CodeTeam: An LLM-Powered Multi-Agent Framework for Repository-Level Code Generation
Pith reviewed 2026-06-26 11:35 UTC · model grok-4.3
The pith
A multi-agent LLM framework divides repository code generation into distinct planning, selection, and implementation stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CodeTeam is an LLM-based multi-agent framework that separates planning, decision making, and implementation into distinct, coordinated stages. In the planning stage, multiple Architect agents draft competing software design sketches optionally grounded by retrieved design references. A CTO agent evaluates, selects, and normalizes the most promising sketch into a machine-checkable contract that specifies file ownership, public interfaces, and dependency constraints. In the implementation stage, Developer agents generate code under a dependency-aware scheduler with bounded context and lightweight Git-based coordination, while a QA agent runs tests and drives iterative repairs. On SketchEval th
What carries the argument
The multi-agent coordination structure that assigns Architect agents to draft software design sketches, a CTO agent to produce a machine-checkable contract, Developer agents to implement under a dependency-aware scheduler, and a QA agent to perform test-driven repairs.
If this is right
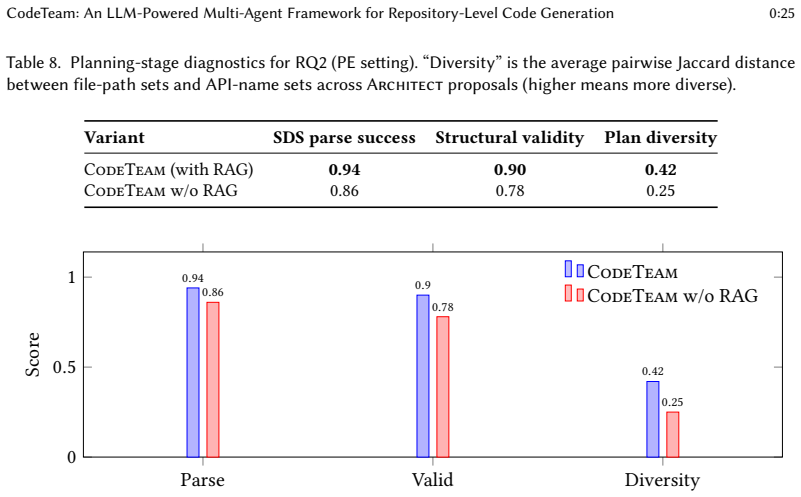
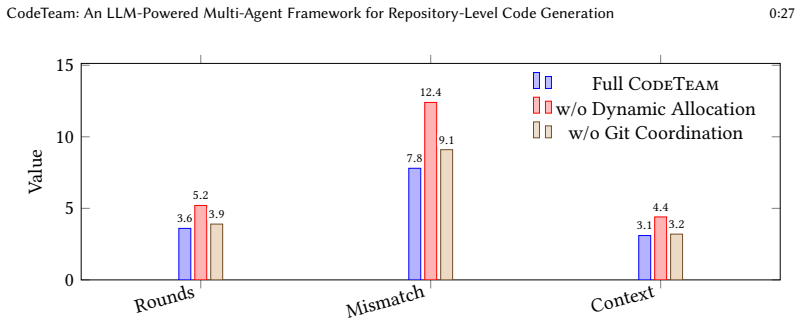
- Project-specific developer allocation contributes 9.9 percent relative improvement to SketchBLEU.
- Retrieval-augmented planning contributes 8.1 percent relative improvement to SketchBLEU.
- Sketch-level improvements translate directly to higher functional correctness on execution-based test suites.
- The staged coordination reduces cross-file inconsistencies during iterative debugging.
Where Pith is reading between the lines
- The pattern of competing design sketches followed by contract normalization could apply to other multi-component generation tasks that need consistency guarantees.
- Lightweight Git-based coordination between agents may scale to larger repositories if the contract remains stable.
- If the QA-driven repair loop generalizes, similar agent separation might reduce error accumulation in long-horizon planning problems outside code generation.
Load-bearing premise
The reported gains come from the multi-agent roles and coordination mechanisms rather than from differences in the base LLM or prompt details relative to the CodeS baselines.
What would settle it
Re-running the CodeS baselines with identical base models, prompts, and implementation details as CodeTeam and finding no performance difference on SketchEval or NL2Repo-Bench.
Figures

read the original abstract
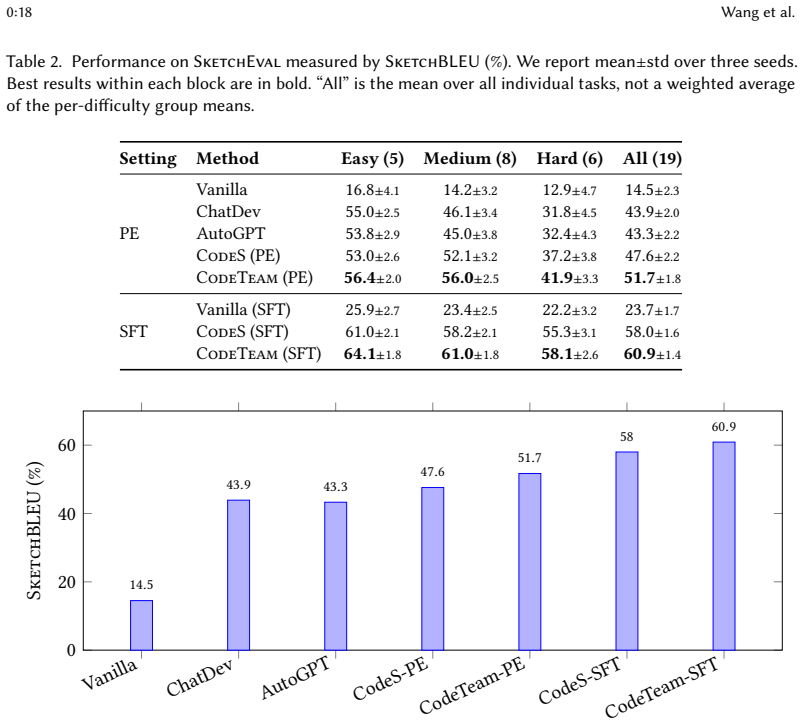
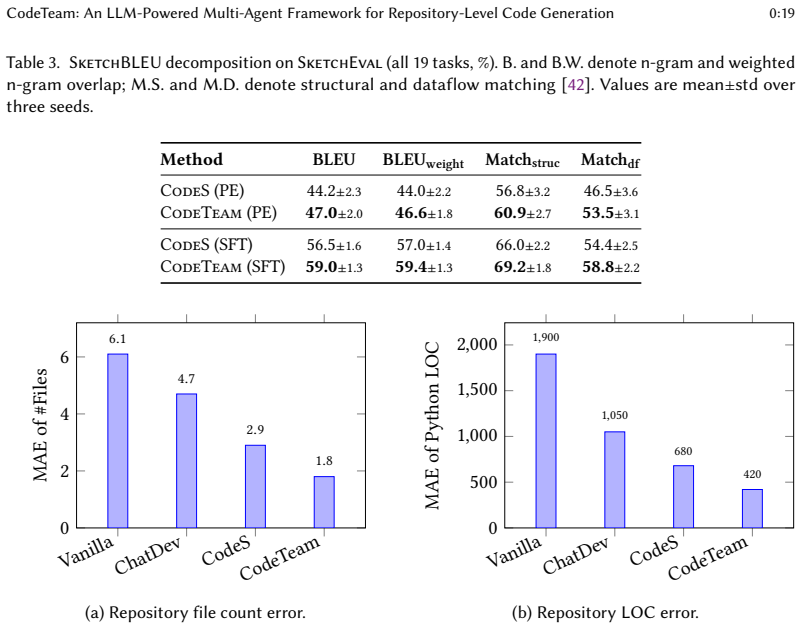
Natural language to repository generation (NL2Repo) requires a system to construct an entire software repository from a natural-language requirements document. Compared with function-level code generation, this task demands longer planning horizons, stable interfaces across files, and iterative debugging of cross-file inconsistencies. To address these challenges, we propose CodeTeam, an LLM-based multi-agent framework that separates planning, decision making, and implementation into distinct, coordinated stages. In the planning stage, multiple Architect agents draft competing software design sketches (SDS), optionally grounded by retrieved design references. A CTO agent then evaluates, selects, and normalizes the most promising SDS into a machine-checkable contract that specifies file ownership, public interfaces, and dependency constraints. In the implementation stage, Developer agents generate code under a dependency-aware scheduler with bounded context and lightweight Git-based coordination, while a QA agent runs tests and drives iterative repairs. On the synthesis-based SketchEval benchmark, we explicitly compare CodeTeam's prompt-engineering (PE) and supervised fine-tuning (SFT) variants with the corresponding CodeS variants, where CodeTeam improves the overall SketchBLEU by 4.1 and 2.9 absolute points, respectively. On the execution-based NL2Repo-Bench benchmark, used as an external validation protocol, CodeTeam achieves the highest average test pass rate in both settings (34.6% PE, 42.3% SFT), confirming that the sketch-improvements extend to functional correctness under upstream test suites. Ablation results show that project-specific developer allocation and retrieval-augmented planning each contribute substantially to the SketchBLEU improvement (9.9% and 8.1% relative, respectively). CodeTeam and the experimental results are available at https://github.com/WhitenWhiten/CodeTeam
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CodeTeam, an LLM-based multi-agent framework for natural language to repository-level code generation (NL2Repo). It divides the task into a planning stage (multiple competing Architect agents producing Software Design Sketches optionally augmented by retrieval, followed by a CTO agent that selects and normalizes the best sketch into a machine-checkable contract specifying file ownership, interfaces, and dependencies) and an implementation stage (Developer agents generating code under a dependency-aware scheduler with Git coordination, plus a QA agent performing test-driven iterative repairs). On the SketchEval benchmark the PE and SFT variants are reported to improve overall SketchBLEU by 4.1 and 2.9 absolute points over corresponding CodeS variants; on the external NL2Repo-Bench they achieve the highest average test pass rates (34.6 % PE, 42.3 % SFT). Ablations attribute 9.9 % and 8.1 % relative SketchBLEU gains to project-specific developer allocation and retrieval-augmented planning, respectively. Code and results are released.
Significance. If the numerical gains can be shown to arise from the multi-agent coordination mechanisms rather than unmatched base models, prompts, or implementation details, the work would provide concrete evidence that structured agent分工 (competing architects, contract normalization, dependency scheduling, Git coordination, QA loop) improves long-horizon repository generation over single-agent or simpler baselines. The explicit PE/SFT comparison protocol and public release of code strengthen the empirical contribution.
major comments (2)
- [Abstract] Abstract: the headline claim that CodeTeam improves SketchBLEU by 4.1/2.9 points and reaches the highest NL2Repo-Bench pass rates (34.6 %/42.3 %) over 'corresponding CodeS variants' in both PE and SFT regimes is load-bearing for the central thesis, yet the manuscript supplies no evidence that the CodeS baselines used identical base LLMs, temperature, retrieval setup, or fine-tuning corpus; without such controls the deltas cannot be attributed to the multi-agent pipeline (competing Architects, CTO contract, dependency scheduler, Git coordination, QA loop).
- [Abstract] Abstract (ablations paragraph): the reported 9.9 % and 8.1 % relative contributions from 'project-specific developer allocation' and 'retrieval-augmented planning' are presented as supporting the architectural mechanisms, but the same baseline-equivalence issue applies; the ablations must be shown to hold the base LLM and prompt engineering fixed.
minor comments (2)
- [Abstract] The abstract states that results are available at a GitHub link; the manuscript should also include a brief description of the exact models, temperatures, and retrieval corpora used for both CodeTeam and CodeS variants so that readers can verify equivalence without external inspection.
- [Abstract] Notation: 'Software Design Sketch (SDS)' and 'CTO agent' are introduced without prior definition in the abstract; a short parenthetical gloss on first use would improve readability.
Simulated Author's Rebuttal
Thank you for your detailed and constructive review. We appreciate the focus on ensuring that performance gains can be attributed to the proposed multi-agent mechanisms. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that CodeTeam improves SketchBLEU by 4.1/2.9 points and reaches the highest NL2Repo-Bench pass rates (34.6 %/42.3 %) over 'corresponding CodeS variants' in both PE and SFT regimes is load-bearing for the central thesis, yet the manuscript supplies no evidence that the CodeS baselines used identical base LLMs, temperature, retrieval setup, or fine-tuning corpus; without such controls the deltas cannot be attributed to the multi-agent pipeline (competing Architects, CTO contract, dependency scheduler, Git coordination, QA loop).
Authors: We agree that baseline equivalence is essential for attributing gains to the multi-agent design. The CodeS variants were implemented using identical base LLMs, temperature (0.7), retrieval setup, and fine-tuning corpus as the corresponding CodeTeam variants; this matching protocol is described in Section 4 (Experimental Setup) of the full manuscript. To address the concern directly in the abstract, we will revise the abstract to briefly note the matched conditions. revision: yes
-
Referee: [Abstract] Abstract (ablations paragraph): the reported 9.9 % and 8.1 % relative contributions from 'project-specific developer allocation' and 'retrieval-augmented planning' are presented as supporting the architectural mechanisms, but the same baseline-equivalence issue applies; the ablations must be shown to hold the base LLM and prompt engineering fixed.
Authors: The ablations isolate the contributions of project-specific developer allocation and retrieval-augmented planning by removing or modifying only those components while holding the base LLM, temperature, prompt templates, and retrieval configuration fixed. This design ensures the reported relative gains are due to the ablated mechanisms. We will revise the abstract to explicitly state that the ablations maintain fixed base model and prompt settings. revision: yes
Circularity Check
No circularity: empirical benchmark comparisons only
full rationale
The paper reports measured improvements on SketchEval (SketchBLEU deltas) and NL2Repo-Bench (pass rates) plus ablation percentages. No equations, fitted parameters, predictions, or first-principles derivations exist that could reduce to inputs by construction. Comparisons to CodeS variants and ablations are presented as external evidence; no self-citation chain or self-definitional step carries the central claim. This is standard empirical SE work with independent benchmark grounding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can reliably perform specialized software engineering roles (architect, CTO, developer, QA) when given structured prompts and contracts.
- domain assumption The SketchEval and NL2Repo-Bench benchmarks are appropriate proxies for real repository-level generation tasks.
invented entities (2)
-
Software Design Sketch (SDS)
no independent evidence
-
CTO agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Barry Boehm and Victor R. Basili. 2001. Software Defect Reduction Top 10 List.IEEE Computer34, 1 (2001), 135–137
2001
-
[2]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3-Embedding: Multi- Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation.arXiv preprint arXiv:2402.03216(2024)
Pith/arXiv arXiv 2024
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating Large Language Models Trained on Code.arXiv preprint arXiv:2107.03374(2021)
Pith/arXiv arXiv 2021
-
[4]
Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2024. Teaching Large Language Models to Self-Debug. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net, 1–23. ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. 0:34 Wang et al
2024
-
[5]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. 2024. LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net, 1–19
2024
-
[6]
Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.arXiv preprint arXiv:2307.08691(2023)
Pith/arXiv arXiv 2023
-
[7]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized LLMs. InProceedings of the 37th Annual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS Proceedings, 10088–10115
2023
-
[8]
Jingzhe Ding, Shengda Long, Changxin Pu, Huan Zhou, Hongwan Gao, Xiang Gao, Chao He, Yue Hou, Fei Hu, Zhaojian Li, Weiran Shi, Zaiyuan Wang, Daoguang Zan, Chenchen Zhang, Xiaoxu Zhang, Qizhi Chen, Xianfu Cheng, Bo Deng, Qingshui Gu, Kai Hua, Juntao Lin, Pai Liu, Mingchen Li, Xuanguang Pan, Zifan Peng, Yujia Qin, Yong Shan, Zhewen Tan, Weihao Xie, Zihan Wa...
arXiv 2025
-
[9]
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. 2023. CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion. InProceedings of the 37th Annual Conference on Neural Information Processing Systems (NeurIPS). NeurI...
2023
-
[10]
Matthijs Douze, Anton Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss Library.arXiv preprint arXiv:2401.08281(2024)
Pith/arXiv arXiv 2024
-
[11]
Bradley Efron. 1979. Bootstrap Methods: Another Look at the Jackknife.Annals of Statistics7, 1 (1979), 1–26
1979
-
[12]
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. 2022. InCoder: A Generative Model for Code Infilling and Synthesis.arXiv preprint arXiv:2204.05999(2022)
Pith/arXiv arXiv 2022
-
[13]
Significant Gravitas. 2023. AutoGPT. https://github.com/Significant-Gravitas/AutoGPT
2023
-
[14]
Hall and Ken Kennedy
Mary W. Hall and Ken Kennedy. 1992. Efficient Call Graph Analysis.ACM Letters on Programming Languages and Systems1, 3 (1992), 227–242
1992
-
[15]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. 2021. Measuring Coding Challenge Competence With APPS.arXiv preprint arXiv:2105.09938(2021)
Pith/arXiv arXiv 2021
-
[16]
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. InProceedings of the 12th International Conference on Learning Repre...
2024
-
[17]
Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez
Md. Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2024. MapCoder: Multi-Agent Code Generation for Competitive Problem Solving. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 4917–4942
2024
-
[18]
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2018. Mapping Language to Code in Program- matic Context. InProceedings of the 23rd Conference on Empirical Methods in Natural Language Processing (EMNLP). ACL, 1643–1652
2018
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE- bench: Can Language Models Resolve Real-World GitHub Issues?. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net, 1–51
2024
-
[20]
Syed Mohammad Kashif, Ruiyin Li, Peng Liang, Amjed Tahir, Qiong Feng, Zengyang Li, and Mojtaba Shahin. 2026. Beyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects.arXiv preprint arXiv:2604.06373 (2026)
Pith/arXiv arXiv 2026
-
[21]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.arXiv preprint arXiv:2005.11401(2020)
Pith/arXiv arXiv 2020
-
[22]
Wei Li, Xin Zhang, Zhongxin Guo, Shaoguang Mao, Wen Luo, Guangyue Peng, Yangyu Huang, Houfeng Wang, and Scarlett Li. 2025. FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 17160–17176
2025
-
[23]
Tianyang Liu, Canwen Xu, and Julian McAuley. 2024. RepoBench: Benchmarking Repository-Level Code Auto- Completion Systems. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenRe- view.net, 1–19. ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. CodeTeam: An LLM-Powered Multi-Agent Fr...
2024
-
[24]
Wei Liu, Ailun Yu, Daoguang Zan, Bo Shen, Wei Zhang, Haiyan Zhao, Zhi Jin, and Qianxiang Wang. 2024. GraphCoder: Enhancing Repository-Level Code Completion via Code Context Graph-based Retrieval and Language Model.arXiv preprint arXiv:2406.07003(2024)
arXiv 2024
-
[25]
Yu. A. Malkov and D. A. Yashunin. 2016. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.arXiv preprint arXiv:1603.09320(2016)
Pith/arXiv arXiv 2016
-
[26]
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong
-
[27]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis.arXiv preprint arXiv:2203.13474(2022)
Pith/arXiv arXiv 2022
-
[28]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 311–318
2002
-
[29]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 15174–15186
2024
-
[30]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.arXiv preprint arXiv:1910.02054(2020)
Pith/arXiv arXiv 2020
-
[31]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a Method for Automatic Evaluation of Code Synthesis.arXiv preprint arXiv:2009.10297 (2020)
Pith/arXiv arXiv 2020
-
[32]
Tal Ridnik, Dedy Kredo, and Itamar Friedman. 2024. Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering.arXiv preprint arXiv:2401.08500(2024)
arXiv 2024
-
[33]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. InProceedings of the 37th Annual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS Proceedings, 8634–8652
2023
-
[34]
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. 2024. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115(2024)
Pith/arXiv arXiv 2024
-
[35]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
2025
-
[36]
Yifei Wang, Ruiyin Li, Peng Liang, Qiong Feng, Zengyang Li, Mojtaba Shahin, and Arif Ali Khan. 2026. Replication Package for the Paper: CodeTeam: An LLM-Powered Multi-Agent Framework for Repository-Level Code Generation. https://github.com/WhitenWhiten/CodeTeam
2026
-
[37]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. InProceedings of the 26th Conference on Empirical Methods in Natural Language Processing (EMNLP). ACL, 8696–8708
2021
-
[38]
Frank Wilcoxon. 1945. Individual Comparisons by Ranking Methods.Biometrics Bulletin1, 6 (1945), 80–83
1945
-
[39]
Ohlsson, Björn Regnell, and Anders Wesslén
Claes Wohlin, Per Runeson, Martin Höst, Magnus C. Ohlsson, Björn Regnell, and Anders Wesslén. 2012.Experimentation in Software Engineering. Springer
2012
-
[40]
Hui Yang, Sifu Yue, and Yunzhong He. 2023. Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions.arXiv preprint arXiv:2306.02224(2023)
arXiv 2023
-
[41]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InProceedings of the 38th Annual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS Proceedings, 50528–50652
2024
-
[42]
Pengcheng Yin, Bowen Deng, Edgar Chen, Bogdan Vasilescu, and Graham Neubig. 2018. Learning to Mine Aligned Code and Natural Language Pairs from Stack Overflow. InProceedings of the 15th International Conference on Mining Software Repositories (MSR). ACM, 476–486
2018
-
[43]
Daoguang Zan, Ailun Yu, Wei Liu, Dong Chen, Bo Shen, Yafen Yao, Wei Li, Xiaolin Chen, Yongshun Gong, Bei Guan, Zhiguang Yang, Yongji Wang, Lizhen Cui, and Qianxiang Wang. 2025. CodeS: Natural Language to Code Repository via Multi-Layer Sketch.ACM Transactions on Software Engineering and Methodology(2025)
2025
-
[44]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen
-
[45]
InProceedings of the 28th Conference on Empirical Methods in Natural Language Processing (EMNLP)
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 28th Conference on Empirical Methods in Natural Language Processing (EMNLP). ACL, 2471–2484
-
[46]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. 2024. CodeAgent: Enhancing Code Generation with Tool-Integrated Agent Systems for Real-World Repo-level Coding Challenges. InProceedings of the 62nd Annual Meeting of the Association ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. 0:36 Wang et al. for Computational L...
2024
-
[47]
Qianhui Zhao, Li Zhang, Fang Liu, Junhang Cheng, Chengru Wu, Junchen Ai, Qiaoyuanhe Meng, Lichen Zhang, Xiaoli Lian, Shubin Song, and Yuanping Guo. 2025. Towards Realistic Project-Level Code Generation via Multi-Agent Collaboration and Semantic Architecture Modeling.arXiv preprint arXiv:2511.03404(2025)
arXiv 2025
-
[48]
Xu, Zhiruo Wang, Zhengbao Jiang, and Graham Neubig
Shuyan Zhou, Uri Alon, Frank F. Xu, Zhiruo Wang, Zhengbao Jiang, and Graham Neubig. 2023. DocPrompting: Generating Code by Retrieving the Docs. InProceedings of the 11th International Conference on Learning Representations (ICLR). OpenReview.net, 1–16. ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.