RigorBench: Benchmarking Engineering Process Discipline in Autonomous AI Coding Agents
Pith reviewed 2026-07-01 07:08 UTC · model grok-4.3
The pith
AI coding agents that follow structured engineering processes achieve 41% better process quality and 17% higher outcome correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
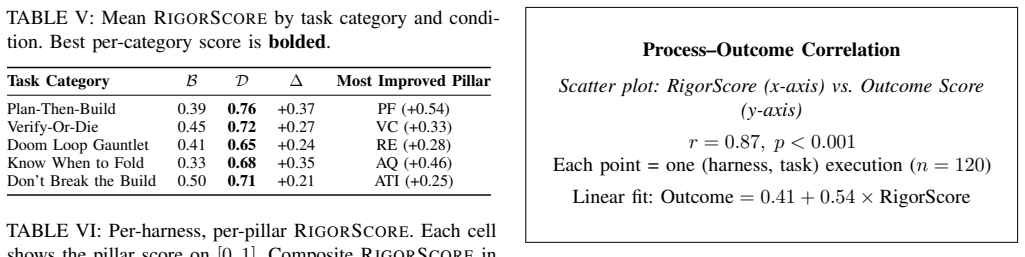
RigorBench measures engineering process discipline in AI coding agents through the five pillars of Planning Fidelity, Verification Coverage, Recovery Efficiency, Abstention Quality, and Atomic Transition Integrity; a weighted RigorScore aggregates them, and controlled experiments on 30 tasks demonstrate that harnesses enforcing these pillars raise both process scores by 41 percent and downstream correctness by 17 percent compared with baseline agents.
What carries the argument
RigorScore, the weighted sum across the five pillars that quantifies adherence to engineering process discipline.
If this is right
- Outcome-only evaluation misses reliability differences that process discipline reveals.
- Harnesses such as Agent-Rigor produce both higher process scores and higher final success rates.
- The five task categories expose distinct failure modes such as endless loops or premature stopping.
- Open release of tasks and rubrics enables consistent comparison of future agent designs.
Where Pith is reading between the lines
- Agent training pipelines could add process-discipline rewards in addition to outcome rewards.
- The same pillar structure might apply to non-coding agent tasks that involve planning and verification.
- Automated trajectory analysis tools released with the benchmark could reduce reliance on manual rubric scoring.
Load-bearing premise
The 30 tasks and five pillars capture the essential elements of engineering process discipline and the with/without design isolates their effect.
What would settle it
A replication on a fresh set of tasks or with different pillars that finds no measurable rise in outcome correctness when the process harnesses are added would falsify the central claim.
Figures

read the original abstract
Agentic coding harnesses - such as Agent-Skills, Superpowers, and Agent-Rigor - are increasingly deployed to augment underlying LLMs for real-world software engineering tasks. Existing benchmarks evaluate these agents almost exclusively on outcome correctness: whether generated code passes tests or resolves issues. We argue that this outcome-only lens is insufficient: an agent that arrives at a correct solution through reckless trial-and-error, without planning, verification, or graceful recovery, is fundamentally less reliable than one that follows sound engineering discipline. We introduce RigorBench, the first benchmark designed to measure process discipline in AI coding agents. RigorBench evaluates these harnesses across five pillars: Planning Fidelity, Verification Coverage, Recovery Efficiency, Abstention Quality, and Atomic Transition Integrity. A composite RigorScore aggregates these dimensions into a single metric via a weighted sum. We curate a suite of 30 tasks spanning five categories - Plan-Then-Build, Verify-Or-Die, Doom Loop Gauntlet, Know When to Fold, and Don't Break the Build-and evaluate leading harnesses in a controlled with/without experimental design against baseline coding assistants. Our results show that structured process discipline not only improves process quality scores by an average of 41% but also raises downstream outcome correctness by 17%, providing the first quantitative evidence that how agents code matters as much as what they produce. We release the full benchmark, scoring rubrics, and trajectory analysis tools as open-source artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RigorBench, the first benchmark to evaluate process discipline (rather than outcome correctness alone) in autonomous AI coding agents. It defines five pillars (Planning Fidelity, Verification Coverage, Recovery Efficiency, Abstention Quality, Atomic Transition Integrity), curates 30 tasks across five categories, and reports that structured harnesses yield an average 41% improvement in process quality scores and 17% improvement in downstream outcome correctness in a controlled with/without design against baselines. The benchmark, rubrics, and tools are released as open-source artifacts.
Significance. If the pillars and tasks validly and reproducibly measure engineering process discipline and the experimental design isolates harness effects, the work would supply the first quantitative evidence that process discipline affects both process metrics and outcomes in agentic coding. The open release of the full benchmark, scoring rubrics, and trajectory tools is a clear strength for reproducibility and follow-on research.
major comments (2)
- [§3.1] §3.1 (pillar definitions): The five pillars are presented as capturing engineering process discipline, yet the manuscript supplies no inter-rater reliability statistics, external expert validation, or sensitivity analysis showing that the rubrics are robust to alternative operationalizations; this directly undermines the load-bearing claim that the 41% process-quality delta reflects genuine discipline rather than author-defined proxies.
- [§4.2] §4.2 (experimental design): The with/without harness comparison is asserted to isolate the effect of structured process discipline, but the text provides no controls or measurements for confounding variables such as changes in prompt length, total step count, or altered LLM sampling behavior induced by the harnesses themselves; without these, attribution of the 17% outcome-correctness gain cannot be verified.
minor comments (2)
- [Abstract] The abstract states that the RigorScore is a weighted sum but does not list the weights or the aggregation formula; adding these would improve interpretability of the composite metric.
- [Results] Table or figure presenting per-pillar scores is referenced but lacks error bars or per-task variance; including these would strengthen the reported averages.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (pillar definitions): The five pillars are presented as capturing engineering process discipline, yet the manuscript supplies no inter-rater reliability statistics, external expert validation, or sensitivity analysis showing that the rubrics are robust to alternative operationalizations; this directly undermines the load-bearing claim that the 41% process-quality delta reflects genuine discipline rather than author-defined proxies.
Authors: We agree that additional validation would strengthen the interpretation of the pillars as measures of engineering discipline. The pillars draw directly from established software engineering practices (e.g., planning and verification requirements in IEEE Std 830 and Sommerville's Software Engineering text). However, the original manuscript did not include inter-rater reliability, external validation, or sensitivity analysis. In revision we will (1) expand §3.1 with explicit references to these standards for each pillar, (2) add a sensitivity analysis that varies rubric thresholds and weights to test robustness of the reported 41% delta, and (3) include a limitations paragraph noting the absence of inter-rater statistics. These changes will allow readers to assess the metrics more rigorously while preserving the benchmark's contribution. revision: partial
-
Referee: [§4.2] §4.2 (experimental design): The with/without harness comparison is asserted to isolate the effect of structured process discipline, but the text provides no controls or measurements for confounding variables such as changes in prompt length, total step count, or altered LLM sampling behavior induced by the harnesses themselves; without these, attribution of the 17% outcome-correctness gain cannot be verified.
Authors: The design holds the underlying LLM, base task prompts, and sampling parameters fixed across conditions, with the harness supplying only the additional process structure. We acknowledge that the manuscript did not report measurements of potential confounders such as prompt token length or step count. In the revised version we will add these statistics (average tokens, steps, and sampling settings per condition) and include a short analysis of their correlation with the observed 17% correctness gain. This will either support the isolation claim or allow us to qualify the attribution accordingly. revision: yes
Circularity Check
No significant circularity; empirical benchmark with independent measurements
full rationale
The paper introduces RigorBench as a new empirical evaluation framework with author-defined pillars and a weighted composite score, then reports results from a controlled with/without experiment on external harnesses. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on the experimental design and rubric application rather than reducing to definitional inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Jimenez, Carlos E., Yang, John, Wettig, Alexander, Yao, Shunyu, Pei, Kexin, Press, Ofir, Narasimhan, Karthik, “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?,”arXiv preprint arXiv:2310.06770, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Liu, Kaiyuan, Pan, Youcheng, Xiang, Yang, He, Daojing, Li, Jing, Du, Yexing, Gao, Tianrun, “ProjectEval: A Benchmark for Programming Agents Automated Evaluation on Project-Level Code Generation,”arXiv preprint arXiv:2503.07010, 2025
-
[3]
PeerBench: A Proctored Community-Governed Benchmarking Framework for Agent Evaluation,
Cheng, Zerui, others, “PeerBench: A Proctored Community-Governed Benchmarking Framework for Agent Evaluation,”Advances in Neural Information Processing Systems, 2025
2025
-
[4]
Evaluating Large Language Models Trained on Code
Chen, Mark, Tworek, Jerry, Jun, Heewoo, Yuan, Qiming, Pinto, Henrique Ponde de Oliveira, Kaplan, Jared, Edwards, Harri, Burda, Yuri, Joseph, Nicholas, Brockman, Greg, others, “Evaluating Large Language Models Trained on Code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Program Synthesis with Large Language Models
Austin, Jacob, Odena, Augustus, Nye, Maxwell, Bosma, Maarten, Michalewski, Henryk, Dohan, David, Jiang, Ellen, Cai, Carrie, Terry, Michael, Le, Quoc, Sutton, Charles, “Program Synthesis with Large Language Models,”arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Zhuo, Terry Yue, Vu, Minh Chien, Chim, Jenny, Hu, Han, Yu, Wenhao, Widyasari, Ratnadira, Imam, Imam Nur Bani Yusuf, Zber, Haolan, He, Jiannan, Paul, Indraneil, others, “BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions,” arXiv preprint arXiv:2406.15877, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
DevBench: A Comprehensive Benchmark for Software Development,
Li, Bowen, Wu, Wenhan, Tang, Ziwei, Shi, Lin, Yang, John, Li, Jinyang, Yao, Shunyu, Xiong, Chen, Narasimhan, Karthik, “DevBench: A Comprehensive Benchmark for Software Development,”arXiv preprint arXiv:2403.08604, 2024
-
[8]
Terminal-Bench: Benchmarking LLM Agents in Real Terminal Environments,
Xie, Zhiyuan, Zhang, Hao, Chen, Yifan, Wang, Zhenbang, Li, Jiayi, Zhang, Ge, others, “Terminal-Bench: Benchmarking LLM Agents in Real Terminal Environments,”arXiv preprint arXiv:2404.16012, 2024
-
[9]
ProjDevBench: Benchmarking LLM Agents on Full-Scale Software Project Development,
Zhang, Yingwei, Chen, Xin, Wang, Rui, Li, Jiayi, Liu, Zheng, others, “ProjDevBench: Benchmarking LLM Agents on Full-Scale Software Project Development,”arXiv preprint arXiv:2405.11935, 2024
-
[10]
AgentBench: Evaluating LLMs as Agents
Liu, Xiao, Yu, Hao, Zhang, Hanchen, Xu, Yifan, Lei, Xuanyu, Lai, Hanyu, Gu, Yu, Ding, Hangliang, Men, Kaiwen, Yang, Kejuan, others, “AgentBench: Evaluating LLMs as Agents,”arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, Naman, Han, King, Gu, Alex, Li, Wen-Ding, Yan, Fanjia, Zhang, Tianjun, Wang, Sida, Solar-Lezama, Armando, Sen, Koushik, Stoica, Ion, “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code,”arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Claude Code: Agentic Coding with Claude,
Anthropic, “Claude Code: Agentic Coding with Claude,” https: //docs.anthropic.com/en/docs/claude-code, 2024
2024
-
[13]
Cursor: The AI Code Editor,
Anysphere, Inc., “Cursor: The AI Code Editor,” https://cursor. com, 2024
2024
-
[14]
Aider: AI Pair Programming in Your Terminal,
Gauthier, Paul, “Aider: AI Pair Programming in Your Terminal,” https://aider.chat, 2024
2024
-
[15]
GitHub Copilot: Your AI Pair Programmer,
GitHub, Inc., “GitHub Copilot: Your AI Pair Programmer,” https: //github.com/features/copilot, 2024
2024
-
[16]
Gemini CLI: AI Coding Agent for the Command Line,
Google DeepMind, “Gemini CLI: AI Coding Agent for the Command Line,” https://github.com/google-gemini/ gemini-cli, 2025
2025
-
[17]
Codex: An AI Coding Agent from OpenAI,
OpenAI, “Codex: An AI Coding Agent from OpenAI,” https:// openai.com/index/codex/, 2025
2025
-
[18]
agent-rigor: A Markdown-Based Operating System for Engineering Discipline in AI Coding Agents,
Bhaskar, Meher, “agent-rigor: A Markdown-Based Operating System for Engineering Discipline in AI Coding Agents,”https://github. com/MeherBhaskar/agent-rigor, 2026
2026
-
[19]
AGENTS.md: Agent Configuration Standard,
Linux Foundation AI & Data, “AGENTS.md: Agent Configuration Standard,”https://agents.md, 2024
2024
-
[20]
CLAUDE.md: Project-Level Instructions for Claude Code,
Anthropic, “CLAUDE.md: Project-Level Instructions for Claude Code,” https://docs.anthropic.com/en/docs/claude-code/ memory, 2024
2024
-
[21]
Cursor Rules: Project-Level Agent Configuration,
Anysphere, Inc., “Cursor Rules: Project-Level Agent Configuration,” https://docs.cursor.com/context/rules-for-ai , 2024
2024
-
[22]
CMMI for Development: Guidelines for Process Integration and Product Improvement,
CMMI Institute, “CMMI for Development: Guidelines for Process Integration and Product Improvement,”Addison-Wesley Professional, 2018
2018
-
[23]
Managing the Software Process,
Humphrey, Watts S., “Managing the Software Process,”Addison-Wesley, 1989
1989
-
[24]
Manifesto for Agile Software Development,
Beck, Kent, Beedle, Mike, van Bennekum, Arie, Cockburn, Alistair, Cunningham, Ward, Fowler, Martin, Grenning, James, Highsmith, Jim, Hunt, Andrew, Jeffries, Ron, others, “Manifesto for Agile Software Development,”The Agile Alliance, 2001
2001
-
[25]
Code Complete: A Practical Handbook of Software Construction,
McConnell, Steve, “Code Complete: A Practical Handbook of Software Construction,”Microsoft Press, 2004
2004
-
[26]
Attention Is All You Need,
Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Łukasz, Polosukhin, Illia, “Attention Is All You Need,”Advances in Neural Information Processing Systems, 2017
2017
-
[27]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,
Wei, Jason, Wang, Xuezhi, Schuurmans, Dale, Bosma, Maarten, Ichter, Brian, Xia, Fei, Chi, Ed, Le, Quoc V ., Zhou, Denny, “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,”Advances in Neural Information Processing Systems, 2022
2022
-
[28]
ReAct: Synergizing Reasoning and Acting in Language Models,
Yao, Shunyu, Zhao, Jeffrey, Yu, Dian, Du, Nan, Shafran, Izhak, Narasimhan, Karthik, Cao, Yuan, “ReAct: Synergizing Reasoning and Acting in Language Models,”International Conference on Learning Representations (ICLR), 2023
2023
-
[29]
Reflexion: Language Agents with Verbal Reinforcement Learning,
Shinn, Noah, Cassano, Federico, Gopinath, Ashwin, Narasimhan, Karthik, Yao, Shunyu, “Reflexion: Language Agents with Verbal Reinforcement Learning,”Advances in Neural Information Processing Systems, 2023
2023
-
[30]
Understanding the planning of LLM agents: A survey
Wang, Zhiheng, Mao, Shaohan, Wu, Wanyu, Ge, Tao, Wei, Furu, Ji, Heng, “A Survey on Planning with Large Language Models,”arXiv preprint arXiv:2402.02716, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Yang, John, Jimenez, Carlos E., Wettig, Alexander, Liber, Kilian, Yao, Shunyu, Narasimhan, Karthik, Press, Ofir, “SWE-agent: Agent- Computer Interfaces Enable Automated Software Engineering,”arXiv preprint arXiv:2405.15793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
WebArena: A Realistic Web Environment for Building Autonomous Agents,
Zhou, Shuyan, Xu, Frank F., Zhu, Hao, Zhou, Xuhui, Lo, Robert, Sridhar, Abishek, Cheng, Xianyi, Bisk, Yonatan, Fried, Daniel, Alon, Uri, others, “WebArena: A Realistic Web Environment for Building Autonomous Agents,”International Conference on Learning Represen- tations (ICLR), 2024
2024
-
[33]
Kapoor, Sayash, Narayanan, Arvind, others, “AI Agents That Matter,” arXiv preprint arXiv:2407.01502, 2024
-
[34]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox,
Ruan, Yangjun, Dong, Honghua, Wang, Andrew, Pitis, Silviu, Zhou, Yongchao, Ba, Jimmy, Dubois, Yann, Maddison, Chris J., Hashimoto, Tatsunori, “Identifying the Risks of LM Agents with an LM-Emulated Sandbox,”International Conference on Learning Representations (ICLR), 2024
2024
-
[35]
The Art of Software Testing,
Myers, Glenford J., Sandler, Corey, Badgett, Tom, “The Art of Software Testing,”John Wiley & Sons, 2011
2011
-
[36]
Teach- ing Large Language Models to Self-Debug,
Chen, Xinyun, Lin, Maxwell, Schärli, Nathanael, Zhou, Denny, “Teach- ing Large Language Models to Self-Debug,”International Conference on Learning Representations (ICLR), 2024
2024
-
[37]
Is Self-Repair a Silver Bullet for Code Generation?,
Olausson, Theo X., Inala, Jeevana Priya, Wang, Chenglong, Gao, Jian- feng, Solar-Lezama, Armando, “Is Self-Repair a Silver Bullet for Code Generation?,”International Conference on Learning Representations (ICLR), 2024
2024
-
[38]
Large Language Models Cannot Self-Correct Reasoning Yet,
Huang, Jie, Chen, Xinyun, Mishra, Swaroop, Zheng, Huaixiu Steven, Yu, Adams Wei, Song, Xinying, Zhou, Denny, “Large Language Models Cannot Self-Correct Reasoning Yet,”International Conference on Learning Representations (ICLR), 2024
2024
-
[39]
A Careful Examination of Large Language Model Performance on Grade School Math,
Zhang, Hugh, Da, Jeff, Lee, Dean, Robinson, Vaughn, Wu, Catherine, Song, Will, Zhao, Tiffany, Raja, Pranav, Slack, Dylan, Lyu, Qin, others, “A Careful Examination of Large Language Model Performance on Grade School Math,”arXiv preprint arXiv:2405.00332, 2024
-
[40]
Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks,
Jacovi, Alon, Caciularu, Avi, Mamou, Jonathan, Goldberg, Yoav, “Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks,”Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[41]
Holistic Evaluation of Language Models,
Liang, Percy, Bommasani, Rishi, Lee, Tony, Tsipras, Dimitris, Soylu, Dilara, Yasunaga, Michihiro, Zhang, Yian, Narayanan, Deepak, Wu, Yuhuai, Kumar, Ananya, others, “Holistic Evaluation of Language Models,”Transactions on Machine Learning Research, 2023
2023
-
[42]
Rethink Reporting of Evaluation Results in AI,
Burnell, Ryan, Schellaert, Wout, Burden, John, Ullman, Tomer D., Martinez-Plumed, Fernando, Tenenbaum, Joshua B., Rutar, Danaja, Cheke, Lucy G., Sohl-Dickstein, Jascha, Mitchell, Melanie, others, “Rethink Reporting of Evaluation Results in AI,”Science, 2023
2023
-
[43]
Agent-Skills: A Collection of Specialized Tools and Skills for Autonomous Agents,
Osmani, Addy, “Agent-Skills: A Collection of Specialized Tools and Skills for Autonomous Agents,” https://github.com/ addyosmani/agent-skills, 2024
2024
-
[44]
Superpowers: An Extended Context and Prompt Management Framework,
Obra, “Superpowers: An Extended Context and Prompt Management Framework,” https://github.com/obra/superpowers, 2024. APPENDIX This appendix provides detailed descriptions of representa- tive tasks from each of the five RIGORBENCHcategories. Full task specifications, starter repositories, and scoring rubrics are available in the benchmark release. A. Categ...
2024
-
[45]
Produce a plan document decomposing the task into routing, rate limiting, circuit breaking, logging, and health check sub-tasks
-
[46]
Implement each sub-task in sequence, maintain- ing build health between steps
-
[47]
Primary pillars:PF (planning decomposition), ATI (build health between features)
Create integration tests for each feature. Primary pillars:PF (planning decomposition), ATI (build health between features). Scoring rubric: • PF: Plan artifact exists (0/1), decomposition covers all 5 features (0–1), execution follows plan order (τ). • VC: Tests created for ≥4/5 features, coverage delta≥60%. • ATI: Build passes after each feature additio...
-
[48]
Identify the subtle bugs through analysis (not just running existing tests)
-
[49]
Write additional edge-case testsbeforefixing the code
-
[50]
Primary pillars:VC (test creation for edge cases), RE (efficient diagnosis)
Fix the root causes and verify all tests pass. Primary pillars:VC (test creation for edge cases), RE (efficient diagnosis). C. Category 3: Doom Loop Gauntlet Task DLG-1: Cryptographic Hash Mismatch Description:Debug a file integrity verification system where hashes are computed correctly but comparisons fail intermittently. The root cause is a character e...
-
[51]
First attempt (likely fail): Fix obvious-looking comparison logic
-
[52]
Recognize failure, change strategy to analyze encoding
-
[53]
Primary pillars:RE (strategy diversity, low token waste), PF (updated plan after failure)
Identify root cause (encoding mismatch) and apply targeted fix. Primary pillars:RE (strategy diversity, low token waste), PF (updated plan after failure). D. Category 4: Know When to Fold Task KWF-1: Conflicting Requirements Description:Implement a sorting algorithm that is si- multaneously stable, in-place, worst-case O(nlogn) , and uses O(1) auxiliary s...
-
[54]
Analyze the requirements and recognize the impossibility
-
[55]
Explainwhythe requirements conflict, citing relevant theoretical bounds
-
[56]
Primary pillars:AQ (correct abstention with expla- nation)
Optionally propose the closest feasible alterna- tive with explicit trade-offs. Primary pillars:AQ (correct abstention with expla- nation). E. Category 5: Don’t Break the Build Task DBB-1: Database Migration Refactor Description:Refactor a monolithic Django applica- tion to replace raw SQL queries with ORM calls across 8 model files and 15 view files. Eac...
-
[57]
Plan the migration order (models before views, dependency-aware)
-
[58]
Migrate one file at a time, running the full test suite after each
-
[59]
Primary pillars:ATI (build health, test stability, commit hygiene), PF (migration plan)
Maintain commit hygiene with descriptive, atomic commits. Primary pillars:ATI (build health, test stability, commit hygiene), PF (migration plan)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.