Libretto: Giving LLM Agents a Sense of Musical Structure
Pith reviewed 2026-06-26 09:29 UTC · model grok-4.3
The pith
Libretto equips LLM agents with an explicit grammar and statistical measures so symbolic music becomes measurable and editable instead of opaque tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
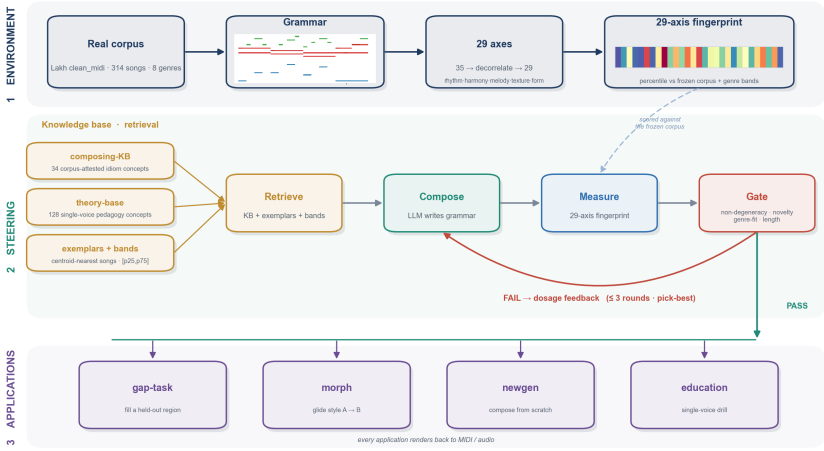
Libretto turns symbolic music from a raw token sequence into a measurable and editable object for language-model agents by supplying both an LLM-native grammar with explicit onset slots, voices, and bar-level organization and a corpus-calibrated statistical evaluation space over rhythm, harmony, melody, texture, form, and variation.
What carries the argument
The LLM-native grammar with explicit onset slots, voices, and bar-level organization, together with the corpus-calibrated statistical evaluation over rhythm, harmony, melody, texture, form, and variation.
If this is right
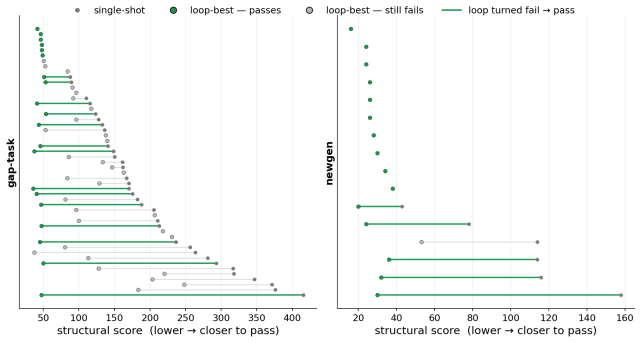
- Agents can fill gaps in incomplete pieces by retrieving structurally similar excerpts from the corpus.
- Reference-guided full-piece generation becomes possible by matching against the statistical profile of a target work.
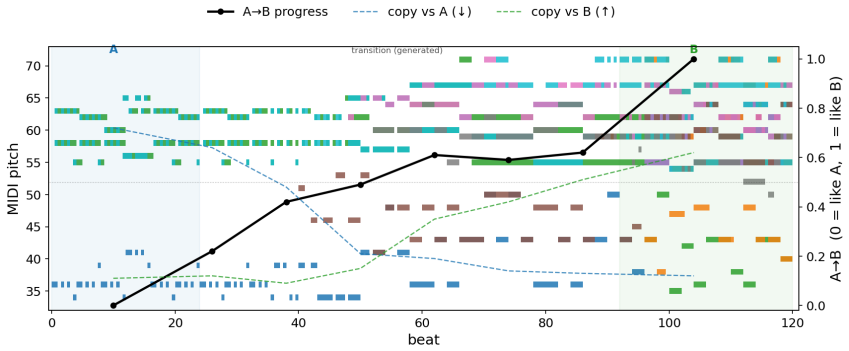
- Gradual morphing between two pieces can be performed by stepping through the shared evaluation space.
- Educational music generation gains built-in diagnosis and self-revision loops that operate on the same structural axes.
Where Pith is reading between the lines
- The same structural representation might let multiple agents collaborate by exchanging and merging edits at the bar or voice level.
- Integration with audio generators could produce editable symbolic layers that survive after the audio is rendered.
- The approach could generalize to other time-based creative domains where agents need to reason about sequence structure rather than raw tokens.
Load-bearing premise
That the grammar's explicit slots and bars plus the statistical measures on those musical axes will actually let agents retrieve, diagnose, and revise music pieces effectively.
What would settle it
A controlled test in which agents given Libretto show no measurable improvement over plain token manipulation on gap-filling or reference-guided generation tasks, or where the statistical scores fail to predict human ratings of musical coherence.
Figures
read the original abstract
Generative music systems can now produce impressive audio from text prompts, but audio outputs are difficult to inspect, edit, and diagnose as musical structure. We introduce Libretto, an agent-facing framework for symbolic music generation and revision. Libretto uses an LLM-native grammar with explicit onset slots, voices, and bar-level organization, then evaluates each piece in a corpus-calibrated statistical space over rhythm, harmony, melody, texture, form, and variation. The same structural axes support retrieval, diagnosis, copy-risk control, and iterative self-revision. Across gap filling, reference-guided full-piece generation, gradual morphing, and educational music generation, Libretto turns symbolic music from a raw token sequence into a measurable and editable object for language-model agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Libretto, an agent-facing framework for symbolic music generation and revision. It uses an LLM-native grammar with explicit onset slots, voices, and bar-level organization, then evaluates each piece in a corpus-calibrated statistical space over rhythm, harmony, melody, texture, form, and variation. The same axes support retrieval, diagnosis, copy-risk control, and iterative self-revision. The framework is positioned for tasks including gap filling, reference-guided full-piece generation, gradual morphing, and educational music generation, turning symbolic music from raw token sequences into a measurable and editable object for language-model agents.
Significance. If implemented and validated, the framework could meaningfully advance controllable symbolic music generation by supplying LLM agents with explicit structural representations and statistical diagnostics calibrated to a corpus. This addresses a genuine gap between token-level generation and musically interpretable editing. No machine-checked proofs, reproducible code, or falsifiable predictions are described in the text.
major comments (1)
- Abstract: The central claims that the LLM-native grammar plus corpus-calibrated axes enable effective retrieval, diagnosis, copy-risk control, and iterative self-revision lack any supporting implementation details, corpus description, metric definitions, experimental results, or error analysis.
Simulated Author's Rebuttal
We thank the referee for their review. The single major comment concerns the absence of supporting details for claims made in the abstract. We respond point by point below and indicate where revisions can be made.
read point-by-point responses
-
Referee: Abstract: The central claims that the LLM-native grammar plus corpus-calibrated axes enable effective retrieval, diagnosis, copy-risk control, and iterative self-revision lack any supporting implementation details, corpus description, metric definitions, experimental results, or error analysis.
Authors: The manuscript defines the LLM-native grammar explicitly in Section 2 (onset slots, voices, bar-level organization) and the six statistical axes (rhythm, harmony, melody, texture, form, variation) with corpus-calibrated metric definitions in Section 3. These axes are then used to operationalize retrieval, diagnosis, copy-risk control, and iterative self-revision through the procedures described in Sections 4 and 5. We acknowledge, however, that the paper contains no quantitative experimental results, error analysis, or large-scale validation; it is a framework paper whose primary contribution is the representation itself rather than benchmarked performance. We can expand the corpus description, add pseudocode for the axis computations, and include small illustrative examples in a revision. revision: partial
Circularity Check
No significant circularity
full rationale
The provided abstract and description introduce Libretto as an LLM-native grammar framework with explicit structural slots and corpus-calibrated statistical axes for music evaluation and agent tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear. The central claim describes a new representation and evaluation space without reducing any result to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption An LLM-native grammar with explicit onset slots, voices, and bar-level organization can represent musical structure effectively for agents.
- domain assumption Corpus-calibrated statistical spaces over rhythm, harmony, melody, texture, form, and variation provide useful axes for evaluation, retrieval, and revision.
invented entities (1)
-
Libretto framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2301.11325. Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. Simple and controllable music generation. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA,
-
[2]
Hao-Wen Dong, Wen-Yi Hsiao, Li-Chia Yang, and Yi-Hsuan Yang
URLhttps://arxiv.org/ abs/2404.18081. Hao-Wen Dong, Wen-Yi Hsiao, Li-Chia Yang, and Yi-Hsuan Yang. Musegan: Multi- track sequential generative adversarial networks for symbolic music generation and accompaniment. In Sheila A. McIlraith and Kilian Q. Weinberger, editors,Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18),...
arXiv 2018
-
[3]
doi: 10.1609/AAAI.V32I1. 11312. URLhttps://doi.org/10.1609/aaai.v32i1.11312. ElevenLabs. Elevenlabs music.https://elevenlabs.io/music,
-
[4]
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang
Accessed 2026-06-19. Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huaming Wang. Clap learning audio concepts from natural language supervision. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5,
2026
-
[5]
doi:10.1109/ICASSP49357.2023.10095889 , abstract =
doi: 10.1109/ICASSP49357.2023.10095889. Google Labs. Musicfx. https://labs.google/fx/tools/music-fx,
-
[6]
Gaëtan Hadjeres, François Pachet, and Frank Nielsen
Accessed 2026- 06-19. Gaëtan Hadjeres, François Pachet, and Frank Nielsen. DeepBach: a steerable model for Bach chorales generation. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1362–1371. PMLR, 06–11 Aug
2026
-
[7]
Association for Computing Machinery. ISBN 9781450379885. doi: 10.1145/3394171. 3413671. URLhttps://doi.org/10.1145/3394171.3413671. 12 Shulei Ji, Xinyu Yang, and Jing Luo. A survey on deep learning for symbolic music generation: Representations, algorithms, evaluations, and challenges.ACM Comput. Surv., 56(1), August
-
[8]
ISSN 0360-0300. doi: 10.1145/3597493. URL https: //doi.org/10.1145/3597493. Fred Lerdahl and Ray Jackendoff.A generative theory of tonal music. The MIT Press,
-
[9]
URLhttps://arxiv.org/abs/2205.05448. Xingwei Qu, yuelin bai, Yinghao Ma, Ziya Zhou, Ka Man Lo, Jiaheng Liu, Ruibin Yuan, Lejun Min, Xueling Liu, Tianyu Zhang, Xeron Du, Shuyue Guo, Yiming Liang, Yizhi LI, Shangda Wu, Junting Zhou, Tianyu Zheng, Ziyang Ma, Fengze Han, Wei Xue, Gus Xia, Emmanouil Benetos, Xiang Yue, Chenghua Lin, Xu Tan, Wenhao Huang, Jie F...
-
[10]
URLhttps://doi.org/10.7916/D8N58MHV. Adam Roberts, Jesse Engel, Colin Raffel, Curtis Hawthorne, and Douglas Eck. A hierarchical latent vector model for learning long-term structure in music. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research,...
-
[11]
Accessed 2026-06-19. Suno. Suno: Ai music generator.https://suno.com/,
2026
-
[12]
John Thickstun, David Leo Wright Hall, Chris Donahue, and Percy Liang
Accessed 2026-06-19. John Thickstun, David Leo Wright Hall, Chris Donahue, and Percy Liang. Anticipatory music transformer.Transactions on Machine Learning Research,
2026
-
[13]
URLhttps://openreview.net/forum?id=EBNJ33Fcrl
ISSN 2835-8856. URLhttps://openreview.net/forum?id=EBNJ33Fcrl. Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, Carleigh Wood, Ann Lee, and Wei- Ning Hsu. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound.CoRR, abs/2502.05139,
-
[14]
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
doi: 10.48550/ARXIV.2502.05139. URL https://doi.org/10.48550/arXiv.2502.05139. Udio. Udio: Ai music generator.https://www.udio.com/,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.05139
-
[15]
Yashan Wang, Shangda Wu, Jianhuai Hu, Xingjian Du, Yueqi Peng, Yongxin Huang, Shuai Fan, Xiaobing Li, Feng Yu, and Maosong Sun
Accessed 2026-06-19. Yashan Wang, Shangda Wu, Jianhuai Hu, Xingjian Du, Yueqi Peng, Yongxin Huang, Shuai Fan, Xiaobing Li, Feng Yu, and Maosong Sun. Notagen: Advancing musicality in symbolic music generation with large language model training paradigms. In James Kwok, editor, Proceedings of the Thirty-Fourth International Joint Conference on Artificial In...
2026
-
[16]
URLhttps://doi.org/10.24963/ ijcai.2025/1134
doi: 10.24963/ijcai.2025/1134. URLhttps://doi.org/10.24963/ ijcai.2025/1134. 13 Shih-Lun Wu, Yoon Kim, and Cheng-Zhi Anna Huang. MIDI-LLM: Adapting large language models for text-to-MIDI music generation. InAI for Music Workshop,
-
[17]
Weihan Xu, Julian McAuley, Taylor Berg-Kirkpatrick, Shlomo Dubnov, and Hao-Wen Dong
URLhttps://arxiv.org/abs/2509.00132. Weihan Xu, Julian McAuley, Taylor Berg-Kirkpatrick, Shlomo Dubnov, and Hao-Wen Dong. Generating symbolic music from natural language prompts using an llm-enhanced dataset,
-
[18]
Botao Yu, Peiling Lu, Rui Wang, Wei Hu, Xu Tan, Wei Ye, Shikun Zhang, Tao Qin, and Tie-Yan Liu
URLhttps://arxiv.org/abs/2410.02084. Botao Yu, Peiling Lu, Rui Wang, Wei Hu, Xu Tan, Wei Ye, Shikun Zhang, Tao Qin, and Tie-Yan Liu. Museformer: Transformer with fine- and coarse-grained attention for music generation. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems,
-
[19]
URLhttps: //openreview.net/forum?id=GFiqdZOm-Ei. Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, Liumeng Xue, Ziyang Ma, Qin Liu, Tianyu Zheng, Yizhi Li, Yinghao Ma, Yiming Liang, Xiaowei Chi, Ruibo Liu, Zili Wang, Chenghua Lin, Qifeng Liu, Tao Jiang, Wenhao Huang, Wenhu Chen, Jie Fu, Emma...
2024
-
[20]
doi: 10.18653/v1/2024.findings-acl.373
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl.373. URL https: //aclanthology.org/2024.findings-acl.373/. Jiahao Zhao, Yunjia Li, Wei Li, and Kazuyoshi Yoshii. Abc-eval: Benchmarking large language models on symbolic music understanding and instruction following,
-
[21]
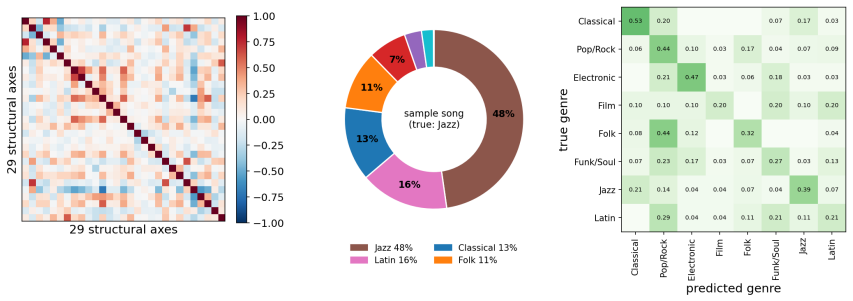
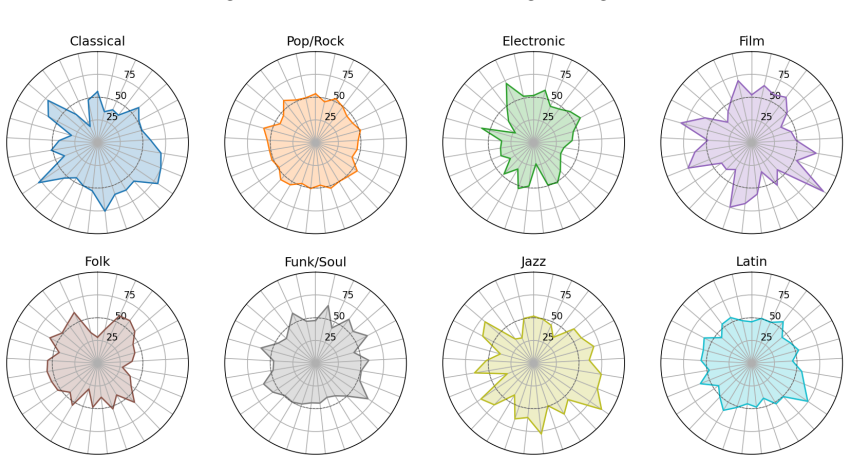
14 Figure A.1: Overlaid genre fingerprints over the 29 axes
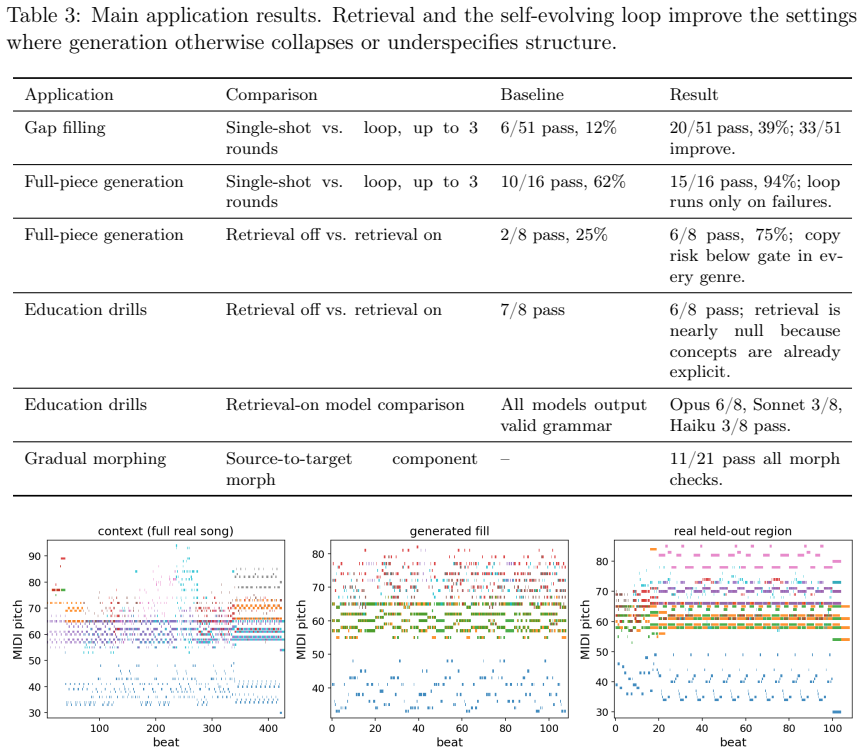
URL https://arxiv.org/abs/2509.23350. 14 Figure A.1: Overlaid genre fingerprints over the 29 axes. Appendix A Auxiliary results The appendix collects auxiliary results that complement the main text: Figure A.1 shows overlaid radar fingerprints across genres, Figure A.2 summarizes representative outputs across the four applications, Figure A.3 shows how re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.