture-of-Experts (MMoE) value head to produce dense per-step rewards across manipulation tasks. Building on RM, we further propose SPIRAL (Self-Policy Improvement via Reward-Aligned Learning), an on-policy reward-guided framework that improves VLA policies from cheap autonomous rollouts. On a 10-task benchmark, RM reduces value-estimation MSE by 80% over the strongest baselines; when used in SPIRAL, it improves task success from around 50% to near-perfect performance on Folding Shorts (58% to 100%) and Cleaning Whiteboard (50% to 90%), showing that high-quality dense rewards are key to a stable robot data flywheel. Project website: https://qianzhong-chen.github.io/sarm2.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RM, a multi-task stage-aware reward model that integrates an action-primitive-based stage estimator with a multi-gate Mixture-of-Experts (MMoE) value head to generate dense per-step rewards for vision-language-action (VLA) policies across manipulation tasks. It further introduces SPIRAL, an on-policy reward-guided framework for self-improving VLA policies via cheap autonomous rollouts. Key claims include an 80% reduction in value-estimation MSE over baselines on a 10-task benchmark and large task-success gains when RM is used in SPIRAL (e.g., Folding Shorts: 58% to 100%; Cleaning Whiteboard: 50% to 90%).
Significance. If the central claims hold after validation, the work would be significant for robotics: it offers a path to generalizable dense rewards for long-horizon tasks without per-task annotations, potentially enabling more scalable self-improving robotic systems that reduce dependence on costly demonstrations. The primitive-based staging plus MMoE design is a concrete technical contribution to multi-task reward modeling.
major comments (3)
- [Method (stage estimator description)] The action-primitive-based stage estimator (described in the method section) is presented as reliably identifying task progress across the 10 tasks using only shared primitives and no per-task labels, yet the manuscript supplies no quantitative validation (accuracy, per-task consistency, or confusion matrices) of this component. This is load-bearing for both the 80% MSE reduction and the SPIRAL success-rate gains, because noisy or task-dependent stage signals would prevent the MMoE value head from learning accurate dense rewards.
- [§5 (Experiments)] §5 (Experiments) and the associated benchmark tables: the reported 80% MSE reduction and per-task success improvements lack details on baseline implementations, number of evaluation runs, statistical significance, and ablations that isolate the contribution of the stage estimator versus the MMoE head alone. Without these, it is impossible to confirm that the gains derive from the proposed architecture rather than other factors.
- [Benchmark results table] The 10-task benchmark results (Table reporting MSE and success rates): no per-task breakdown of stage-estimator performance or comparison against task-specific stage-aware baselines is provided, which is required to substantiate the multi-task generalization claim over both task-specific models and general VLM rewards.
minor comments (2)
- [Abstract] Abstract: the phrase 'around 50%' for baseline success rates should be replaced with the exact baseline values for precision.
- [Throughout] Notation: ensure RM, SPIRAL, and MMoE are defined at first use and used consistently; a short table of acronyms would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the stage estimator and more rigorous experimental details. We address each major comment below and will incorporate the requested additions and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Method (stage estimator description)] The action-primitive-based stage estimator (described in the method section) is presented as reliably identifying task progress across the 10 tasks using only shared primitives and no per-task labels, yet the manuscript supplies no quantitative validation (accuracy, per-task consistency, or confusion matrices) of this component. This is load-bearing for both the 80% MSE reduction and the SPIRAL success-rate gains, because noisy or task-dependent stage signals would prevent the MMoE value head from learning accurate dense rewards.
Authors: We agree that quantitative validation of the stage estimator is essential. In the revised manuscript we will add accuracy metrics, per-task consistency scores, and confusion matrices computed on held-out autonomous rollouts, confirming reliable progress identification across tasks without per-task labels. revision: yes
-
Referee: [§5 (Experiments)] §5 (Experiments) and the associated benchmark tables: the reported 80% MSE reduction and per-task success improvements lack details on baseline implementations, number of evaluation runs, statistical significance, and ablations that isolate the contribution of the stage estimator versus the MMoE head alone. Without these, it is impossible to confirm that the gains derive from the proposed architecture rather than other factors.
Authors: We will expand §5 with explicit baseline implementation details (including multi-task adaptations), results over five independent evaluation runs with standard deviations, statistical significance tests, and ablations that isolate the stage estimator from the MMoE head. revision: yes
-
Referee: [Benchmark results table] The 10-task benchmark results (Table reporting MSE and success rates): no per-task breakdown of stage-estimator performance or comparison against task-specific stage-aware baselines is provided, which is required to substantiate the multi-task generalization claim over both task-specific models and general VLM rewards.
Authors: The revised version will include a per-task breakdown of stage-estimator accuracy and explicit comparisons against both task-specific stage-aware reward models and general VLM-based rewards to substantiate the multi-task generalization claim. revision: yes
Circularity Check
No circularity: empirical model and benchmark results are self-contained
full rationale
The paper presents RM (action-primitive stage estimator + MMoE value head) and SPIRAL as a new architecture and on-policy framework. All headline numbers (80% MSE reduction, success rate jumps on Folding Shorts and Cleaning Whiteboard) are reported as direct experimental outcomes on a 10-task benchmark. No equations, fitted-parameter renamings, or self-citation chains appear in the provided text that would make any claimed prediction equivalent to its inputs by construction. The work is therefore scored as self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Pose-Agnostic Robotic Functional Grasping via Observation-Action Canonicalization
AnyMug trains a single closed-loop visuomotor policy in simulation using observation-action canonicalization and deploys it zero-shot on a real robot for functional mug-handle grasping across poses.
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[6]
Q. Chen, J. Yu, M. Schwager, P. Abbeel, Y . Shentu, and P. Wu. Sarm: Stage-aware reward modeling for long horizon robot manipulation.arXiv preprint arXiv:2509.25358, 2025
Pith/arXiv arXiv 2025
-
[7]
Physical Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, et al.π ∗ 0.6: A vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[8]
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao. Conrft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
-
[9]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision-language- action model with online reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15665–15672. IEEE, 2025
2025
- [10]
-
[11]
K. Lei, H. Li, D. Yu, Z. Wei, L. Guo, Z. Jiang, Z. Wang, S. Liang, and H. Xu. Rl- 100: Performant robotic manipulation with real-world reinforcement learning.arXiv preprint arXiv:2510.14830, 2025
arXiv 2025
-
[12]
Y . J. Ma, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman. Liv: Language-image repre- sentations and rewards for robotic control. InInternational Conference on Machine Learning, pages 23301–23320. PMLR, 2023
2023
-
[13]
M. Alakuijala, R. McLean, I. Woungang, N. Farsad, S. Kaski, P. Marttinen, and K. Yuan. Video-language critic: Transferable reward functions for language-conditioned robotics.arXiv preprint arXiv:2405.19988, 2024
arXiv 2024
-
[14]
K.-H. Hung, P.-C. Lo, J.-F. Yeh, H.-Y . Hsu, Y .-T. Chen, and W. H. Hsu. Victor: Learning hier- archical vision-instruction correlation rewards for long-horizon manipulation.arXiv preprint arXiv:2405.16545, 2024
arXiv 2024
-
[15]
C. Kim, M. Heo, D. Lee, J. Shin, H. Lee, J. J. Lim, and K. Lee. Subtask-aware visual reward learning from segmented demonstrations.arXiv preprint arXiv:2502.20630, 2025
arXiv 2025
- [16]
-
[17]
Y . J. Ma, J. Hejna, C. Fu, D. Shah, J. Liang, Z. Xu, S. Kirmani, P. Xu, D. Driess, T. Xiao, et al. Vision language models are in-context value learners. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[18]
H. Tan, S. Chen, Y . Xu, Z. Wang, Y . Ji, C. Chi, Y . Lyu, Z. Zhao, X. Chen, P. Co, et al. Robo- dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025
arXiv 2025
-
[19]
S. Chen, C. Harrison, Y .-C. Lee, A. J. Yang, Z. Ren, L. J. Ratliff, J. Duan, D. Fox, and R. Kr- ishna. Topreward: Token probabilities as hidden zero-shot rewards for robotics.arXiv preprint arXiv:2602.19313, 2026
arXiv 2026
-
[20]
T. Lee, A. Wagenmaker, K. Pertsch, P. Liang, S. Levine, and C. Finn. Roboreward: General- purpose vision-language reward models for robotics.arXiv preprint arXiv:2601.00675, 2026
arXiv 2026
-
[21]
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, et al. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons.arXiv preprint arXiv:2603.02115, 2026
Pith/arXiv arXiv 2026
-
[22]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[23]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[24]
T. Mu, M. Liu, and H. Su. Drs: Learning reusable dense rewards for multi-stage tasks.arXiv preprint arXiv:2404.16779, 2024
arXiv 2024
- [25]
-
[26]
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine. Serl: A software suite for sample-efficient robotic reinforcement learning. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 16961–16969. IEEE, 2024
2024
-
[27]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[28]
Y . Zhao, H. Jin, L. Jiang, X. Zhang, K. Wu, P. Ren, Z. Xu, Z. Che, L. Sun, D. Wu, et al. Real-world reinforcement learning from suboptimal interventions.arXiv preprint arXiv:2512.24288, 2025
arXiv 2025
-
[29]
Kalashnikov, A
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on robot learning, pages 651–673. PMLR, 2018
2018
-
[30]
Y . Seo, J. Uruc ¸, and S. James. Continuous control with coarse-to-fine reinforcement learning. arXiv preprint arXiv:2407.07787, 2024
arXiv 2024
-
[31]
P. Wu, A. Escontrela, D. Hafner, K. Goldberg, and P. Abbeel. Daydreamer: World models for physical robot learning.Conference on Robot Learning, 2022
2022
-
[32]
H. Hu, S. Mirchandani, and D. Sadigh. Imitation bootstrapped reinforcement learning.arXiv preprint arXiv:2311.02198, 2023. 10
arXiv 2023
-
[33]
J. Yang, M. S. Mark, B. Vu, A. Sharma, J. Bohg, and C. Finn. Robot fine-tuning made easy: Pre-training rewards and policies for autonomous real-world reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4804–4811. IEEE, 2024
2024
-
[34]
P. Wu, Y . Shentu, Q. Liao, D. Jin, M. Guo, K. Sreenath, X. Lin, and P. Abbeel. Robocopi- lot: Human-in-the-loop interactive imitation learning for robot manipulation.arXiv preprint arXiv:2503.07771, 2025
arXiv 2025
-
[35]
X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
Pith/arXiv arXiv 1910
-
[36]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[37]
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning.arXiv preprint arXiv:2506.15799, 2025
Pith/arXiv arXiv 2025
-
[38]
H. Niu, Q. Chen, T. Liu, J. Li, G. Zhou, Y . Zhang, J. Hu, and X. Zhan. xted: Cross-domain adaptation via diffusion-based trajectory editing.arXiv preprint arXiv:2409.08687, 2024
arXiv 2024
-
[39]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. Fan, et al. Self- improving vision-language-action models with data generation via residual rl.arXiv preprint arXiv:2511.00091, 2025
arXiv 2025
- [40]
-
[41]
C. Hao, X. Zhai, Y . Liu, and H. Soh. Abstracting robot manipulation skills via mixture-of- experts diffusion policies.arXiv preprint arXiv:2601.21251, 2026
arXiv 2026
- [42]
-
[43]
Zhang, Y
X. Zhang, Y . Jiang, H. Qin, J. Bai, and M. Bai. Language-conditioned representations and mixture-of-experts policy for robust multi-task robotic manipulation.IEEE Robotics and Au- tomation Letters, 11(5):6153–6160, 2026
2026
-
[44]
W. Shen, Y . Liu, Y . Wu, Z. Liang, S. Gu, D. Wang, T. Nian, L. Xu, Y . Qin, J. Pang, et al. Expertise need not monopolize: Action-specialized mixture of experts for vision-language- action learning.arXiv preprint arXiv:2510.14300, 2025
arXiv 2025
-
[45]
Z. Du, B. Liu, Y . Liang, Y . Shen, H. Cao, X. Zheng, Z. Feng, Z. Wu, J. Yang, and Y .-G. Jiang. Himoe-vla: Hierarchical mixture-of-experts for generalist vision-language-action poli- cies.arXiv preprint arXiv:2512.05693, 2025
arXiv 2025
-
[46]
Z. Yang, Y . Chai, X. Jia, Q. Li, Y . Shao, X. Zhu, H. Su, and J. Yan. Drivemoe: Mixture-of- experts for vision-language-action model in end-to-end autonomous driving.arXiv preprint arXiv:2505.16278, 2025
Pith/arXiv arXiv 2025
-
[47]
Huang, S
R. Huang, S. Zhu, Y . Du, and H. Zhao. Moe-loco: Mixture of experts for multitask locomotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 14218–14225. IEEE, 2025
2025
-
[48]
Seyde, W
T. Seyde, W. Schwarting, I. Gilitschenski, M. Wulfmeier, and D. Rus. Strength through diver- sity: Robust behavior learning via mixture policies. InConference on Robot Learning, pages 1144–1155. PMLR, 2022. 11
2022
-
[49]
Q. Chen, N. Gao, S. Huang, J. Low, T. Chen, J. Sun, and M. Schwager. Grad-nav++: Vision- language model enabled visual drone navigation with gaussian radiance fields and differen- tiable dynamics.IEEE Robotics and Automation Letters, 11(2):1418–1425, 2025
2025
-
[50]
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi. Modeling task relationships in multi- task learning with multi-gate mixture-of-experts. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1930–1939, 2018
1930
-
[51]
H. Lei, X. Cheng, Q. Qin, D. Wang, K. Fan, H. Huang, Q. Gu, Y . Wu, Z. Jiang, Y . Chen, et al. M3-jepa: Multimodal alignment via multi-gate moe based on the joint-embedding predictive architecture.arXiv preprint arXiv:2409.05929, 2024
arXiv 2024
-
[52]
Fujimoto, H
S. Fujimoto, H. van Hoof, and D. Meger. Addressing function approximation error in actor- critic methods. InInternational Conference on Machine Learning, pages 1587–1596. PMLR, 2018
2018
-
[53]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[54]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control.arXiv preprint arXiv:2502.05855, 2025
Pith/arXiv arXiv 2025
-
[55]
Kooijmans, M
P. Kooijmans, M. Aractingi, S. Palma, C. Pascal, J. Choghari, K. Meftah, M. Russi, N. Rabault, V . Batto, L. von Werra, and T. Wolf. Unfolding robotics: The open-source recipe for teaching a robot to fold your clothes, 2026
2026
-
[56]
Yam – 6-dof robotic arm.https://i2rt.com/products/ yam-manipulator, 2025
I2RT-Robotics. Yam – 6-dof robotic arm.https://i2rt.com/products/ yam-manipulator, 2025
2025
-
[57]
Realsensedepth camera d405.https://store.realsenseai.com/ buy-intel-realsense-depth-camera-d405.html, 2025
RealSense. Realsensedepth camera d405.https://store.realsenseai.com/ buy-intel-realsense-depth-camera-d405.html, 2025
2025
-
[58]
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12156–12163. IEEE, 2024
2024
-
[59]
Fedus, B
W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[60]
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
Pith/arXiv arXiv 2006
-
[61]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chap- lot, D. d. l. Casas, E. B. Hanna, F. Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
Pith/arXiv arXiv 2024
-
[62]
D. Dai, C. Deng, C. Zhao, R. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1280–1297, 2024
2024
-
[63]
shared backbone, specialized head
C. Zheng, J. Sun, Y . Gao, E. Xie, Y . Wang, P. Wang, T. Xu, C. Matthew, L. Ren, J. Li, J. Xiong, K. Rasul, M. Schwager, A. Schneider, Z. Wang, and Y . Nevmyvaka. Understanding the mixture-of-experts with nadaraya-watson kernel.The Fourteenth International Conference on Learning Representations (ICLR), 2026. 12 6 Appendix 6.1 Hardware Setup For our real-w...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.