DUET: Decentralized Bilevel Optimization without Lower-Level Strong Convexity
Pith reviewed 2026-06-26 14:03 UTC · model grok-4.3
The pith
DUET enables decentralized bilevel optimization without lower-level strong convexity by adding diminishing quadratic regularization to the lower-level objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DUET is the first decentralized bilevel optimization method to guarantee approximate KKT-stationary point convergence without lower-level strong convexity, by applying diminishing quadratic regularization to the lower-level objective together with gradient tracking for heterogeneity.
What carries the argument
Diminishing quadratic regularization added to the lower-level objective, which produces a well-defined hypergradient and stationarity measure without requiring strong convexity.
If this is right
- Convergence to approximate KKT points holds under the paper's relaxed lower-level assumptions rather than strong convexity.
- Gradient tracking inside DUET addresses data heterogeneity without a central server.
- The iteration complexity scales as O(1/T^{1-5p-11/4 τ}) with explicit dependence on the lower-level learning-rate and averaging parameters.
- The algorithm applies to multi-agent systems performing local bilevel tasks in a fully decentralized manner.
Where Pith is reading between the lines
- The regularization technique could be tested on lower-level problems that are non-convex but still satisfy the paper's relaxed conditions.
- Removing the strong-convexity assumption opens the method to bilevel tasks arising in modern machine-learning models where convexity rarely holds.
- The same diminishing-regularization idea might be portable to other decentralized or distributed bilevel settings beyond the ones studied here.
Load-bearing premise
Relaxed assumptions on the lower-level problem suffice to make the diminishing quadratic regularization produce a well-defined hypergradient and stationarity measure.
What would settle it
A counterexample or numerical run in which the hypergradient becomes undefined or stationarity fails to hold for any choice of the diminishing regularization schedule.
Figures
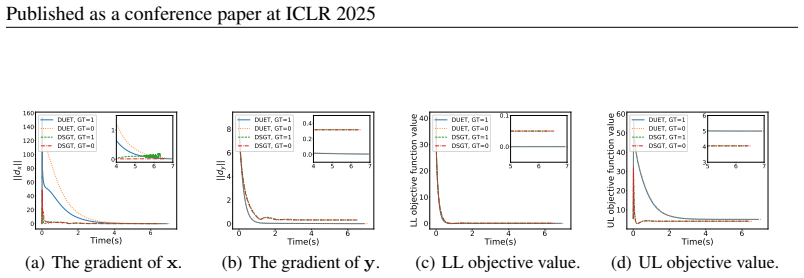
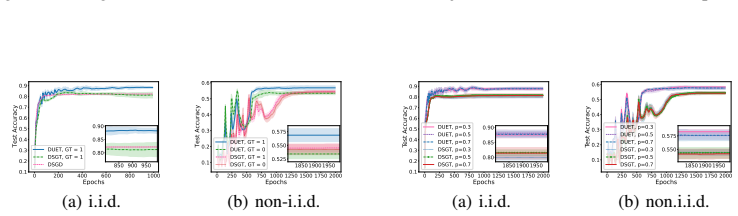
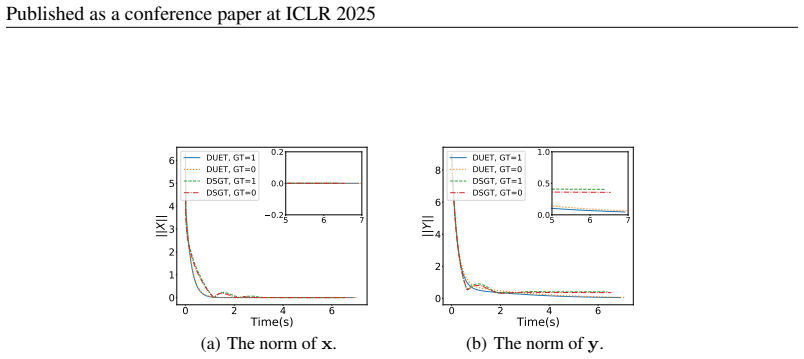
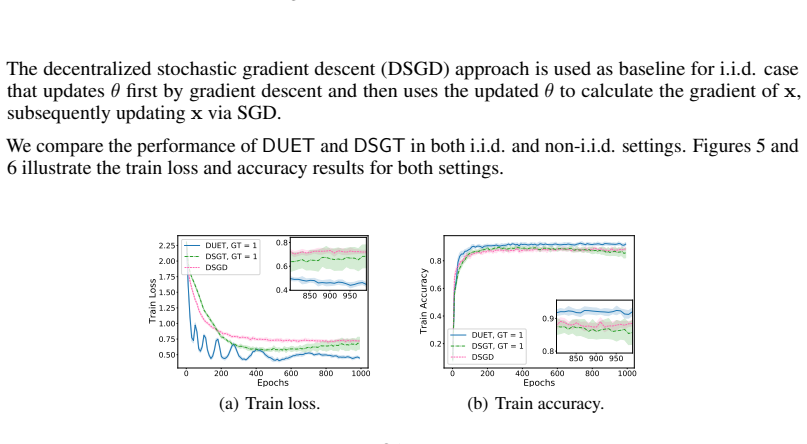



read the original abstract
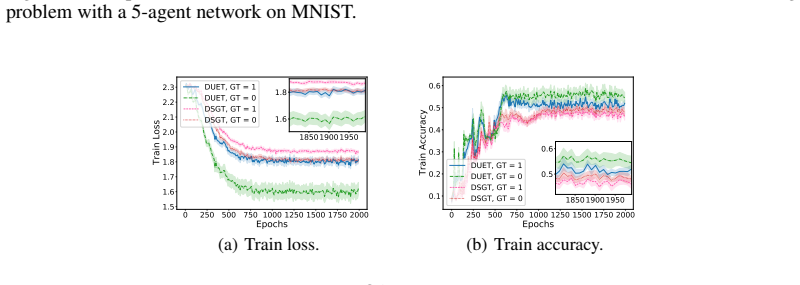
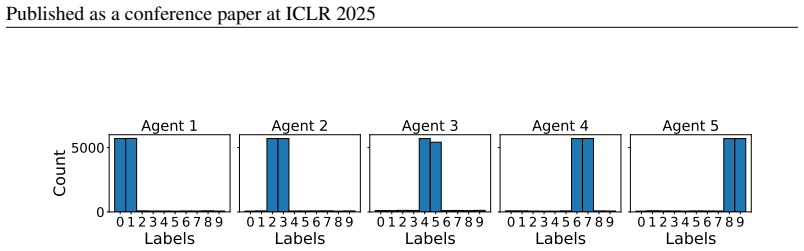
Decentralized bilevel optimization (DBO) provides a powerful framework for multi-agent systems to solve local bilevel tasks in a decentralized fashion without the need for a central server. However, most existing DBO methods rely on lower-level strong convexity (LLSC) to guarantee unique solutions and a well-defined hypergradient for stationarity measure, hindering their applicability in many practical scenarios not satisfying LLSC. To overcome this limitation, we introduce a new single-loop DBO algorithm called diminishing quadratically-regularized bilevel decentralized optimization (DUET), which eliminates the need for LLSC by introducing a diminishing quadratic regularization to the lower-level (LL) objective. We show that DUET achieves an iteration complexity of $O(1/T^{1-5p-\frac{11}{4}\tau})$ for approximate KKT-stationary point convergence under relaxed assumptions, where $p$ and $\tau $ are control parameters for LL learning rate and averaging, respectively. In addition, our DUET algorithm incorporates gradient tracking to address data heterogeneity, a key challenge in DBO settings. To the best of our knowledge, this is the first work to tackle DBO without LLSC under decentralized settings with data heterogeneity. Numerical experiments validate the theoretical findings and demonstrate the practical effectiveness of our proposed algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DUET, a single-loop decentralized bilevel optimization algorithm that applies a diminishing quadratic regularization to the lower-level objective. This removes the need for lower-level strong convexity (LLSC) while preserving a well-defined hypergradient and enabling convergence to approximate KKT-stationary points. The claimed iteration complexity is O(1/T^{1-5p-11/4 τ}) under relaxed assumptions, with gradient tracking incorporated to handle data heterogeneity across agents. Numerical experiments are presented to validate the theory, and the work claims to be the first to address DBO without LLSC in decentralized heterogeneous settings.
Significance. If the derivation and assumptions hold, the result would meaningfully extend decentralized bilevel optimization beyond the LLSC regime that limits most prior DBO methods. The combination of diminishing regularization with gradient tracking directly targets practical multi-agent scenarios, and the explicit (parameter-dependent) complexity bound provides a concrete benchmark. The absence of machine-checked proofs or fully reproducible code is noted but does not diminish the potential impact if the analysis is correct.
major comments (2)
- [§3 and §4] §3 (Assumptions) and §4 (Convergence Analysis): the relaxed assumptions replacing LLSC are invoked to guarantee a well-defined hypergradient and the KKT stationarity measure, yet the manuscript does not explicitly list or compare them to standard LLSC conditions; this is load-bearing for the central claim that the complexity bound holds without LLSC.
- [Theorem 1] Theorem 1 (or equivalent complexity statement): the exponent 1-5p-11/4 τ depends on the control parameters p and τ; the manuscript should clarify the admissible range of these parameters and whether the bound remains meaningful (positive exponent) under the relaxed assumptions without additional hidden restrictions.
minor comments (2)
- [§2 and §4] Notation for the diminishing regularization parameter and the stationarity measure should be introduced once and used consistently across the algorithm description and analysis sections.
- [§5] The experimental section would benefit from an explicit statement of how the relaxed assumptions are satisfied (or approximated) in the chosen test problems.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Assumptions) and §4 (Convergence Analysis): the relaxed assumptions replacing LLSC are invoked to guarantee a well-defined hypergradient and the KKT stationarity measure, yet the manuscript does not explicitly list or compare them to standard LLSC conditions; this is load-bearing for the central claim that the complexity bound holds without LLSC.
Authors: We agree that an explicit listing and comparison would strengthen the presentation. In the revised manuscript we will insert a dedicated paragraph in §3 that enumerates the relaxed assumptions and provides a direct side-by-side comparison with the classical lower-level strong-convexity condition, clarifying how the diminishing quadratic regularization guarantees a well-defined hypergradient and a meaningful KKT stationarity measure without invoking LLSC. revision: yes
-
Referee: [Theorem 1] Theorem 1 (or equivalent complexity statement): the exponent 1-5p-11/4 τ depends on the control parameters p and τ; the manuscript should clarify the admissible range of these parameters and whether the bound remains meaningful (positive exponent) under the relaxed assumptions without additional hidden restrictions.
Authors: The parameters must satisfy 0 < p, τ and 5p + (11/4)τ < 1 to obtain a positive exponent. These ranges are admissible under the relaxed assumptions because the convergence analysis relies only on the diminishing regularization schedule and the gradient-tracking mechanism, not on LLSC. We will revise the statement of Theorem 1 (and the surrounding discussion in §4) to state the admissible ranges explicitly and to confirm that the exponent remains positive throughout this range with no additional hidden restrictions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces DUET via diminishing quadratic regularization on the lower-level objective to remove the LLSC assumption, then derives an iteration complexity bound O(1/T^{1-5p-11/4 τ}) for approximate KKT-stationary points under explicitly relaxed assumptions, with gradient tracking for heterogeneity. The bound is stated as a function of tunable control parameters p and τ rather than any fitted quantity; no equations reduce by construction to inputs, no self-citation chains are load-bearing for the central claim, and the derivation is presented as independent theoretical analysis. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- p
- τ
axioms (1)
- domain assumption Relaxed assumptions on the lower-level problem that replace lower-level strong convexity
Reference graph
Works this paper leans on
-
[1]
Proceedings of International Conference on Machine Learning , pages =
Risheng Liu and Yaohua Liu and Wei Yao and Shangzhi Zeng and Jin Zhang , title =. Proceedings of International Conference on Machine Learning , pages =
-
[2]
arXiv preprint arXiv:2301.00712 , year=
On bilevel optimization without lower-level strong convexity , author=. arXiv preprint arXiv:2301.00712 , year=
-
[3]
Proceedings of International Conference on Artificial Intelligence and Statistics , pages=
A conditional gradient-based method for simple bilevel optimization with convex lower-level problem , author=. Proceedings of International Conference on Artificial Intelligence and Statistics , pages=
-
[6]
Optimization Letters , year=
Decentralized bilevel optimization , author=. Optimization Letters , year=
-
[7]
Advances in Neural Information Processing Systems , year=
A stochastic linearized augmented Lagrangian method for decentralized bilevel optimization , author=. Advances in Neural Information Processing Systems , year=
-
[8]
Advances in neural information processing systems , volume=
Decentralized gossip-based stochastic bilevel optimization over communication networks , author=. Advances in neural information processing systems , volume=
-
[9]
International Conference on Artificial Intelligence and Statistics , pages=
On the Convergence of Distributed Stochastic Bilevel Optimization Algorithms over a Network , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[10]
2018 , publisher=
Lectures on Convex Optimization , author=. 2018 , publisher=
2018
-
[12]
Proceedings of the 38th International Conference on Machine Learning , pages =
Bilevel Optimization: Convergence Analysis and Enhanced Design , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[13]
Proceedings of the Neural Information Processing Systems (NeurIPS) , year=
A Near-Optimal Algorithm for Stochastic Bilevel Optimization via Double-Momentum , author=. Proceedings of the Neural Information Processing Systems (NeurIPS) , year=
-
[14]
Journal of Machine Learning Research , year =
Kaiyi ji and Yingbin Liang , title =. Journal of Machine Learning Research , year =
-
[15]
Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
A Single-Timescale Method for Stochastic Bilevel Optimization , author=. Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[16]
Advances in Neural Information Processing Systems , volume=
A framework for bilevel optimization that enables stochastic and global variance reduction algorithms , author=. Advances in Neural Information Processing Systems , volume=. 2022 , organization=
2022
-
[17]
Proceedings of the International Conference on Machine Learning (ICML) , year=
A Generic First-Order Algorithmic Framework for Bi-Level Programming Beyond Lower-Level Singleton , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[18]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Ji, Kaiyi and Liu, Mingrui and Liang, Yingbin and Ying, Lei , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[21]
SIAM Journal on Optimization , volume =
Shoham Sabach and Shimrit Shtern , title =. SIAM Journal on Optimization , volume =
-
[22]
Xu , title =
H.-K. Xu , title =. Journal of Mathematical Analysis and Applications , volume =. 2004 , doi =
2004
-
[23]
2020 , eprint=
Improved Bilevel Model: Fast and Optimal Algorithm with Theoretical Guarantee , author=. 2020 , eprint=
2020
-
[24]
IEEE INFOCOM 2023-IEEE Conference on Computer Communications , pages=
DIAMOND: Taming Sample and Communication Complexities in Decentralized Bilevel Optimization , author=. IEEE INFOCOM 2023-IEEE Conference on Computer Communications , pages=. 2023 , organization=
2023
-
[25]
Proceedings of the Twenty-Third International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing , pages=
Interact: Achieving low sample and communication complexities in decentralized bilevel learning over networks , author=. Proceedings of the Twenty-Third International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing , pages=
-
[26]
Proceedings of the 40th International Conference on Machine Learning , pages =
Prometheus: Taming Sample and Communication Complexities in Constrained Decentralized Stochastic Bilevel Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =
-
[27]
Proceedings of the 41st International Conference on Machine Learning , pages =
Distributed Bilevel Optimization with Communication Compression , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[28]
arXiv preprint arXiv:2312.14690 , year=
Distributed Stochastic Bilevel Optimization: Improved Complexity and Heterogeneity Analysis , author=. arXiv preprint arXiv:2312.14690 , year=
-
[29]
and Kingsbury, Brian and Horesh, Lior , booktitle=
Lu, Songtao and Cui, Xiaodong and Squillante, Mark S. and Kingsbury, Brian and Horesh, Lior , booktitle=. Decentralized Bilevel Optimization for Personalized Client Learning , year=
-
[30]
Proceedings of the 40th International Conference on Machine Learning , volume=
Decentralized stochastic bilevel optimization with improved per-iteration complexity , author=. Proceedings of the 40th International Conference on Machine Learning , volume=. 2023 , organization=
2023
-
[31]
SIAM Journal on Optimization , year=
A two-timescale framework for bilevel optimization: Complexity analysis and application to actor-critic , author=. SIAM Journal on Optimization , year=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bi-level actor-critic for multi-agent coordination , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Smooth bilevel programming for sparse regularization , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW) , pages=
BOML: A modularized bilevel optimization library in Python for meta-learning , author=. 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW) , pages=. 2021 , organization=
2021
-
[35]
Advances in neural information processing systems , volume=
Meta-learning with implicit gradients , author=. Advances in neural information processing systems , volume=
-
[36]
Proceedings of Thirty Seventh Conference on Learning Theory , pages =
On Finding Small Hyper-Gradients in Bilevel Optimization: Hardness Results and Improved Analysis , author =. Proceedings of Thirty Seventh Conference on Learning Theory , pages =. 2024 , editor =
2024
-
[37]
Advances in Neural Information Processing Systems , volume=
Automatic and harmless regularization with constrained and lexicographic optimization: A dynamic barrier approach , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
2024 , eprint=
A Single-Loop Algorithm for Decentralized Bilevel Optimization , author=. 2024 , eprint=
2024
-
[39]
NeurIPS 2021 , year=
Bi-objective trade-off with dynamic barrier gradient descent , author=. NeurIPS 2021 , year=
2021
-
[40]
Neural Computation , volume=
Dictionary learning algorithms for sparse representation , author=. Neural Computation , volume=
-
[41]
IEEE Transactions on Signal Processing , volume=
Dictionary learning for sparse approximations with the majorization method , author=. IEEE Transactions on Signal Processing , volume=. 2009 , publisher=
2009
-
[42]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
PyTorch Geometric Temporal: Spatiotemporal Signal Processing with Neural Machine Learning Models , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=. 2021 , organization=
2021
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Dictionary learning for sparse coding: Algorithms and convergence analysis , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2015 , publisher=
2015
-
[44]
ArXiv , year=
DoCoM-SGT: Doubly Compressed Momentum-assisted Stochastic Gradient Tracking Algorithm for Communication Efficient Decentralized Learning , author=. ArXiv , year=
-
[45]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Bi-Level Actor-Critic for Multi-Agent Coordination , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=. doi:10.1609/aaai.v34i05.6226 , pages=
-
[47]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
CoBo: Collaborative Learning via Bilevel Optimization , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[48]
Distributed Subgradient Methods for Multi-Agent Optimization , year=
Nedic, Angelia and Ozdaglar, Asuman , journal=. Distributed Subgradient Methods for Multi-Agent Optimization , year=
-
[49]
Advances in neural information processing systems , volume=
Bome! bilevel optimization made easy: A simple first-order approach , author=. Advances in neural information processing systems , volume=
-
[50]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Penalty-based Methods for Simple Bilevel Optimization under H\"olderian Error Bounds , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[52]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
An Accelerated Gradient Method for Convex Smooth Simple Bilevel Optimization , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[53]
2024 American Control Conference (ACC) , year=
Achieving Optimal Complexity Guarantees for a Class of Bilevel Convex Optimization Problems , author=. 2024 American Control Conference (ACC) , year=
2024
-
[54]
Projection-free methods for stochastic simple bilevel optimization with convex lower-level problem
Jincheng Cao, Ruichen Jiang, Nazanin Abolfazli, Erfan Yazdandoost Hamedani, and Aryan Mokhtari. Projection-free methods for stochastic simple bilevel optimization with convex lower-level problem. arXiv preprint arXiv:2308.07536, 2023
arXiv 2023
-
[55]
An accelerated gradient method for convex smooth simple bilevel optimization
Jincheng Cao, Ruichen Jiang, Erfan Yazdandoost Hamedani, and Aryan Mokhtari. An accelerated gradient method for convex smooth simple bilevel optimization. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=aFOdln7jBV
2024
-
[56]
On finding small hyper-gradients in bilevel optimization: Hardness results and improved analysis
Lesi Chen, Jing Xu, and Jingzhao Zhang. On finding small hyper-gradients in bilevel optimization: Hardness results and improved analysis. In Shipra Agrawal and Aaron Roth (eds.), Proceedings of Thirty Seventh Conference on Learning Theory, volume 247 of Proceedings of Machine Learning Research, pp.\ 947--980. PMLR, 30 Jun--03 Jul 2024 a . URL https://proc...
2024
-
[57]
Penalty-based methods for simple bilevel optimization under h\"olderian error bounds
Pengyu Chen, Xu Shi, Rujun Jiang, and Jiulin Wang. Penalty-based methods for simple bilevel optimization under h\"olderian error bounds. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024 b . URL https://openreview.net/forum?id=oQ1Zj9iH88
2024
-
[58]
X. Chen, M. Huang, S. Ma, and K. Balasubramanian. Decentralized stochastic bilevel optimization with improved per-iteration complexity. In Proceedings of the 40th International Conference on Machine Learning, volume 202, pp.\ 4641--4671. PMLR, 2023
2023
-
[59]
Decentralized bilevel optimization
Xuxing Chen, Minhui Huang, and Shiqian Ma. Decentralized bilevel optimization. Optimization Letters, 2022. URL https://api.semanticscholar.org/CorpusID:249626492
2022
-
[60]
Dagréou, P
M. Dagréou, P. Ablin, S. Vaiter, and T. Moreau. A framework for bilevel optimization that enables stochastic and global variance reduction algorithms. In Advances in Neural Information Processing Systems, volume 35, pp.\ 26698--26710. Curran Associates, Inc., 2022
2022
-
[61]
A single-loop algorithm for decentralized bilevel optimization, 2024
Youran Dong, Shiqian Ma, Junfeng Yang, and Chao Yin. A single-loop algorithm for decentralized bilevel optimization, 2024. URL https://arxiv.org/abs/2311.08945
arXiv 2024
-
[62]
On the convergence of distributed stochastic bilevel optimization algorithms over a network
Hongchang Gao, Bin Gu, and My T Thai. On the convergence of distributed stochastic bilevel optimization algorithms over a network. In International Conference on Artificial Intelligence and Statistics, pp.\ 9238--9281. PMLR, 2023
2023
-
[63]
Approximation methods for bilevel programming
Saeed Ghadimi and Mengdi Wang. Approximation methods for bilevel programming. arXiv preprint arXiv:1802.02246, 2018
Pith/arXiv arXiv 2018
-
[64]
Cobo: Collaborative learning via bilevel optimization
Diba Hashemi, Lie He, and Martin Jaggi. Cobo: Collaborative learning via bilevel optimization. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=SjQ1iIqpfU
2024
-
[65]
Distributed bilevel optimization with communication compression
Yutong He, Jie Hu, Xinmeng Huang, Songtao Lu, Bin Wang, and Kun Yuan. Distributed bilevel optimization with communication compression. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.), Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proce...
2024
-
[66]
Lower bounds and accelerated algorithms for bilevel optimization
Kaiyi ji and Yingbin Liang. Lower bounds and accelerated algorithms for bilevel optimization. Journal of Machine Learning Research, 24 0 (22): 0 1--56, 2023. URL http://jmlr.org/papers/v24/21-0949.html
2023
-
[67]
Bilevel optimization: Convergence analysis and enhanced design
Kaiyi Ji, Junjie Yang, and Yingbin Liang. Bilevel optimization: Convergence analysis and enhanced design. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp.\ 4882--4892. PMLR, 18--24 Jul 2021. URL https://proceedings.mlr.press/v139/ji21c.html
2021
-
[68]
Will bilevel optimizers benefit from loops
Kaiyi Ji, Mingrui Liu, Yingbin Liang, and Lei Ying. Will bilevel optimizers benefit from loops. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA, 2024. Curran Associates Inc. ISBN 9781713871088
2024
-
[69]
A conditional gradient-based method for simple bilevel optimization with convex lower-level problem
Ruichen Jiang, Nazanin Abolfazli, Aryan Mokhtari, and Erfan Yazdandoost Hamedani. A conditional gradient-based method for simple bilevel optimization with convex lower-level problem. In Proceedings of International Conference on Artificial Intelligence and Statistics, pp.\ 10305--10323, 2023
2023
-
[70]
Boao Kong, Shuchen Zhu, Songtao Lu, Xinmeng Huang, and Kun Yuan. Decentralized bilevel optimization over graphs: Loopless algorithmic update and transient iteration complexity. arXiv preprint arXiv:2402.03167, 2024
arXiv 2024
-
[71]
Improved bilevel model: Fast and optimal algorithm with theoretical guarantee, 2020
Junyi Li, Bin Gu, and Heng Huang. Improved bilevel model: Fast and optimal algorithm with theoretical guarantee, 2020. URL https://arxiv.org/abs/2009.00690
arXiv 2020
-
[72]
Bome! bilevel optimization made easy: A simple first-order approach
Bo Liu, Mao Ye, Stephen Wright, Peter Stone, and Qiang Liu. Bome! bilevel optimization made easy: A simple first-order approach. Advances in neural information processing systems, 35: 0 17248--17262, 2022 a
2022
-
[73]
Averaged method of multipliers for bi-level optimization without lower-level strong convexity
Risheng Liu, Yaohua Liu, Wei Yao, Shangzhi Zeng, and Jin Zhang. Averaged method of multipliers for bi-level optimization without lower-level strong convexity. In Proceedings of International Conference on Machine Learning, pp.\ 21839--21866, 2023 a
2023
-
[74]
Liu and R
Y. Liu and R. Liu. Boml: A modularized bilevel optimization library in python for meta-learning. In 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), pp.\ 1--2. IEEE, 2021
2021
-
[75]
Interact: Achieving low sample and communication complexities in decentralized bilevel learning over networks
Zhuqing Liu, Xin Zhang, Prashant Khanduri, Songtao Lu, and Jia Liu. Interact: Achieving low sample and communication complexities in decentralized bilevel learning over networks. In Proceedings of the Twenty-Third International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, pp.\ 61--70, 2022 b
2022
-
[76]
Prometheus: Taming sample and communication complexities in constrained decentralized stochastic bilevel learning
Zhuqing Liu, Xin Zhang, Prashant Khanduri, Songtao Lu, and Jia Liu. Prometheus: Taming sample and communication complexities in constrained decentralized stochastic bilevel learning. In Proceedings of the 40th International Conference on Machine Learning, pp.\ 22420--22453, 2023 b
2023
-
[77]
A stochastic linearized augmented lagrangian method for decentralized bilevel optimization
Songtao Lu, Siliang Zeng, Xiaodong Cui, Mark Squillante, Lior Horesh, Brian Kingsbury, Jia Liu, and Mingyi Hong. A stochastic linearized augmented lagrangian method for decentralized bilevel optimization. Advances in Neural Information Processing Systems, 2022
2022
-
[78]
First-order penalty methods for bilevel optimization
Zhaosong Lu and Sanyou Mei. First-order penalty methods for bilevel optimization. arXiv preprint arXiv:2301.01716, 2023
arXiv 2023
-
[79]
Convex bi-level optimization problems with nonsmooth outer objective function
Roey Merchav and Shoham Sabach. Convex bi-level optimization problems with nonsmooth outer objective function. SIAM Journal on Optimization, 33 0 (4): 0 3114--3142, 2023. doi:10.1137/22M1533608. URL https://doi.org/10.1137/22M1533608
-
[80]
Distributed subgradient methods for multi-agent optimization
Angelia Nedic and Asuman Ozdaglar. Distributed subgradient methods for multi-agent optimization. IEEE Transactions on Automatic Control, 54 0 (1): 0 48--61, 2009. doi:10.1109/TAC.2008.2009515
-
[81]
Lectures on Convex Optimization, volume 137
Yurii Nesterov. Lectures on Convex Optimization, volume 137. Springer, 2018
2018
-
[82]
Distributed stochastic bilevel optimization: Improved complexity and heterogeneity analysis, 2023
Youcheng Niu, Jinming Xu, Ying Sun, Yan Huang, and Li Chai. Distributed stochastic bilevel optimization: Improved complexity and heterogeneity analysis, 2023
2023
-
[83]
Smooth bilevel programming for sparse regularization
Clarice Poon and Gabriel Peyr \'e . Smooth bilevel programming for sparse regularization. Advances in Neural Information Processing Systems, 34: 0 1543--1555, 2021
2021
-
[84]
Diamond: Taming sample and communication complexities in decentralized bilevel optimization
Peiwen Qiu, Yining Li, Zhuqing Liu, Prashant Khanduri, Jia Liu, Ness B Shroff, Elizabeth Serena Bentley, and Kurt Turck. Diamond: Taming sample and communication complexities in decentralized bilevel optimization. In IEEE INFOCOM 2023-IEEE Conference on Computer Communications, pp.\ 1--10. IEEE, 2023
2023
-
[85]
Meta-learning with implicit gradients
Aravind Rajeswaran, Chelsea Finn, Sham M Kakade, and Sergey Levine. Meta-learning with implicit gradients. Advances in neural information processing systems, 32, 2019
2019
-
[86]
A first order method for solving convex bilevel optimization problems
Shoham Sabach and Shimrit Shtern. A first order method for solving convex bilevel optimization problems. SIAM Journal on Optimization, 27 0 (2): 0 640--660, 2017
2017
-
[87]
Achieving optimal complexity guarantees for a class of bilevel convex optimization problems
Sepideh Samadi, Daniel Burbano, and Farzad Yousefian. Achieving optimal complexity guarantees for a class of bilevel convex optimization problems. 2024 American Control Conference (ACC), pp.\ 2206--2211, 2023. URL https://api.semanticscholar.org/CorpusID:264305773
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.