SwarmX: Agentic Scheduling for Low-Latency Agentic Systems
Pith reviewed 2026-06-26 13:08 UTC · model grok-4.3
The pith
SwarmX uses neural predictors of prompt-dependent runtimes to drive tail-aware routing and scaling in agentic AI clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
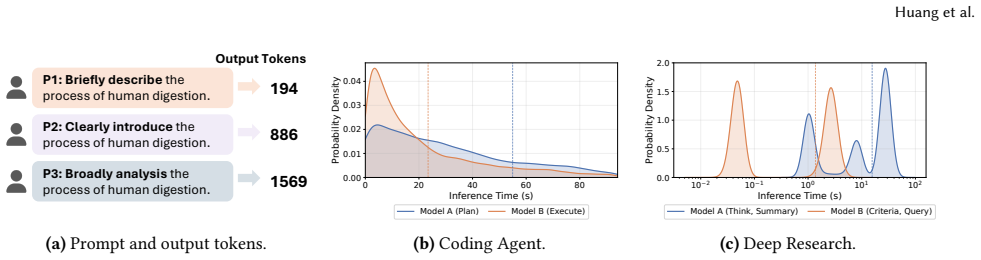
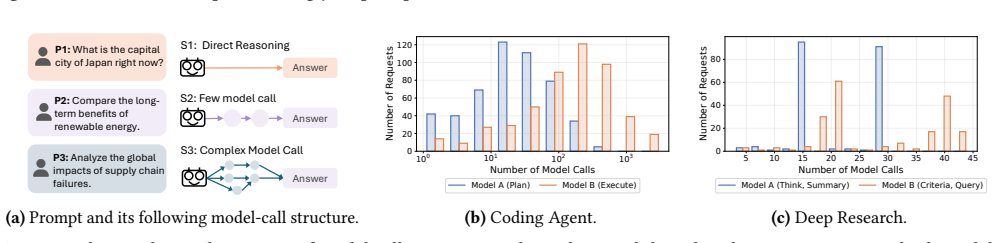
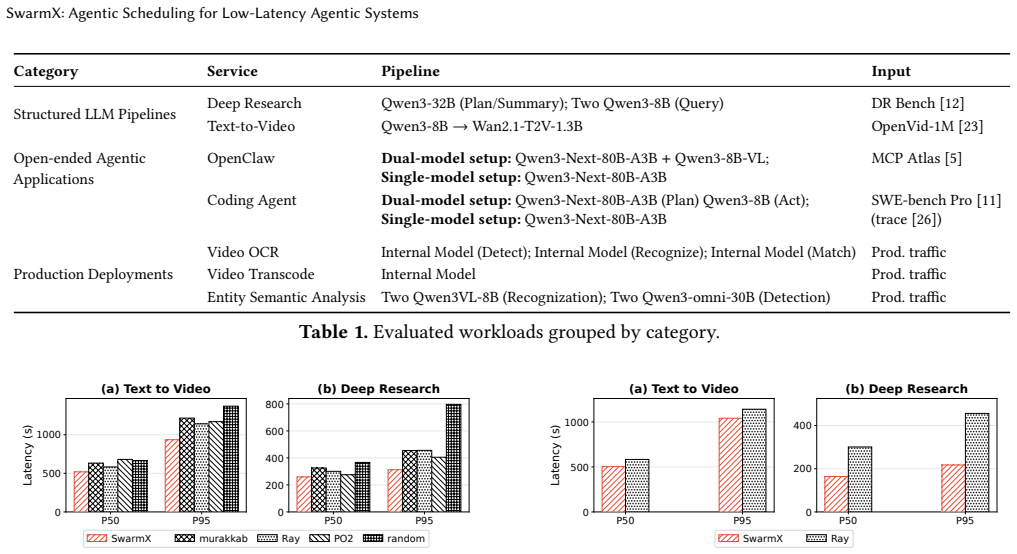
SwarmX implements agentic scheduling by training scheduling-specific neural predictors that ingest prompt, device, runtime, and target-model features and emit distributional forecasts of inference times; these forecasts are exposed to routers and scalers for tail-aware decisions inside a scheduler-agent framework that integrates with existing model-serving infrastructure, producing up to 61.5 percent lower tail latency and up to 2 times the throughput of prior schedulers under identical SLOs on multi-agent code generation, deep research, and multimodal workflows.
What carries the argument
Scheduling-specific neural predictors that output distributional forecasts of prompt-dependent inference times for use by routers and scalers.
If this is right
- Routers can now avoid slow execution paths by consulting full predicted distributions rather than averages.
- Scalers can provision resources with explicit awareness of tail risk instead of relying on mean latency.
- Existing model-serving stacks gain a common substrate for adding prompt-aware scheduling logic without rewriting core inference engines.
- Online adaptation keeps the forecasts aligned when prompt distributions shift over time.
Where Pith is reading between the lines
- The same distributional-prediction technique could be tested on other multi-step latency-sensitive systems such as database query planners or scientific pipeline schedulers.
- If the predictors remain accurate across rapid distribution shifts, clusters could safely reduce over-provisioning margins.
- A direct test would measure predictor error when new models are introduced or when user prompts change abruptly.
Load-bearing premise
The scheduling-specific neural predictors can be trained and adapted online to produce accurate distributional forecasts of prompt-dependent inference times that stay reliable under production load and prompt distributions.
What would settle it
Run the same workloads with the neural predictors replaced by constant or random time forecasts and check whether the reported tail-latency reductions and throughput gains disappear.
Figures









read the original abstract
Agentic AI applications compose multiple model calls and tool executions, creating new scheduling challenges for GPU-CPU clusters. Their inference time and model-call structure often depend on prompt semantics, making conventional scheduling approaches ineffective for low-latency serving. This paper presents SwarmX, a system that implements agentic scheduling for low-latency agentic applications. SwarmX uses scheduling-specific neural predictors to capture prompt, device, runtime, and target-model features; exposes distributional predictions to routers and scalers for tail-aware decisions; and provides mechanisms for predictor training and online adaptation. These predictors and mechanisms are integrated into a scheduler-agent framework that provides a common substrate for integration with existing scheduling and model-serving infrastructure. We evaluate SwarmX using production deployment (nearly one thousand GPUs and one million CPU cores) and controlled experiments on a 128-GPU testbed. Across multi-agent code generation, deep research, and multimodal agentic workflows, SwarmX reduces tail latency by up to 61.5% compared to state-of-the-art schedulers and sustains up to 2x the throughput of production schedulers under the same SLO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. SwarmX is presented as a system for agentic scheduling in low-latency agentic AI applications. It utilizes scheduling-specific neural predictors to model prompt-dependent inference time distributions using features from prompts, devices, runtimes, and target models. These distributional predictions are exposed to routers and scalers for tail-aware scheduling decisions. The system is embedded in a scheduler-agent framework for integration with existing infrastructure. Evaluations in production (nearly 1000 GPUs, 1M CPU cores) and on a 128-GPU testbed show up to 61.5% tail latency reduction vs. SOTA schedulers and up to 2x throughput under same SLO for multi-agent code gen, deep research, and multimodal workflows.
Significance. Should the predictor accuracy and adaptation claims be validated with appropriate metrics and ablations, the work would offer a meaningful contribution to scheduling in dynamic, prompt-semantics-dependent agentic systems at scale. The production-scale evaluation and focus on distributional forecasts distinguish it from conventional approaches.
major comments (2)
- [Abstract] The central performance claims (61.5% tail latency reduction, 2x throughput) depend on the scheduling-specific neural predictors producing reliable distributional forecasts of inference times, yet the abstract provides no reported metrics on their accuracy (point or distributional, e.g., pinball loss or quantile calibration), no ablation on predictor error under prompt distribution shift, and no characterization of online adaptation stability at the claimed production scale of 1000 GPUs.
- [Evaluation (production deployment and controlled experiments)] The evaluation using production deployment and controlled experiments supplies no information on baselines, statistical methods, workload definitions, or how predictors were validated, making it impossible to judge whether the data support the reported gains or to attribute them to the described scheduling mechanisms.
minor comments (1)
- [Abstract] The description of the workloads (multi-agent code generation, deep research, multimodal agentic workflows) could be expanded with more specific definitions or references to standard benchmarks for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the abstract and evaluation section would benefit from explicit reporting of predictor metrics and methodological details. We will perform a major revision to incorporate these elements without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract] The central performance claims (61.5% tail latency reduction, 2x throughput) depend on the scheduling-specific neural predictors producing reliable distributional forecasts of inference times, yet the abstract provides no reported metrics on their accuracy (point or distributional, e.g., pinball loss or quantile calibration), no ablation on predictor error under prompt distribution shift, and no characterization of online adaptation stability at the claimed production scale of 1000 GPUs.
Authors: We agree the abstract should surface these metrics. In revision we will add: (1) pinball loss and quantile calibration error for the distributional predictors, (2) a one-sentence summary of the ablation on prompt distribution shift, and (3) a brief statement on adaptation stability measured over the production trace at ~1000 GPUs. These numbers already exist in the body (Section 4.2 and 5.3) but were omitted from the abstract for brevity. revision: yes
-
Referee: [Evaluation (production deployment and controlled experiments)] The evaluation using production deployment and controlled experiments supplies no information on baselines, statistical methods, workload definitions, or how predictors were validated, making it impossible to judge whether the data support the reported gains or to attribute them to the described scheduling mechanisms.
Authors: We accept that the current evaluation write-up is insufficiently explicit. We will expand Section 5 with: (a) a table listing all baselines and their configurations, (b) a paragraph on statistical methods (95th-percentile latency, 10 independent runs, bootstrap CIs), (c) precise workload definitions including prompt distributions and arrival traces, and (d) predictor validation protocol (offline hold-out plus online monitoring). This will allow readers to reproduce the attribution of gains to the tail-aware mechanisms. revision: yes
Circularity Check
No circularity: empirical systems evaluation with external measurements
full rationale
The paper describes a scheduling system (SwarmX) whose core claims—tail latency reductions up to 61.5% and 2x throughput—are presented as outcomes of production deployment on ~1000 GPUs and controlled 128-GPU experiments. No equations, derivations, or self-referential fitting steps appear in the abstract or described content. Neural predictors are trained and adapted online, but their outputs are evaluated against observed performance rather than defined to match the reported gains by construction. The evaluation is therefore self-contained against external benchmarks and does not reduce to any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anomaly. 2026. OpenCode: The Open Source Coding Agent.https: //github.com/anomalyco/opencodeAccessed: 2026-05-15
2026
-
[2]
Anthropic. 2025. Claude Code: Anthropic’s agentic coding system. https://www.anthropic.com/product/claude-codeAccessed: 2026-05- 11
2025
-
[3]
Kubernetes Authors. 2025. Production-Grade Container Orchestration. https://kubernetes.io/
2025
-
[4]
Ray Authors. 2025. Ray.https://docs.ray.io/en/latest/ray-core/ walkthrough.html
2025
-
[5]
Chaithanya Bandi, Ben Hertzberg, Geobio Boo, Tejas Polakam, Jeff Da, Sami Hassaan, Manasi Sharma, Andrew Park, Ernesto Hernan- dez, Dan Rambado, Ivan Salazar, Rafael Cruz, Chetan Rane, Ben Levin, Brad Kenstler, and Bing Liu. 2026. MCP-Atlas: A Large- Scale Benchmark for Tool-Use Competency with Real MCP Servers. arXiv:2602.00933 [cs.SE]https://arxiv.org/a...
Pith/arXiv arXiv 2026
-
[6]
Romil Bhardwaj, Kirthevasan Kandasamy, Asim Biswal, Wenshuo Guo, Benjamin Hindman, Joseph Gonzalez, Michael Jordan, and Ion Stoica
-
[7]
In17th USENIX Symposium on Operat- ing Systems Design and Implementation (OSDI 23)
Cilantro: Performance-Aware Resource Allocation for General Objectives via Online Feedback. In17th USENIX Symposium on Operat- ing Systems Design and Implementation (OSDI 23). USENIX Association, Boston, MA, 623–643.https://www.usenix.org/conference/osdi23/ presentation/bhardwaj
-
[8]
Gohar Irfan Chaudhry, Esha Choukse, Haoran Qiu, Íñigo Goiri, Ro- drigo Fonseca, Adam Belay, and Ricardo Bianchini. 2025. Murakkab: Resource-Efficient Agentic Workflow Orchestration in Cloud Plat- forms. arXiv:2508.18298 [cs.MA]https://arxiv.org/abs/2508.18298
arXiv 2025
-
[9]
Comfy Org. 2026. ComfyUI: The Most Powerful and Modular Diffusion Model GUI, API and Backend with a Graph/Nodes Interface.https: //github.com/comfy-org/ComfyUIAccessed: 2026-05-15
2026
-
[10]
CrewAI. 2024. CrewAI: Framework for orchestrating role-playing, autonomous AI agents.https://github.com/joaomdmoura/crewAI
2024
-
[11]
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. 2025. PaddleOCR 3.0 Technical Report. arXiv:2507.05595 [cs.CV]https://arxiv.org/abs/2507.05595
Pith/arXiv arXiv 2025
-
[12]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. 2025. SWE-Bench Pro: Can AI Agents Solve L...
Pith/arXiv arXiv 2025
-
[13]
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. 2025. DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents. arXiv:2506.11763 [cs.CL]https://arxiv.org/ abs/2506.11763
Pith/arXiv arXiv 2025
-
[14]
Abdullah Bin Faisal, Noah Martin, Hafiz Mohsin Bashir, Swaminathan Lamelas, and Fahad R Dogar. 2024. When will my {ML} Job finish? Toward providing Completion Time Estimates through{Predictability- Centric} Scheduling. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 487–505
2024
-
[15]
In Gim, Zhiyao Ma, Seung-seob Lee, and Lin Zhong. 2025. Pie: A Programmable Serving System for Emerging LLM Applications. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 415–430
2025
-
[16]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[17]
and Zhang, Hao and Stoica, Ion , booktitle =
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New York, NY, USA, 611–626. doi:10.1145/3600006.3613165
-
[18]
LangChain. 2024. LangGraph: Build resilient language agents as graphs.https://github.com/langchain-ai/langgraph
2024
-
[19]
Yaniv Leviathan, Dani Valevski, Matan Kalman, Danny Lumen, Eyal Se- galis, Eyal Molad, Shlomi Pasternak, Vishnu Natchu, Valerie Nygaard, Srinivasan, Venkatachary, James Manyika, and Yossi Matias. 2026. Gen- erative UI: LLMs are Effective UI Generators. arXiv:2604.09577 [cs.HC] https://arxiv.org/abs/2604.09577
Pith/arXiv arXiv 2026
-
[20]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient serving of {LLM-based} applications with semantic variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 929–945
2024
-
[21]
Weiwen Liu, Xu Huang, Xingshan Zeng, xinlong hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, Zezhong WANG, Yuxian Wang, Wu Ning, Yutai Hou, Bin Wang, Chuhan Wu, Wang Xinzhi, Yong Liu, Yasheng Wang, Duyu Tang, Dandan Tu, Lifeng Shang, Xin Jiang, Ruiming Tang, Defu Lian, Qun Liu, and Enhong Chen. 2025. ToolACE: Winning the Point...
2025
-
[22]
Ashraf Mahgoub, Edgardo Barsallo Yi, Karthick Shankar, Sameh El- nikety, Somali Chaterji, and Saurabh Bagchi. 2022. ORION and the Three Rights: Sizing, Bundling, and Prewarming for Serverless DAGs. In16th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 22). USENIX Association, Carlsbad, CA, 303–320. https://www.usenix.org/conferenc...
2022
-
[23]
Microsoft. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation.https://github.com/microsoft/autogen
2024
-
[24]
M. Mitzenmacher. 2001. The power of two choices in randomized load balancing.IEEE Transactions on Parallel and Distributed Systems12, 10 (2001), 1094–1104. doi:10.1109/71.963420
-
[25]
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. 2024. OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation.arXiv preprint arXiv:2407.02371(2024)
Pith/arXiv arXiv 2024
-
[26]
OpenAI. 2026. Codex: Lightweight Coding Agent that Runs in Your Terminal.https://github.com/openai/codexAccessed: 2026-05-15
2026
-
[27]
OpenClaw Contributors. 2026. OpenClaw: Personal AI Assistant. https://github.com/openclaw/openclawAccessed: 2026-05-15
2026
-
[28]
2026.DataClaw PeterOMallet: Coding Agent Conver- sation Logs.https://huggingface.co/datasets/peteromallet/dataclaw- peteromalletMIT License, accessed 2026-05-15
Peter O’Malley. 2026.DataClaw PeterOMallet: Coding Agent Conver- sation Logs.https://huggingface.co/datasets/peteromallet/dataclaw- peteromalletMIT License, accessed 2026-05-15
2026
-
[29]
Malte Schwarzkopf, Andy Konwinski, Michael Abd-El-Malek, and John Wilkes. 2013. Omega: flexible, scalable schedulers for large compute clusters. InProceedings of the 8th ACM European Confer- ence on Computer Systems(Prague, Czech Republic)(EuroSys ’13). Association for Computing Machinery, New York, NY, USA, 351–364. doi:10.1145/2465351.2465386
-
[30]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 173–191.https://www.usenix.org/conference/osdi24/ presentation/sun-biao
2024
-
[31]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. DeepSeek-OCR: Con- texts Optical Compression.arXiv preprint arXiv:2510.18234(2025)
Pith/arXiv arXiv 2025
-
[32]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Asso- ciation, Carlsbad, CA, 521–538.https://www.usenix.org/conference/ osdi22/presentation/yu
2022
-
[33]
Shan Yu, Junyi Shu, Yuanjiang Ni, Kun Qian, Xue Li, Yang Wang, Jinyuan Zhang, Ziyi Xu, Shuo Yang, Lingjun Zhu, Ennan Zhai, Qingda Lu, Jiarong Xing, Youyou Lu, Xin Jin, Xuanzhe Liu, and Harry Xu. 2026. Pythia: Exploiting Workflow Predictability for Efficient Agent-Native LLM Serving. arXiv:2604.25899 [cs.MA]https://arxiv.org/abs/2604. 25899
Pith/arXiv arXiv 2026
-
[34]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: effi- cient execution of structured language model programs. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC,...
2024
-
[35]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 193– 210.https://www.usenix.org/co...
2024
-
[36]
Hang Zhou, Yehui Tang, Haochen Qin, Yujie Yang, Renren Jin, Deyi Xiong, Kai Han, and Yunhe Wang. 2024. Star-agents: automatic data optimization with LLM agents for instruction tuning. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red Hook, NY, USA, Arti...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.