Robot Self-Improvement via Human-Video Dynamics Models
Pith reviewed 2026-06-26 14:38 UTC · model grok-4.3
The pith
Human videos supply transferable models that let robots correct their own failures and improve policies without extra data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
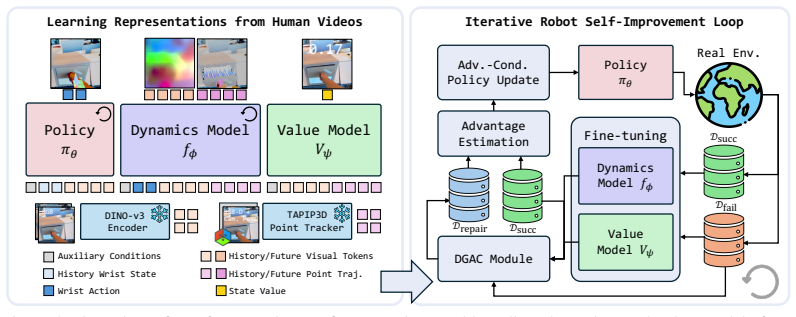
Human videos can be used to learn embodiment-agnostic action, dynamics, and value representations that transfer across robot embodiments, providing the predictive foundation required for robots to autonomously improve from their own rollouts and failures. We introduce Dynamics-Guided Action Correction (DGAC), a training-free approach that leverages these adapted models to repair failed states: each failure becomes a query for which the learned models propose and rank corrective actions, turning failures into supervision for the next policy update. Across seven real-world manipulation tasks spanning both a mobile manipulator and a static manipulator arm, our approach improves success rates fr
What carries the argument
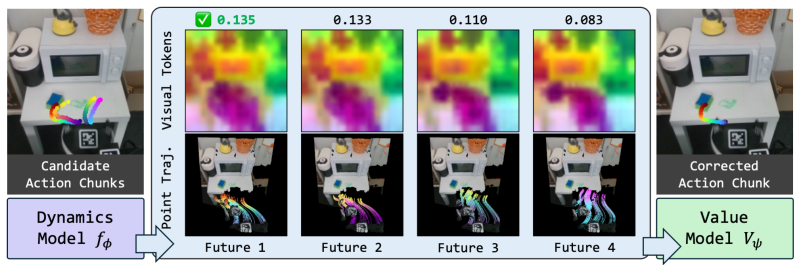
Dynamics-Guided Action Correction (DGAC), a training-free procedure that queries the human-video models to propose and rank corrective actions for each observed robot failure state.
If this is right
- Robot policies can be improved iteratively using only their own failed rollouts and the fixed human-video models.
- The same human-video representations work for both mobile and fixed-base manipulators without embodiment-specific changes.
- Multiple different policy backbones receive large gains from the same correction procedure.
- Self-improvement no longer requires fresh robot data collection or model retraining after the initial human-video stage.
Where Pith is reading between the lines
- Robots could keep refining behaviors in homes or factories by treating everyday failures as new supervision signals.
- The approach suggests shifting data collection emphasis from robot demonstrations toward large-scale human video archives.
- Similar failure-to-correction loops might appear in other embodied domains such as mobile navigation once suitable video priors exist.
Load-bearing premise
The action, dynamics, and value representations extracted from human videos remain accurate enough on robot bodies to identify and rank useful corrective actions without any robot-specific retraining.
What would settle it
Running DGAC on a new robot embodiment or task and finding that success rates stay flat or drop compared with the uncorrected policy.
Figures




read the original abstract
A central question in robot learning is how to acquire skills from the kinds of data that humans learn from: passive observation, embodied practice, and the experience of failure. Human videos provide the first of these in abundance, and prior work has shown they can initialize useful policies. Far less clear is whether they can support the second and third: whether priors extracted from human videos can ground a robot's own attempts well enough to evaluate them, correct them, and improve from them. In this work, we show that human videos can be used to learn embodiment-agnostic action, dynamics, and value representations that transfer across robot embodiments, providing the predictive foundation required for robots to autonomously improve from their own rollouts and failures. We introduce Dynamics-Guided Action Correction (DGAC), a training-free approach that leverages these adapted models to repair failed states: each failure becomes a query for which the learned models propose and rank corrective actions, turning failures into supervision for the next policy update. Across seven real-world manipulation tasks spanning both a mobile manipulator and a static manipulator arm, our approach improves success rates from 40% to 81% across multiple policy backbones, demonstrating cross-embodiment robot self-improvement from human-video priors. These results show that human priors and robot failures can be combined to enable scalable autonomous policy improvement. Project page: https://ethz-mrl.github.io/robot-self-improvement-website/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that human videos can be used to learn embodiment-agnostic action, dynamics, and value representations that transfer across robot embodiments. It introduces Dynamics-Guided Action Correction (DGAC), a training-free method that leverages these models to repair failed robot states by proposing and ranking corrective actions from failures, enabling autonomous policy improvement. Empirical results across seven real-world manipulation tasks on a mobile manipulator and a static arm show success rates rising from 40% to 81% across multiple policy backbones.
Significance. If the central empirical claim holds with rigorous validation, the work would demonstrate a scalable route to robot self-improvement that combines abundant passive human video data with robot-specific failures, reducing reliance on embodiment-specific training data.
major comments (2)
- [Abstract] Abstract: the central claim of reliable cross-embodiment transfer and corrective-action ranking rests on the assertion that human-video models remain accurate on robot states without adaptation, yet the abstract supplies no methods, observation-alignment procedure, or failure analysis, rendering the 40%-to-81% improvement impossible to evaluate for soundness or post-hoc selection.
- [Abstract] The weakest assumption (human-video dynamics and value estimates suffice to rank corrective actions on robot states) is load-bearing for the self-improvement result; without explicit quantification of embodiment gap or ablation on alignment steps, it is unclear whether the reported gains are attributable to the claimed priors or to unstated robot-specific components.
minor comments (1)
- The project page is referenced but no quantitative results, code, or additional experimental details appear in the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. The comments highlight opportunities to strengthen the presentation of our cross-embodiment claims. We address each point below and will revise the abstract to improve clarity and evaluability while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of reliable cross-embodiment transfer and corrective-action ranking rests on the assertion that human-video models remain accurate on robot states without adaptation, yet the abstract supplies no methods, observation-alignment procedure, or failure analysis, rendering the 40%-to-81% improvement impossible to evaluate for soundness or post-hoc selection.
Authors: The abstract is a high-level summary; the full manuscript details the training-free DGAC procedure, the embodiment-agnostic representations, and the observation alignment steps used to apply human-video models to robot states. We agree the abstract can better support evaluation and will revise it to briefly reference the alignment procedure (e.g., visual feature matching) and note that results are aggregated across seven tasks and multiple policy backbones with no post-hoc selection. Full failure analysis and per-task breakdowns appear in Section 5. revision: yes
-
Referee: [Abstract] The weakest assumption (human-video dynamics and value estimates suffice to rank corrective actions on robot states) is load-bearing for the self-improvement result; without explicit quantification of embodiment gap or ablation on alignment steps, it is unclear whether the reported gains are attributable to the claimed priors or to unstated robot-specific components.
Authors: The manuscript includes ablations across policy backbones and comparisons with and without the human-video priors to attribute gains to the cross-embodiment models. The DGAC method is explicitly training-free on robot data. We will revise the abstract to state that no robot-specific fine-tuning or adaptation of the dynamics/value models occurs, and we will add a parenthetical reference to the alignment ablations in the main text. Explicit numerical quantification of the embodiment gap (e.g., prediction error deltas) is not currently reported and would require additional analysis. revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript text (abstract plus full description) presents an empirical method (DGAC) and reports success-rate improvements on real-world tasks. No equations, derivations, fitted parameters, or mathematical claims appear that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The central claim is an observed performance gain from human-video priors transferred without embodiment-specific adaptation; this is framed as an experimental outcome rather than a closed-form derivation that collapses to its inputs by construction. No load-bearing steps matching the enumerated circularity patterns are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn. Bc- z: Zero-shot task generalization with robotic imitation learning. InCoRL, pages 991–1002. PMLR, 2022
2022
-
[2]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: A vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[3]
J. Yang, K. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, et al. Rise: Self-improving robot policy with compositional world model.arXiv preprint arXiv:2602.11075, 2026
Pith/arXiv arXiv 2026
-
[4]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation, 2022. arXiv:2203.12601. 9
Pith/arXiv arXiv 2022
-
[5]
Bharadhwaj, A
H. Bharadhwaj, A. Gupta, V . Kumar, and S. Tulsiani. Towards generalizable zero-shot manip- ulation via translating human interaction plans. InICRA, pages 6904–6911. IEEE, 2024
2024
-
[6]
T. Xiao, I. Radosavovic, T. Darrell, and J. Malik. Masked visual pre-training for motor control. arXiv preprint arXiv:2203.06173, 2022
arXiv 2022
-
[7]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards univer- sal visual reward and representation via value-implicit pre-training, 2023. arXiv:2210.00030
Pith/arXiv arXiv 2023
-
[8]
H. Chen, B. Sun, A. Zhang, M. Pollefeys, and S. Leutenegger. Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation.CVPR, 2025
2025
-
[9]
M. Xu, Z. Xu, Y . Xu, C. Chi, G. Wetzstein, M. Veloso, and S. Song. Flow as the cross-domain manipulation interface. InCoRL, 2024
2024
- [10]
-
[11]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
-
[12]
Borja-Diaz, O
J. Borja-Diaz, O. Mees, G. Kalweit, L. Hermann, J. Boedecker, and W. Burgard. Affordance learning from play for sample-efficient policy learning. InProceedings of the IEEE Interna- tional Conference on Robotics and Automation (ICRA), Philadelphia, USA, 2022
2022
-
[13]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024
Pith/arXiv arXiv 2024
- [14]
-
[15]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[16]
Z. Feng, Q. Li, H. Liang, R. Yang, Y . Shen, Z. Du, Z. Zhang, Y . Deng, L. Zhao, H. Zhao, Z. Lu, O. Mees, M. Pollefeys, J. Yang, and B. Guo. From human videos to robot manipulation: A survey on scalable vision-language-action learning with human-centric data. InProceed- ings of the 35th International Joint Conference on Artificial Intelligence (IJCAI-26),...
2026
-
[17]
S. Bahl, A. Gupta, and D. Pathak. Human-to-robot imitation in the wild.arXiv preprint arXiv:2207.09450, 2022
arXiv 2022
-
[18]
A. S. Chen, S. Nair, and C. Finn. Learning generalizable robotic reward functions from" in- the-wild" human videos.arXiv preprint arXiv:2103.16817, 2021
arXiv 2021
-
[19]
O. Mees, M. Merklinger, G. Kalweit, and W. Burgard. Adversarial skill networks: Unsuper- vised robot skill learning from videos. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 2020
2020
-
[20]
J. Shi, J. Smith, J. Qian, and D. Jayaraman. Points2reward: Robotic manipulation rewards from just one video. InRobotics: Science and Systems (RSS), 2025
2025
-
[21]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from human videos as a versatile representation for robotics. InCVPR, pages 13778–13790, 2023. 10
2023
-
[22]
R. Mendonca, S. Bahl, and D. Pathak. Structured world models from human videos.arXiv preprint arXiv:2308.10901, 2023
arXiv 2023
- [23]
-
[24]
Papagiannis, N
G. Papagiannis, N. D. Palo, P. Vitiello, and E. Johns. R+x: Retrieval and execution from everyday human videos.ICRA, 2025
2025
-
[25]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InECCV, pages 570–587. Springer, 2022
2022
-
[26]
Q. Li, Y . Deng, Y . Liang, L. Luo, L. Zhou, C. Yao, L. Zeng, Z. Feng, H. Liang, S. Xu, et al. Scalable vision-language-action model pretraining for robotic manipulation with real-life hu- man activity videos.arXiv preprint arXiv:2510.21571, 2025
arXiv 2025
-
[27]
C. Yuan, C. Wen, T. Zhang, and Y . Gao. General flow as foundation affordance for scalable robot learning.CoRL, 2024
2024
-
[28]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[29]
Nagabandi, K
A. Nagabandi, K. Konolige, S. Levine, and V . Kumar. Deep dynamics models for learning dexterous manipulation. InConference on robot learning, pages 1101–1112. PMLR, 2020
2020
-
[30]
K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models.Advances in neural information processing systems, 31, 2018
2018
-
[31]
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
Pith/arXiv arXiv 1912
-
[32]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[33]
Nematollahi, O
I. Nematollahi, O. Mees, L. Hermann, and W. Burgard. Hindsight for foresight: Un- supervised structured dynamics models from physical interaction. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Ve- gas, USA, 2020. URLhttp://ais.informatik.uni-freiburg.de/publications/ papers/nematoli20iros.pdf
2020
-
[34]
B. Hou, G. Li, J. Jia, T. An, X. Guo, S. Leng, H. Geng, Y . Ze, T. Harada, P. Torr, O. Mees, M. Pollefeys, Z. Liu, J. Wu, P. Abbeel, J. Malik, Y . Du, and J. Yang. World model for robot learning: A comprehensive survey.arXiv preprint arXiv:2605.00080, 2026
Pith/arXiv arXiv 2026
-
[35]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
Pith/arXiv arXiv 2025
-
[36]
A. L. Chandra, I. Nematollahi, C. Huang, T. Welschehold, W. Burgard, and A. Valada. Diwa: Diffusion policy adaptation with world models.arXiv preprint arXiv:2508.03645, 2025
arXiv 2025
-
[37]
G. R. Team, K. Choromanski, C. Devin, Y . Du, D. Dwibedi, R. Gao, A. Jindal, T. Kipf, S. Kir- mani, I. Leal, et al. Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025
arXiv 2025
-
[39]
H. Qi, H. Yin, A. Zhu, Y . Du, and H. Yang. Inference-time enhancement of generative robot policies via predictive world modeling.IEEE Robotics and Automation Letters, 2026
2026
- [40]
-
[41]
L. Ke, Y . Zhang, A. Deshpande, S. Srinivasa, and A. Gupta. Ccil: Continuity-based data augmentation for corrective imitation learning.arXiv preprint arXiv:2310.12972, 2023
arXiv 2023
-
[42]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through neural trajectories.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[43]
P. Wu, Y . Shentu, Q. Liao, D. Jin, M. Guo, K. Sreenath, X. Lin, and P. Abbeel. Robocopi- lot: Human-in-the-loop interactive imitation learning for robot manipulation.arXiv preprint arXiv:2503.07771, 2025
arXiv 2025
-
[44]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[45]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[46]
Z. Zhou, P. Atreya, A. Lee, H. Walke, O. Mees, and S. Levine. Autonomous improvement of instruction following skills via foundation models.arXiv preprint arXiv:407.20635, 2024
2024
-
[47]
D. Kalashnikov, J. Varley, Y . Chebotar, B. Swanson, R. Jonschkowski, C. Finn, S. Levine, and K. Hausman. Mt-opt: Continuous multi-task robotic reinforcement learning at scale.arXiv preprint arXiv:2104.08212, 2021
arXiv 2021
-
[48]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
Pith/arXiv arXiv 2025
-
[49]
K. Lei, H. Li, D. Yu, Z. Wei, L. Guo, Z. Jiang, Z. Wang, S. Liang, and H. Xu. Rl- 100: Performant robotic manipulation with real-world reinforcement learning.arXiv preprint arXiv:2510.14830, 2025
arXiv 2025
-
[50]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision-language- action model with online reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15665–15672. IEEE, 2025
2025
-
[51]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. Fan, et al. Self- improving vision-language-action models with data generation via residual rl.arXiv preprint arXiv:2511.00091, 2025
arXiv 2025
- [52]
-
[53]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[54]
T. Li and K. He. Back to basics: Let denoising generative models denoise, 2025.URL https://arxiv. org/abs/2511.13720, 7, 2026
Pith/arXiv arXiv 2025
-
[55]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023. 12
Pith/arXiv arXiv 2023
- [56]
-
[57]
O. Siméoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Cou- prie, J. Mairal, H. Jégou, P. Labatut, and P. Bojanowski. DINOv3, 2025. URLhttps: //arxiv.org/abs/...
Pith/arXiv arXiv 2025
-
[58]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
- [59]
-
[60]
R. S. Sutton. Learning to predict by the methods of temporal differences.Machine learning, 3 (1):9–44, 1988
1988
-
[61]
X. B. Peng, A. Kumar, G. Zhang, and S. Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.CoRR, abs/1910.00177, 2019. URLhttps: //arxiv.org/abs/1910.00177
Pith/arXiv arXiv 1910
-
[62]
Mendonca, S
R. Mendonca, S. Bahl, and D. Pathak. Structured world models from human videos. InRSS, 2023
2023
- [63]
-
[64]
Openai gpt-5 system card, 2026
OpenAI. Openai gpt-5 system card, 2026. URLhttps://arxiv.org/abs/2601.03267
Pith/arXiv arXiv 2026
-
[65]
Y . Liu, Y . Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. InCVPR, pages 21013–21022, June 2022
2022
-
[66]
Werby, M
A. Werby, M. Büchner, A. Röfer, C. Huang, W. Burgard, and A. Valada. Articulated object estimation in the wild. InConference on Robot Learning (CoRL), volume 2, 2025
2025
-
[67]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
Pith/arXiv arXiv 2025
-
[68]
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[69]
Pavlakos, D
G. Pavlakos, D. Shan, I. Radosavovic, A. Kanazawa, D. Fouhey, and J. Malik. Reconstructing hands in 3D with transformers. InCVPR, 2024
2024
-
[70]
Savitzky and M
A. Savitzky and M. J. Golay. Smoothing and differentiation of data by simplified least squares procedures.Analytical chemistry, 36(8):1627–1639, 1964
1964
-
[71]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[72]
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
2025
-
[73]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InCVPR, pages 5745–5753, 2019. 13
2019
-
[74]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun. Navigation world models, 2024. URL https://arxiv.org/abs/2412.03572
arXiv 2024
-
[75]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[76]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[77]
Wan Team, A. Wang, B. Ai, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 14 A.1 Supplementary Video We include a supplementary video showcasing an overview of our framework, along with demon- strations of various real-world robot manipulation tasks:https://www.youtube.com/watch?v= ZW3ZHjrllJA. A.2 ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.