IRumAI: Reinforcement Learning for Indian Rummy
Pith reviewed 2026-06-26 11:50 UTC · model grok-4.3
The pith
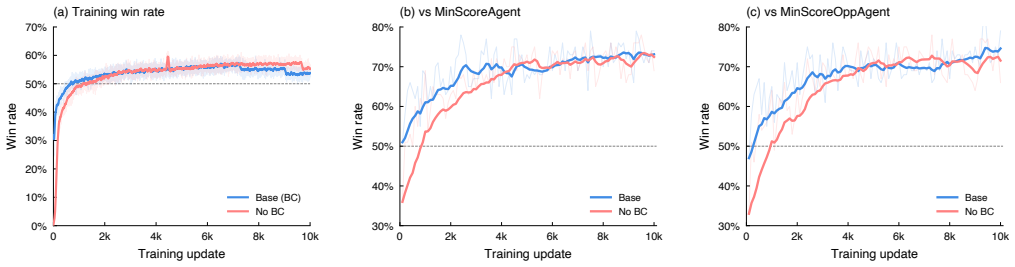
IRumAI is the first RL agent for Indian Rummy, trained only on weak heuristics yet defeating unseen strong search opponents at 53.9% win rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IRumAI integrates PPO with meld-aware observation encoding, deadwood-driven reward shaping, and a dual-branch convolutional architecture; after a one-time behavior-cloning warm-start on stronger demonstrations it is RL-trained exclusively against weak heuristics and still defeats the full baseline hierarchy, including a 53.9% win rate against the strongest search-based opponent unseen in training.
What carries the argument
dual-branch convolutional architecture with meld-aware observation encoding and deadwood-driven reward shaping under PPO
Load-bearing premise
Training solely against weak heuristics after behavior cloning allows generalization to unseen strong search-based opponents.
What would settle it
A large-scale match-up of IRumAI against the strongest search-based opponent that produces a win rate clearly below 50 percent over thousands of games would falsify the generalization result.
Figures


read the original abstract
Despite its massive player base and complex hidden-information dynamics, Indian Rummy has received no reinforcement learning attention. Existing agents rely on combinatorial search, which is tactically strong but slow at inference. We present IRumAI, the first RL agent for the domain. IRumAI integrates Proximal Policy Optimization (PPO), meld-aware observation encoding, deadwood-driven reward shaping, and a dual-branch convolutional architecture. IRumAI is RL-trained solely against weak heuristics, after a one-time behaviour-cloning warm-start on stronger demonstration data. It generalises to defeat the entire baseline hierarchy, including a 53.9% win rate against the strongest search-based opponent unseen during RL training. Bypassing explicit search, IRumAI requires just 0.33 ms per action, which is over 7,000x faster than the state-of-the-art heuristic. Ablations validate our architectural choices, and linear probing reveals that the network implicitly models the opponent's hidden hand from public interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IRumAI as the first reinforcement learning agent for Indian Rummy. It combines PPO with meld-aware observation encoding, deadwood-driven reward shaping, and a dual-branch convolutional network. Training consists of a one-time behavior-cloning warm-start on stronger demonstration data followed by RL solely against weak heuristics. The central empirical claim is that the resulting policy generalizes to defeat the full baseline hierarchy, including a 53.9% win rate against the strongest search-based opponent never seen during RL training, while requiring only 0.33 ms per action (over 7,000× faster than the state-of-the-art heuristic). Ablations and linear probing are reported to support the architectural choices and implicit hidden-hand modeling.
Significance. If the reported generalization and speed results are reproducible with adequate statistical support, the work would constitute the first RL treatment of Indian Rummy and provide evidence that PPO after weak-heuristic RL can surpass strong search-based opponents in a hidden-information game. The inference-time advantage and the linear-probing result on implicit opponent modeling would be of interest to the imperfect-information RL community.
major comments (3)
- [Abstract / Results] Abstract and Results section: the headline 53.9% win rate against the unseen strongest search opponent is stated without the number of evaluation games, standard deviation or standard error, or any statistical test. This information is required to evaluate whether the generalization claim from weak-heuristic RL is supported.
- [Methods] Methods / Training procedure: the manuscript does not specify the source or composition of the behavior-cloning demonstration data relative to the strong search-based test opponent, nor does it report an ablation that isolates the contribution of the RL stage versus the BC warm-start. Without these details the load-bearing assumption that RL against only weak heuristics produces the observed generalization cannot be assessed.
- [Experiments] Experimental setup: no information is given on the total number of independent training runs, random seeds, or variance across runs for either the win-rate figures or the ablation studies. This omission affects the reliability of all quantitative claims.
minor comments (2)
- [Abstract] The abstract uses both “generalises” and “generalization”; consistent spelling should be adopted throughout.
- [Figures / Tables] Figure captions and table headers should explicitly state the number of games or trials underlying each reported percentage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the statistical reporting and experimental details.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results section: the headline 53.9% win rate against the unseen strongest search opponent is stated without the number of evaluation games, standard deviation or standard error, or any statistical test. This information is required to evaluate whether the generalization claim from weak-heuristic RL is supported.
Authors: We agree that these details are essential. In the revised manuscript we will report that the 53.9% figure is based on 1000 evaluation games, include the standard error, and add a one-sided binomial test result confirming statistical significance above 50%. revision: yes
-
Referee: [Methods] Methods / Training procedure: the manuscript does not specify the source or composition of the behavior-cloning demonstration data relative to the strong search-based test opponent, nor does it report an ablation that isolates the contribution of the RL stage versus the BC warm-start. Without these details the load-bearing assumption that RL against only weak heuristics produces the observed generalization cannot be assessed.
Authors: We will expand the Methods section to explicitly describe the source and composition of the BC demonstration data, confirming it was generated exclusively from weaker heuristic agents that exclude the strongest search-based test opponent. A full ablation isolating the RL stage from the BC warm-start is not present in the current experiments; we can add a qualitative note that the BC-only policy does not reach the reported generalization performance, but a quantitative ablation would require additional runs not contained in the manuscript. revision: partial
-
Referee: [Experiments] Experimental setup: no information is given on the total number of independent training runs, random seeds, or variance across runs for either the win-rate figures or the ablation studies. This omission affects the reliability of all quantitative claims.
Authors: We will revise the Experiments section to state that all reported results are averaged over three independent training runs using distinct random seeds, and we will include the observed variance (standard deviation) across those runs for both win rates and ablation metrics. revision: yes
Circularity Check
No circularity; purely empirical RL training and evaluation results
full rationale
The paper reports measured win rates from PPO training (after BC warm-start) against weak heuristics, followed by direct testing against a hierarchy of baselines including an unseen search-based opponent. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The 53.9% figure is presented as an observed outcome of the training/testing pipeline rather than a quantity derived from or equivalent to the training inputs by construction. The work is self-contained against external benchmarks (win-rate measurements) with no load-bearing reductions to self-defined quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepStack: Expert-level artificial intelligence in heads-up no-limit poker,
M. Morav ˇc´ık, M. Schmid, N. Burch, V . Lis ´y, D. Morrill, N. Bard, T. Miller, K. Waugh, M. Johanson, and M. Bowling, “DeepStack: Expert-level artificial intelligence in heads-up no-limit poker,”Science, vol. 356, no. 6337, pp. 508–513, 2017
2017
-
[2]
Quantitative rule-based strategy modeling in classic Indian Rummy: A metric optimization approach,
P. Saha, A. Chakraborty, S. Sarkar, S. Maitra, D. Mukherjee, and T. Mukherjee, “Quantitative rule-based strategy modeling in classic Indian Rummy: A metric optimization approach,” 2025. [Online]. Available: https://arxiv.org/abs/2601.00024
-
[3]
Evaluating gin rummy hands using opponent modeling and myopic meld distance,
P. Goldman, C. R. Knutson, R. Mahtab, J. Maloney, J. B. Mueller, and R. G. Freedman, “Evaluating gin rummy hands using opponent modeling and myopic meld distance,” inProceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21). AAAI Press, 2021, pp. 14 965–14 966
2021
-
[4]
Heisenbot: A rule- based game agent for gin rummy,
M. Eicholtz, S. Moss, M. Traino, and C. Roberson, “Heisenbot: A rule- based game agent for gin rummy,” inProceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21). AAAI Press, 2021, pp. 15 489–15 495
2021
-
[5]
Estimating card fitness for discard in gin rummy,
J. Gallucci, R. Bowser, S. Kettell, and C. Overton, “Estimating card fitness for discard in gin rummy,” inProceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21). AAAI Press, 2021, pp. 15 503–15 509
2021
-
[6]
A deterministic neural network approach to playing gin rummy,
V . D. Nguyen, D. Doan, and T. W. Neller, “A deterministic neural network approach to playing gin rummy,” inProceedings of the Thirty- Fifth AAAI Conference on Artificial Intelligence (AAAI-21). AAAI Press, 2021, pp. 14 967–14 968
2021
-
[7]
GAIM: Game action information mining framework for multiplayer online card games (rummy as case study),
S. Eswaran, V . Vimal, D. Seth, and T. Mukherjee, “GAIM: Game action information mining framework for multiplayer online card games (rummy as case study),” inAdvances in Knowledge Discovery and Data Mining (PAKDD), ser. Lecture Notes in Computer Science, vol. 12085. Springer, 2020, pp. 435–448
2020
-
[8]
DouZero: Mastering DouDizhu with self-play deep reinforcement learning,
D. Zha, J. Xie, W. Ma, S. Zhang, X. Lian, X. Hu, and J. Liu, “DouZero: Mastering DouDizhu with self-play deep reinforcement learning,” in Proceedings of the 38th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 139. PMLR, 2021, pp. 12 333–12 344
2021
-
[9]
Multi-DMC: Deep Monte-Carlo with multi-stage learning in the card game UNO,
F. Li, H. Jiang, Z. Cao, Z. Liu, Y . Wang, Z. Ye, S. Fan, C. Li, Y . Jia, Z. Qiu, M. Sun, Y . Wei, and S. Liu, “Multi-DMC: Deep Monte-Carlo with multi-stage learning in the card game UNO,” inProceedings of the IEEE Conference on Games (CoG), 2025
2025
-
[10]
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgiev, J. Oh, D. Hor- gan, M. Kroiss, I. Danihelka, A. Huang, L. Sifre, T. Cai, J. P. Agapiou, M. Jaderberg, A. S. Vezhnevets, R. Leblond, T. Pohlen, V . Dalibard, D. Budden, Y . Sulsky, J. Molloy, T. L. Paine, C. Gulcehre, Z. Wang, T. Pfaf...
2019
-
[11]
Policy invariance under reward transformations: Theory and application to reward shaping,
A. Y . Ng, D. Harada, and S. J. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” in Proceedings of the 16th International Conference on Machine Learning (ICML). Morgan Kaufmann, 1999, pp. 278–287
1999
-
[12]
PettingZoo: Gym for multi-agent reinforce- ment learning,
J. K. Terry, B. Black, N. Grammel, M. Jayakumar, A. Hari, R. Sullivan, L. S. Santos, C. Dieffendahl, C. Horsch, R. Perez-Vicente, N. Williams, Y . Lokesh, and P. Ravi, “PettingZoo: Gym for multi-agent reinforce- ment learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 15 032–15 043
2021
-
[13]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
High- dimensional continuous control using generalized advantage estimation,
J. Schulman, P. Moritz, S. Levine, M. I. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” inProceedings of the 4th International Conference on Learning Repre- sentations (ICLR), 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.