MIRCaps: A Large-Scale Mixed-Domain Dataset with Image-Level and Region-Level Captions for Fine-Grained Vision-Language Learning
Pith reviewed 2026-06-26 14:24 UTC · model grok-4.3
The pith
A mixed-domain dataset supplies image-level and region-level captions to fine-tune lightweight vision-language models on fine-grained attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
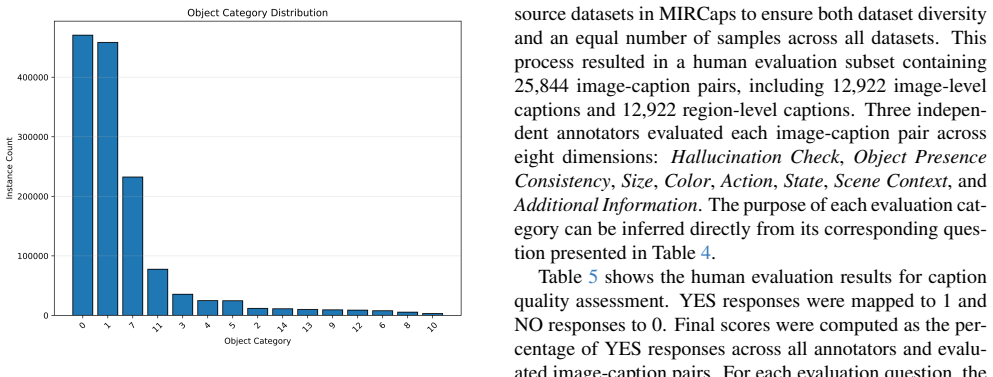
MIRCaps provides 141364 images with an average of seven image-level captions per image and seven region-level captions per bounding box, for totals of 981947 image captions, 1742264 region captions, and 1391779 boxes. The dual caption types are constructed to help models learn fine-grained visual attributes including object categories, estimated sizes, colors, actions, states, and surrounding environmental context in both general-purpose and surveillance domains. Experiments confirm that fine-tuning the listed lightweight VLMs on the dataset produces usable gains on image captioning and object detection tasks.
What carries the argument
Dual-level caption annotations that pair multiple scene-wide descriptions with multiple per-region descriptions linked to bounding boxes.
If this is right
- Lightweight VLMs can be fine-tuned for image captioning using the dual-caption structure.
- The same fine-tuning produces gains on object detection tasks.
- Models acquire the ability to describe estimated sizes, colors, actions, states, and environmental context.
- The mixed-domain coverage supports both general-purpose and surveillance applications.
Where Pith is reading between the lines
- The dual annotation pattern could transfer to video sequences for temporal fine-grained description in surveillance.
- Region-level captions may support better handling of rare object categories through explicit attribute training.
- Combining this dataset with existing general-purpose collections could yield further gains on standard benchmarks.
Load-bearing premise
The image-level and region-level captions accurately capture fine-grained visual attributes including object categories, estimated sizes, colors, actions, states, and surrounding environmental context.
What would settle it
Fine-tuning the listed models on the dataset and observing no improvement in standard captioning metrics such as BLEU or CIDEr and no gain in detection mAP relative to training on prior datasets alone would falsify the utility claim.
Figures








read the original abstract
Despite recent progress in Vision-Language Models (VLMs), mixed-domain image-caption datasets for both general-purpose and CCTV-based video surveillance systems remain limited. To address this gap, we introduce a large-scale multimodal dataset comprising 141,364 images, 981,947 image-level captions, 1,742,264 region-level captions, and 1,391,779 bounding box annotations. Each image is associated with an average of seven image-level captions describing different aspects of the overall scene, as well as seven region-level captions for each annotated bounding box. These complementary caption types are designed to help VLMs learn fine-grained visual attributes, including object categories, estimated sizes, colors, actions, states, and surrounding environmental context. We demonstrate the effectiveness of the dataset on two important downstream tasks: image captioning and object detection. Experimental results show that lightweight VLMs, including SmolVLM-256M-Instruct, BLIP, BLIP2, and Qwen2.5-VL 3B-Instruct, can be effectively fine-tuned using our dataset. Our dataset and code are publicly available at https://zenodo.org/records/20418601.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIRCaps, a mixed-domain dataset containing 141,364 images, 981,947 image-level captions, 1,742,264 region-level captions, and 1,391,779 bounding boxes. Each image has an average of seven image-level captions and seven region-level captions per bounding box, intended to support fine-grained VLM learning of attributes such as object categories, sizes, colors, actions, states, and environmental context. The authors claim to demonstrate the dataset's utility through fine-tuning of lightweight VLMs (SmolVLM-256M-Instruct, BLIP, BLIP2, Qwen2.5-VL 3B-Instruct) on image captioning and object detection tasks, with the dataset and code released publicly.
Significance. A validated, large-scale public dataset spanning general and CCTV surveillance domains with paired image- and region-level captions would address a documented gap in mixed-domain vision-language resources and enable reproducible fine-tuning experiments. The public Zenodo release and stated code availability constitute a concrete strength that would facilitate follow-on work if the caption quality and fine-tuning claims are substantiated with metrics.
major comments (2)
- [Abstract] Abstract: The central claim that 'lightweight VLMs, including SmolVLM-256M-Instruct, BLIP, BLIP2, and Qwen2.5-VL 3B-Instruct, can be effectively fine-tuned using our dataset' on image captioning and object detection is unsupported by any quantitative metrics (e.g., CIDEr, BLEU, mAP), baseline comparisons, training hyperparameters, or before/after performance deltas. This absence is load-bearing for the effectiveness demonstration.
- [Abstract / Dataset Construction] Dataset description (abstract and presumed §3): No annotation protocol, inter-annotator agreement, or quality metric (human or automatic) is reported for the 981k image-level and 1.7M region-level captions. Without evidence that these captions accurately encode the claimed fine-grained attributes, the causal link between the dataset and any downstream fine-tuning gains cannot be established.
minor comments (1)
- [Abstract] The average of seven captions per image and per box is stated; reporting the distribution or variance of caption counts would improve transparency of the dataset statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger quantitative support and annotation details. We address each major comment below and will revise the manuscript accordingly to substantiate the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'lightweight VLMs, including SmolVLM-256M-Instruct, BLIP, BLIP2, and Qwen2.5-VL 3B-Instruct, can be effectively fine-tuned using our dataset' on image captioning and object detection is unsupported by any quantitative metrics (e.g., CIDEr, BLEU, mAP), baseline comparisons, training hyperparameters, or before/after performance deltas. This absence is load-bearing for the effectiveness demonstration.
Authors: We agree that the abstract's effectiveness claim requires explicit quantitative backing to be fully substantiated. The manuscript's Section 4 presents experimental results on fine-tuning the listed VLMs, but we will revise the abstract to incorporate key metrics (e.g., CIDEr and BLEU for captioning, mAP for detection), baseline comparisons, training hyperparameters, and performance deltas. This will directly address the load-bearing concern while preserving the original intent. revision: yes
-
Referee: [Abstract / Dataset Construction] Dataset description (abstract and presumed §3): No annotation protocol, inter-annotator agreement, or quality metric (human or automatic) is reported for the 981k image-level and 1.7M region-level captions. Without evidence that these captions accurately encode the claimed fine-grained attributes, the causal link between the dataset and any downstream fine-tuning gains cannot be established.
Authors: We concur that explicit details on caption quality are necessary to establish the link to downstream gains. We will expand the dataset construction section (presumed §3) in the revised manuscript to describe the annotation protocol, including the process for generating image-level and region-level captions, any inter-annotator agreement measures, and quality metrics (human or automatic) used to verify encoding of fine-grained attributes such as categories, sizes, colors, actions, states, and context. revision: yes
Circularity Check
Dataset release paper contains no derivations, equations, or predictions that could reduce to self-defined inputs.
full rationale
The manuscript introduces a new image-caption dataset and reports empirical fine-tuning results on standard VLMs. No equations, fitted parameters, uniqueness theorems, or ansatzes are present in the provided text. The central claims rest on dataset statistics and downstream task performance rather than any derivation chain that could be circular by construction. Self-citations are absent from the load-bearing sections. This is a standard non-circular dataset contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- Average number of captions per image and per region =
seven
axioms (1)
- domain assumption Images from general and CCTV domains can be annotated with bounding boxes and descriptive captions that capture fine-grained attributes.
Reference graph
Works this paper leans on
-
[1]
nocaps: Novel object caption- ing at scale
Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Ste- fan Lee, and Peter Anderson. nocaps: Novel object caption- ing at scale. InCVPR, 2019. 4
2019
-
[2]
Smarteyes: Plug-and-play event detection for retail loss pre- vention
Pi-Wei Chen, Jerry Chun-Wei Lin, Barıs Fahri Kahrıman, Zih-Ching Chen, Rafał Cupek, and Marek Drewniakk. Smarteyes: Plug-and-play event detection for retail loss pre- vention. InAAAI, 2026. 1
2026
-
[3]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedan- tam, Saurabh Gupta, Piotr Dollar, and C. Lawrence Zit- nick. Microsoft coco captions: Data collection and evalu- ation server.arXiv:1504.00325, 2015. 1, 4
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
Pedro Vinícius A. B. de Venâncio, Adriano C. Lisboa, and Adriano V . Barbosa. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices.Neural Computing and Appli- cations, 2022. 2, 4, 13, 17
2022
-
[5]
Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382,
Joseph Leonard Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382,
-
[6]
Clipscore: A reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning. 2021. 4
2021
-
[7]
Dataset of personal pro- tective equipment (ppe), 2025
Mei-Ling Huang and Ying Cheng. Dataset of personal pro- tective equipment (ppe), 2025. Mendeley Data, V6. 2, 4, 13, 17
2025
-
[8]
What’s in the im- age? a deep-dive into the vision of vision-language models
Omri Kaduri, Shai Bagon, and Tali Dekel. What’s in the im- age? a deep-dive into the vision of vision-language models. InCVPR, 2025. 1
2025
-
[9]
Shamma, Michael S
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual genome: Connecting language and vision using crowdsourced dense image annotations.IJCV, 2017. 4
2017
-
[10]
Real-time city- wide reconstruction of traffic flow from moving cameras on lightweight edge devices.ISPRS Journal of Photogrammetry and Remote Sensing, 192:115–129, 2022
Ashutosh Kumar, Takehiro Kashiyama, Hiroya Maeda, Hi- roshi Omata, and Yoshihide Sekimoto. Real-time city- wide reconstruction of traffic flow from moving cameras on lightweight edge devices.ISPRS Journal of Photogrammetry and Remote Sensing, 192:115–129, 2022. 2, 4, 13, 17
2022
-
[11]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1): 159–174, 1977. 5
1977
-
[12]
Object attribute matters in visual question answering
Peize Li, Qingyi Si, Peng Fu, Zheng Lin, and Yan Wang. Object attribute matters in visual question answering. In NeurIPS, 2024. 1
2024
-
[13]
Lawrence Zitnick, and Piotr Dollár
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context. InECCV, pages 740–755,
-
[14]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classi- fication of aircraft.arXiv:1306.5151, 2013. 2, 4, 13, 17
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
No-reference image quality assessment in the spa- tial domain.IEEE TIP, 21(12):4695–4708, 2012
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. No-reference image quality assessment in the spa- tial domain.IEEE TIP, 21(12):4695–4708, 2012. 4, 14
2012
-
[16]
completely blind
Anish Mittal, Soundararajan Rajiv, and Alan C. Bovik. Mak- ing a “completely blind” image quality analyzer.IEEE Sign. Process. Letters, 20(3):209–212, 2013. 4, 14
2013
- [17]
-
[18]
Vicente Ordonez, Girish Kulkarni, and Tamara L. Berg. Im2text: Describing images using 1 million captioned pho- tographs. InNeurIPS, 2011. 4
2011
-
[19]
Annotated fire-smoke image dataset for fire detection using yolo, 2025
Shouthiri Partheepan. Annotated fire-smoke image dataset for fire detection using yolo, 2025. CQUniversity Dataset. 2, 4, 13, 17
2025
-
[20]
Plummer, Liwei Wang, Chris M
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InICCV,
-
[21]
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv:2111.02114, 2021. 4
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Forest fire dataset, 2023
Ibrahim Shamta and Batıkan Erdem Demir. Forest fire dataset, 2023. Mendeley Data, V1. 2, 4, 13, 17
2023
-
[23]
CrowdHuman: A Benchmark for Detecting Human in a Crowd
Shuai Shao, Zijian Zhao, Boxun Li, Tete Xiao, Gang Yu, Xiangyu Zhang, and Jian Sun. Crowdhuman: A benchmark for detecting human in a crowd.arXiv:1805.00123, 2018. 2, 4, 13, 17
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Conceptual captions: A cleaned, hypernymed im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed im- age alt-text dataset for automatic image captioning. InACL,
-
[25]
Textcaps: A dataset for image caption- ing with reading comprehension
Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: A dataset for image caption- ing with reading comprehension. InECCV, 2020. 4
2020
-
[26]
Od-virat: A large-scale benchmark for object detection in realistic surveillance environments
Hayat Ullah, Abbas Khan, Arslan Munir, and Hari Kalva. Od-virat: A large-scale benchmark for object detection in realistic surveillance environments. InNeurIPS, 2011. 2, 4, 13, 17
2011
-
[27]
Channappayya, and S
Naga Venkata Naga Venkatanath, Debbabi Praneeth, Maruthi Chandrasekhar Bh, Sumohana S. Channappayya, and S. S. Medasani. Blind image quality evaluation using perception-based features. InTwenty First National Confer- ence on Communications (NCC), pages 1–6, 2015. 4, 14
2015
-
[28]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. Technical report, 2011. 2, 4, 13, 17
2011
-
[29]
A dataset for fire and smoke object detection.Multimedia Tools and Applications, 82(5), 2022
Siyuan Wu, Xinrong Zhang, Ruqi Liu, and Binhai Li. A dataset for fire and smoke object detection.Multimedia Tools and Applications, 82(5), 2022. 2, 4, 13, 17
2022
-
[30]
Hardhat-vest dataset,
Muhammet Zahit and Burhan Bulut. Hardhat-vest dataset,
-
[31]
2, 4, 13, 17
Kaggle Dataset. 2, 4, 13, 17
-
[32]
Detrs beat yolos on real-time object detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection. InCVPR,
-
[33]
Data, annotations, and evaluation code
Yitong Zheng and Shun Zhang. Mcships: A large-scale ship dataset for detection and fine-grained categorization in the wild. InICME, pages 1–6, 2020. 2, 4, 13, 17 Appendix A. Introduction Comparison of Image-Level Captions from SOTA LLMs and Our Dataset. Figure 7 provides a descriptive overview comparing image-level captions generated by state-of-the-art L...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.