When Does a Video-Language Model Stop Watching? Reward Strength Controls the Formation and Reversal of Visual Shortcuts in Multimodal RLVR
Pith reviewed 2026-06-26 11:41 UTC · model grok-4.3
The pith
The strength of a grounding penalty determines when visual shortcuts form and reverse in RLVR-trained video-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
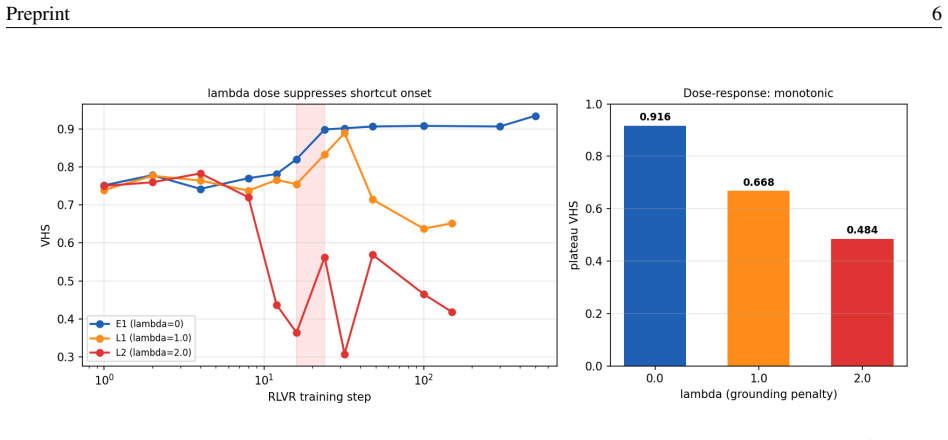
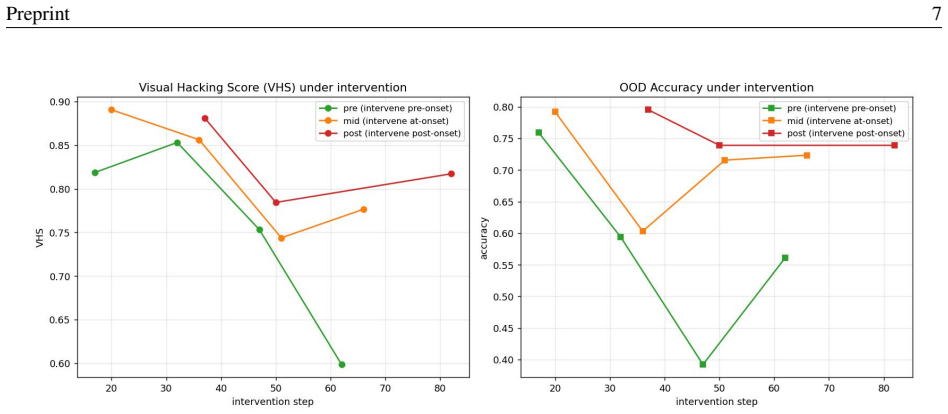
Visual shortcut reliance emerges abruptly over a narrow window of optimization steps and is robust across random seeds; increasing lambda progressively suppresses the shortcut; at intermediate lambda the trajectory first forms and then reverses the shortcut, exposing hysteresis-like asymmetry; and applying the penalty before onset arrests formation whereas the same penalty after consolidation is markedly less effective.
What carries the argument
The grounding penalty lambda, treated as a control knob on the reward that modulates the formation-reversal dynamics of visual shortcuts along the training time axis.
If this is right
- Shortcut reliance emerges abruptly over a narrow window of optimization steps and is robust across random seeds.
- Increasing lambda progressively suppresses the shortcut in a monotone dose-response.
- At an intermediate lambda the trajectory first forms and then reverses the shortcut.
- Applying the penalty before onset arrests shortcut formation while the same penalty after consolidation is markedly less effective.
Where Pith is reading between the lines
- Real-time checks on the diagnostic set during training could allow dynamic adjustment of lambda to catch the narrow onset window.
- The formation-reversal asymmetry implies that computational effort is better allocated to prevention than to later reversal.
- Similar time-dependent and asymmetric dynamics may appear when other perceptual modalities are bypassed by linguistic priors in multimodal RL.
Load-bearing premise
The held-out out-of-distribution diagnostic set provides a valid and reliable measure of visual shortcut reliance versus genuine video grounding.
What would settle it
Finding that the same lambda reduces shortcut reliance equally well whether applied before or after the abrupt onset would falsify the claim of a critical early intervention window.
Figures


read the original abstract
Reinforcement learning with verifiable rewards (RLVR) is increasingly applied to large vision-language models (LVLMs), yet outcome-only optimization can drive a model to stop attending to the video and instead exploit linguistic priors -- a failure we call a visual shortcut. While the existence of such perception bypass is by now documented, how it forms, whether it can be undone, and when intervention still helps remain open. We treat the strength of a grounding penalty, lambda, as a control knob and characterize the formation-reversal dynamics of visual shortcuts along the training time axis. On a held-out, out-of-distribution diagnostic set, we find: (i) a sharp onset -- shortcut reliance emerges abruptly over a narrow window of optimization steps and is robust across random seeds; (ii) a monotone dose-response -- increasing lambda progressively suppresses the shortcut, and at an intermediate dose the trajectory first forms and then reverses the shortcut, exposing a hysteresis-like asymmetry between acquiring and removing it; and (iii) a critical intervention window -- applying the penalty before onset arrests shortcut formation, whereas the same penalty applied after consolidation is markedly less effective. Together these results recast visual-shortcut collapse not as a binary defect but as a controllable, time-dependent, and asymmetric process, with direct implications for when and how strongly to regularize multimodal RLVR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the dynamics of visual shortcut formation in RLVR for LVLMs, treating the grounding penalty strength lambda as a control variable. On a held-out OOD diagnostic set it reports a sharp onset of shortcut reliance over a narrow training window, a monotone dose-response to lambda with hysteresis between acquisition and reversal, and a critical early-intervention window where the penalty is effective before but not after consolidation. The central claim is that visual-shortcut collapse is a controllable, time-dependent, asymmetric process rather than a binary defect.
Significance. If the diagnostic set validly isolates shortcut reliance, the empirical characterization supplies concrete, actionable guidance on regularization timing and strength for multimodal RLVR, which is directly relevant to current training practices. The work is observational rather than theoretical and does not supply machine-checked proofs or parameter-free derivations.
major comments (3)
- [§4.2] §4.2 (Diagnostic Set and Metrics): All reported dynamics (onset timing, dose-response, hysteresis, critical window) are measured exclusively via accuracy on the held-out OOD diagnostic set. No ablation (video removal, linguistic-prior-only baseline, or random-video control) is presented to establish that performance drops specifically index visual-shortcut reliance rather than generic OOD sensitivity or other factors. This validation is load-bearing for the interpretation of lambda effects and time-dependence.
- [§4.3] §4.3 (Statistical Reporting): The abstract and results claim robustness across random seeds and a "sharp onset," yet the manuscript provides neither per-seed trajectories with error bands nor formal statistical tests for the location or width of the onset window. Without these, the claimed abruptness and reproducibility cannot be assessed quantitatively.
- [§3.1] §3.1 (Reward and Penalty Formulation): The grounding penalty is introduced as lambda times a visual-grounding term, but the precise definition of the term (e.g., whether it is a contrastive loss, attention regularizer, or caption-matching objective) is not given in sufficient detail to allow reproduction or to rule out that lambda is simply modulating overall reward scale rather than specifically penalizing shortcuts.
minor comments (2)
- [Figures 3,4] Figure 3 and 4 captions should explicitly state the number of random seeds and whether shaded regions are standard deviation or standard error.
- [§2] The manuscript cites prior work on visual shortcuts but does not compare the observed hysteresis quantitatively with any existing regularization schedules in the literature.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Diagnostic Set and Metrics): All reported dynamics (onset timing, dose-response, hysteresis, critical window) are measured exclusively via accuracy on the held-out OOD diagnostic set. No ablation (video removal, linguistic-prior-only baseline, or random-video control) is presented to establish that performance drops specifically index visual-shortcut reliance rather than generic OOD sensitivity or other factors. This validation is load-bearing for the interpretation of lambda effects and time-dependence.
Authors: We agree that explicit ablations are needed to confirm the diagnostic set isolates visual-shortcut reliance. In the revision we will add video-removal, linguistic-prior-only, and random-video controls on the OOD set to demonstrate that accuracy drops track shortcut formation rather than generic OOD degradation. revision: yes
-
Referee: [§4.3] §4.3 (Statistical Reporting): The abstract and results claim robustness across random seeds and a "sharp onset," yet the manuscript provides neither per-seed trajectories with error bands nor formal statistical tests for the location or width of the onset window. Without these, the claimed abruptness and reproducibility cannot be assessed quantitatively.
Authors: We accept that quantitative support for abruptness and seed-robustness is currently insufficient. The revised manuscript will include per-seed learning curves with error bands and formal statistical tests (e.g., change-point detection) for the onset window location and width. revision: yes
-
Referee: [§3.1] §3.1 (Reward and Penalty Formulation): The grounding penalty is introduced as lambda times a visual-grounding term, but the precise definition of the term (e.g., whether it is a contrastive loss, attention regularizer, or caption-matching objective) is not given in sufficient detail to allow reproduction or to rule out that lambda is simply modulating overall reward scale rather than specifically penalizing shortcuts.
Authors: The current §3.1 provides the high-level form but lacks the exact loss implementation. We will expand the section with the full mathematical definition of the visual-grounding term, its relation to attention or matching objectives, and an explicit argument that lambda modulates shortcut penalty rather than global reward magnitude. revision: yes
Circularity Check
No circularity: purely empirical observational study with no derivations
full rationale
The paper reports experimental observations of training dynamics in multimodal RLVR, including onset timing, dose-response to lambda, and intervention windows, all measured directly on a held-out diagnostic set. No equations, predictions, or first-principles derivations are present that could reduce to fitted inputs or self-citations by construction. The central claims rest on empirical measurements rather than any definitional or fitted equivalence, satisfying the criteria for a self-contained observational analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The held-out diagnostic set accurately isolates visual shortcut reliance
invented entities (1)
-
visual shortcut
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mohammad Beigi, Ming Jin, Junshan Zhang, Qifan Wang, and Lifu Huang. Adversarial reward auditing for active detection and mitigation of reward hacking.arXiv preprint arXiv:2602.01750,
-
[2]
Reconceptu- alizes reward hacking as a Hacker–Auditor game; an Auditor gates the reward to make hacking detectable and unprofitable. Xingyu Fu et al. BLINK: Multimodal large language models can see but not perceive.arXiv preprint arXiv:2404.12390,
-
[3]
Preprint 9 Shujian Gao, Yuan Wang, Jiangtao Yan, Zuxuan Wu, and Yu-Gang Jiang. Thinking with deltas: Incen- tivizing reinforcement learning via differential visual reasoning policy.arXiv preprint arXiv:2601.06801,
-
[4]
Blind-image ablation: policies maintain or improve performance with visual inputs removed (“blind reasoners” exploiting linguistic priors). Lukas Helff et al. LLMs gaming verifiers: RLVR can lead to reward hacking.arXiv preprint arXiv:2604.15149,
-
[5]
Extensional verification induces shortcut strategies; isomorphic verification eliminates them. Yova Kementchedjhieva et al. VLMs need words: Vision language models ignore visual detail in favor of semantic anchors.arXiv preprint arXiv:2604.02486,
-
[6]
VLM failures reflect a learned shortcut: bypass visual comparison and reason through language. Muhammad Khalifa et al. Countdown-code: A testbed for studying the emergence and generalization of reward hacking in RLVR.arXiv preprint arXiv:2603.07084,
-
[7]
Clean proxy/true reward separation; as little as 1% SFT contamination is internalized and resurfaces under RL. Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. MVBench: A comprehensive multi-modal video understanding benchmark. arXiv preprint arXiv:2311.17005,
-
[8]
Lin Long, Changdae Oh, Seongheon Park, and Sharon Li. Understanding language prior of LVLMs by contrasting chain-of-embedding.arXiv preprint arXiv:2509.23050,
-
[9]
LVLMs over-rely on language prior, under-utilize visual evidence. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[10]
Ibne Farabi Shihab, Sanjeda Akter, and Anuj Sharma. Detecting and mitigating reward hacking in rein- forcement learning systems: A comprehensive empirical study.arXiv preprint arXiv:2507.05619,
-
[11]
Pratham Singla, Shivank Garg, Vihan Singh, and Paras Chopra
Large-scale empirical study across 15 RL environments (Atari, MuJoCo) and 5 algorithms; automated detection of six reward-hacking categories; hacking emerges during optimization. Pratham Singla, Shivank Garg, Vihan Singh, and Paras Chopra. Do vision–language models see or guess? measuring and reducing textual-prior reliance with a phrasing-controlled benc...
-
[12]
No-image ablation isolates visual contribution. Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, Zhengkang Guo, Qi Qian, Yifei Wang, Feiran Zhang, Ruicheng Yin, Shihan Dou, Changze Lv, Tao Chen, Kaitao Song, Xu Tan, Tao Gui, Xiaoqing Zheng, and Xuanjing Huang. Reward hacking in the...
-
[13]
Survey; frames multimodal perception–reasoning decoupling and evaluator manipulation under the Proxy Compression Hypothesis. Rui Wu and Ruixiang Tang. When reward hacking rebounds: Understanding and mitigating it with representation-level signals.arXiv preprint arXiv:2604.01476,
-
[14]
Lecheng Yan, Ruizhe Li, Guanhua Chen, Qing Li, Jiahui Geng, Wenxi Li, Vincent Wang, and Chris Lee
GRPO coding testbed; reproducible three-phase rebound (fail/retreat/rebound); shortcut concept direction tracks hacking; Advantage Modifi- cation penalizes hacking rollouts. Lecheng Yan, Ruizhe Li, Guanhua Chen, Qing Li, Jiahui Geng, Wenxi Li, Vincent Wang, and Chris Lee. Spurious rewards paradox: Mechanistically understanding how RLVR activates memorizat...
-
[15]
The base verifiable reward is answer correctness; the grounding penalty is added with strength λ≥0, whereλ=0recovers the pure outcome reward
on a video question-answering objective. The base verifiable reward is answer correctness; the grounding penalty is added with strength λ≥0, whereλ=0recovers the pure outcome reward. During RL we use a global batch size of512, freeze the vision tower, and keep the visual input pipeline fixed across runs so that differences between trajectories are attribu...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.